距 RAG 系列课程上线已两周,不知道大家的进度如何?
前五讲里,志宏老师带我们搞懂了什么是 RAG、如何快速上手 LazyLLM,还示范了项目工程化与自定义 Reader 的实现。然而在学习群里,问题接踵而至:
🙋♂️“召回率太低,想要的内容找不回来...”
🙋♂️“模型经常答非所问,怎么破?”
可见,掌握基础并不等于拥有一套高性能、企业级 RAG 系统。第 6、7 讲 正是为此而来——聚焦效果评测与效果优化。
本贴心小编已为你把干货浓缩成精华
一起来看看
如何评测RAG系统的效果?
Why-为什么做评测?
📌量化→迭代;对齐产品指标
📌系统性多指标分析,助力系统稳步优化
What-评测维度有哪些?
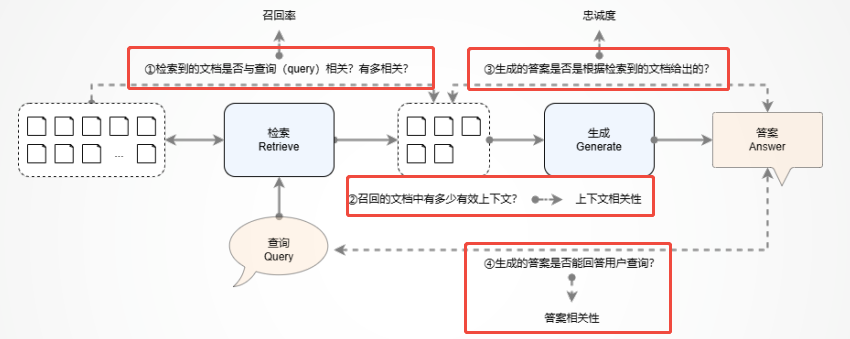
RAG系统主要有检索和生成两大阶段👇
📌检索组件评估(Retrieval)
📌生成组件评估(Generation)
🚨注意:部分评测方法依赖LLM参与
How-实施步骤
Step1:
构建评测集。
Step2:
用LazyLLM封装的组件,例如LLMContextRecall()、ContextRelevance()、Faithfulness()等。
Step3:
获得评测结果,分析并进行系统迭代。
![]()
RAG系统的效果往往取决于四个维度
实践举例
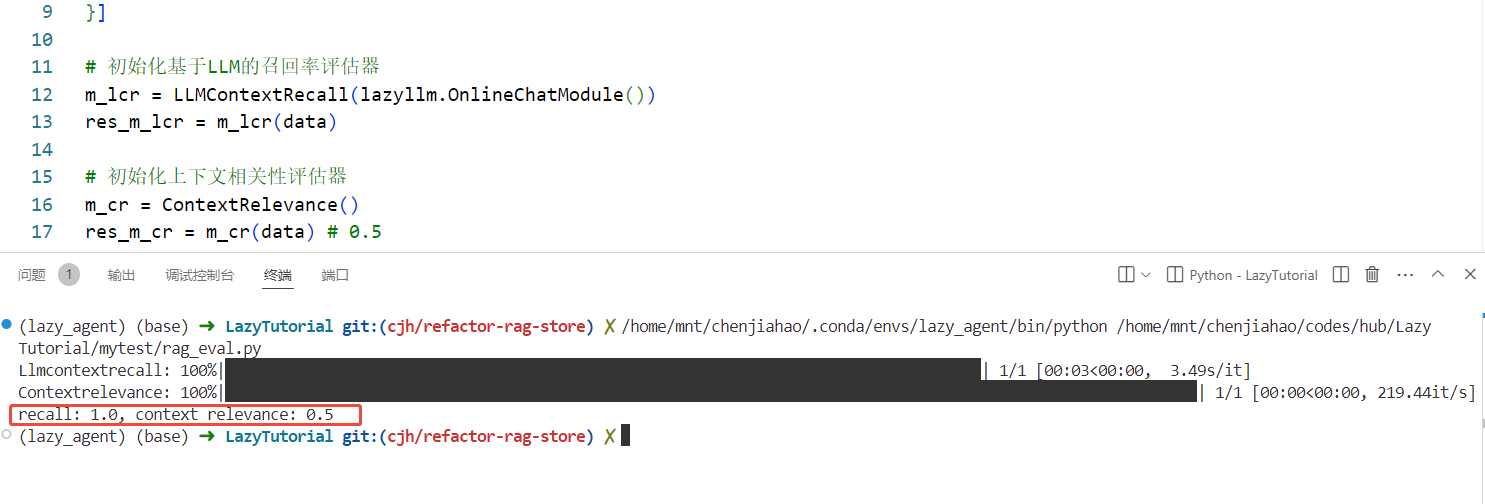
运行代码:
import lazyllm
from lazyllm.tools.eval import LLMContextRecall, ContextRelevance
data = [{'question': '非洲的猴面包树果实的长度约是多少厘米?',
'answer': '非洲猴面包树的果实长约15至20厘米。',
'context_retrieved': ['非洲猴面包树是一种锦葵科猴面包树属的大型落叶乔木,原产于热带非洲,它的果实长约15至20厘米。',
'钙含量比菠菜高50%以上,含较高的抗氧化成分。',],
'context_reference': ['非洲猴面包树是一种锦葵科猴面包树属的大型落叶乔木,原产于热带非洲,它的果实长约15至20厘米。']
