1 概述
1.1 案例介绍
仓颉编程语言作为一款面向全场景应用开发的现代编程语言,通过现代语言特性的集成、全方位的编译优化和运行时实现、以及开箱即用的 IDE工具链支持,为开发者打造友好开发体验和卓越程序性能。
案例结合代码体验,让大家更直观的了解仓颉语言中的IO操作。
1.2 适用对象
1.3 案例时间
本案例总时长预计40分钟。
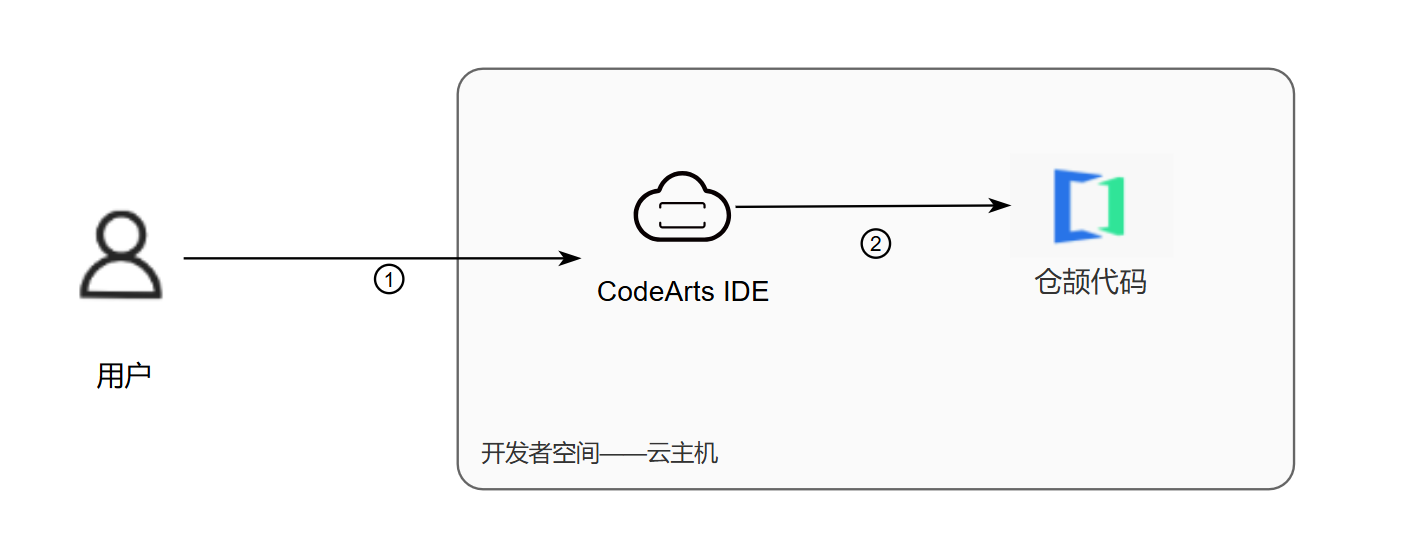
1.4 案例流程
![abf6ec3409dff70ce74ed05ed269792a.png]()
说明:
- 进入华为开发者空间,登录云主机;
- 使用CodeArts IDE for Cangjie编程和运行仓颉代码。
1.5 资源总览
| 资源名称 |
规格 |
单价(元) |
时长(分钟) |
| 开发者空间 - 云主机 |
鲲鹏通用计算增强型 kc2 | 4vCPUs | 8G | Ubuntu |
免费 |
免费 |
40 |
2 运行测试环境准备
2.1 开发者空间配置
面向广大开发者群体,华为开发者空间提供一个随时访问的“开发桌面云主机”、丰富的“预配置工具集合”和灵活使用的“场景化资源池”,开发者开箱即用,快速体验华为根技术和资源。
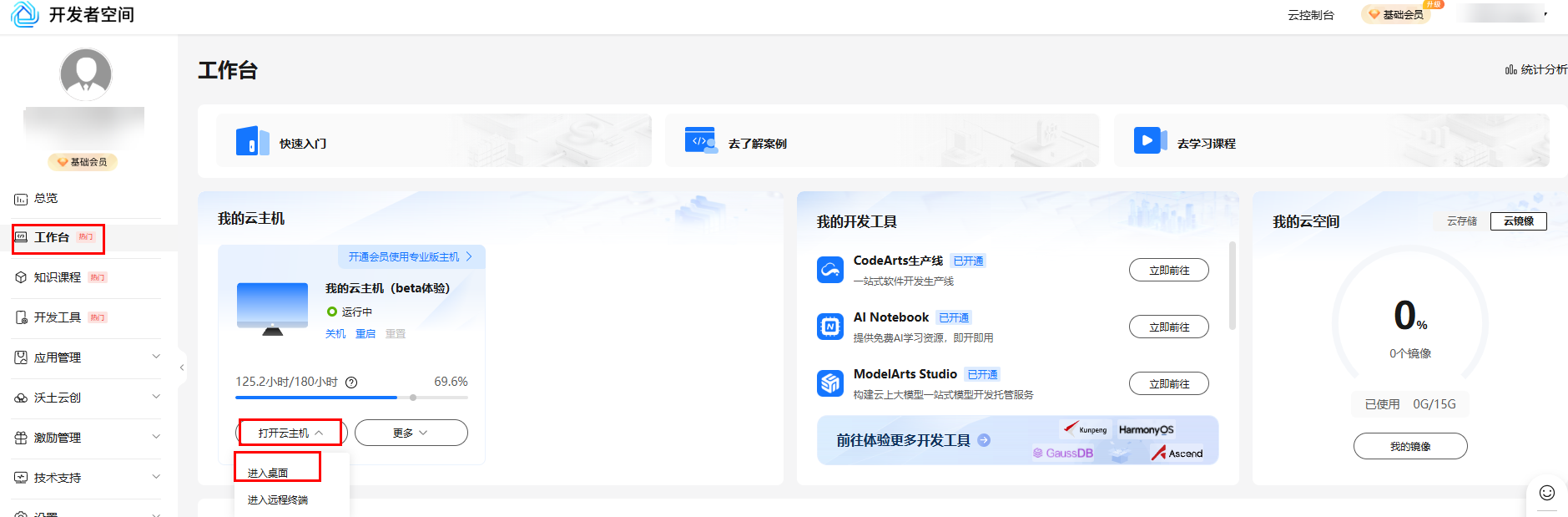
领取云主机后可以直接进入华为开发者空间工作台界面,点击打开云主机 > 进入桌面连接云主机。没有领取在开发者空间根据指引领取配置云主机即可,云主机配置参考1.5资源总览。
![a1aae6ff53aac98855ef597dd6899967.png]()
![552fc96c3b58a06e294e4a760ae719e3.PNG]()
2.2 创建仓颉程序
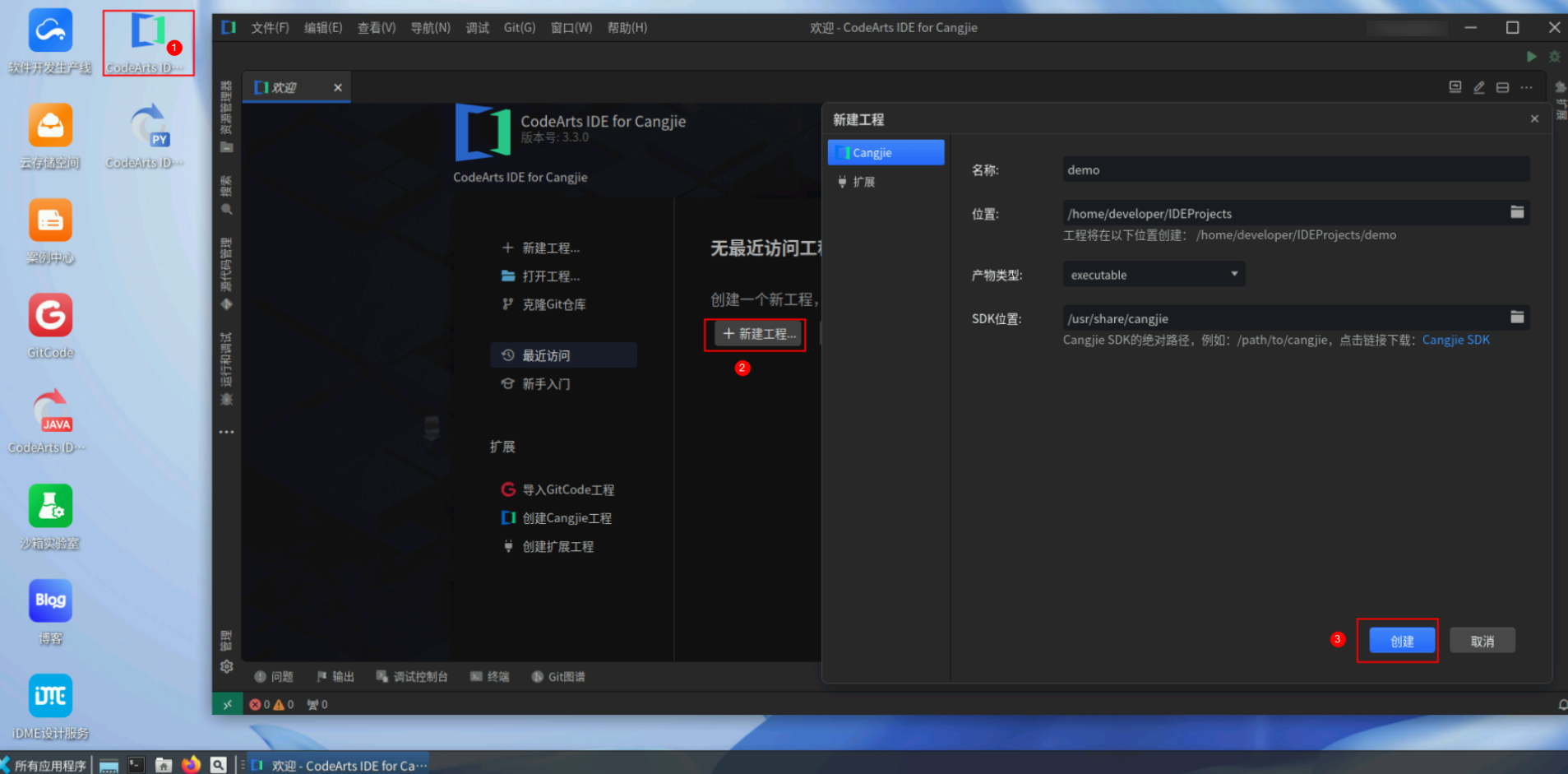
点击桌面CodeArts IDE for Cangjie,打开编辑器,点击新建工程,保持默认配置,点击创建。
产物类型说明:
- executable,可执行文件;
- static,静态库,是一组预先编译好的目标文件的集合;
- dynamic,动态库,是一种在程序运行时才被加载到内存中的库文件,多个程序共享一个动态库副本,而不是像静态库那样每个程序都包含一份完整的副本。
![28acbca9146a8a6aacbfdd4f6ac3791b.png]()
2.3 运行仓颉工程
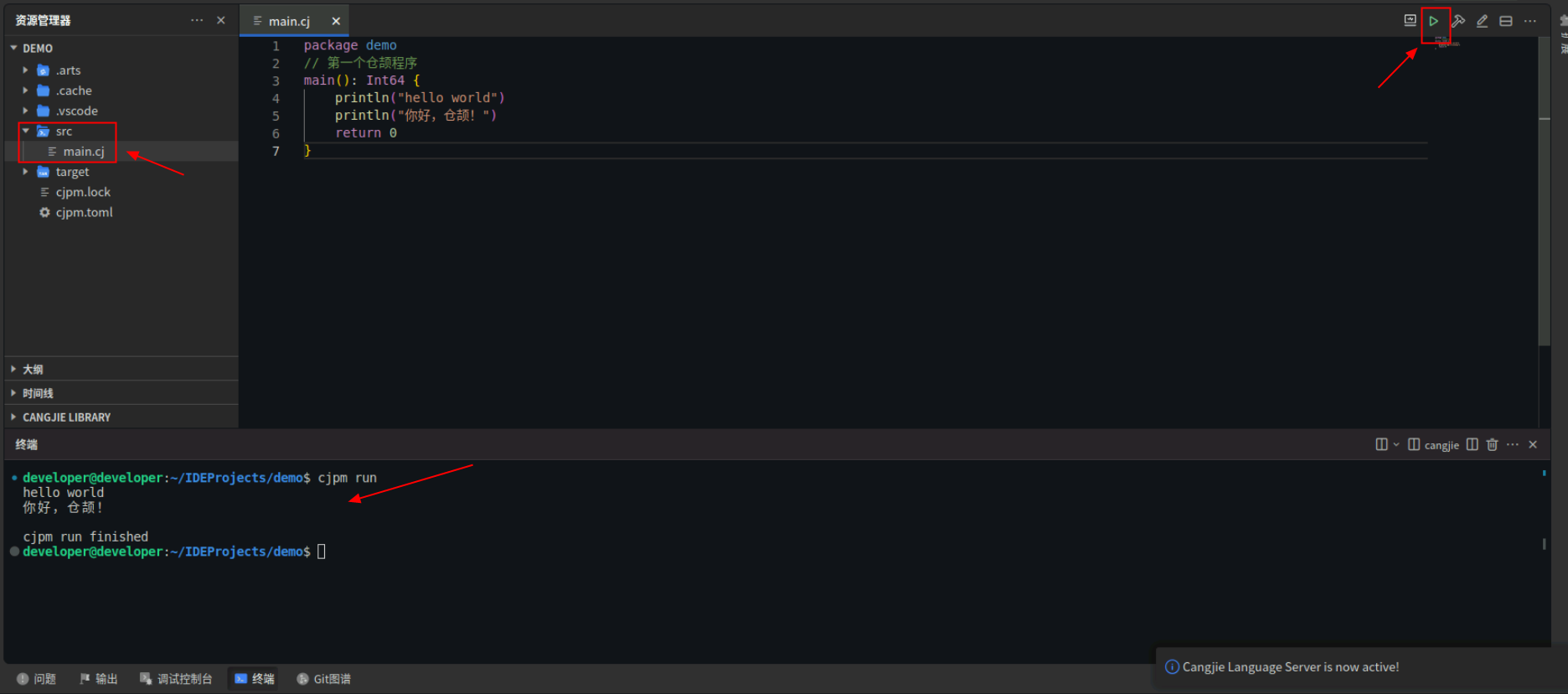
创建完成后,打开src/main.cj,参考下面代码简单修改后,点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
package demo
// 第一个仓颉程序
main(): Int64 {
println("hello world")
println("你好,仓颉!")
return 0
}
(* 注意:后续替换main.cj文件代码时,package demo保留)
(* 仓颉注释语法:// 符号之后写单行注释,也可以在一对 /* 和 */ 符号之间写多行注释)
