环境声明:
Gradle + Docker + Spring Boot 2.1.5.RELEASE
目的
利用docker容器技术简化项目部署
配置Docker服务(Ubuntu)
卸载旧版本docker(全新安装时,无需执行该步骤)
sudo apt-get remove docker docker-engine docker.io
更新系统软件
sudo apt-get update
安装依赖包
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
添加官方密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
如果出现‘sudo: unable to resolve host {你的主机名}’,需要编辑你的hosts文件
vim /etc/hosts
127.0.0.1 localhost
# 添加下边这行
127.0.0.1 {你的主机名}
添加仓库
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
再次更新软件
sudo apt-get update
安装
apt-get install docker-ce
修改源
vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://kv3qfp85.mirror.aliyuncs.com"
]
}
开放远程 2375 端口访问
vim /lib/systemd/system/docker.service
修改如下内容
#ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
systemctl daemon-reload
sudo service docker restart
![]()
开发环境配置
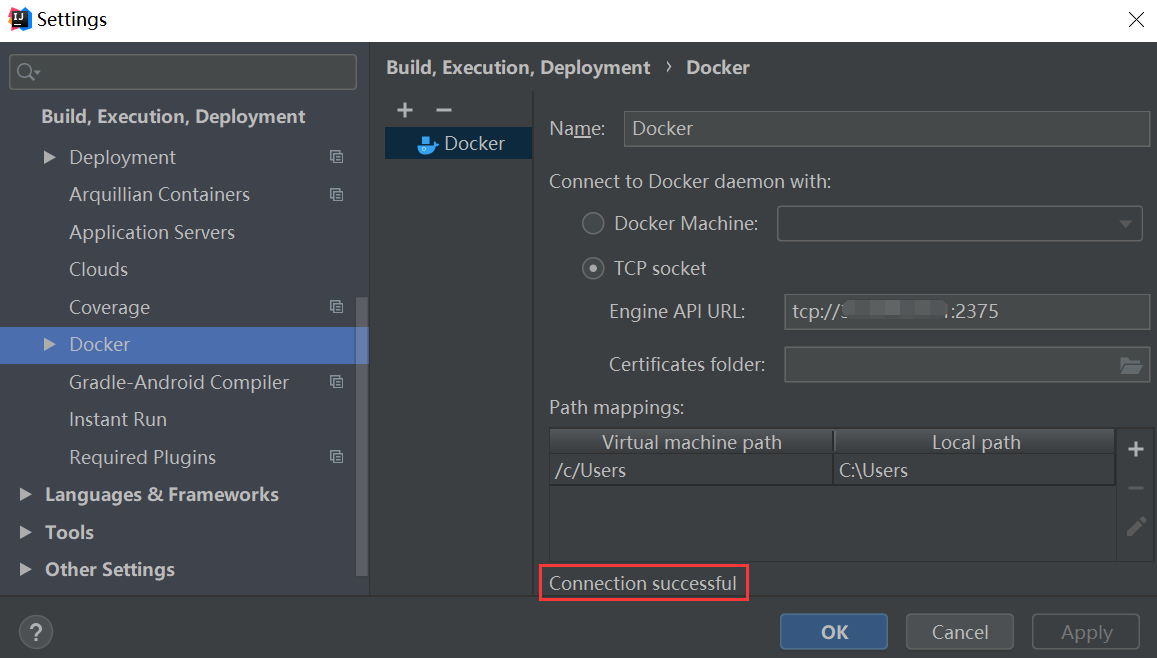
idea连接远程Docker
![]()
构建镜像
- gradle配置,增加 gradle 的 Docker 插件
parent build.gradle
......
buildscript {
......
dependencies {
......
classpath('gradle.plugin.com.palantir.gradle.docker:gradle-docker:0.19.2')
}
}
......
subprojects {
......
apply plugin: 'application'
apply plugin: 'com.palantir.docker'
......
