1. 背景
近年来,随着社交媒体、流媒体平台以及XR设备的快速发展,沉浸式3D空间视频的需求迅猛增长,尤其是在短视频、直播和电影领域,正在重新定义观众的观看体验。2023年,苹果公司发布的空间视频技术为这一趋势注入了新的活力,2025年以来,轻量化AI/AR眼镜迎来爆发,持续推动对3D空间视频内容的需求。然而,尽管消费端对3D内容的需求不断上升,供给端仍面临创作瓶颈,主要体现在可用于拍摄3D视频内容的专业相机设备稀缺、制作专业度要求高以及成本高昂等问题。
我们创新性地提出了一种基于3D视觉和AIGC生成技术的方法,将存量的2D视频资源不断转化为3D空间视频资源,极大降低了3D内容的供给成本,提升了覆盖量。最新的研究成果已被多媒体领域的旗舰会议ICME 2025接受,并在京东.Vision视频频道等业务场景落地。ICME(International Conference on Multimedia and Expo)是由IEEE主办的国际多媒体与博览会,2025年会议将在法国举行,主题涵盖3D多媒体、增强现实(AR)、虚拟现实(VR)、沉浸式多媒体和计算机视觉等领域。本次会议共计收到来自全球3700多篇投稿,录用率为27%。我们提出的基于人工智能的2D视频转换为3D空间视频的方法,涉及深度估计、图像生成等算法,并构建了一个3D视频数据集,作为后续行业发展的评测基准。