![d1e16b48f5f9620fafe9fc59ae62a367.png]()
到这里,我们第一个仓颉程序就运行成功啦!后面案例中的示例代码都可以放到main.cj文件中进行执行,接下来我们继续探索仓颉语言。
3 仓颉I/O操作
3.1 I/O流概述
仓颉编程语言将与应用程序外部载体交互的操作称为 I/O 操作。I 对应输入(Input),O 对应输出(Output)。
仓颉编程语言将输入输出抽象为流(Stream)。Stream 主要面向处理原始二进制数据,Stream 中最小的数据单元是 Byte。
3.1.1 输入流
程序从输入流读取数据源(数据源包括外界的键盘、文件、网络等),即输入流是将数据源读入到程序的通信通道。
仓颉编程语言用 InputStream 接口类型来表示输入流,它提供了 read 函数,这个函数会将可读的数据写入到 buffer 中,返回值表示了该次读取的字节总数。
InputStream接口定义:
interface InputStream {
func read(buffer: Array<Byte>): Int64
}
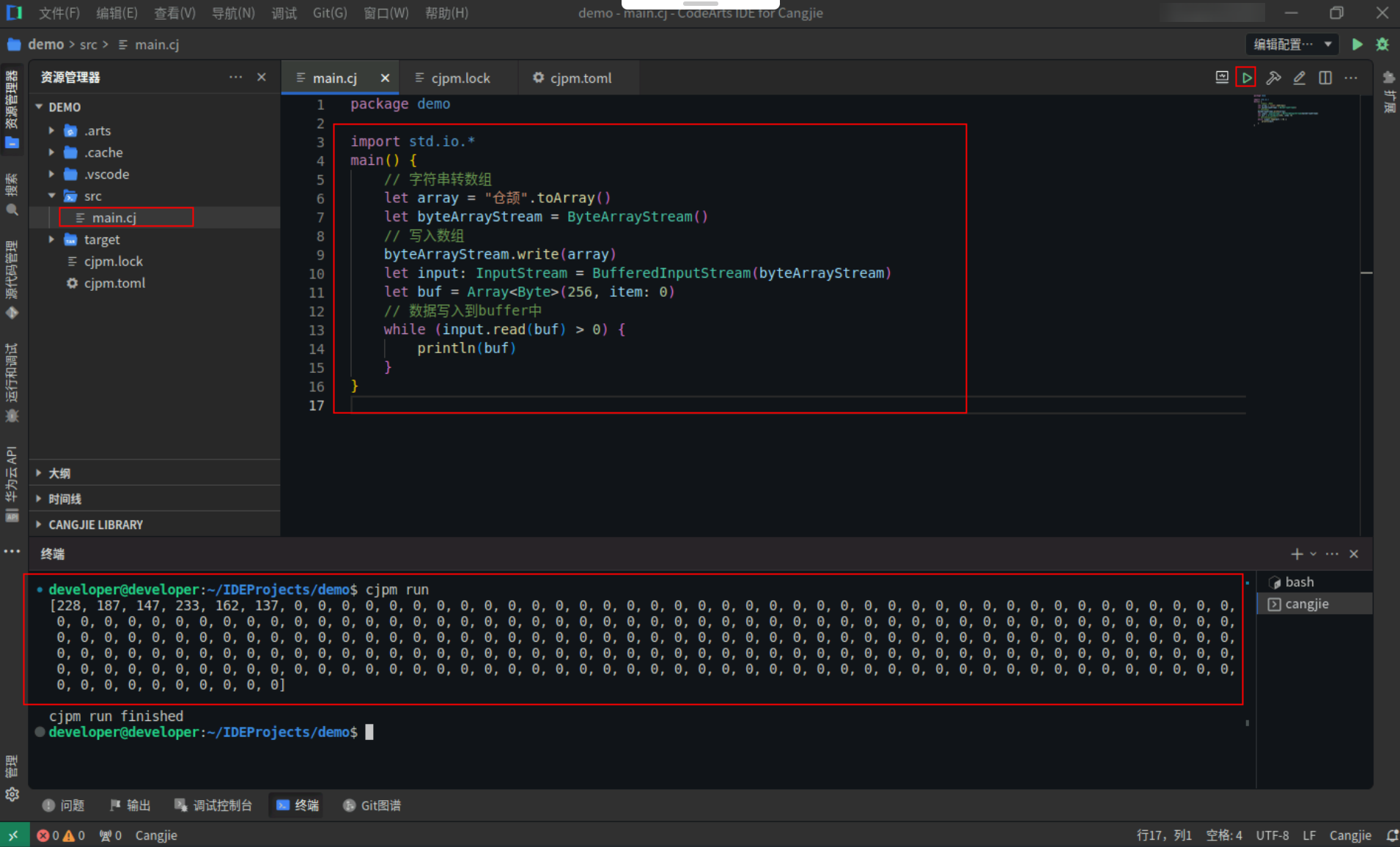
输入流读取示例,具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.io.*
main() {
// 字符串转数组
let array = "仓颉".toArray()
let byteArrayStream = ByteArrayStream()
// 写入数组
byteArrayStream.write(array)
let input: InputStream = BufferedInputStream(byteArrayStream)
let buf = Array<Byte>(256, item: 0)
// 数据写入到buffer中
while (input.read(buf) > 0) {
println(buf)
}
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![573ba57eff26222811ebcb40304064f6.PNG]()
3.1.2 输出流
程序向输出流写入数据。输出流是将程序中的数据输出到外界(显示器、打印机、文件、网络等)的通信通道。
仓颉编程语言用 OutputStream 接口类型来表示输出流,它提供了 write 函数,这个函数会将 buffer 中的数据写入到绑定的流中。
特别的,有一些输出流的 write 不会立即写到外存中,而是有一定的缓冲策略,只有当符合条件或主动调用 flush 时才会真实写入,目的是提高性能。
OutputStream 接口定义:
interface OutputStream {
func write(buffer: Array<Byte>): Unit
func flush(): Unit {
// 空实现
}
}