}]
# 初始化基于LLM的召回率评估器
m_lcr = LLMContextRecall(lazyllm.OnlineChatModule())
res_m_lcr = m_lcr(data)
# 初始化上下文相关性评估器
m_cr = ContextRelevance()
res_m_cr = m_cr(data) # 0.5
print(f"recall: {res_m_lcr}, context relevance: {res_m_cr}")
运行结果:
![]()
测试召回率得分1.0,上下文相关性得分0.5
如何提升RAG系统的召回率?
为什么要提升召回率?
如图,“RAG的效果,重点在R”,准确的知识召回是RAG系统效果的基础。
![]()
优化召回有哪些具体策略?
检索前-优化方向:查询重写
📌扩写查询:补充或优化原始查询,使查询更清晰。
📌子问题查询:将查询拆解为多个更具体的子问题,通常用于抽象问题。
📌多步骤查询:层层递进的子问题,适用于需要多轮推理或信息串联的场景。
![]()
检索时-优化方向:检索优化策略
📌构造节点组(node group)
-
基于分块的策略
🗝️固定大小分块(例如LazyLLM预置的"CoarseChunk", "MediumChunk", "FineChunk"节点组):固定token数量
🗝️递归分块:优先按段落分块,超长则进一步分块,保留语义连贯性
🗝️语义分块:基于语义向量,按照语义单元分割。
🗝️基于文档分块:按照文档自然划分(标题或章节),仅适用于结构化文档。
-
基于语义提取的策略
🗝️关键词节点组
🗝️摘要节点组
🗝️预置QA对节点组:通过构建标准化的问答对,可直接提供完整答案,提升响应效率和体验。
📌使用向量化(Embedding),实现语义相似度检索。
-
原理:使用Embedding模型将用户查询和文档段落转换为高维向量,通过相似度计算(如余弦相似度)筛选距离相近的向量,获取对应文档信息。![]()
-
分类
🗝️稠密向量(Dense Vector):多数元素非零,支持同义词识别和语境理解,但计算开销大,且对文本细节把握弱。