图1 研究成果被ICME 2025接收
2. 技术方案
3D空间视频生成属于新视角合成任务(Novel View Synthesis),指的是在给定源图像和目标姿态的情况下,通过算法渲染生成与目标姿态对应的图像。最新的通用新视角合成方案包括基于NeRF神经辐射场、Gaussian Splatting高斯喷射以及Diffusion Model扩散模型等。与通用的任意视角合成不同,3D空间视频需为双眼分别提供具有视角差的画面,算法需根据输入的一帧左视角图像,生成对应的固定姿态右眼视角图像。
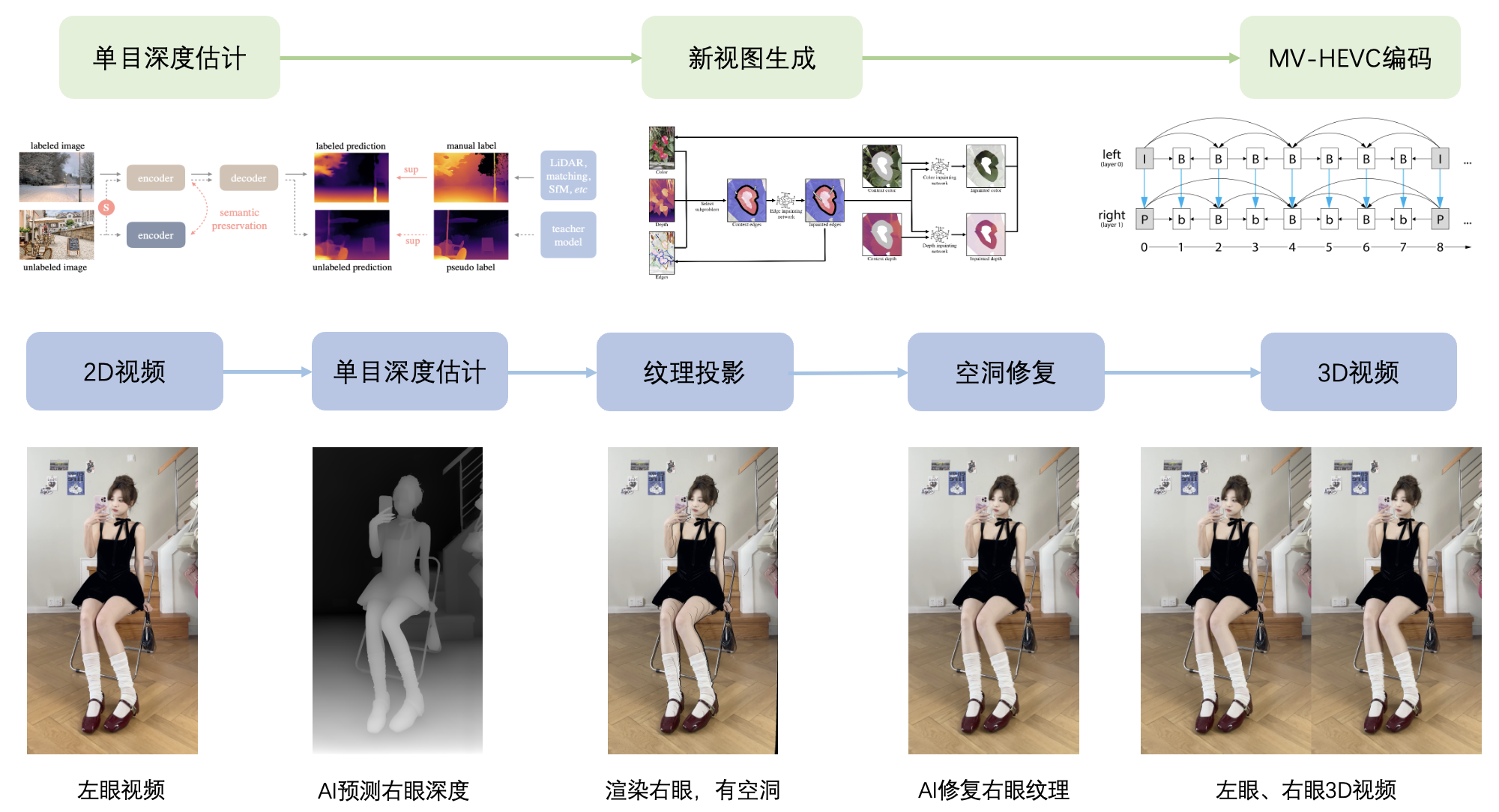
为了实现端到端的3D空间视频生成,我们的算法技术方案主要包含三个部分,分别是单目深度估计、新视角合成(包括视差图计算、Warp和空洞区域填充)以及MV-HEVC编码,整体方案如下图2所示。
图2 3D空间视频生成架构
我们的最新研究成果基于上述架构,针对单目深度估计、新视角合成和MV-HEVC编码等三个核心模块进行了创新和优化。此外,考虑到该领域内用于训练与评测的Benchmark数据集在质量和规模上普遍较差的现状,我们创建了一个高质量、大规模的立体视频数据集StereoV1K。该数据集包含在各种真实场景中捕获的1000个视频,分辨率为1180×1180,总帧数超过50万帧。StereoV1K将作为该领域的重要基准数据集。