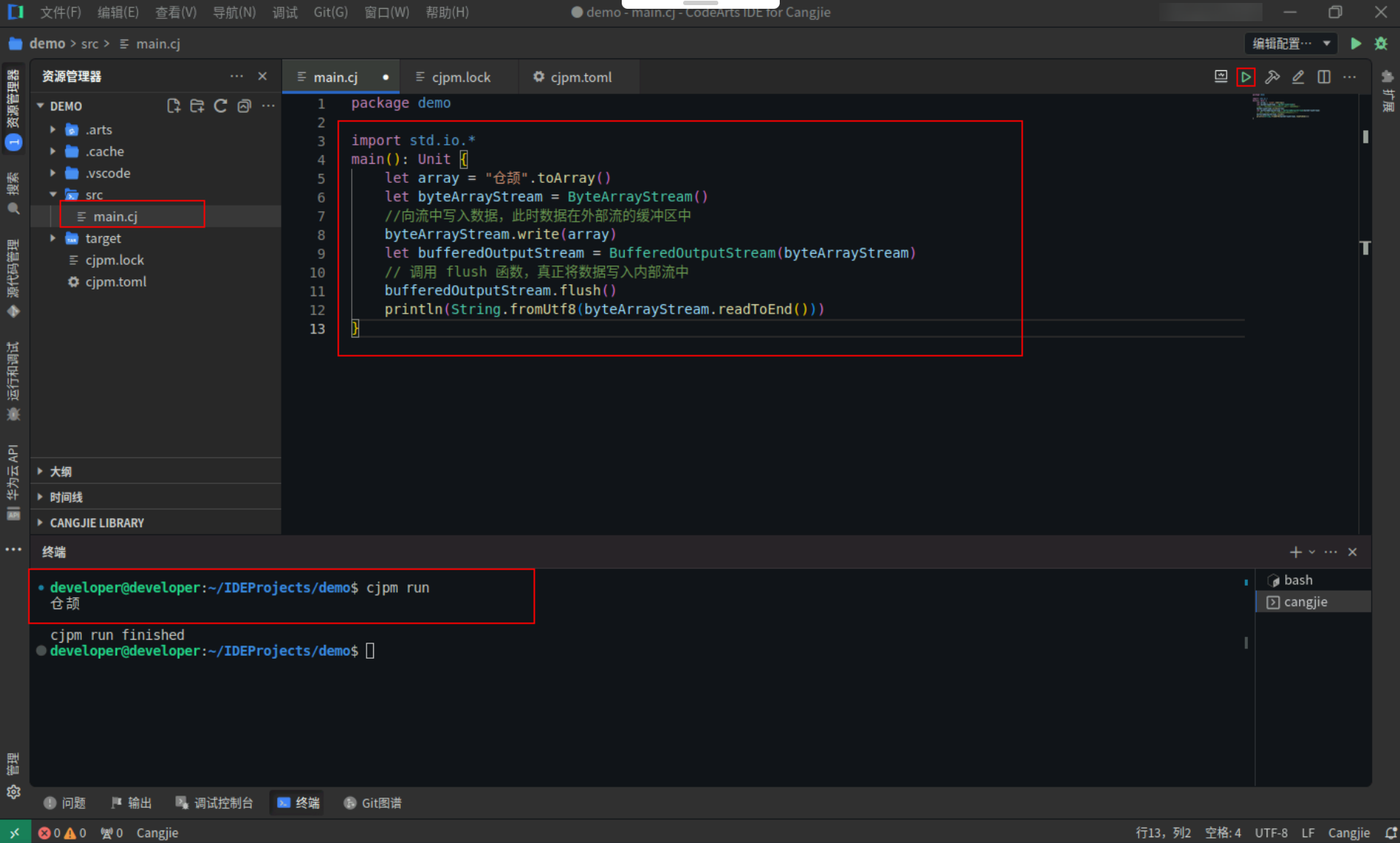
输出流读取示例,具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.io.*
main(): Unit {
let array = "仓颉".toArray()
let byteArrayStream = ByteArrayStream()
//向流中写入数据,此时数据在外部流的缓冲区中
byteArrayStream.write(array)
let bufferedOutputStream = BufferedOutputStream(byteArrayStream)
// 调用 flush 函数,真正将数据写入内部流中
bufferedOutputStream.flush()
println(String.fromUtf8(byteArrayStream.readToEnd()))
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![fba2f374e097ccb87ccb04c265e44c62.PNG]()
3.1.3 数据流分类
按照数据流职责上的差异,可以将 Stream 简单分成两类:
节点流:直接提供数据源,构造方式通常是依赖某种直接的外部资源(即文件、网络等)。
处理流:只能代理其它数据流进行处理,处理流的构造方式通常是依赖其它的流。
3.2 I/O节点流
什么是节点流?
节点流是指直接提供数据源的流,它的构造方式通常是依赖某种直接的外部资源(即文件、网络等)。节点流包括:标准流(StdIn、StdOut、StdErr)、文件流(File)、网络流(Socket)等。
3.2.1 标准流
标准流包含了标准输入流(stdin)、标准输出流(stdout)和标准错误输出流(stderr)。
在仓颉编程语言中可以使用 Console 类型来访问标准流。
使用 Console 类型需要导入 console 包:
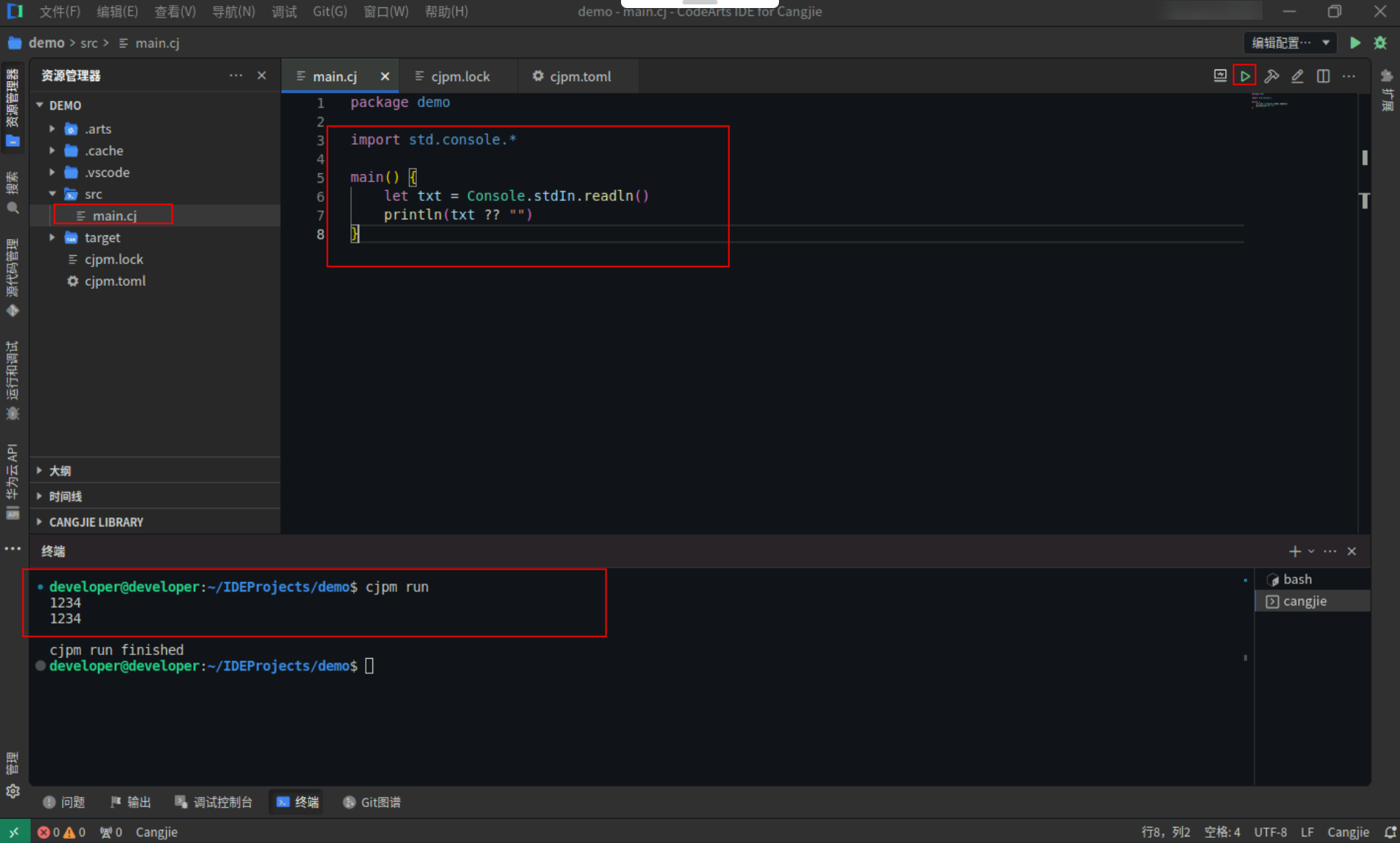
标准输入流读取示例,具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.console.*
main() {
let txt = Console.stdIn.readln()
println(txt ?? "")
}
Step2:点击编辑器右上角运行按钮运行代码,在命令行上输入内容“1234”,然后换行结束,即可看到输入的内容。
![1738ab9e44881dfe94201fb6ccb5a095.PNG]()
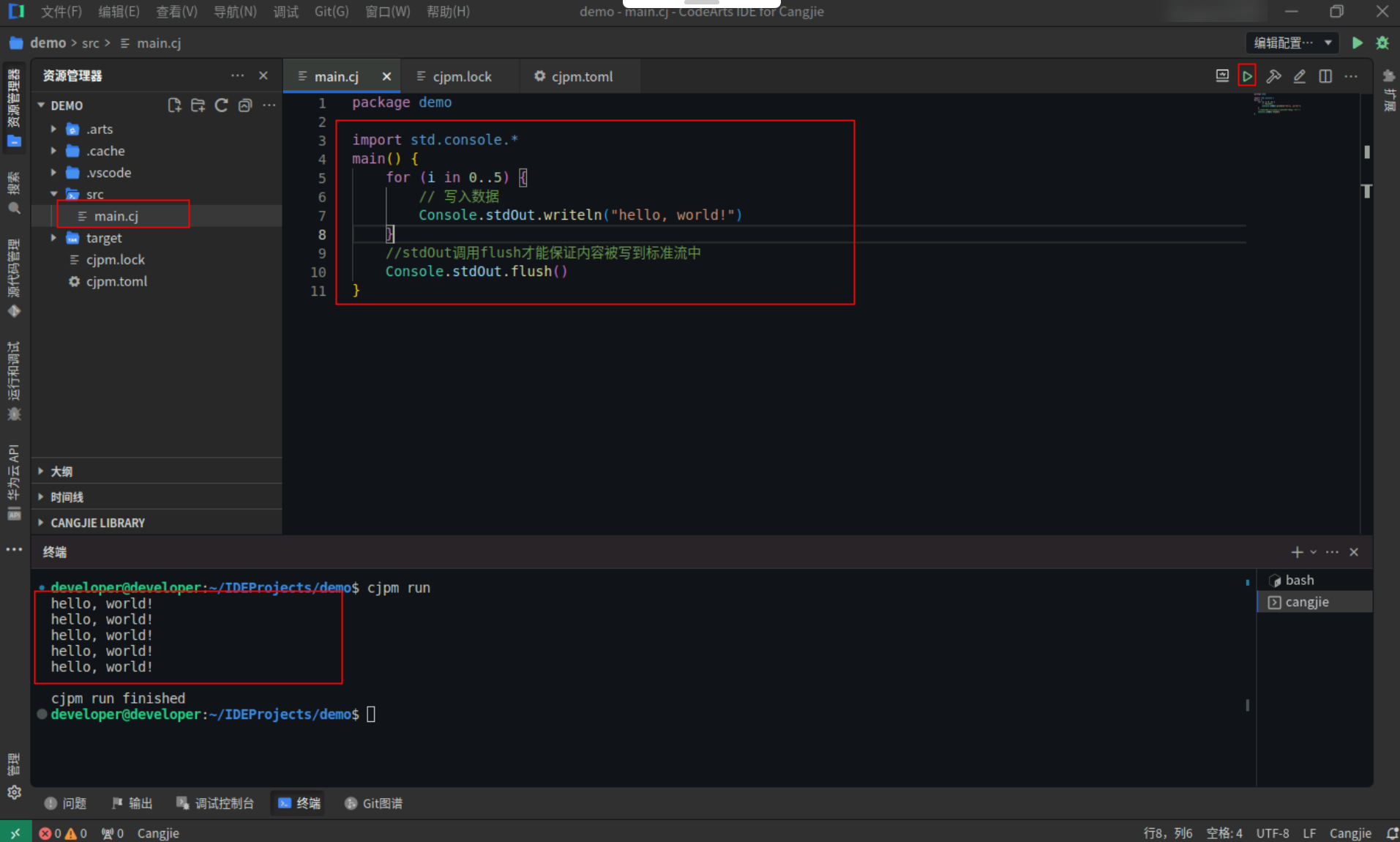
标准输出流写入示例,具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.console.*
main() {
for (i in 0..5) {
// 写入数据
Console.stdOut.writeln("hello, world!")
