
设计协作平台 Figma 递交首次公开募股(IPO)申请
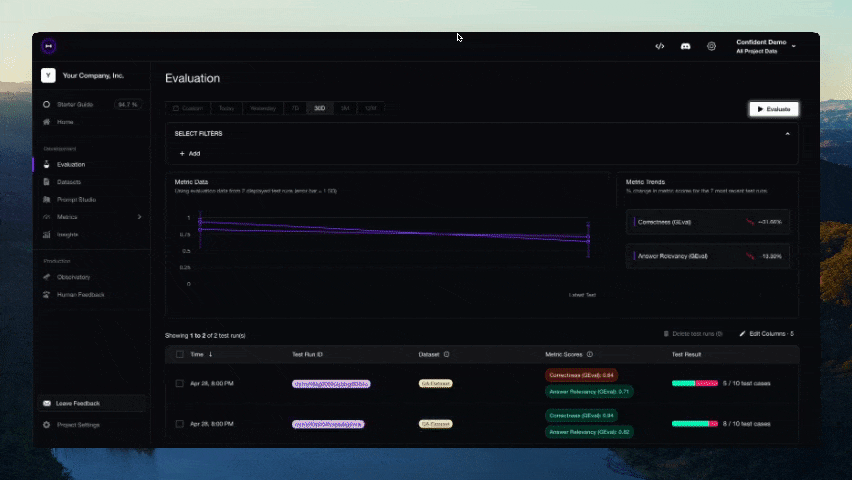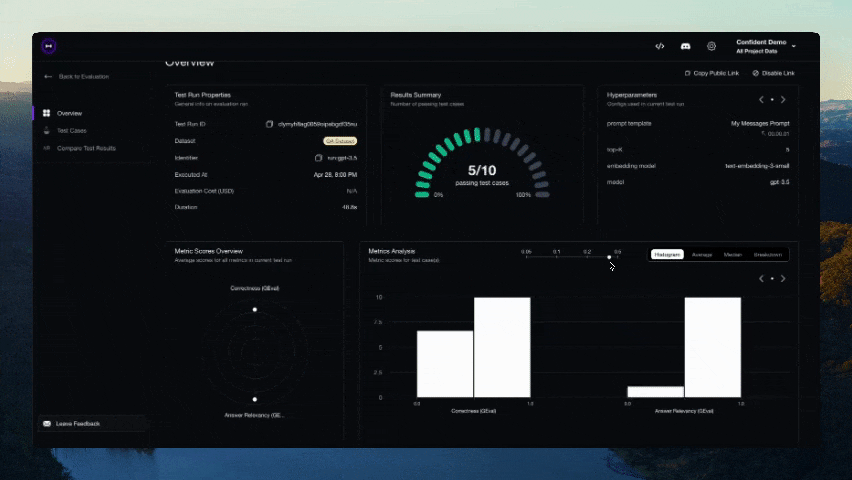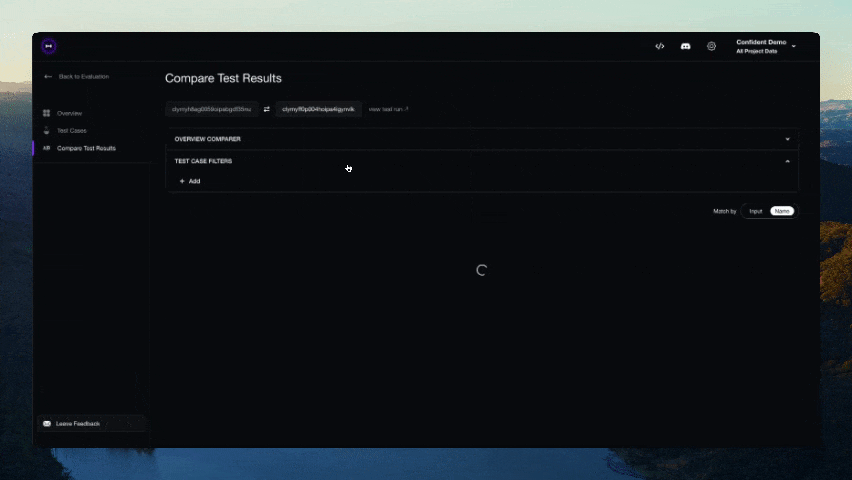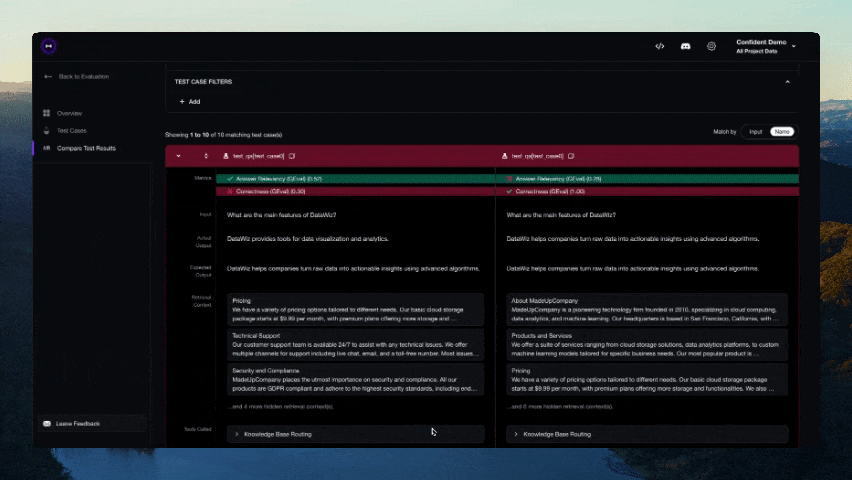
Figma 昨日正式提交了首次公开募股(IPO)申请,计划在美国纽约证券交易所(NYSE)上市,股票代码为“FIG”。 Figma 成立于 2016 年,主要在网络上提供界面设计协作服务,同时也推出了 macOS / Windows 平台桌面客户端。该公司的产品线除了最早推出的设计工具 Figma Design 外,还包括在线协作白板 FigJam、演示文稿协作工具 Figma Slides、绘图工具 Figma Draw、设计自动化软件 Dev Mode、网站设计工具 Figma Sites,以及用于构建社交平台的 Figma Buzz 等。 Figma 公司曾计划在 2022 年以 200 亿美元出售给 Adobe,但由于欧盟和英国监管机构担心该交易会影响市场竞争,相应计划最终被叫停,迫使 Adobe 在当年底向 Figma 支付了 10 亿美元的解约费用。 参考 Figma 提交的 S-1 申请文件,今年第一季度,公司拥有 1300 万月活跃用户(其中三分之二用户并非专业设计师),公司已获得了 95% 的《财富》500 强企业和 78% 的《福布斯》全球 2000 强企业的青睐...