🔥 Solon Flow 设计器入门
探索视频:
Hugging Face 近日发布开放权重模型贡献榜,中国团队Qwen和DeepSeek成功入围前15名。该榜单表彰为开源社区提供高质量模型权重的团队,其模型广泛应用于学术与产业创新。
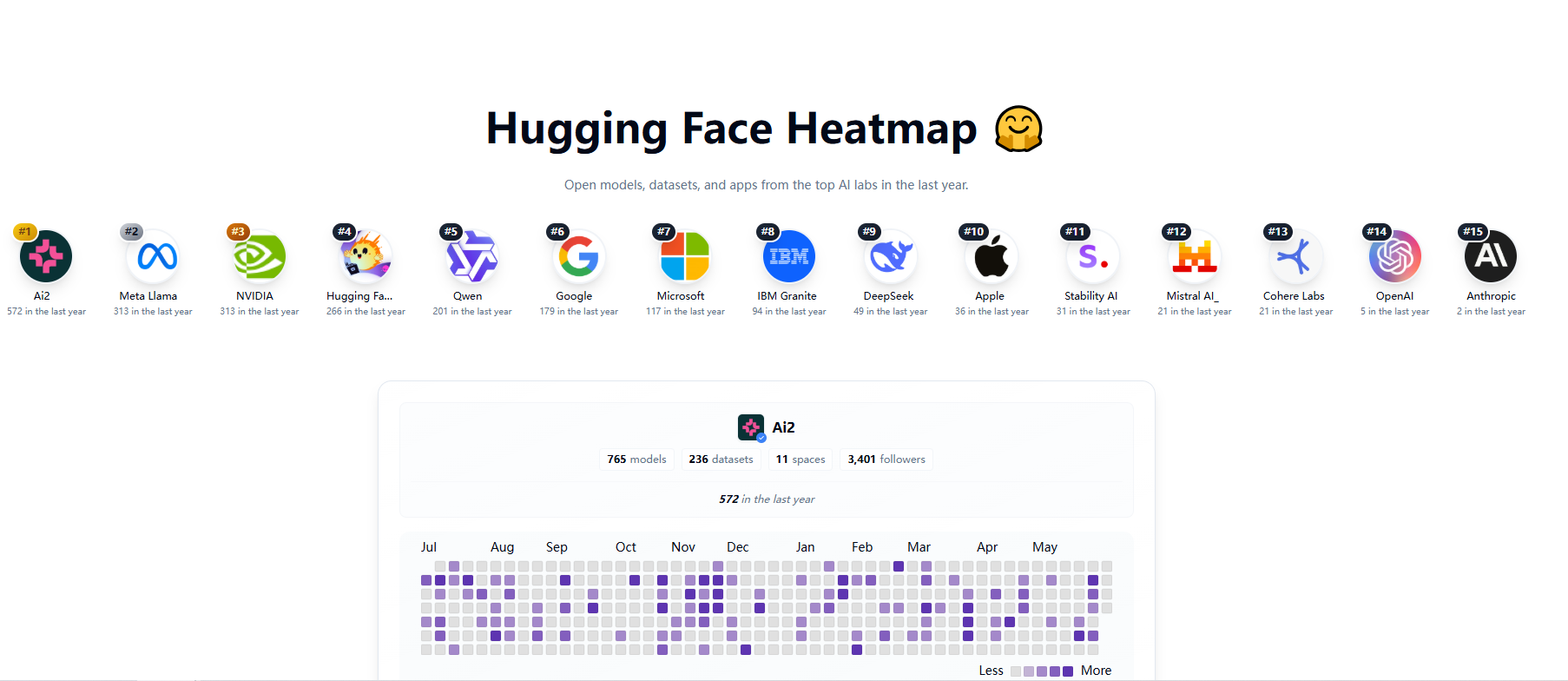
由阿里巴巴云智能集团支持的Qwen团队,以Qwen3系列模型在指令跟随、代码生成等任务中的优异表现受到社区青睐。Qwen2.5-72B系列位列开源大语言模型前列,其轻量化模型QwQ-32B通过强化学习优化,在数学推理和代码生成中媲美大型模型,大幅降低部署成本。
DeepSeek则以低成本、高性能的R1系列模型闻名。R1-0528在LiveCodeBench排行榜中超越多个国际竞品,仅次于OpenAI顶尖模型。其轻量化版本DeepSeek-R1-0528-Qwen3-8B通过知识蒸馏技术,单GPU即可运行,在AIME2025数学测试中击败Google的Gemini2.5Flash,展现了在特定领域的竞争优势。
Qwen和DeepSeek的入榜反映了中国AI团队在开源生态中的崛起。Hugging Face负责人表示,两团队的贡献为全球开发者提供了高效资源。NVIDIA首席执行官黄仁勋也赞扬其性能与成本平衡正在重塑AI格局。未来,Qwen计划探索多模态技术,DeepSeek则将推出R2模型,持续推动AI创新。

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273