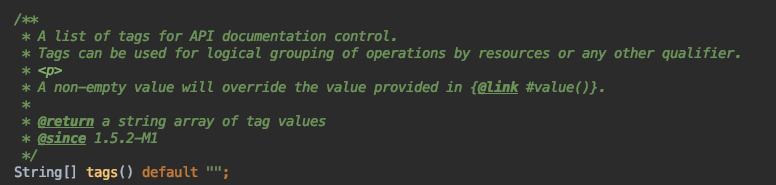
之前通过Spring Boot 2.x基础教程:使用Swagger2构建强大的API文档一文,我们学习了如何使用Swagger为Spring Boot项目自动生成API文档,有不少用户留言问了关于文档内容的组织以及排序问题。所以,就特别开一篇详细说说Swagger中文档内容如何来组织以及其中各个元素如何控制前后顺序的具体配置方法。
接口的分组
我们在Spring Boot中定义各个接口是以Controller作为第一级维度来进行组织的,Controller与具体接口之间的关系是一对多的关系。我们可以将同属一个模块的接口定义在一个Controller里。默认情况下,Swagger是以Controller为单位,对接口进行分组管理的。这个分组的元素在Swagger中称为Tag,但是这里的Tag与接口的关系并不是一对多的,它支持更丰富的多对多关系。
默认分组
首先,我们通过一个简单的例子,来看一下默认情况,Swagger是如何根据Controller来组织Tag与接口关系的。定义两个Controller,分别负责教师管理与学生管理接口,比如下面这样:
@RestController
@RequestMapping(value = "/teacher")
static class TeacherController {
@GetMapping("/xxx")
public String xxx() {
return "xxx";
}
}
@RestController
@RequestMapping(value = "/student")
static class StudentController {
@ApiOperation("获取学生清单")
@GetMapping("/list")
public String bbb() {
return "bbb";
}
@ApiOperation("获取教某个学生的老师清单")
@GetMapping("/his-teachers")
public String ccc() {
return "ccc";
}
@ApiOperation("创建一个学生")
@PostMapping("/aaa")
public String aaa() {
return "aaa";
}
}
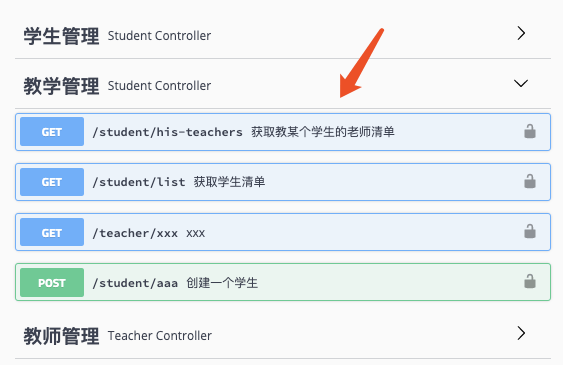
启动应用之后,我们可以看到Swagger中这两个Controller是这样组织的:
![]()
图中标出了Swagger默认生成的Tag与Spring Boot中Controller展示的内容与位置。
自定义默认分组的名称
接着,我们可以再试一下,通过@Api注解来自定义Tag,比如这样:
@Api(tags = "教师管理")
@RestController
@RequestMapping(value = "/teacher")
static class TeacherController {
// ...
}
@Api(tags = "学生管理")
@RestController
@RequestMapping(value = "/student")
static class StudentController {
// ...
}
再次启动应用之后,我们就看到了如下的分组内容,代码中@Api定义的tags内容替代了默认产生的teacher-controller和student-controller。
![]()
合并Controller分组
到这里,我们还都只是使用了Tag与Controller一一对应的情况,Swagger中还支持更灵活的分组!从@Api注解的属性中,相信聪明的读者一定已经发现tags属性其实是个数组类型:
![]()
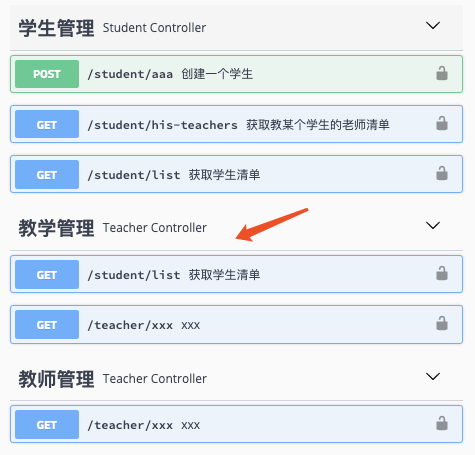
我们可以通过定义同名的Tag来汇总Controller中的接口,比如我们可以定义一个Tag为“教学管理”,让这个分组同时包含教师管理和学生管理的所有接口,可以这样来实现:
@Api(tags = {"教师管理", "教学管理"})
@RestController
@RequestMapping(value = "/teacher")
static class TeacherController {
// ...