🗝️稀疏向量(Sparse Vector):维度通常等于词表大小,更好保留词级细节。
🗝️相似度计算方法
🗝️内积
🗝️Cosine(向量常用):搭配摘要等概括内容效果更有,即使措辞不同,也能捕捉语义关联性
🗝️BM25(不依赖embedding,直接衡量⽂本匹配程度):更适合原文段落,精准匹配查询当中的关键词
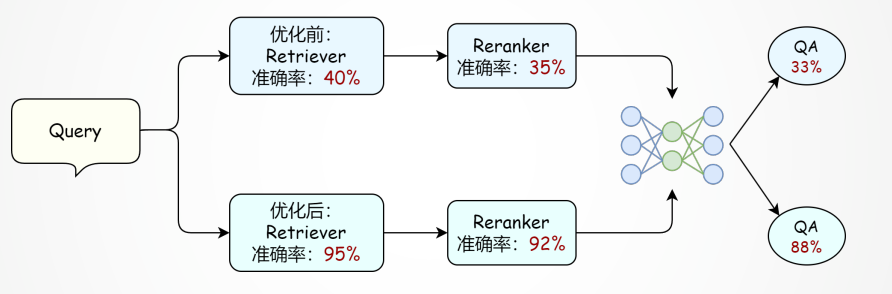
检索后-优化方向:重排序 Reranker
📌原理:先⽤检索器初筛⽂档,再⽤更强模型重排序提升准确率。
📌两阶段检索策略:
整体框架综合优化-优化方向:多路召回策略
📌思路:设置多个检索器在不同粒度进行检索或使用不同的相似度计算方法进行文档召回,对所有检索器召回的文档进行排序得到最终上下文。
📌常用方法:
-
不同粒度的检索器:如原文分块+文档摘要/问答对
-
不同相似度计算方法:如向量+BM25混合检索
实践举例:
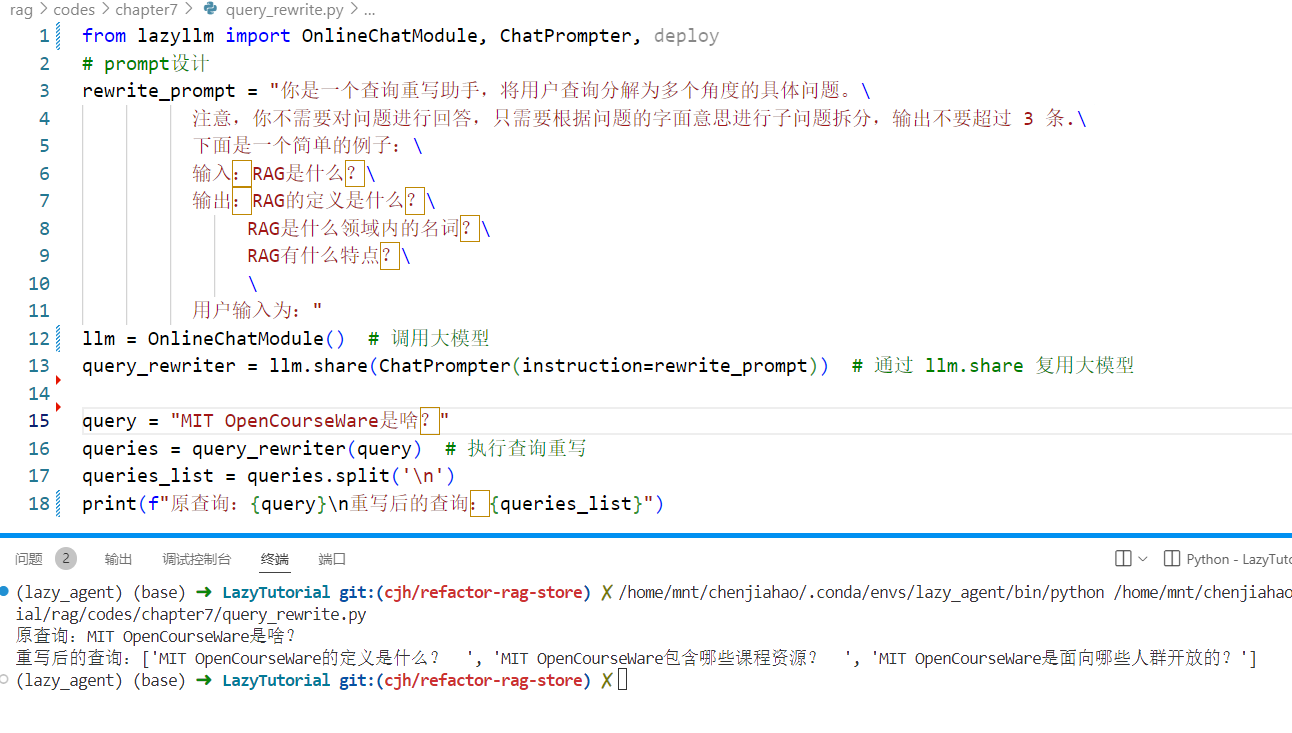
📌查询重写:编写对应功能的prompt,使用llm组件接收用户查询,输出重写后的查询。例如子问题查询:
from lazyllm import OnlineChatModule, ChatPrompter, deploy
# prompt设计
rewrite_prompt = "你是一个查询重写助手,将用户查询分解为多个角度的具体问题。\
注意,你不需要对问题进行回答,只需要根据问题的字面意思进行子问题拆分,输出不要超过 3 条.\
下面是一个简单的例子:\
输入:RAG是什么?\
输出:RAG的定义是什么?\
RAG是什么领域内的名词?\
RAG有什么特点?\
\
用户输入为:"
llm = OnlineChatModule() # 调用大模型
query_rewriter = llm.share(ChatPrompter(instruction=rewrite_prompt)) # 通过 llm.share 复用大模型
query = "MIT OpenCourseWare是啥?"