}
//stdOut调用flush才能保证内容被写到标准流中
Console.stdOut.flush()
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![2cb4fa1eeac00524a867bfd66ef768c3.PNG]()
3.2.1 文件流
仓颉编程语言提供了 fs 包来支持通用文件系统任务。常规操作任务包括:创建文件/目录、读写文件、重命名或移动文件/目录、删除文件/目录、复制文件/目录、获取文件/目录元数据、检查文件/目录是否存在。
使用文件系统相关的功能需要导入 fs 包:
本节会着重介绍File相关的使用,File 类型在仓颉编程语言中同时提供了常规文件操作和文件流两类功能。
常规文件操作:
如果要检查某个路径对应的文件是否存在,可以使用 exists 函数。
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.fs.*
main() {
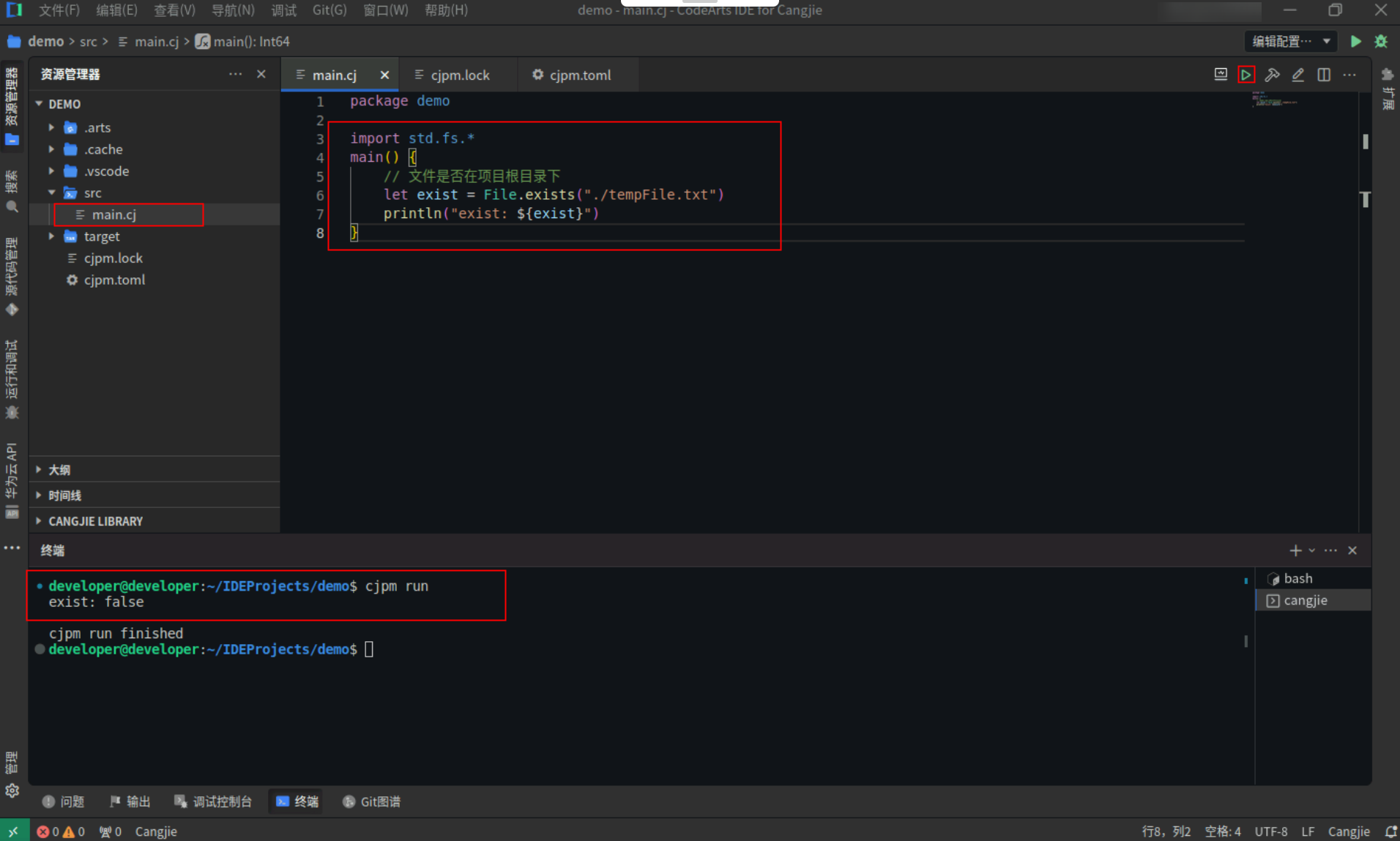
// 文件是否在项目根目录下
let exist = File.exists("./tempFile.txt")
println("exist: ${exist}")
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![ef3c513e23888f987539c4ec0433be16.PNG]()
拷贝文件,使用copy函数,具体代码操作如下:
Step1:在项目根目录下新建文本文件:tempFile.txt。
![81eaa5b6e3434a934a2af9b77f22dfe7.PNG]()
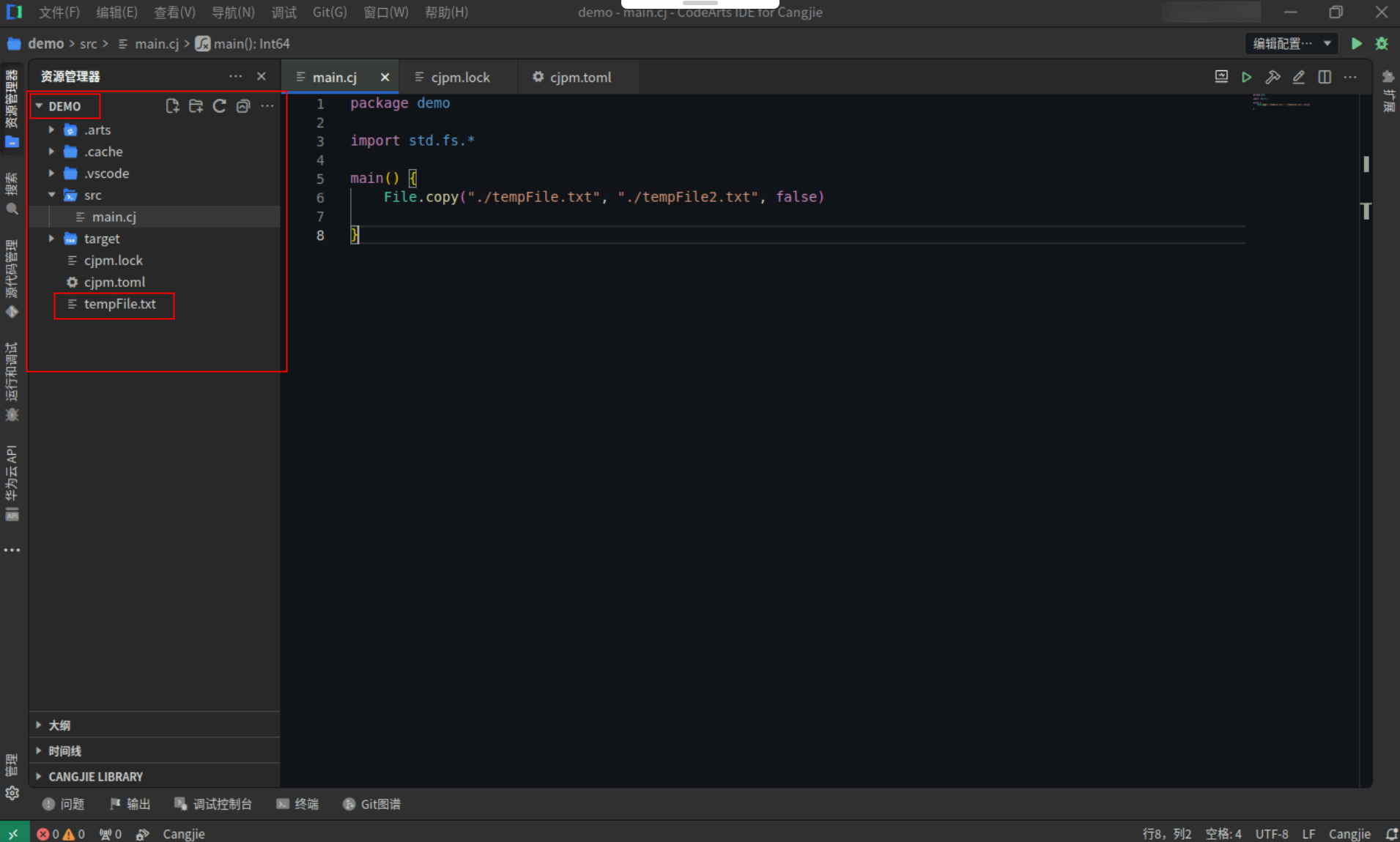
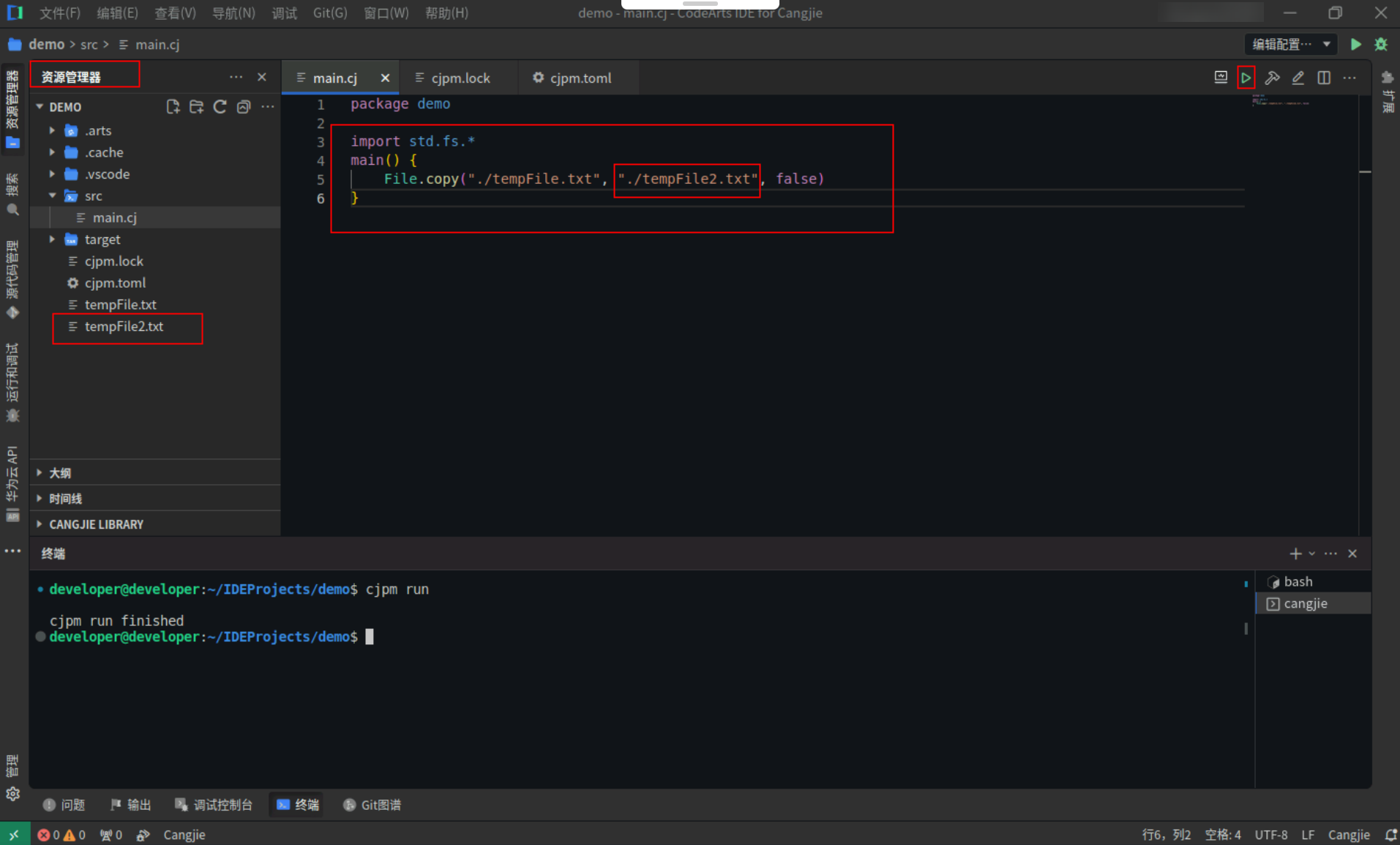
Step2:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.fs.*
main() {
File.copy("./tempFile.txt", "./tempFile2.txt", false)
}
Step3:点击编辑器右上角运行按钮直接运行,资源管理器->项目根目录下复制了新的文件。
![efee0787700ac3ebe34e4c1b7e71c93a.PNG]()
