版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq1010885678/article/details/44984327
在使用mahout之前要安装并启动hadoop集群
将mahout的包上传至linux中并解压即可
mahout下载地址:
点击打开链接
mahout中的算法大致可以分为三大类:
聚类,协同过滤和分类
其中
常用聚类算法有:canopy聚类,k均值算法(kmeans),模糊k均值,层次聚类,LDA聚类等
常用分类算法有:贝叶斯,逻辑回归,支持向量机,感知器,神经网络等
下面将运行mahout中自带的example例子jar包来查看mahou是否能正确运行
练习数据下载地址:
点击打开链接
上面的练习数据是用来检测kmeans聚类算法的数据
使用hadoop命令运行mahout的例子程序(确保hadoop集群已开启)
在例子代码中写死了输入的路径是/user/hadoop/testdata
将练习数据上传到hdfs中对应的testdata目录下即可
写死的输出路径是/user/hadoop/output
执行命令:
hadoop jar ~/mahout/mahout-examples-0.9-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
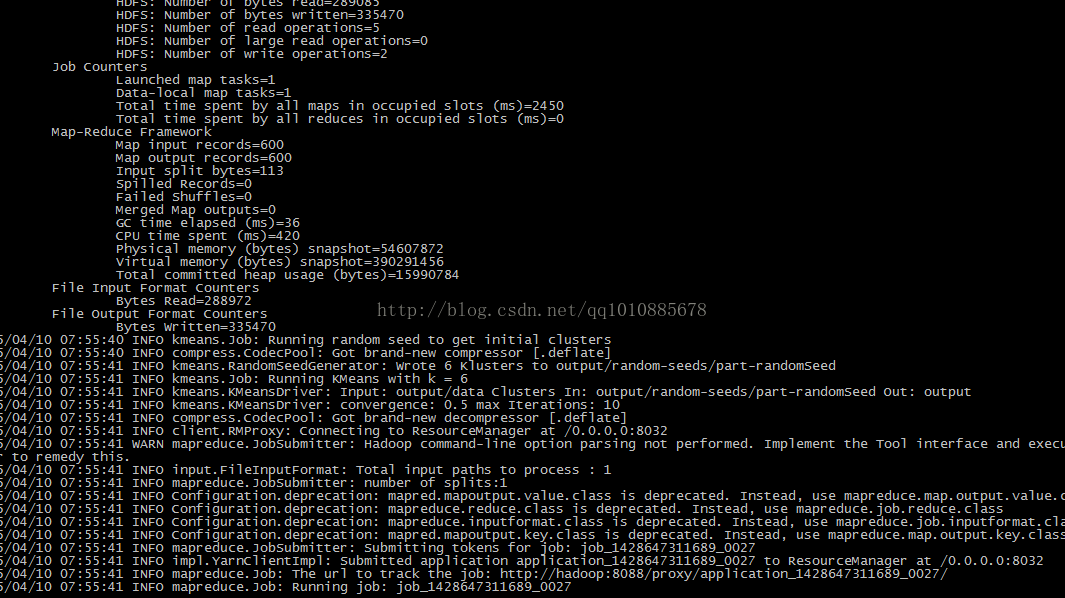
开始执行任务
![]()
由于聚类算法是一种迭代的过程(之后会讲解)
所欲他会一直重复的执行mr任务到符合要求(这其中的过程可能有点久。。。)
运行结果如下:
![]()
mahout无异常
执行完这个kmeans算法之后产生的文件按普通方式是查看不了的,看到的只是一堆莫名其妙的数据
需要用mahout的seqdumper命令来下载到本地linux上才能查看正常结果
查看聚类分析的结果:
./mahout seqdumper -s /user/hadoop/output/data/part-m-0000 /home/hadoop/res
之后使用cat命令即可查看
cat res | more
现在来说说什么是kmeans聚类算法
所谓聚类算法就是将一份数据,按照我们想要的或者这份数据中的规律来将数据分类的算法
例如:
现有一份杂乱的样本数据,我们希望数据最后按照某些类别来划分(红豆分为红豆,绿豆分为绿豆等意思)
聚类算法会从n个类的初始中心开始(如果没有人为设置,其会按照随机的初始中心开始)
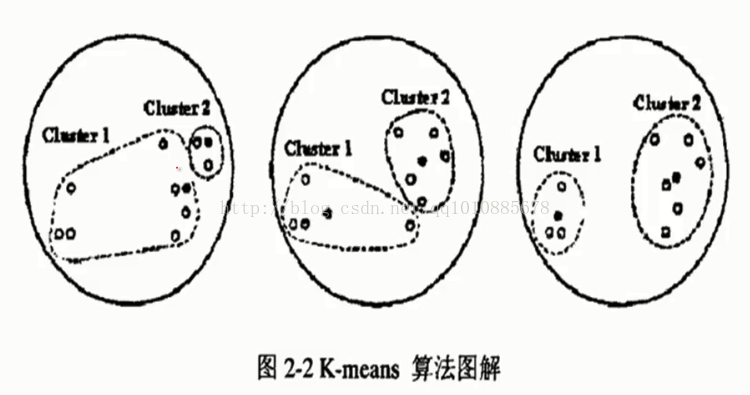
什么意思呢?来看一张图
![]()
上图中,左一的圆圈表示原始数据在随机的初始中心划分后的的分布
但是可以看出很明显cluster1中有很多是靠近cluster2的数据点
所以kmeans会根据规则再次计算出更加合适的中心点来进行划分
这个规则就是:
计算每个数据点,到原始中心cluster1和cluster2的距离
离谁比较近就划分到谁那边去(形如中间的圆圈)
然后将cluster1和cluster2中的数据分别求平均值,得到的两个平均值成为新的cluster1和cluster2中心点
但是很明显这样划分还是不够合理
所以kmeans会继续迭代计算每个数据到新的中心点的距离
离谁比较近就划分给谁
然后在分别求平均值得到新的中心点
直到cluster1和cluster2中的数据平均值不在发生变化时认为此时是最理想的划分方式(也可以进行人工的干预)
该算法的最大优势在于简介快速。算法的关键在于初始中心的选择和计算距离的公式
最后在调用一个mahout的一个算法来测试mahout
调用fpg算法(实现计数频繁项集的算法)
测试数据下载(电商购物车数据)
点击打开链接
在mahout的bin目录下
./mahout fpg -i /user/hadoop/testdata/tail.txt -o /user/hadoop/output -method mapreduce -s 1000 -regex '[]'
各个参数的意义:
-i:指定输入数据的路径
-o:指定输出结果的路径
-method:指定使用mapreduce方法
-s:最小支持度
-regex:使用指定的正则来匹配过滤数据
同样的,运行结果的数据要通过seqdumper来查看