上次配了一次,没多少感觉。
代码看累了。
配置一次再轻松一下脑袋。。。
不过,这次是在家里的VM上,用最新的JDK-7U-17和上HADOOP-1.1.2搞的。
CENTOS版本来6.3-I386.
一次OK。
这次参考的贴子是:
http://bjbxy.blog.51cto.com/854497/352692
相关输出如下:
# jps
2614 Jps
2280 TaskTracker
1908 NameNode
2110 SecondaryNameNode
2012 DataNode
2169 JobTracker
报告输出:
![]()
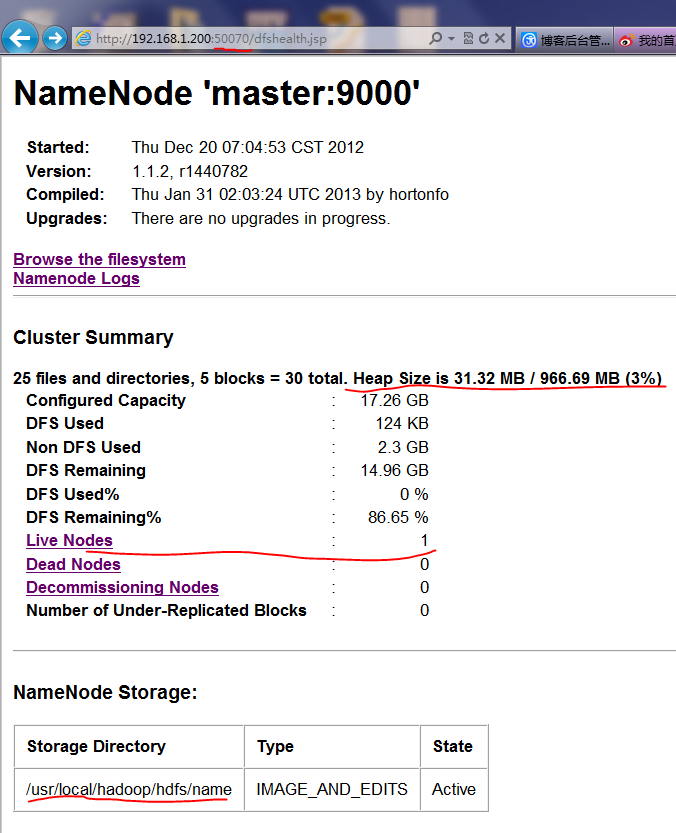
HDFS管理界面:
![]()
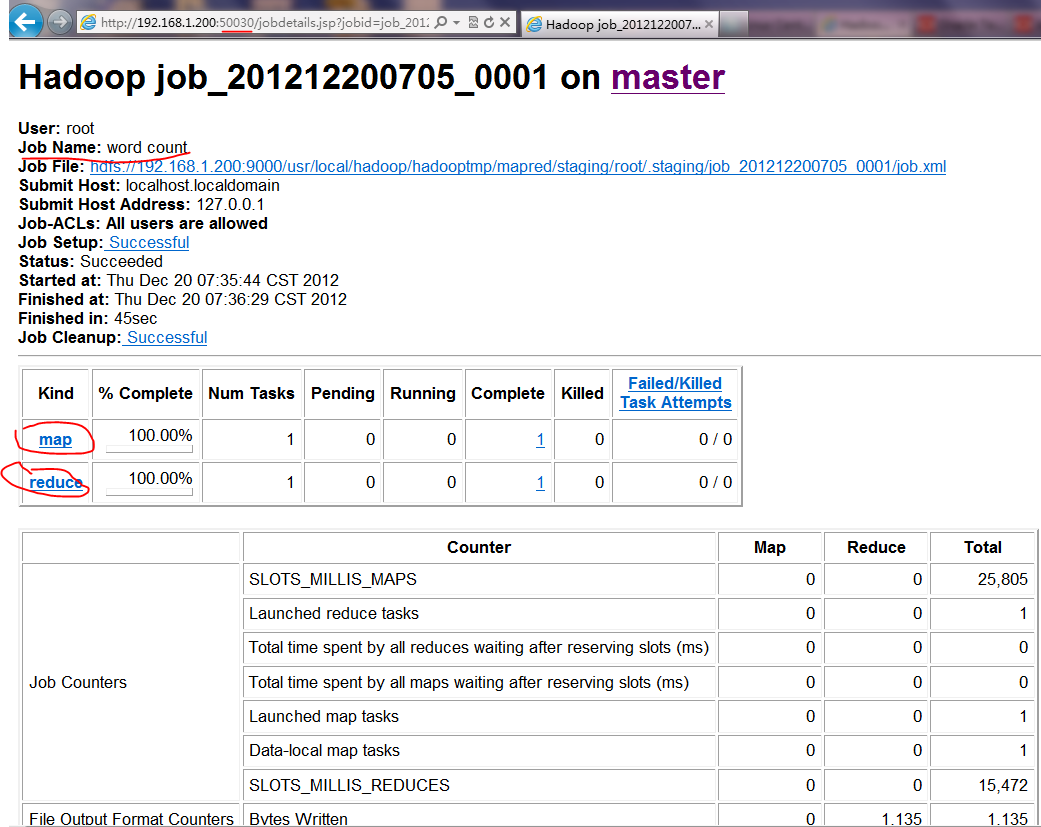
WORDCOUNT的JOB测试样例运行:
]# ./hadoop jar hadoop-examples-1.1.2.jar wordcount bxy output
Exception in thread "main" java.io.IOException: Error opening job jar: hadoop-examples-1.1.2.jar
at org.apache.hadoop.util.RunJar.main(RunJar.java:90)
Caused by: java.io.FileNotFoundException: hadoop-examples-1.1.2.jar (No such file or directory)
at java.util.zip.ZipFile.open(Native Method)
at java.util.zip.ZipFile.<init>(ZipFile.java:214)
at java.util.zip.ZipFile.<init>(ZipFile.java:144)
at java.util.jar.JarFile.<init>(JarFile.java:153)
at java.util.jar.JarFile.<init>(JarFile.java:90)
at org.apache.hadoop.util.RunJar.main(RunJar.java:88)
[root@localhost bin]# pwd
/usr/local/hadoop/hadoop-1.1.2/bin
[root@localhost bin]# ./hadoop jar /usr/local/hadoop/hadoop-1.1.2/hadoop-examples-1.1.2.jar wordcount bxy output
12/12/20 07:35:43 INFO input.FileInputFormat: Total input paths to process : 1
12/12/20 07:35:43 INFO util.NativeCodeLoader: Loaded the native-hadoop library
12/12/20 07:35:43 WARN snappy.LoadSnappy: Snappy native library not loaded
12/12/20 07:35:45 INFO mapred.JobClient: Running job: job_201212200705_0001
12/12/20 07:35:46 INFO mapred.JobClient: map 0% reduce 0%
12/12/20 07:36:10 INFO mapred.JobClient: map 100% reduce 0%
12/12/20 07:36:26 INFO mapred.JobClient: map 100% reduce 100%
12/12/20 07:36:30 INFO mapred.JobClient: Job complete: job_201212200705_0001
12/12/20 07:36:30 INFO mapred.JobClient: Counters: 29
12/12/20 07:36:30 INFO mapred.JobClient: Job Counters
12/12/20 07:36:30 INFO mapred.JobClient: Launched reduce tasks=1
12/12/20 07:36:30 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=25805
12/12/20 07:36:30 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