2.1 单目深度估计
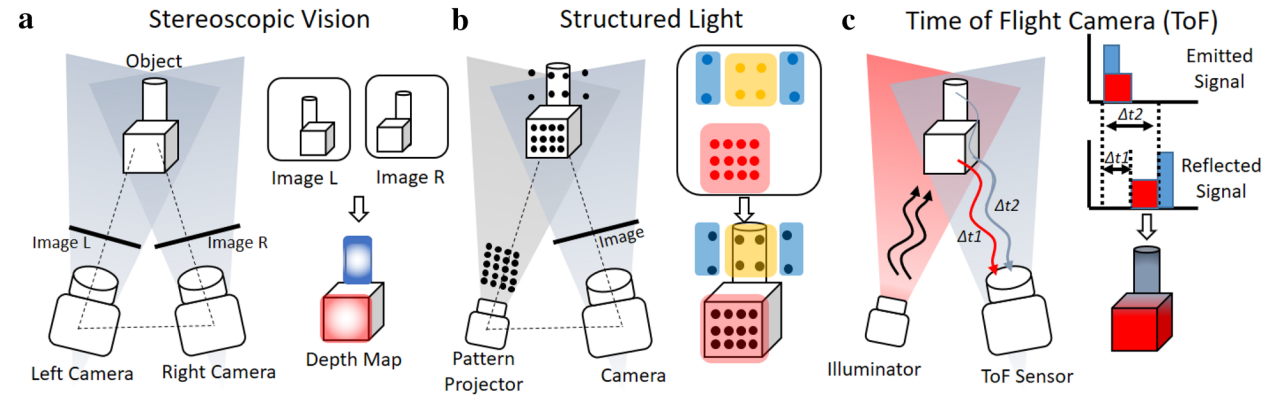
深度估计是计算机视觉领域的一个基础性问题,旨在从图像或视频中推断出场景中物体的距离或深度信息。这项技术对增强现实、虚拟现实、机器人导航以及自动驾驶汽车等应用至关重要。深度估计的目标是根据给定的输入图像,预测每个像素点或图像中物体的相对距离或真实深度值。常见的深度估计方法包括基于深度相机等TOF(Time of Flight)和激光雷达(LiDAR)硬件设备的方案、基于双目图像的立体匹配算法方案,以及基于单目深度估计(Monocular Depth Estimation, MDE)算法模型的方案。其中,单目深度估计由于成本较低、适用场景广泛,更容易普及,但算法的难度也相对较大。
图3 基于双目图像立体匹配以及硬件的深度估计方案
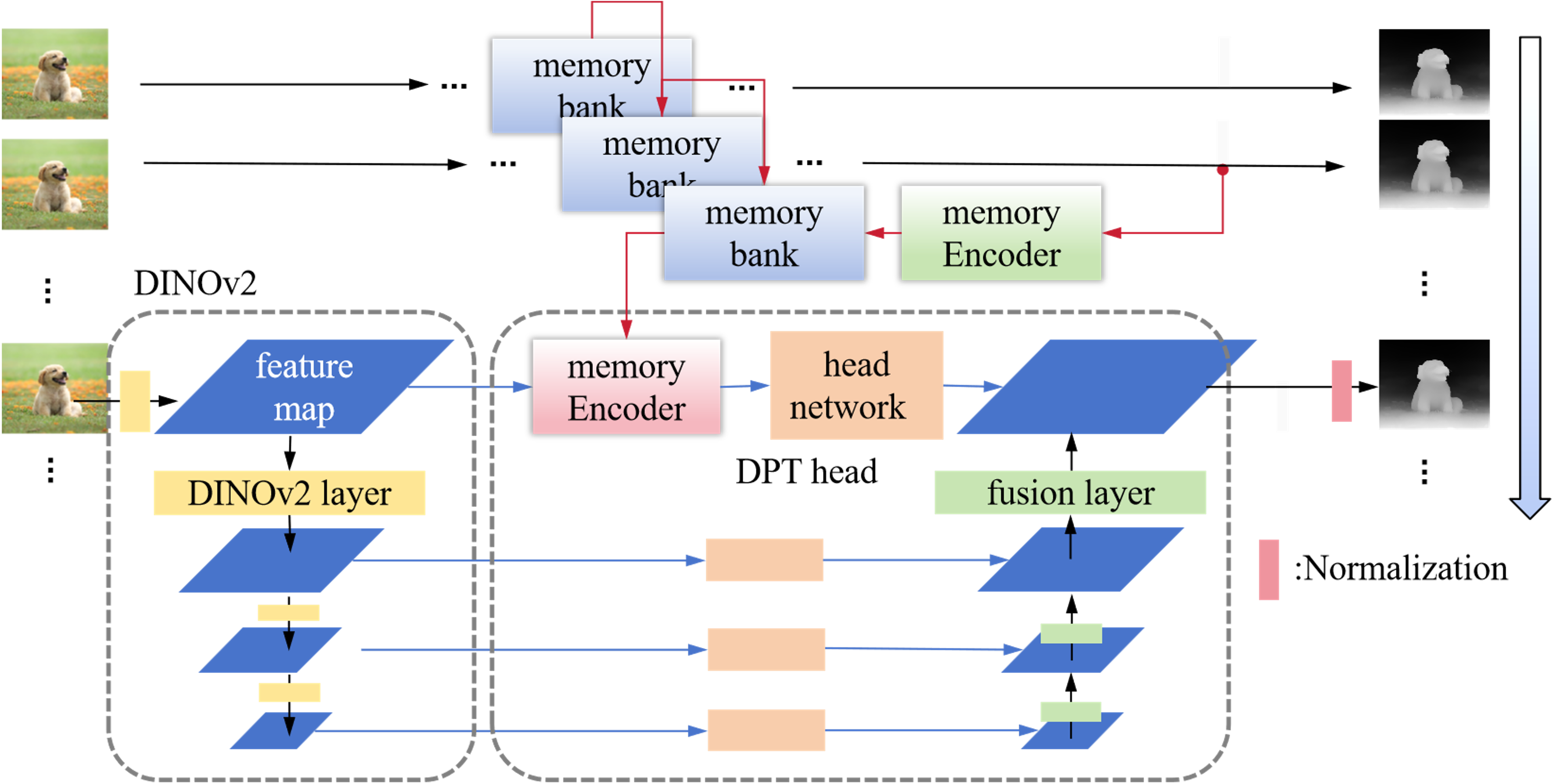
伴随着AI大模型算法的快速发展,单目深度估计在技术方案上经历了从传统方法到基于深度学习的方法,再到最新的基于大模型或生成式方法的演变。根据处理对象的不同,单目深度估计可以进一步细分为图像深度估计和视频深度估计。通常情况下,图像深度估计在细节表现上更为出色,而视频深度估计则在时序一致性方面表现更佳。