移动文件、删除文件,使用move函数和delete函数。
具体代码操作如下:
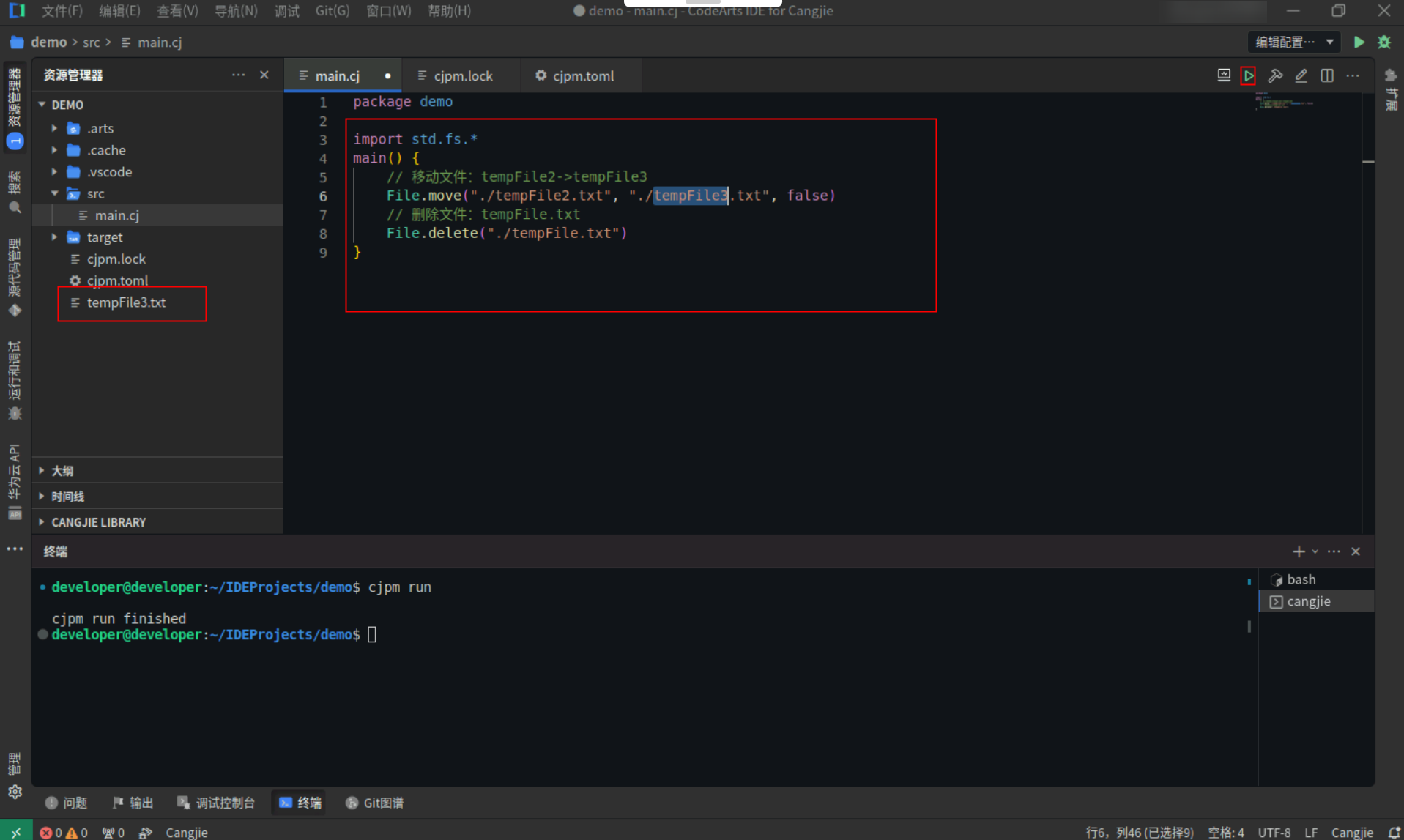
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.fs.*
main() {
// 移动文件:tempFile2->tempFile3
File.move("./tempFile2.txt", "./tempFile3.txt", false)
// 删除文件
File.delete("./tempFile.txt")
}
Step2:点击编辑器右上角运行按钮直接运行,可以看到项目根目录下只剩下tempFile3文件。
![6d102fb56d79f92ecf23640c85310acf.PNG]()
如果需要直接将文件的所有数据读出来,或者一次性将数据写入文件里,可以使用 File 提供的 readFrom、writeTo 函数直接读写文件。
readFrom、writeTo 函数使用,具体代码操作如下:
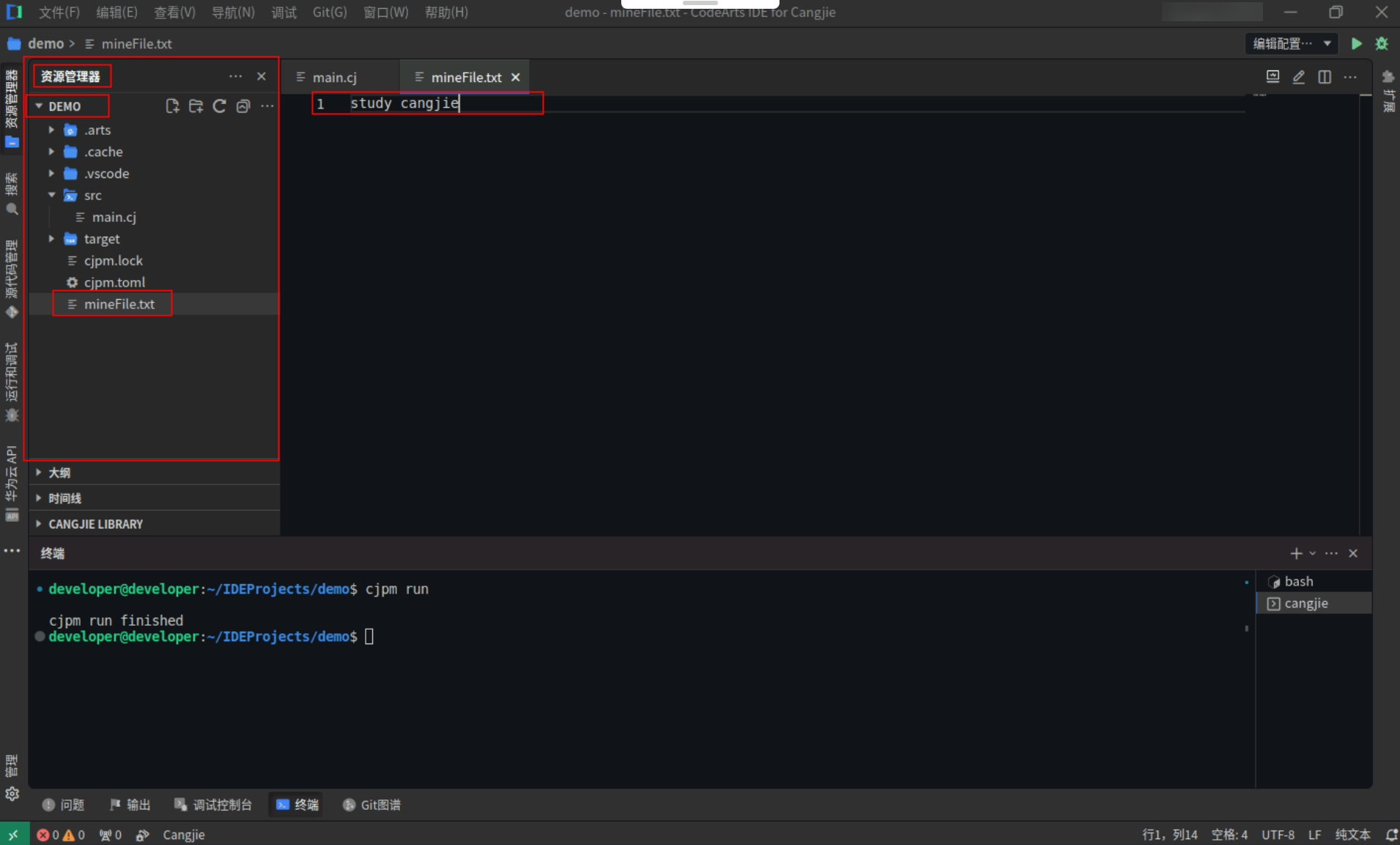
Step1:在项目根目录下新建文本文件:mineFile.txt,文本内容:study cangjie。
![bce582dfcbdaf6aefc5b2f8ddd5d8a15.PNG]()
Step2:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.fs.*
main() {
// 一次性读取了所有的数据
let bytes = File.readFrom("./mineFile.txt")
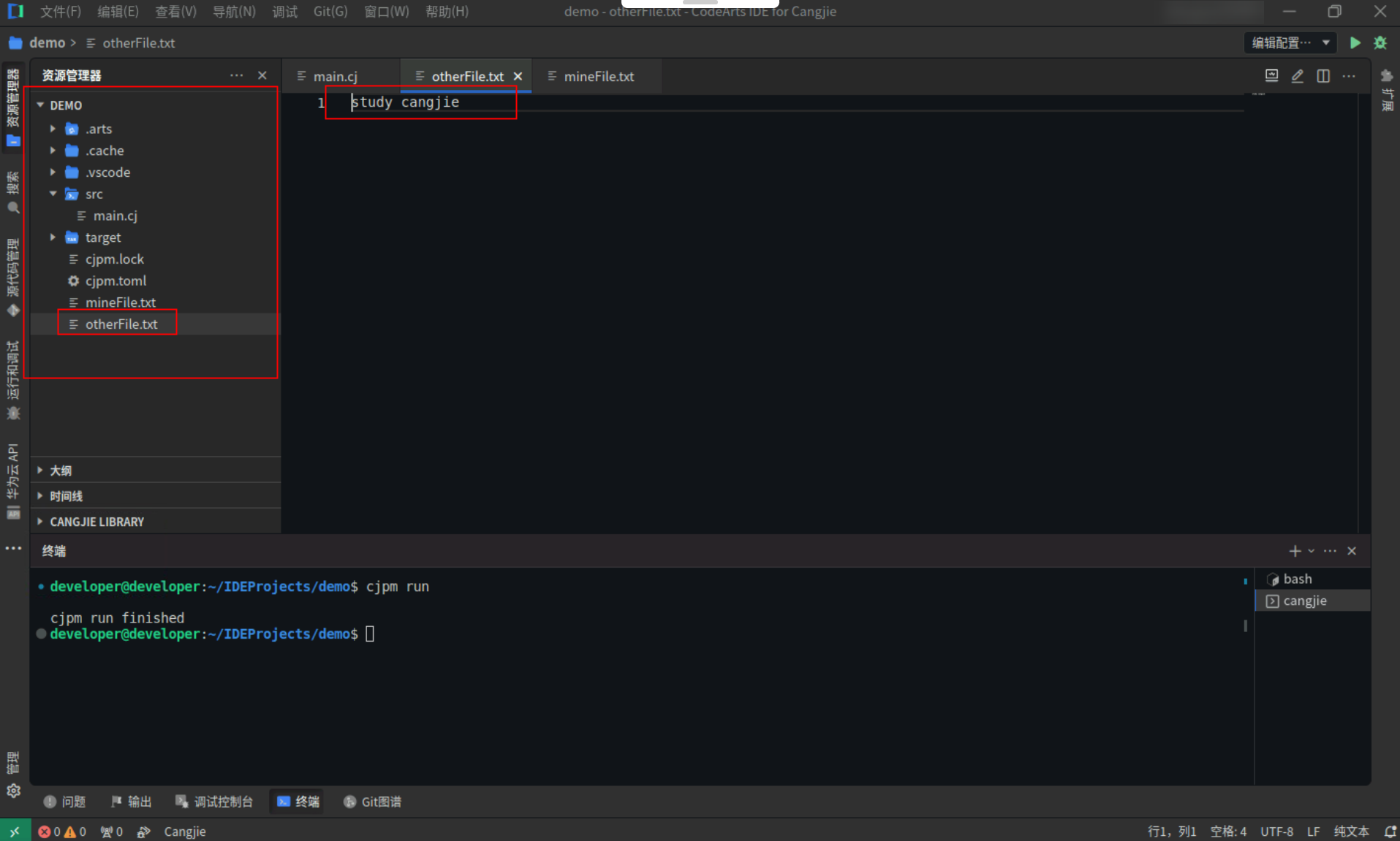
// 把数据一次性写入另一个文件中
File.writeTo("./otherFile.txt", bytes)
}
Step3:点击编辑器右上角运行按钮直接运行,资源管理器->项目根目录下,源文件数据写入了另外一个文件中。
![aeafbe45b879511fa537a0faec0a9007.PNG]()
文件流操作:
除了上述的常规文件操作之外,File 类型也被设计为一种数据流类型,因此 File 类型本身实现了 IOStream 接口。当创建了一个 File 的实例,可以把这个实例当成数据流来使用。
通过静态函数 openRead/create 直接打开文件或创建新文件的实例。
