
大模型生成内容的相关性及模型性能的评估方式探讨
为什么要评估测试(Evaluation Testing)
随着大模型技术的推进,评测其性能和能力的需求也日益增长,这不仅仅是技术层面的需求,更关系到商业决策和公众认知。 为什么需要大模型评估测试?主要原因如下;
- 模型好坏的统一判断标准:如果不构建一个客观公正和定量的模型评测体系,则无法判断众多大模型之间的能力高低,用户无法了解模型的真实能力和实际效果。
- 模型迭代优化的依据:对于开发者而言,如果不能定量评估模型的能力,则无法跟踪模型能力的变化,无法知道模型的优势和劣势,从而无法有针对的指定模型提升策略,影响模型的迭代升级。
- 监管安全的要求考虑:对于法律、医疗等关乎社会安全的领域,需要对大模型进行系统的评测,以确认大模型适合在该领域进行使用,而不会造成安全事故。
- 领域基础模型的选择依据:在不同的领域下,大模型的能力表现各有优劣,需要引入评测体系对大模型在各个领域下的能力进行统一测试,选择出最适合该特定领域的大模型作为基座,从而更好的产业落地。
大模型的评估标准是什么
大模型的评估需要一套标准,所有按照一套标准进行评估,比较才会有公平性,就以 SuperCLUE 为例。
SuperCLUE是一个综合性大模型评测基准,评测主要聚焦于大模型的四个能力象限,包括语言理解与生成、专业技能与知识、Agent智能体和安全性,进而细化为12项基础能力。
评估基准
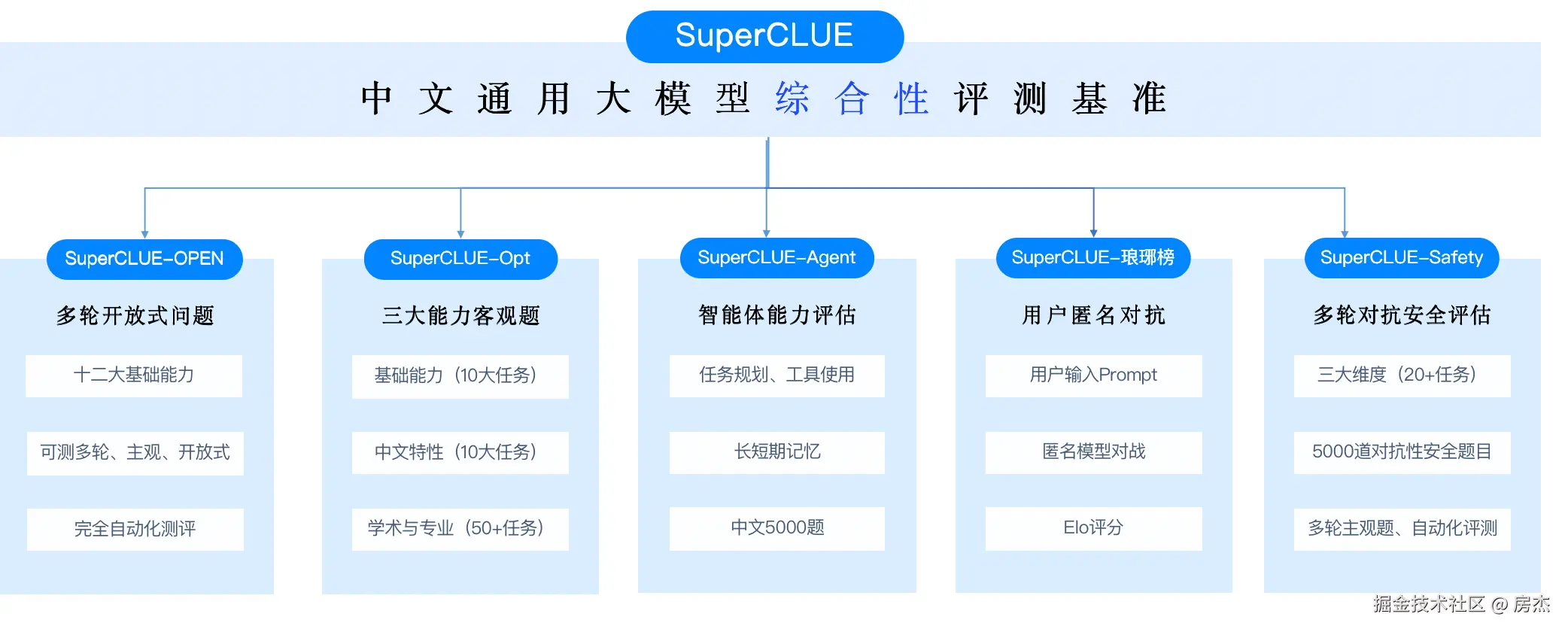
多维度的评测方案