此外,从估计结果的角度来看,单目深度估计还可以分为绝对深度估计和相对深度估计。绝对深度估计指的是从图像中估计出每个像素到摄像机的真实物理距离,而相对深度估计则关注图像中物体之间的深度关系,而非绝对距离。基于我们的应用场景,我们采用了一种结合图像和视频深度估计优点的单目相对深度估计算法。该算法架构如下:我们使用DINO v2作为Backbone,并结合DPT Head,同时尝试引入多帧序列的memory bank和注意力机制,以提升深度估计结果在时序上的准确性与稳定性。算法架构如图4所示。
图4 视频单目深度估计算法架构
通过在短视频等数据上构建百万级的伪标签训练数据集,并采用SFT(Supervised Fine-Tuning)和蒸馏等技术手段,我们对开源模型进行了优化。效果如图5所示,可以明显看到,我们不仅提升了深度估计的细节表现,还确保了估计结果的时序稳定性。
图5 视频单目深度估计算法优化效果对比(原始输入-开源模型-优化后模型)
2.2 新视角合成
新视角合成是视觉领域中的一项关键任务,其目标是在有限的视图基础上生成场景或物体的其他视角。这项技术在虚拟现实、增强现实、电影特效和游戏开发等领域具有广泛应用。尽管基于NeRF、3DGS和Diffusion的方法近年来取得了显著进展,但仍面临诸多挑战。例如,NeRF和3DGS方法通常只能针对单一场景进行建模,而扩散模型在生成视频时难以保证稳定性和一致性。