具体代码操作如下:
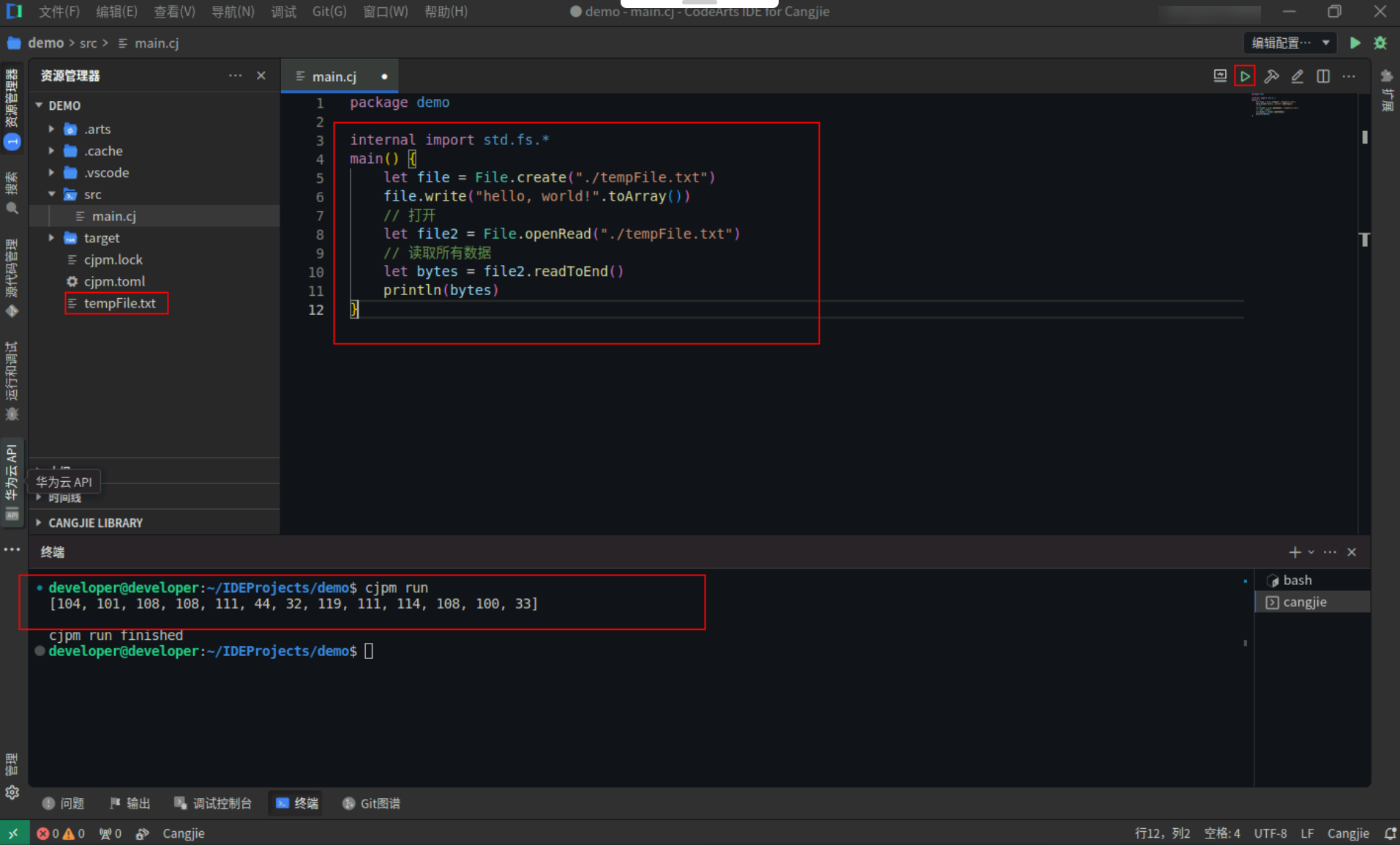
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
internal import std.fs.*
main() {
let file = File.create("./tempFile.txt")
file.write("hello, world!".toArray())
// 打开
let file2 = File.openRead("./tempFile.txt")
// 读取所有数据
let bytes = file2.readToEnd()
println(bytes)
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![446767e7952375cab52fe647ba04d2b3.PNG]()
3.3 I/O处理流
处理流是指代理其它数据流进行处理的流。仓颉编程语言中常见的处理流包含 BufferedInputStream、BufferedOutputStream、StringReader、StringWriter、ChainedInputStream 等。
使用处理流时,需要导入io包:
本节主要介绍缓冲流和字符串流。
3.3.1 缓冲流
由于磁盘的 I/O 操作相比内存的 I/O 操作要慢很多,所以要使用缓冲流,等凑够了缓冲区大小的时候再一次性操作磁盘,减少磁盘操作次数,从而提升性能表现。
仓颉编程语言标准库提供了 BufferedInputStream 和 BufferedOutputStream 这两个类型用来提供缓冲功能。
BufferedInputStream 使用示例,具体代码操作如下:
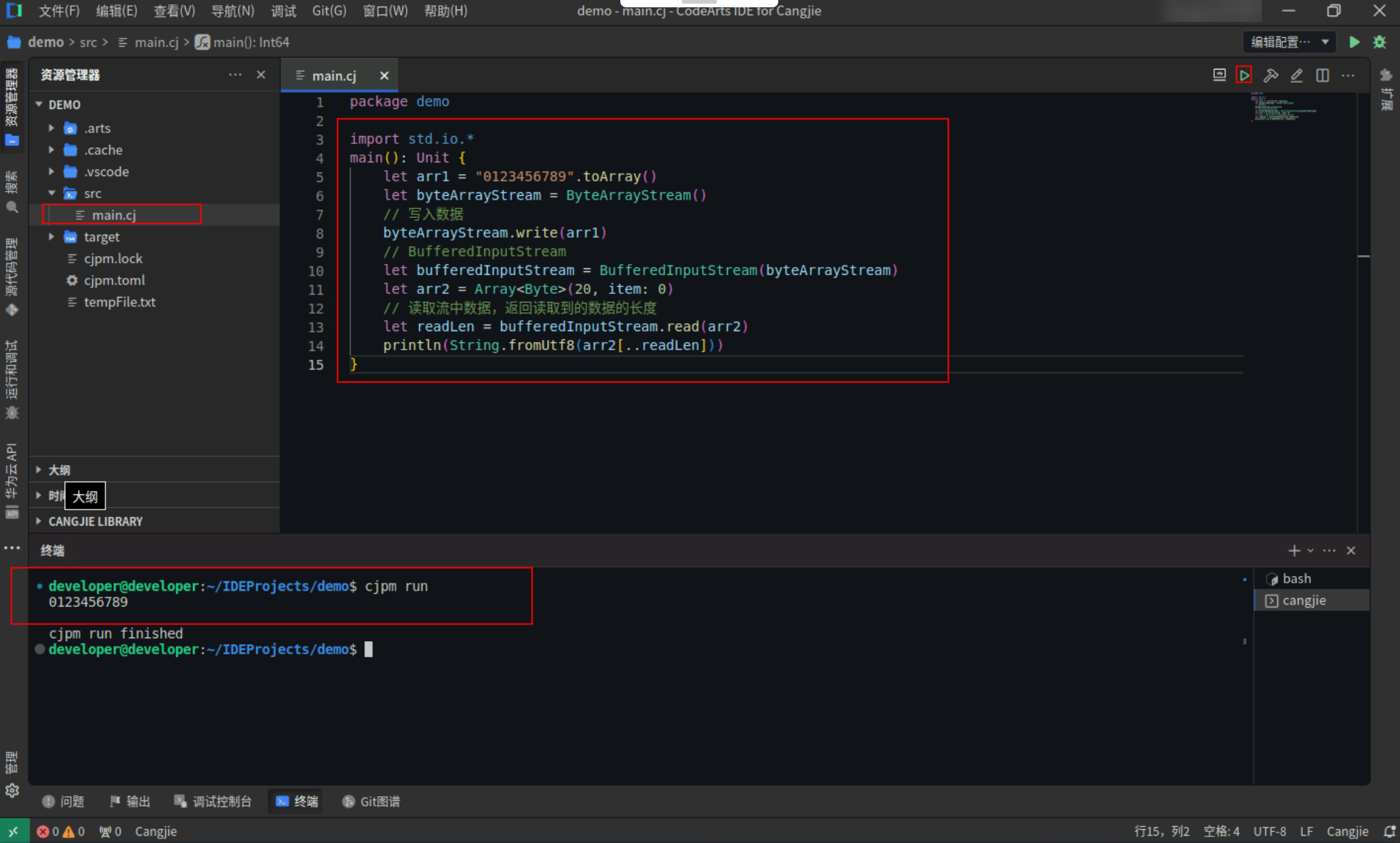
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.io.*
main(): Unit {
let arr1 = "0123456789".toArray()
let byteArrayStream = ByteArrayStream()
// 写入数据
byteArrayStream.write(arr1)
// BufferedInputStream