jar {
enabled = true
}
bootJar {
classifier = 'boot'
}
}
FROM openjdk:8-jdk-alpine
VOLUME /tmp
ADD build/libs/*-boot.jar app.jar
RUN sh -c 'touch /app.jar'
ENV JAVA_OPTS=""
ENTRYPOINT [ "sh", "-c", "java $JAVA_OPTS -Djava.security.egd=file:/dev/./urandom -jar /app.jar" ]
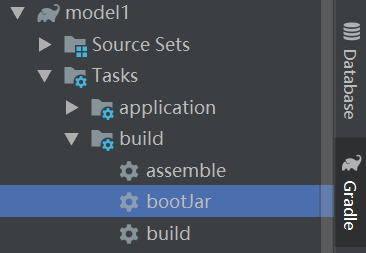
- 构建可运行jar包,打好的包在build-libs目录内*-boot.jar
![]()
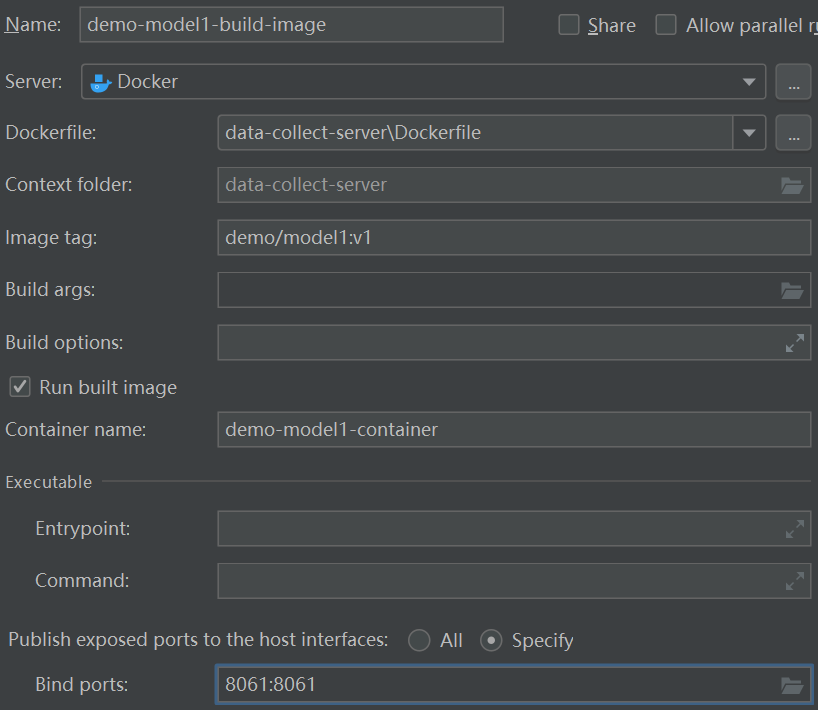
为了方便查看(当然不这样做也是可以的),假设我的项目是多模块架构,项目名为 demo,现在为我的子模块model1构建和部署镜像
![]()
![]()
最下边Command preview也就是原生的Docker构建镜像的命令:
docker build -t demo/model1:v1 . && docker run -p 8061:8061 --name demo-model1-container demo/model1:v1
run it (莫慌,骚微一等)
![]()
Deploy log:
Deploying 'demo-model1-container Dockerfile: model1/Dockerfile'...
Building image...
Step 1/6 : FROM openjdk:8-jdk-alpine
---> a3562aa0b991
Step 2/6 : VOLUME /tmp
---> Using cache
---> 0ccc6c4dcc3f
Step 3/6 : ADD build/libs/*-boot.jar app.jar
---> Using cache
---> 999503a5bf26
Step 4/6 : RUN sh -c 'touch /app.jar'
---> Using cache
---> d99dd527cb5b
Step 5/6 : ENV JAVA_OPTS=""
---> Using cache
---> 468e80ce7f62
Step 6/6 : ENTRYPOINT [ "sh", "-c", "java $JAVA_OPTS -Djava.security.egd=file:/dev/./urandom -jar /app.jar" ]
---> Using cache
---> d8d32a964e71
Successfully built d8d32a964e71
Successfully tagged demo/model1:v1
Creating container...
Container Id: 0f91b3f38e771cb1288fb7b01451aeeef917d83f4f2fbe803a65a091684a7430
Container name: 'demo-model1-container'
Attaching to container 'demo-model1-container'...
Starting container 'demo-model1-container'
Failed to deploy 'demo-model1-container Dockerfile: data-collect-server/Dockerfile': com.github.dockerjava.api.exception.InternalServerErrorException: {"message":"driver failed programming external connectivity on endpoint demo-model1-container (10fcfb5d05feffb40b75715b531c7504a8ee7262c2af43b642d2202e9e3f4b31): Bind for 0.0.0.0:8061 failed: port is already allocated"}
![]()
启动成功,访问测试
![]()
![]()
示例项目:gradle-docker