queries = query_rewriter(query) # 执行查询重写
queries_list = queries.split('\n')
print(f"原查询:{query}\n重写后的查询:{queries_list}")
运行结果:
![]()
程序将查询拆分成多个子查询
📌创建节点组:Document中使用create_node_group方法,并将分块策略传入'transform'参数当中。对于语义提取策略,transform可直接使用lazyllm.LLMParser。例如创建摘要节点组:
import lazyllm
llm = lazyllm.OnlineChatModule(source="qwen")
summary_llm = lazyllm.LLMParser(llm, language="zh", task_type="summary")
docs = lazyllm.Document("test_parse") # 初始化文档对象
# 注册摘要节点组
docs.create_node_group(name='summary', transform=summary_llm, trans_node=True, parent='CoarseChunk’)
📌在RAG中使用Embedding和Reranker:
from lazyllm import Document, Retriever, Reranker, OnlineEmbeddingModule
# 如果您要使用在线重排模型,请指定相应的 API key。
online_embed = OnlineEmbeddingModule(source='doubao')
online_rerank = OnlineEmbeddingModule(source='qwen', type="rerank")
docs = Document("/LazyTutorial/test1", embed=online_embed)
# 定义检索器
retriever = Retriever(docs, group_name="MediumChunk", similarity="cosine", topk=3)
# 定义重排器,指定输出为字符串,并进行串联,未进行串联时输出为字符串列表
reranker = Reranker('ModuleReranker', model=online_rerank, topk=3)
query = "证券管理年龄相关的限制?"
result1 = retriever(query=query)
result2 = reranker(result1, query=query)
print("检索器结果:")
print("\n\n".join([res.get_content() for res in result1]))
print("==="*20)
print("重排器结果:")
print("\n\n".join([res.get_content() for res in result2]))
运行结果:
![]()
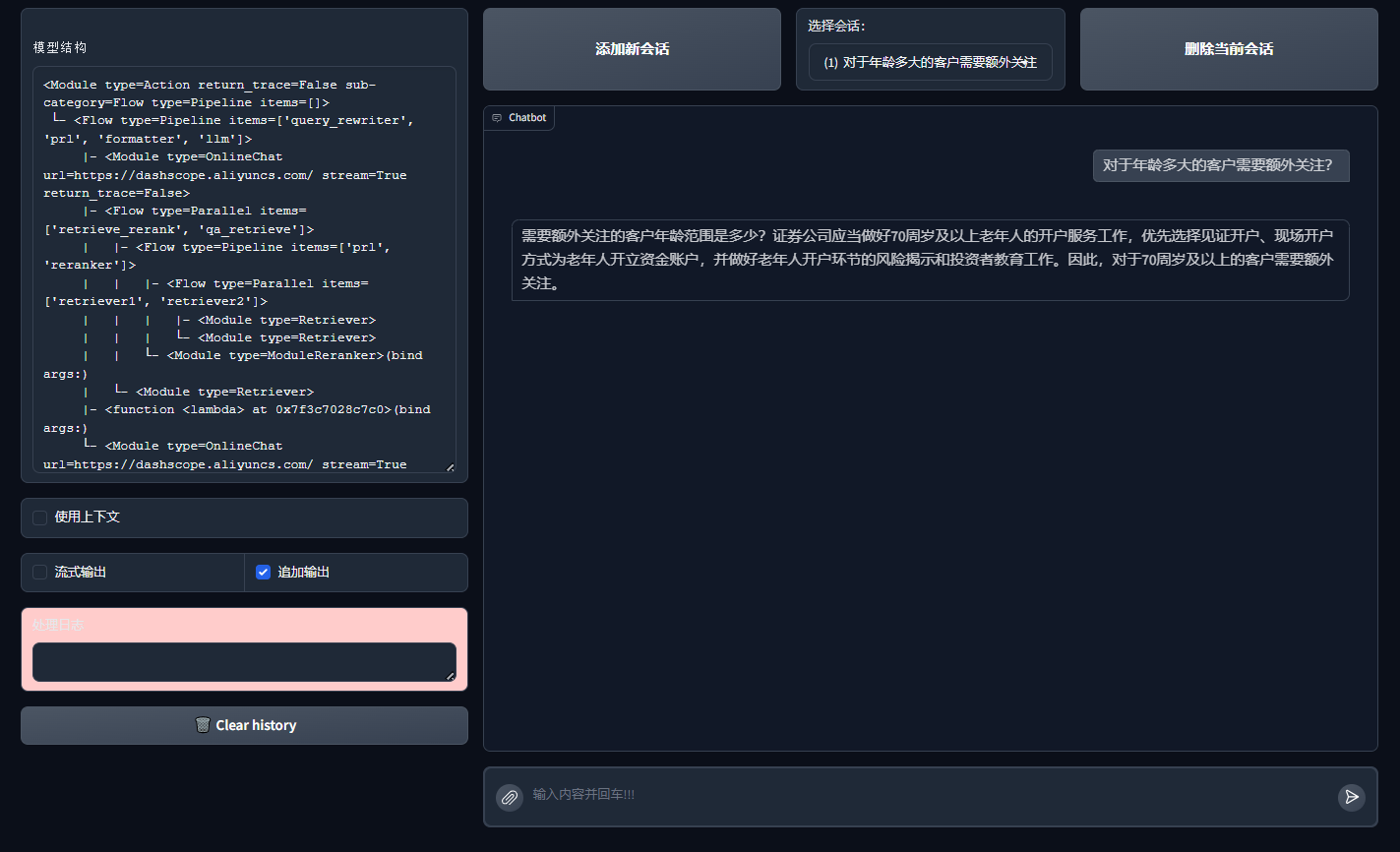
📌多路召回,综合优化后的RAG系统:
import lazyllm
from lazyllm import bind
rewriter_prompt = "你是一个查询重写助手,负责给用户查询进行模板切换。\
注意,你不需要进行回答,只需要对问题进行重写,使更容易进行检索\
下面是一个简单的例子:\
输入:RAG是啥?\
输出:RAG的定义是什么?"
rag_prompt = 'You will play the role of an AI Q&A assistant and complete a dialogue task.'\
' In this task, you need to provide your answer based on the given context and question.'
