今天的开头有点恶心。你有没有见过扫地机器人因为无法识别宠物便便,变成推💩机器人的。此处就不上图了,好奇宝宝可以自己去搜索下看看。其中关键原因就是机器人无法100%识别宠物排泄物。
在机械世界里,感知交互是智能化的第一步,也是机器人获取环境信息、进行学习与适应、实现自主决策的前提。如果说大模型是 AI 的“大脑”,那么感知系统则是机器人的“五感”,它让冰冷的机械体具备了理解世界的生物学基础。
视觉、听觉、嗅觉、味觉、触觉——人类通过五感将外界刺激转化为神经信号,传递至大脑的初级感觉皮层,对形状、颜色、声音频率等进行初步特征提取。随后,高级脑区会对多模态信息进行整合,形成对环境的整体认知。例如,视觉的色彩和光线会影响情绪判断,嗅觉的气味会直接激活记忆相关脑区,触发情感联想等等。
机器人要想无限贴近人类,首先就要学会人类五感。
事实上,当前全球机器人感知技术的发展方面,单项感知能力并不算弱,甚至有的方面已经超越人类。但是在多模态感知融合上,还存在不小的认知鸿沟。比如视觉无法分辨地毯纹理与粪便,嗅觉会遭遇气流扰动的信号失真,触觉反馈延迟一秒就可能导致鸡蛋破碎——这些技术断点恰是智能觉醒必须跨越的天堑。或许未来某天,搭载神经形态芯片的机器人能像人类一样,闻到雨后泥土气息时自动调低吸力,触到宠物毛发瞬间切换轻柔模式,那才是真正的感知革命。
技术拆解:从单点突破到多模态交响
单一的感知技术很难应对真实复杂的场景需求,因此业界正在转向多模态感知融合的研究,本质是通过硬件协同、算法泛化与场景适配,构建“感知-决策-执行”的闭环智能体。同时,多模态感知的融合则是构筑在单一感知技术的突破之上。
![]()
2025机器人全产业链接会上,帕西尼展出的灵巧手融合了视觉交互技术
触觉
新中式赛博的叙事里,机器人可以化身老中医,给人把脉、问诊。
第一步就是通过一个小小的触觉传感芯片——当人体脉搏跳动时,血管扩张产生的压力会使触觉芯片中的压电材料发生形变,材料内部的正负电荷发生位移,从而产生与脉搏压力成正比的电荷信号。这种信号经过放大和滤波处理后,可转换为脉搏波形数据。一般通过波形分析获,可以初步诊断血管弹性、血流量变化等心血管疾病。
![]()
但这个场景只能算是触觉感知里的入门级应用。现在,我们更想看到的是,机器人灵巧手可以捏捏葡萄藤上的果子,根据软硬判断它的成熟度,又或者是通过触摸能判断一只包的材质……
如果说早期的触觉传感器还停留在工业场景的"有无"判断,那么它的进化史就是一部从机械触须到仿生神经的蜕变录。20世纪70年代,科学家用压阻式、电感式传感器绘制出触觉感知的雏形;2003年 MIT 给 NASA 宇航机器人 Robonaut 披上电子皮肤时,首次实现触觉覆盖,可感知压力、温度等多维信息;待到2020年,以深度学习驱动的触觉数据处理技术兴起,布里斯托大学团队首次将深度神经网络应用于机器人指尖触觉,通过三维滑动接触数据训练模型,使机器人能估算物体表面角度并实时调整抓握策略,让触觉感知从简单的压力检测,升级为可解析纹理、形变的动态交互系统。
当下,触觉感知的硬件基础持续迭代,同时结合深度学习与仿真技术,提升模型泛化能力,加速多维触觉数据的获取与解析。
帕西尼多维度触觉传感器 PX-6AX 接触到物体时,其柔性阵列上亚毫米级别的微小形变场能被瞬间捕捉,在传统三维/六维力检测的基础上,安装在 PX-6AX 上的柔性传感阵列能额外为机器人提供滑动、摩擦、纹理、温度等额外信息,使得机器人能在更丰富多元的场景下完美感知,完成复杂的自适应动作。
今年3月,多模态触觉感知公司千觉机器人推出全球首个触觉仿真工具 Xense_Sim 以及多模态高精度触觉传感器 G1-WS,通过深度学习生成合成触觉数据,解决了真实数据采集成本高的难题,同时助力智元机器人完备数据采集模态,为人形机器人在精密装配、工业智造及智能服务等复杂场景中落地应用构建数据基础。据智元机器人内部人士评价,“合成数据与真实机器人操作轨迹数据互补,提升数据的多样性和模型的泛化性,并降低数据成本。”