let bufferedInputStream = BufferedInputStream(byteArrayStream)
let arr2 = Array<Byte>(20, item: 0)
// 读取流中数据,返回读取到的数据的长度
let readLen = bufferedInputStream.read(arr2)
println(String.fromUtf8(arr2[..readLen]))
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![381840ea5fa1168aaf6a3df8f5c3ea2a.PNG]()
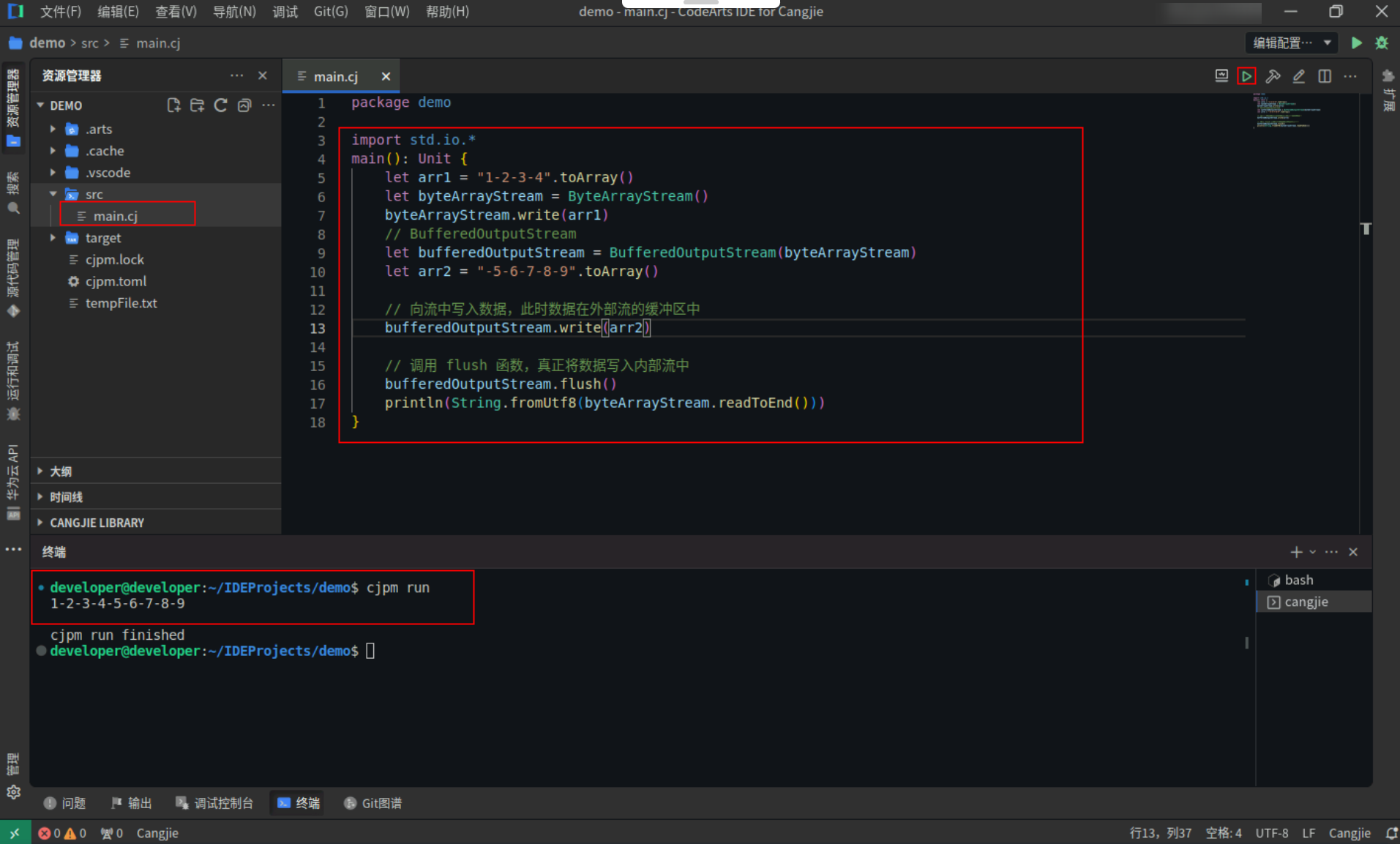
BufferedOutputStream 使用示例,具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.io.*
main(): Unit {
let arr1 = "1-2-3-4".toArray()
let byteArrayStream = ByteArrayStream()
byteArrayStream.write(arr1)
// BufferedOutputStream
let bufferedOutputStream = BufferedOutputStream(byteArrayStream)
let arr2 = "-5-6-7-8-9".toArray()
// 向流中写入数据,此时数据在外部流的缓冲区中
bufferedOutputStream.write(arr2)
// 调用 flush 函数,真正将数据写入内部流中
bufferedOutputStream.flush()
println(String.fromUtf8(byteArrayStream.readToEnd()))
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![5d43ae9bb30ae829c58c6f90474f2196.PNG]()
3.3.2 字符串流
由于仓颉编程语言的输入流和输出流是基于字节数据来抽象的(拥有更好的性能),在部分以字符串为主的场景中使用起来不太友好,为了提供友好的字符串操作能力,仓颉编程语言提供了 StringReader 和 StringWriter 来添加字符串处理能力。