在分析任务的特殊需求时,我们发现只需生成固定姿态的右眼视角图像,且场景具有位移小、丰富多样以及视频稳定性和一致性要求高等特点。基于这些考虑,我们最终选择采用深度Warp和空洞区域填充InPaint的方法来完成新视角合成任务。
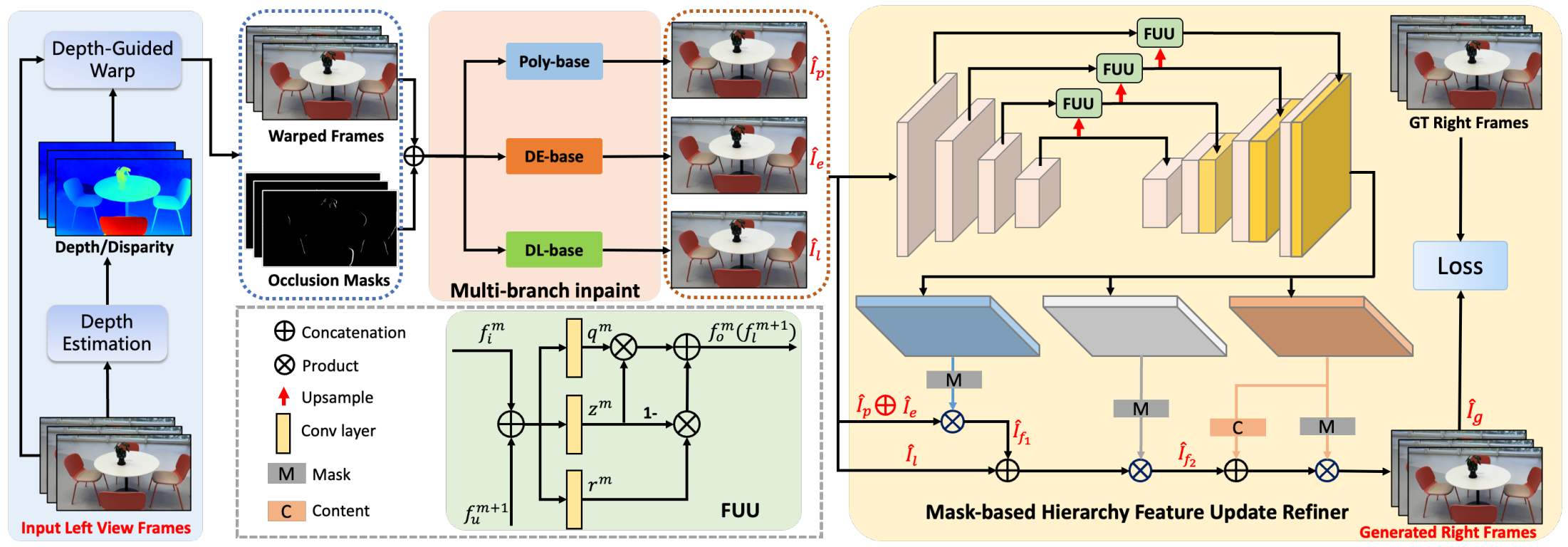
在2.1部分获取到视频对应的深度信息后,我们首先计算视差图,并引导输入的单目视频进行Warp操作,从而生成对应的待填充右视角视频和掩码视频。接下来,我们将这些数据输入到我们设计的InPaint填充框架中,以完成空洞区域的补全,最终得到完整的新视角结果。整体框架图如图6所示:
图6 新视角合成端到端算法架构
2.2.1 多分支InPaint模块
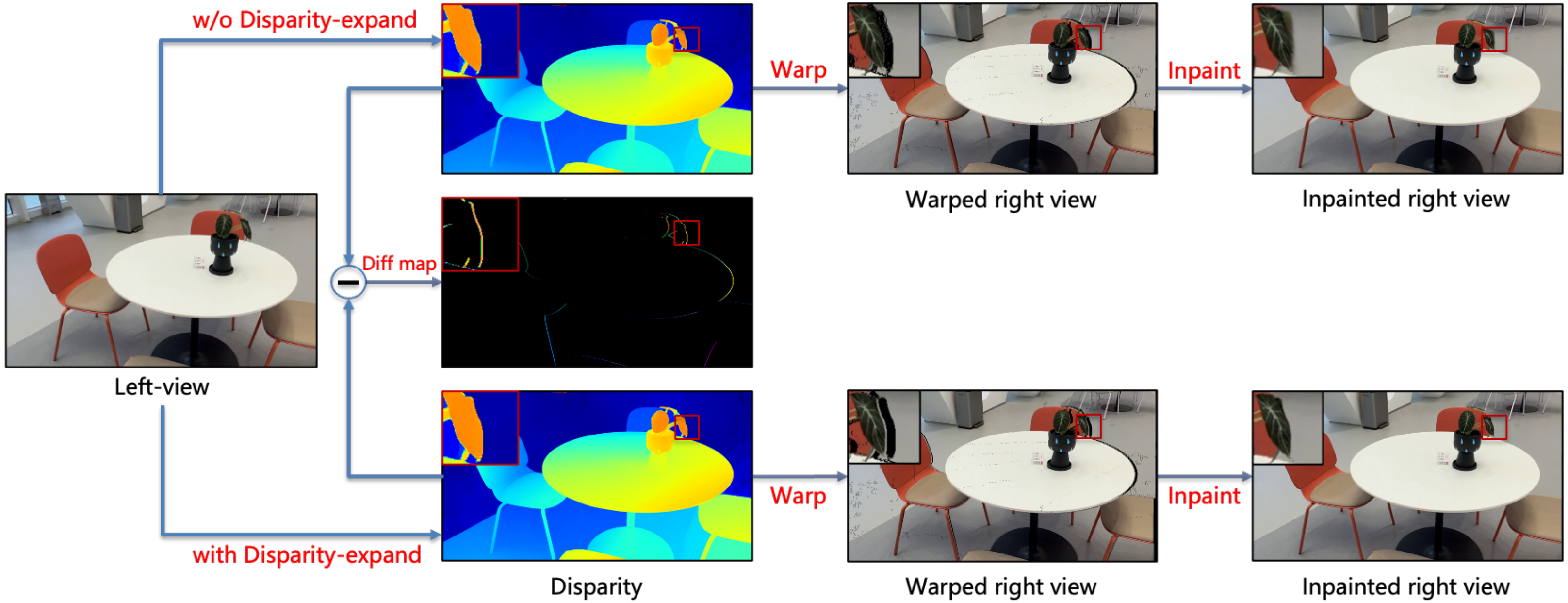
为了获得高质量和高一致性的InPaint填充效果,我们采用了多分支填充策略。该模块集成了三种InPaint分支:传统多边形插值修复(Poly-base)、深度学习神经网络修复(DL-base)和视差扩展策略修复(DE-base)。每个分支各有优缺点:(i) Poly-base能够保证视频的稳定性并减少字幕抖动,但在边缘填充时容易出现像素拉伸和毛刺;(ii) DL-base在前景和背景边缘的填充效果良好,但视频稳定性较差,可能导致字幕抖动和前景渗透;(iii) DE-base优化了像素拉伸和前景渗透问题,但在复杂背景和几何结构处可能提供错误的参考像素。