根据评测我们可以从大范围内选择适合我们的模型,在此基础上我们可能对模型进行微调等,在微调后我们就需要对微调的模型,使用一些测试数据,对模型进行评估测试。
Spring AI 框架如何支持评估测试
Spring AI 主要测试 AI 应用程序需要评估生成的内容,以确保 AI 模型没有产生幻觉反应。
第一种方式:使用AI自身评估
用于评估响应的 Spring AI 接口定义为 Evaluator :
@FunctionalInterface public interface Evaluator { EvaluationResponse evaluate(EvaluationRequest evaluationRequest) } 评估的输入 EvaluationRequest 定义为
public class EvaluationRequest { private final String userText; private final List<Content> dataList; private final String responseContent; public EvaluationRequest(String userText, List<Content> dataList, String responseContent) { this.userText = userText; this.dataList = dataList; this.responseContent = responseContent; } ... } - userText: 用户的输入文本
- dataList: 附加到原始输入的上下文数据
- reponseContent: AI 模型的响应内容
第二种方式:RelevancyEvaluator
它使用 AI 模型进行评估。未来版本中将提供更多实现。 RelevancyEvaluator 使用输入 ( userText ) 和 AI 模型的输出 ( chatResponse ) 来提出问题:
Your task is to evaluate if the response for the query is in line with the context information provided.\n You have two options to answer. Either YES/ NO.\n Answer - YES, if the response for the query is in line with context information otherwise NO.\n Query: \n {query}\n Response: \n {response}\n Context: \n {context}\n Answer: " 例如:该测试对加载到 Vector Store 中的 PDF 文档执行 RAG 查询,然后评估响应是否与用户文本相关。
@Test void testEvaluation() { dataController.delete(); dataController.load(); // 用户的提问 String userText = "What is the purpose of Carina?"; // 大模型影响 String responseContent = ChatClient.builder(chatModel) .build().prompt() .advisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults())) .user(userText) .call() .content(); // 定义一个相关性评估器 var relevancyEvaluator = new RelevancyEvaluator(ChatClient.builder(chatModel)); // 将 用户提问 + 模型的响应,一并发给大模型进行评估 EvaluationRequest evaluationRequest = new EvaluationRequest(userText, (List<Content>) response.getMetadata().get(QuestionAnswerAdvisor.RETRIEVED_DOCUMENTS), responseContent); // 返回评估结果 EvaluationResponse evaluationResponse = relevancyEvaluator.evaluate(evaluationRequest); // 断言是否大模型是否满足性能需求 assertTrue(evaluationResponse.isPass(), "Response is not relevant to the question"); } 总结
大模型的评估也是相当重要的,是用好大模型的关键步骤。就像测试一样保障程序尽量少出bug。这个也是一个值得研究的专题,后续也会持续研究,并实践。本文也仅是做一个引入并记录一下。
参考文章
 关注公众号
关注公众号 低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。
持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
转载内容版权归作者及来源网站所有,本站原创内容转载请注明来源。
- 上一篇

大模型生成内容的相关性及模型性能的评估方式探讨
为什么要评估测试(Evaluation Testing) 随着大模型技术的推进,评测其性能和能力的需求也日益增长,这不仅仅是技术层面的需求,更关系到商业决策和公众认知。 为什么需要大模型评估测试?主要原因如下; 模型好坏的统一判断标准:如果不构建一个客观公正和定量的模型评测体系,则无法判断众多大模型之间的能力高低,用户无法了解模型的真实能力和实际效果。 模型迭代优化的依据:对于开发者而言,如果不能定量评估模型的能力,则无法跟踪模型能力的变化,无法知道模型的优势和劣势,从而无法有针对的指定模型提升策略,影响模型的迭代升级。 监管安全的要求考虑:对于法律、医疗等关乎社会安全的领域,需要对大模型进行系统的评测,以确认大模型适合在该领域进行使用,而不会造成安全事故。 领域基础模型的选择依据:在不同的领域下,大模型的能力表现各有优劣,需要引入评测体系对大模型在各个领域下的能力进行统一测试,选择出最适合该特定领域的大模型作为基座,从而更好的产业落地。 大模型的评估标准是什么 大模型的评估需要一套标准,所有按照一套标准进行评估,比较才会有公平性,就以 SuperCLUE 为例。 SuperCLUE是...
- 下一篇
大模型生成内容的相关性及模型性能的评估方式探讨
为什么要评估测试(Evaluation Testing) 随着大模型技术的推进,评测其性能和能力的需求也日益增长,这不仅仅是技术层面的需求,更关系到商业决策和公众认知。 为什么需要大模型评估测试?主要原因如下; 模型好坏的统一判断标准:如果不构建一个客观公正和定量的模型评测体系,则无法判断众多大模型之间的能力高低,用户无法了解模型的真实能力和实际效果。 模型迭代优化的依据:对于开发者而言,如果不能定量评估模型的能力,则无法跟踪模型能力的变化,无法知道模型的优势和劣势,从而无法有针对的指定模型提升策略,影响模型的迭代升级。 监管安全的要求考虑:对于法律、医疗等关乎社会安全的领域,需要对大模型进行系统的评测,以确认大模型适合在该领域进行使用,而不会造成安全事故。 领域基础模型的选择依据:在不同的领域下,大模型的能力表现各有优劣,需要引入评测体系对大模型在各个领域下的能力进行统一测试,选择出最适合该特定领域的大模型作为基座,从而更好的产业落地。 大模型的评估标准是什么 大模型的评估需要一套标准,所有按照一套标准进行评估,比较才会有公平性,就以 SuperCLUE 为例。 SuperCLUE是...
相关文章
文章评论
共有0条评论来说两句吧...
文章二维码
点击排行

推荐阅读






最新文章
- SpringBoot2配置默认Tomcat设置,开启更多高级功能
- CentOS7安装Docker,走上虚拟化容器引擎之路
- Hadoop3单机部署,实现最简伪集群
- SpringBoot2编写第一个Controller,响应你的http请求并返回结果
- Springboot2将连接池hikari替换为druid,体验最强大的数据库连接池
- CentOS8编译安装MySQL8.0.19
- Docker使用Oracle官方镜像安装(12C,18C,19C)
- Red5直播服务器,属于Java语言的直播服务器
- CentOS关闭SELinux安全模块
- CentOS7,CentOS8安装Elasticsearch6.8.6
 微信收款码
微信收款码 支付宝收款码
支付宝收款码