}
@Api(tags = {"学生管理", "教学管理"})
@RestController
@RequestMapping(value = "/student")
static class StudentController {
// ...
}
最终效果如下:
![]()
更细粒度的接口分组
通过@Api可以实现将Controller中的接口合并到一个Tag中,但是如果我们希望精确到某个接口的合并呢?比如这样的需求:“教学管理”包含“教师管理”中所有接口以及“学生管理”管理中的“获取学生清单”接口(不是全部接口)。
那么上面的实现方式就无法满足了。这时候发,我们可以通过使用@ApiOperation注解中的tags属性做更细粒度的接口分类定义,比如上面的需求就可以这样子写:
@Api(tags = {"教师管理","教学管理"})
@RestController
@RequestMapping(value = "/teacher")
static class TeacherController {
@ApiOperation(value = "xxx")
@GetMapping("/xxx")
public String xxx() {
return "xxx";
}
}
@Api(tags = {"学生管理"})
@RestController
@RequestMapping(value = "/student")
static class StudentController {
@ApiOperation(value = "获取学生清单", tags = "教学管理")
@GetMapping("/list")
public String bbb() {
return "bbb";
}
@ApiOperation("获取教某个学生的老师清单")
@GetMapping("/his-teachers")
public String ccc() {
return "ccc";
}
@ApiOperation("创建一个学生")
@PostMapping("/aaa")
public String aaa() {
return "aaa";
}
}
效果如下图所示:
![]()
内容的顺序
在完成了接口分组之后,对于接口内容的展现顺序又是众多用户特别关注的点,其中主要涉及三个方面:分组的排序、接口的排序以及参数的排序,下面我们就来逐个说说如何配置与使用。
分组的排序
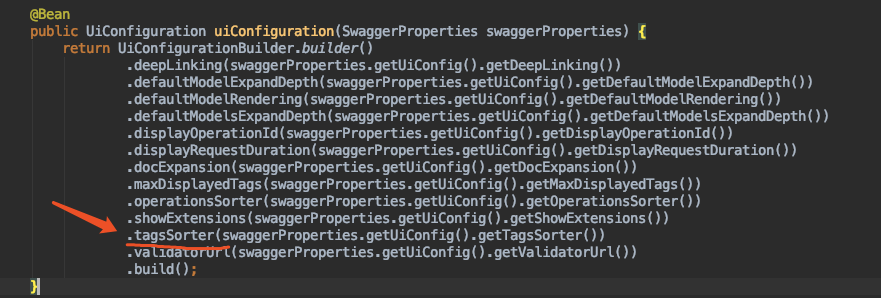
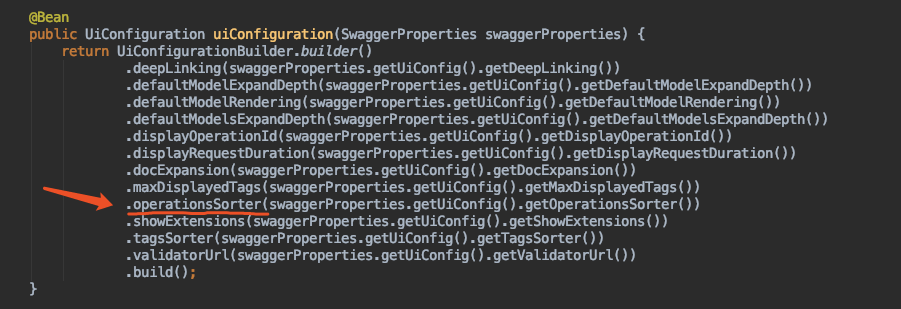
关于分组排序,也就是Tag的排序。目前版本的Swagger支持并不太好,通过文档我们可以找到关于Tag排序的配置方法。