我们结合这些分支的互补优势,以实现更好的填充效果。下图展示了我们视差扩展策略的有效性。
图7 视差扩展策略与优化效果
为了更好地融合上述三个分支的结果, 并进行进一步优化,我们提出了一种新颖的基于层级化特征更新的掩码融合器。该融合器的输入为多分支填充模块三个分支的输出结果,输出则为三张单通道的掩码图M1,M2,M3和一张三通道的内容图C,通过融合这些信息,我们能够获得最终的生成结果。
我们的结果在与当前先进模型的定量和定性比较中均表现出色,达到了SOTA(State-of-the-Art)水平。特别是在LPIPS指标上,我们的方法相比其他方法提升了超过28%,充分体现了结果的真实性和优越性。同时,在可视化效果方面,我们的方法显著减少了生成区域中的模糊伪影和前背景的错误拉伸,呈现出更加清晰自然的边缘和内容,如图8所示。
图8 多分支InPaint方法与其他方法结果对比
2.2.2 StereoV1K立体视频数据集
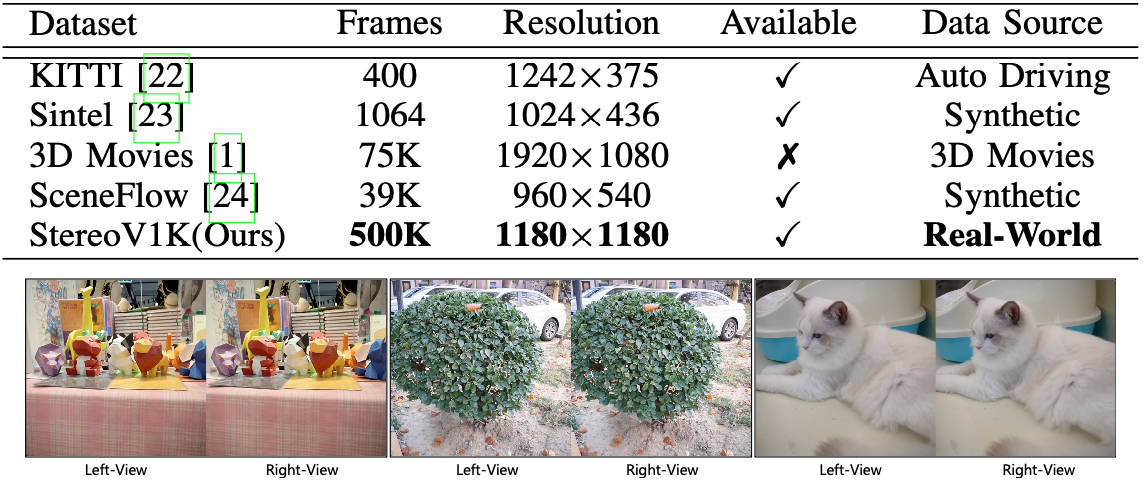