# 定义嵌入模型和重排序模型
online_embed = lazyllm.OnlineEmbeddingModule(source='doubao')
online_rerank = lazyllm.OnlineEmbeddingModule(source='qwen', type="rerank")
llm = lazyllm.OnlineChatModule(source='qwen')
qa_parser = lazyllm.LLMParser(llm, language="zh", task_type="qa")
docs = lazyllm.Document("/LazyTutorial/test1", embed=online_embed)
# 创建按行拆分以及QA对节点组
docs.create_node_group(name='block', transform=(lambda d: d.split('\n')))
docs.create_node_group(name='qapair', transform=qa_parser)
def retrieve_and_rerank():
with lazyllm.pipeline() as ppl:
with lazyllm.parallel().sum as ppl.prl:
# 多路召回(不同分块)
ppl.prl.retriever1 = lazyllm.Retriever(doc=docs, group_name="CoarseChunk", similarity="cosine", topk=3)
ppl.prl.retriever2 = lazyllm.Retriever(doc=docs, group_name="block", similarity="bm25_chinese", topk=3)
ppl.reranker = lazyllm.Reranker("ModuleReranker",
model=online_rerank,
topk=3) | bind(query=ppl.input)
return ppl
with lazyllm.pipeline() as ppl:
ppl.query_rewriter = llm.share(lazyllm.ChatPrompter(instruction=rewriter_prompt))
with lazyllm.parallel().sum as ppl.prl:
# 多路召回(分块检索与QA对检索)
ppl.prl.retrieve_rerank = retrieve_and_rerank()
ppl.prl.qa_retrieve = lazyllm.Retriever(doc=docs, group_name="qapair", similarity="cosine", topk=3)
ppl.formatter = (
lambda nodes, query: dict(
context_str='\n'.join([node.get_content() for node in nodes]),
query=query)
) | bind(query=ppl.input)
ppl.llm = llm.share(lazyllm.ChatPrompter(instruction=rag_prompt, extra_keys=['context_str']))
lazyllm.WebModule(ppl, port=23491).start().wait()
运行结果:
![]()
今天,我们先用评测指标给RAG系统把脉,再用 召回优化策略对症下药。至此,你已具备打造企业级高性能RAG的部分关键技能啦~
现在就动手实践一番,提升你的RAG系统吧!欢迎各位同学晒结果、提疑惑,一起交流RAG的学习心得~