第一种:原生Swagger用户,可以通过如下方式:
![file]()
第二种:Swagger Starter用户,可以通过修改配置的方式:
swagger.ui-config.tags-sorter=alpha
似乎找到了希望,但是其实这块并没有什么可选项,一看源码便知:
public enum TagsSorter {
ALPHA("alpha");
private final String value;
TagsSorter(String value) {
this.value = value;
}
@JsonValue
public String getValue() {
return value;
}
public static TagsSorter of(String name) {
for (TagsSorter tagsSorter : TagsSorter.values()) {
if (tagsSorter.value.equals(name)) {
return tagsSorter;
}
}
return null;
}
}
是的,Swagger只提供了一个选项,就是按字母顺序排列。那么我们要如何实现排序呢?这里笔者给一个不需要扩展源码,仅依靠使用方式的定义来实现排序的建议:为Tag的命名做编号。比如:
@Api(tags = {"1-教师管理","3-教学管理"})
@RestController
@RequestMapping(value = "/teacher")
static class TeacherController {
// ...
}
@Api(tags = {"2-学生管理"})
@RestController
@RequestMapping(value = "/student")
static class StudentController {
@ApiOperation(value = "获取学生清单", tags = "3-教学管理")
@GetMapping("/list")
public String bbb() {
return "bbb";
}
// ...
}
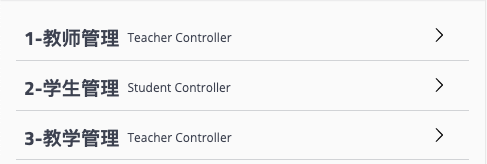
由于原本存在按字母排序的机制在,通过命名中增加数字来帮助排序,可以简单而粗暴的解决分组问题,最后效果如下:
![]()
接口的排序
在完成了分组排序问题(虽然不太优雅...)之后,在来看看同一分组内各个接口该如何实现排序。同样的,凡事先查文档,可以看到Swagger也提供了相应的配置,下面也分两种配置方式介绍:
第一种:原生Swagger用户,可以通过如下方式:
![]()
第二种:Swagger Starter用户,可以通过修改配置的方式:
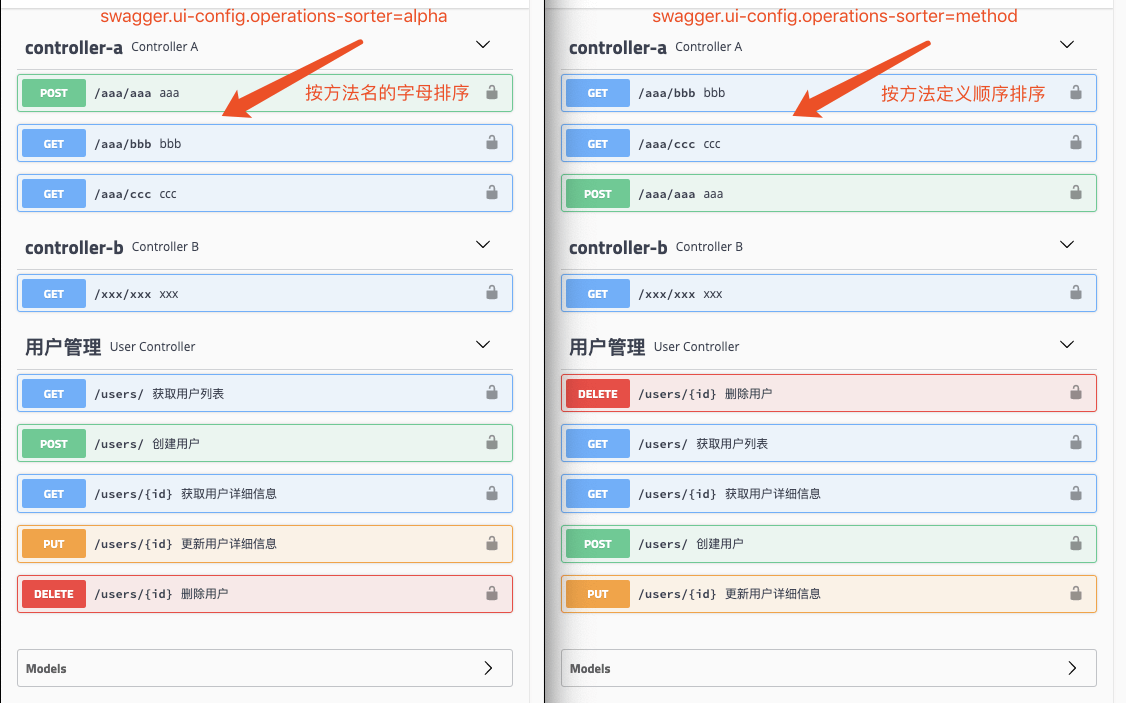
swagger.ui-config.operations-sorter=alpha
很庆幸,这个配置不像Tag的排序配置没有可选项。它提供了两个配置项:alpha和method,分别代表了按字母表排序以及按方法定义顺序排序。当我们不配置的时候,改配置默认为alpha。两种配置的效果对比如下图所示:
![]()
参数的排序
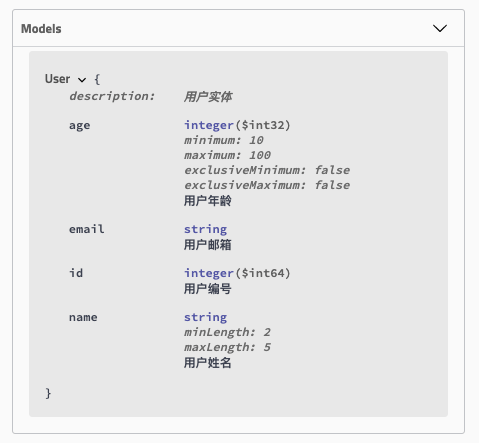
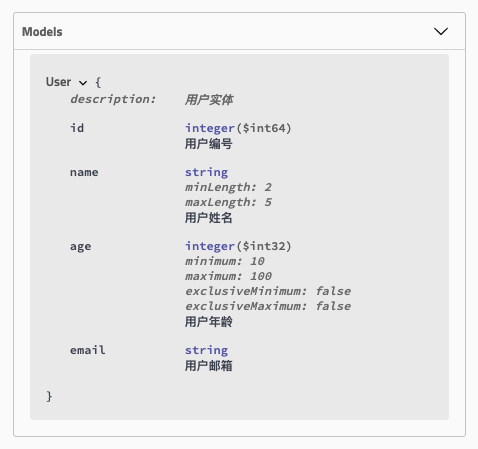
完成了接口的排序之后,更细粒度的就是请求参数的排序了。默认情况下,Swagger对Model参数内容的展现也是按字母顺序排列的。所以之前教程中的User对象在文章中展现如下:
![]()
如果我们希望可以按照Model中定义的成员变量顺序来展现,那么需要我们通过@ApiModelProperty注解的position参数来实现位置的设置,比如:
@Data
@ApiModel(description = "用户实体")
public class User {
@ApiModelProperty(value = "用户编号", position = 1)
private Long id;
@NotNull
@Size(min = 2, max = 5)
@ApiModelProperty(value = "用户姓名", position = 2)
private String name;
@NotNull
@Max(100)
@Min(10)
@ApiModelProperty(value = "用户年龄", position = 3)
private Integer age;
@NotNull
@Email
@ApiModelProperty(value = "用户邮箱", position = 4)
private String email;
}
最终效果如下:
![]()
小结
本文详细的介绍了Swagger中对接口内容的组织控制。有些问题并没有通过配置来解决,也可能是对文档或源码内容的了解不够深入。如果读者有更好的实现方案,欢迎提出与交流。
代码示例
本文的完整工程可以查看下面仓库中的chapter2-4目录:
如果您觉得本文不错,欢迎Star支持,您的关注是我坚持的动力!
相关资料
> 欢迎关注我的公众号:程序猿DD,获得独家整理的学习资源和日常干货推送。 > 如果您对我的专题内容感兴趣,也可以关注我的博客:didispace.com