在3D空间视频生成领域,现有的公开数据集存在量级小、分辨率低、场景单一和真实性差等问题,限制了行业算法的发展与提升。为了解决这些问题,我们创建了StereoV1K,这是第一个高质量的真实世界立体视频数据集。我们使用最新的佳能 RF-S7.8mm F4 STM DUAL镜头和EOS R7专业相机,在室内和室外场景中拍摄了1000个空间视频。每个视频裁剪后的分辨率为1180×1180,时长约20秒,录制速度为50 fps,最终整个数据集的总帧数超过了500,000帧。图9展示了与其他数据集的对比以及我们数据集的示例。该数据集将作为该领域的基准数据集,推动行业的发展。
图9 StereoV1K数据集与现有数据集对比
2.3 MV-HEVC编码
通过上述算法框架,我们能够生成高质量的双目3D视频,包括左眼视频和右眼视频,其数据量是传统2D视频的两倍。因此,高效压缩和编码3D视频在实际应用中显得尤为重要,这直接关系到在线播放视频的清晰度和带宽。目前,3D视频编码主要分为两类方法:传统的SBS(Side-by-Side)HEVC编码方式以及MV-HEVC(Multi-View HEVC)编码。
• SBS-HEVC:该方法将3D视频在相同时间点的左右眼画面拼接为一个普通的2D画面,并采用传统的HEVC编码技术进行压缩。该方案实现简单,可以使用如ffmpeg等开源软件进行处理。然而,SBS-HEVC的编码压缩率较低,因此需要更大的传输带宽。