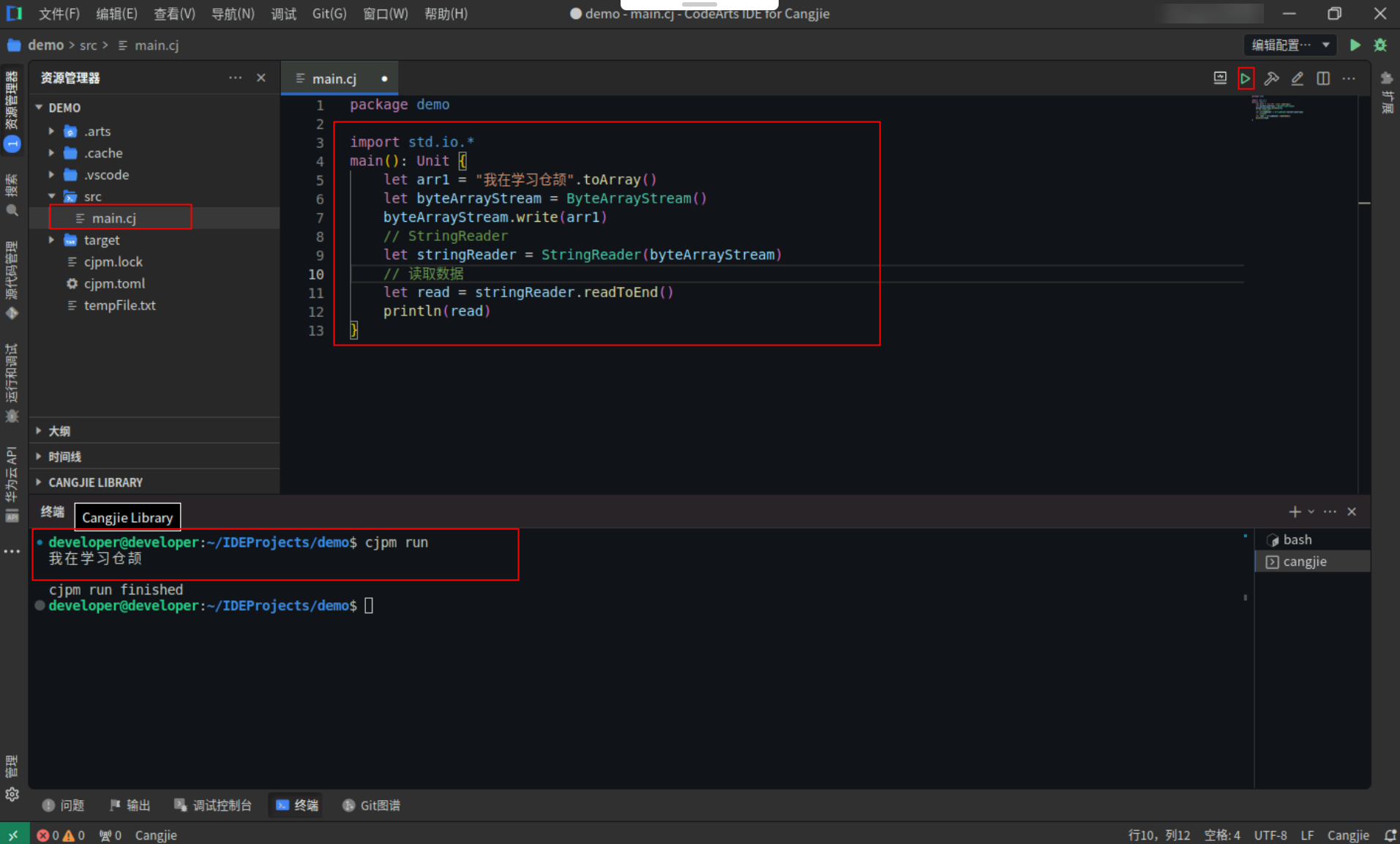
StringReader提供了字符串读取的能力,StringReader使用示例,具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.io.*
main(): Unit {
let arr1 = "我在学习仓颉".toArray()
let byteArrayStream = ByteArrayStream()
byteArrayStream.write(arr1)
// StringReader
let stringReader = StringReader(byteArrayStream)
// 读取数据
let read = stringReader.readToEnd()
println(read)
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![e40e8a5d0b3acdf382a0c6c4d0ab501a.PNG]()
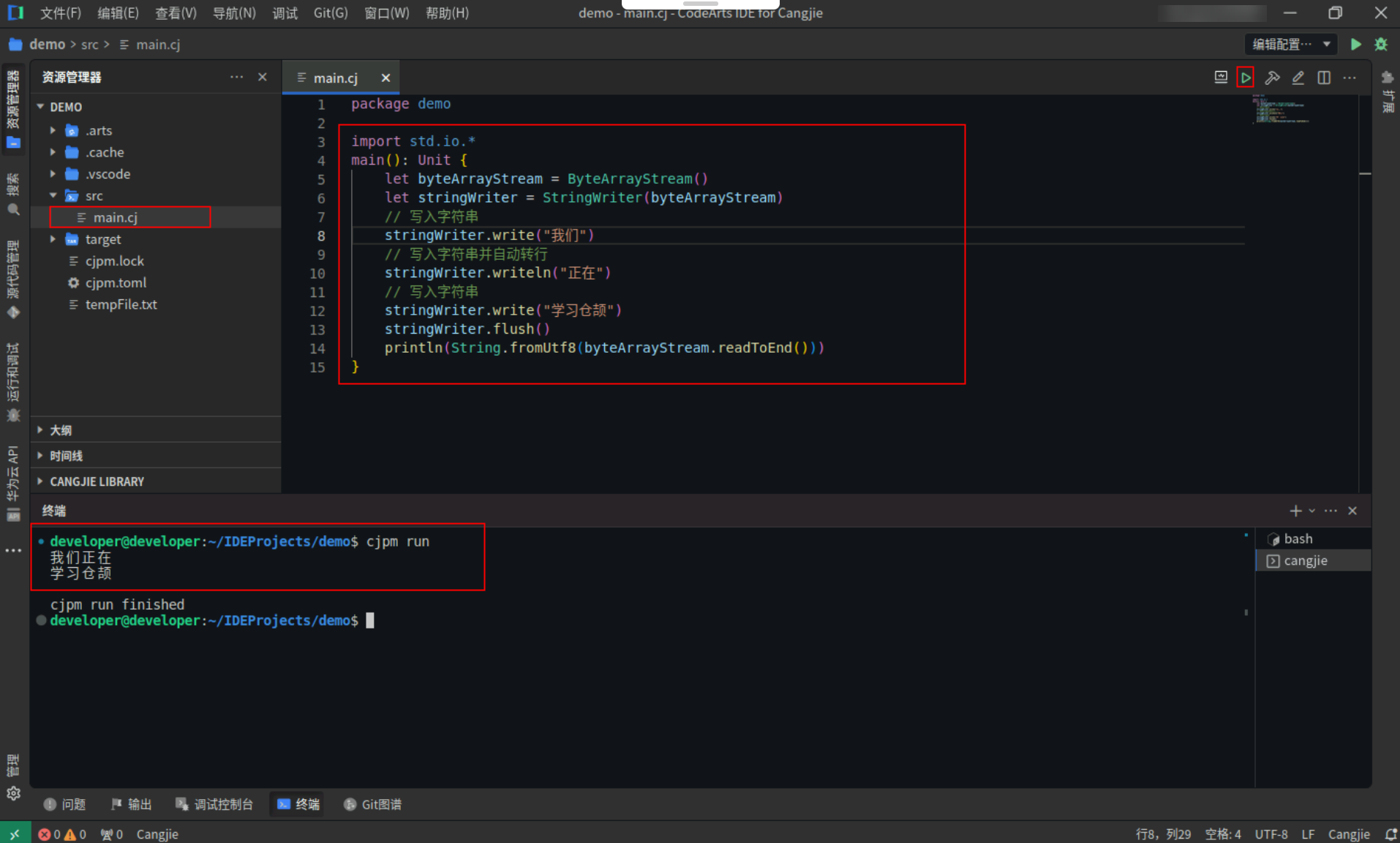
StringWriter提供了写字符串的能力,StringWriter使用示例,具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
import std.io.*
main(): Unit {
let byteArrayStream = ByteArrayStream()
let stringWriter = StringWriter(byteArrayStream)
// 写入字符串
stringWriter.write("我们")
// 写入字符串并自动转行
stringWriter.writeln("正在")
// 写入字符串
stringWriter.write("学习仓颉")
stringWriter.flush()
println(String.fromUtf8(byteArrayStream.readToEnd()))
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![68f1868f217c37be36485483e34ae1e0.PNG]()
至此,仓颉之IO操作的交互奥秘案例内容已全部完成。
如果想了解更多仓颉编程语言知识可以访问:https://cangjie-lang.cn/