12/12/20 07:36:30 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
12/12/20 07:36:30 INFO mapred.JobClient: Launched map tasks=1
12/12/20 07:36:30 INFO mapred.JobClient: Data-local map tasks=1
12/12/20 07:36:30 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=15472
12/12/20 07:36:30 INFO mapred.JobClient: File Output Format Counters
12/12/20 07:36:30 INFO mapred.JobClient: Bytes Written=1135
12/12/20 07:36:30 INFO mapred.JobClient: FileSystemCounters
12/12/20 07:36:30 INFO mapred.JobClient: FILE_BYTES_READ=1600
12/12/20 07:36:30 INFO mapred.JobClient: HDFS_BYTES_READ=1280
12/12/20 07:36:30 INFO mapred.JobClient: FILE_BYTES_WRITTEN=105526
12/12/20 07:36:30 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=1135
12/12/20 07:36:30 INFO mapred.JobClient: File Input Format Counters
12/12/20 07:36:30 INFO mapred.JobClient: Bytes Read=1166
12/12/20 07:36:30 INFO mapred.JobClient: Map-Reduce Framework
12/12/20 07:36:30 INFO mapred.JobClient: Map output materialized bytes=1600
12/12/20 07:36:30 INFO mapred.JobClient: Map input records=34
12/12/20 07:36:30 INFO mapred.JobClient: Reduce shuffle bytes=1600
12/12/20 07:36:30 INFO mapred.JobClient: Spilled Records=230
12/12/20 07:36:30 INFO mapred.JobClient: Map output bytes=1824
12/12/20 07:36:30 INFO mapred.JobClient: Total committed heap usage (bytes)=131665920
12/12/20 07:36:30 INFO mapred.JobClient: CPU time spent (ms)=8970
12/12/20 07:36:30 INFO mapred.JobClient: Combine input records=169
12/12/20 07:36:30 INFO mapred.JobClient: SPLIT_RAW_BYTES=114
12/12/20 07:36:30 INFO mapred.JobClient: Reduce input records=115
12/12/20 07:36:30 INFO mapred.JobClient: Reduce input groups=115
12/12/20 07:36:30 INFO mapred.JobClient: Combine output records=115
12/12/20 07:36:30 INFO mapred.JobClient: Physical memory (bytes) snapshot=187215872
12/12/20 07:36:30 INFO mapred.JobClient: Reduce output records=115
12/12/20 07:36:30 INFO mapred.JobClient: Virtual memory (bytes) snapshot=755154944
12/12/20 07:36:30 INFO mapred.JobClient: Map output records=169
![]()