![]()
视觉
机器人视觉感知方向上。2009年,李飞飞实验室发布了包含1500万张图像的 lmageNet 数据集,视觉算法的速度和准确性得以迅速提升。此后图像识别引领了一段时间的 AI 发展,再到物体切分、动态关系预测,使用人类自然语言描述照片等。2015年扩散模型出现,可以应用在图像去噪、图像修复、超分辨率成像、图像生成等场景中。而后扩散模型又推动了生成式 AI 的发展,可以将人类输入的句子转化为照片和视频。
2022年底开始,全球大模型进入高速发展阶段,至今,国内外已经有多个大模型通过参数规模突破与训练范式革新,进而提升机器人视觉感知能力。比如,今年2月,豆包大模型团队与高校联合推出的 VideoWorld 视频生成实验模型,实现了无需语言模型的纯视觉信号学习,通过纯视觉信号将复杂的推理、规划和决策能力转化为现实,只需通过海量视频数据的浏览,便能让机器自主学习。
除了大模型能力的加持,机器人视觉硬件也在同步迭代。传统机器人视觉依赖单一传感器,如 RGB 摄像头或激光雷达,通过灰度/彩色图像或点云数据完成目标识别与定位,但存在环境光干扰、测距精度不足等问题。当下的视觉感知在硬件上也已经在从单一感知向多模态融合。比如早期聚焦车载激光雷达的企业 RoboSense 在今年3月发布了机器人视觉全新品类 Active Camera 的首款产品 AC1及 AI-Ready 生态,其中 AC1提供深度、色彩、运动姿态硬件级融合信息,让机器人感知构型摆脱堆叠传感器的传统方法。
![]()
室外 AC1 拍摄画面及建图数据,图片来自速腾聚创官网视频截图
听觉、味觉与嗅觉
当前的具身智能感知技术研究中,听觉、味觉、嗅觉往往是作为补充性功能,叠加视觉或者触觉,让机器人的感知更加全面、精细。
比如听觉主要用于语音交互和环境声事件检测,像异常警报,但其核心价值还是依附于视觉与触觉的协同,例如通过声音辅助定位目标物体等等。味觉和嗅觉的应用场景目前也高度垂直,如食品检测、医疗诊断中,主要依赖电子鼻这类的化学传感器和特定算法,技术通用性差,例如葡萄酒检测机器人需定制红外光谱仪,难以迁移到其他场景。
工业和服务机器人更关注抓取、移动的基础操作能力,而听觉、味觉、嗅觉的研发成本高、商业回报周期长,所以我们常见以触觉或视觉为核心的具身智能创企和团队,但很少有以听觉、味觉、嗅觉为核心的创企。应用场景上同样,智能家居中视觉门锁、触觉机械臂已普及,但气味控制机器人仍属于小众市场
多模态融合
业内在感知方面研究较深的帕西尼,其灵巧手在掌内可以内嵌多颗摄像头,通过触觉与视觉的融合,能有效避免因角度遮挡带来的识别失误,同时提升复杂操作的稳定性。比如在物流仓储场景下,它能自主判断并完成扫码、贴标、分拣等动作,无需额外人工干预。
![]()
触觉+视觉的融合是具身智能感知方面最常见的融合之一,触觉传感器能够捕捉物体的质地、硬度、温度、滑移状态等物理特性,而视觉传感器擅长获取形状、颜色、空间位置信息,二者结合便更容易在复杂动态场景中实现类人化的环境理解与精准操作。
事实上,关于多模态融合的研究也是始于对人类多感官协同机制的探索。早在20世纪70年代,心理学领域便关注到人类交流中非言语模态,如肢体动作、声音的主导作用;到了2002年,加州大学伯克利分校的 Banks 团队通过神经科学实验首次揭示了人类视觉与触觉的天然融合机制,发现触觉信息能有效弥补视觉遮挡或模糊时的感知空缺。这一发现不仅证实了多模态融合的生物基础,更直接推动了工程化研究——例如,MIT 团队随后开发了结合视觉触觉传感器的 GelSight 系统,通过触觉图像重建物体表面纹理,并将触觉数据与视觉特征对齐。
随着深度学习技术的突破,多模态融合从生物启发式建模转向数据驱动的跨模态表征学习。2010年代,基于深度玻尔兹曼机的多模态模型首次实现视觉与触觉的联合编码;至2020年代,Transformer 架构的引入使跨模态语义对齐能力显著提升;去年年底,卡内基梅隆大学机器人研究所、加州大学伯克利分校等共同组成的研究团队提出了一种名为 NeuralFeels 的方法,将视觉与触觉感知相结合,通过多模态融合的方式,使机器手能够对未知物体持续进行 3D 建模,从而更精确地估计掌上操作物体的姿态和形状。
政策也在指引多模态感知融合研究。今年2月,《北京具身智能科技创新与产业培育行动计划(2025-2027年)》印发。其中重点任务的第一项便是“突破多模态融合感知技术”:支持高校院所联合优势企业,研究多传感器数据的时空同步与校准技术,高效整合不同感知源数据;研究跨模态学习算法,加强不同模态数据的相互作用和互相补充;研究交互式感知、主动感知、多模态数据补全等算法,实现规模化多模态数据高效自动对齐;研究具身环境中高效、鲁棒的视觉-语言-动作多模态统一表征与融合方法,提升机器人感知理解能力。
行业落地:工业场景抢跑,服务市场蓄势
工厂就像个规规矩矩的考场,流水线怎么摆、零件怎么放都是固定套路,这种环境对机器人来说简直就是量身定制的舞台。
越是结构化、可预测、标准化的交互环境,机器人行动起来越是自如。所以目前我们看到的机器人应用也多是在工业场景中,在固定的产线布局和标准化的作业流程中,机器人做起汽车焊接、货物分拣、贴标签等工作来得心应手。
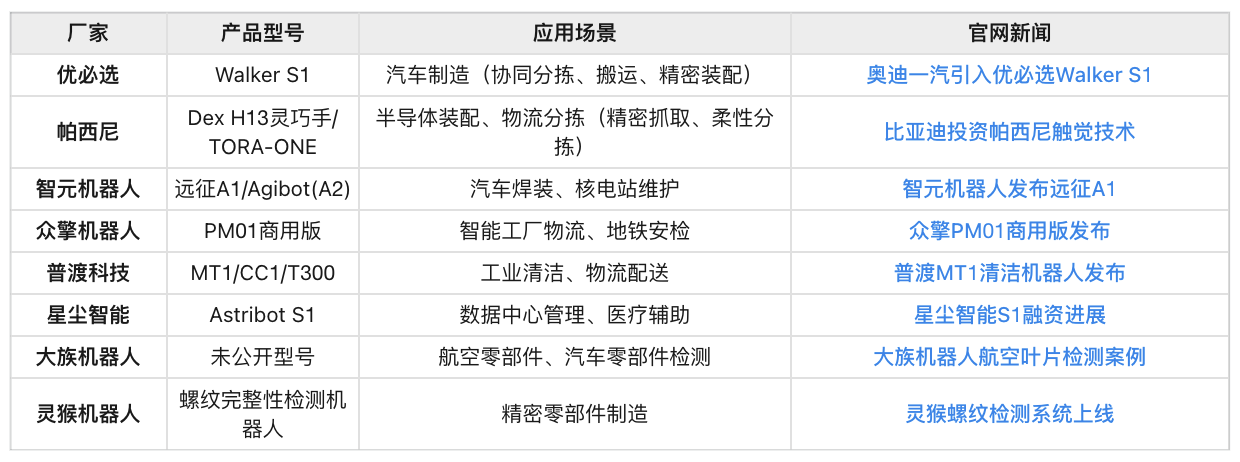
今年以来,也有不少厂商官宣了机器人“进厂”的动态。综合来看,机器人在工业领域的应用主要集中在焊接、搬运、质检、装配四大场景,核心技术包括多模态感知、AI大模型和自适应学习。厂商通过垂直行业需求定制解决方案,推动降本增效。
![]()
除了在流水线上做工人,市场也正在让机器人走进家庭做服务,下到地里做农民,爬到山上做救援……技术进化的箭头正在转向更复杂的非标领域。
IDC 最新发布的报告显示,2025年人形机器人有望在商用服务、特种作业领域从事运动速度、节拍要求较低的生产服务任务,预计将实现千台量级的小规模商用。商用服务如展厅、商超、机场等公共场的服务机器人,特种作业则是指在安全巡检、应急救援等特殊作业场景替代人类从事重复劳动、高风险的任务。
相较于开放环境中的复杂挑战,家庭生活场景中的清洁任务因其重复性强、空间结构相对标准,成为具身智能技术最先攻克的一站。目前,家庭生活场景中,家庭清洁任务的重复性强、空间结构相对标准,是具身智能最容易落地的场景之一。
在海尔与穹彻智能联合研发的衣物管理系统中,机器人通过3D视觉扫描脏衣篓,机械臂基于AnyGrasp算法抓取堆叠衣物时,能自动识别蕾丝裙装与牛仔外套的材质差异,前者采用真空吸附避免勾丝,后者切换三指抓取确保承重。
当技术突破不断刷新场景落地的可能性,商业模式的创新也在同步重塑产业生态。随着应用场景的变迁,具身智能机器人市场的商业模式也正在从“卖硬件”扩展到“卖服务”。深圳火狗智能以“机器狗租赁”降低用户门槛,北京探索“开源开放+赛事展演”推广模式。头部企业更倾向“HaaS 硬件即服务”,通过订阅制分摊研发成本——银河通用、智元机器人已获美团、华为等战略投资,押注长期生态价值。
《2025-2030中国具身智能行业发展创新策略》:预测2030年全球市场规模突破5万亿元,技术研发与商业化投资占比超60%
中国《政府工作报告(2025)》首次将具身智能列为未来产业,配套资金与税收优惠直接推动实验室与产业链扩张。
欧盟《地平线计划2030》拨款120亿欧元支持具身智能技术研发,美国《国家人工智能倡议法案》明确每年投入50亿美元。
感知技术的突破,正在让机器人从执行工具进化为具有环境交互能力的认知主体。这场融合硬件、算法与数据的“认知战争”,正在重构人机协作的底层逻辑。尽管异构传感器协同、跨模态语义对齐等技术瓶颈仍需攻克,但全球超百家实验室的联合攻关与万亿级行业投资驱动下,具身智能的“感知革命”已不可逆。
从工厂车间到家庭空间,从标准流程到非标服务……人类教会了机器人感受世界,而它们的反馈也将重塑智能边界。