• MV-HEVC:该方法将3D视频的不同视角编码到同一码流中,允许用户在不同视角之间自由切换。编码器可以利用左右眼画面之间的相似性来进一步减少冗余,从而显著提升压缩编码效率。MV-HEVC编码是对标准HEVC的扩展,目前除了苹果AVFoundation框架中提供的闭源工具外,尚无自主可控的编码软件可供部署,用户需要自定义编码器来实现这一功能。
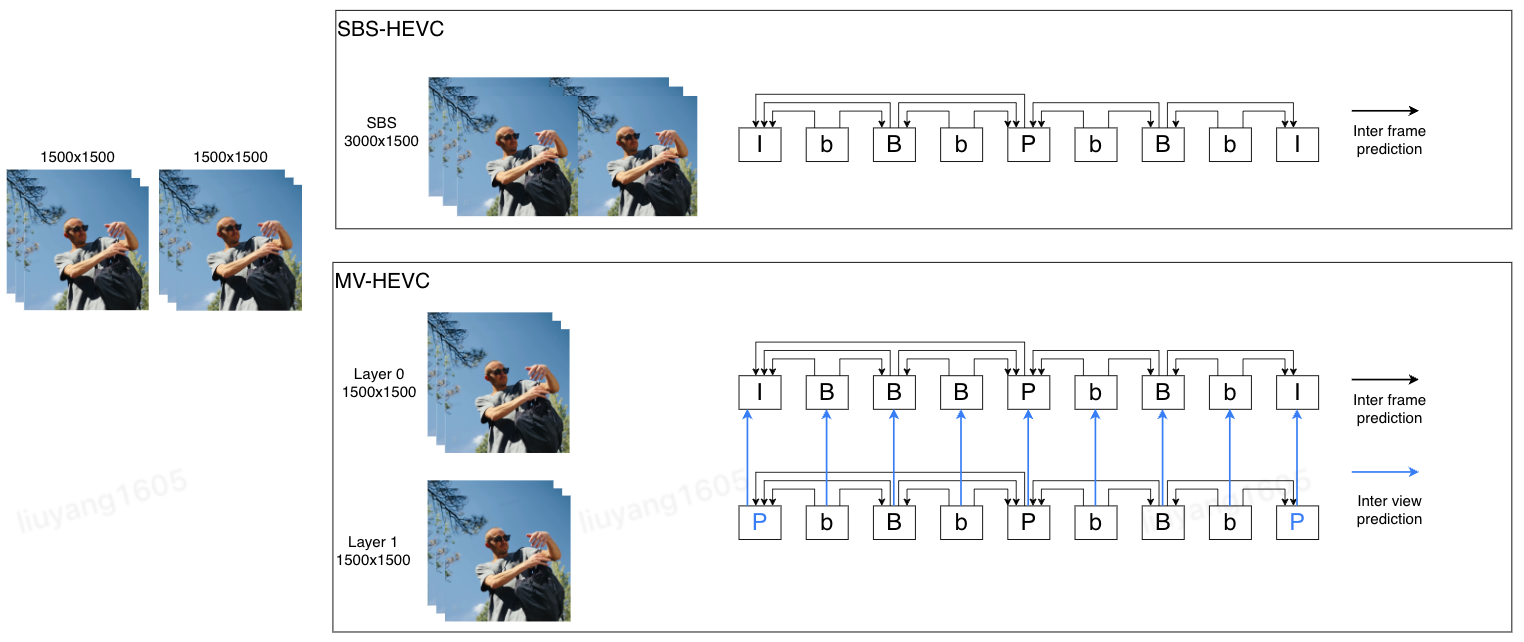
图10 SBS-HEVC和MV-HEVC编码方式对比
以1920x1080的视频为例,在SBS-HEVC编码流程中,画面以“左+右”的形式合并为3840x1080的新视频帧,然后作为普通视频进行HEVC编码,此时只能使用帧间预测(Inter frame prediction)。而在MV-HEVC编码流程中,左眼和右眼分别被称为基本层(Layer 0)和增强层(Layer 1)。除了帧间预测外,MV-HEVC还可以利用“视间预测”(Inter view prediction),因为同一时间点的左眼和右眼画面之间具有较高的相似性和冗余性,因此视间预测能够进一步提升压缩效率。
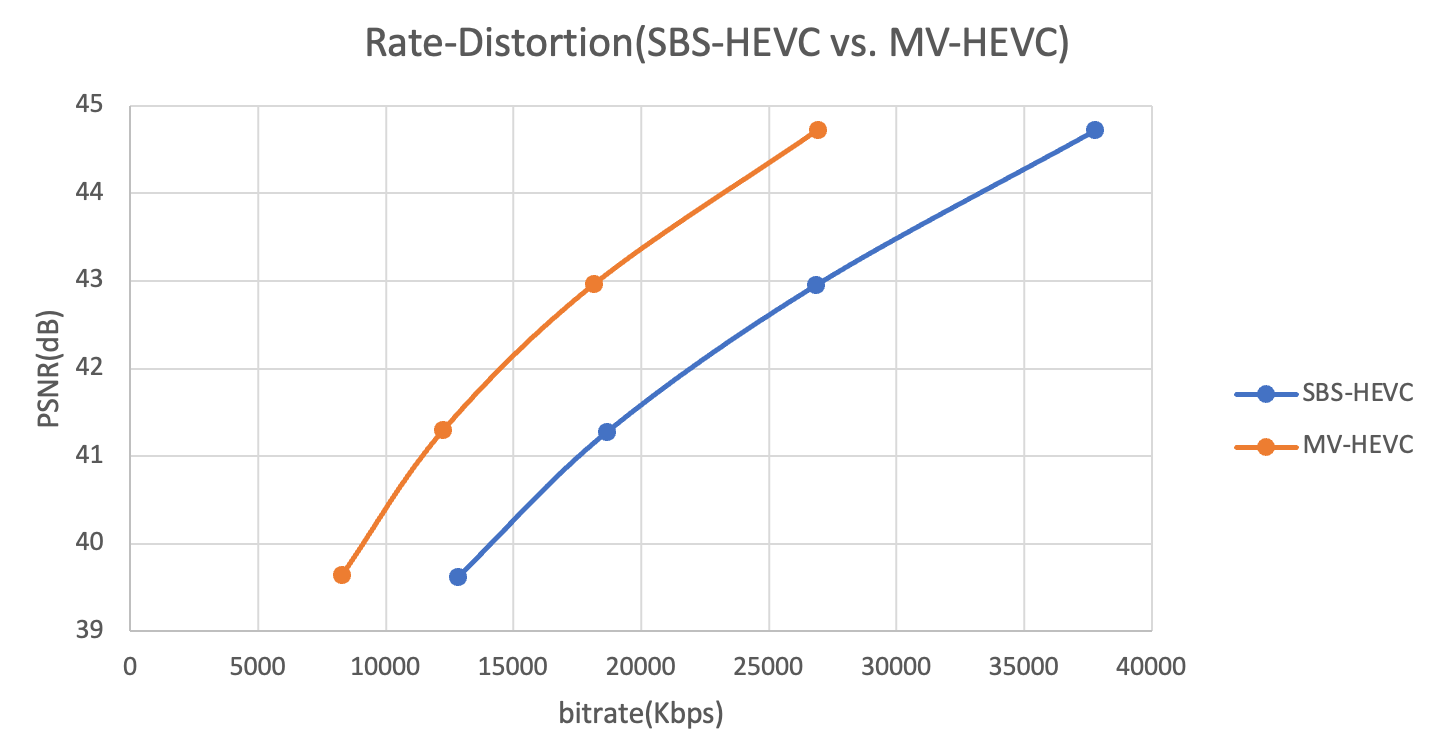
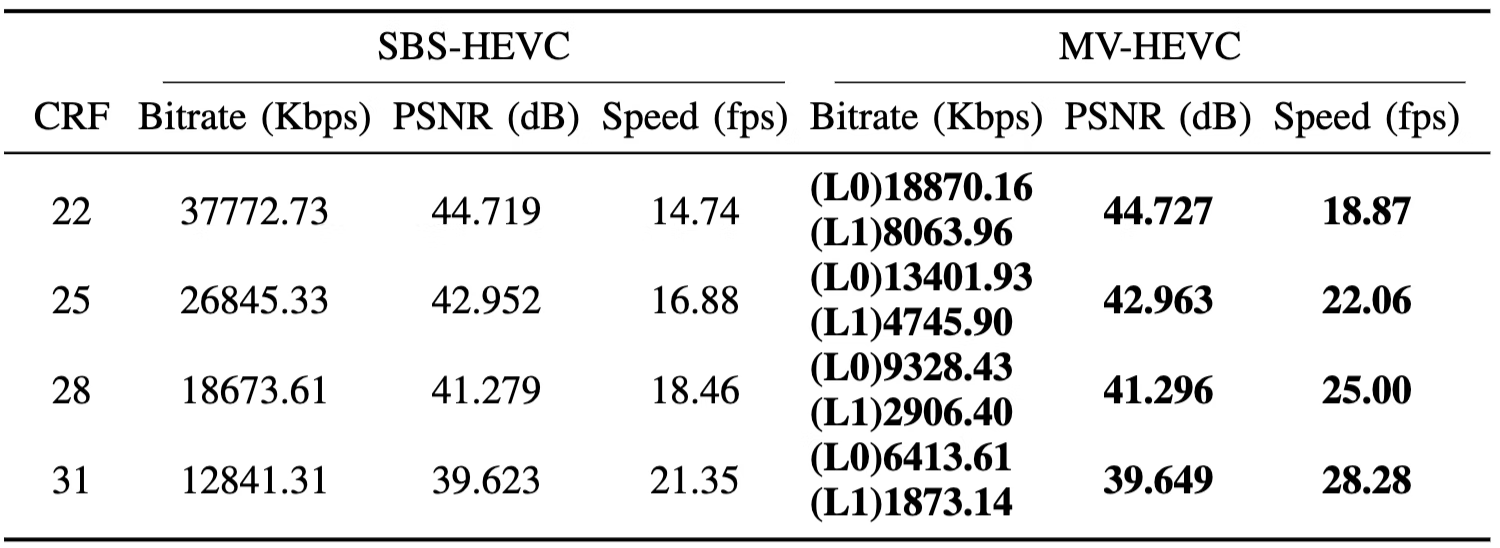
我们在标准HEVC编码器的基础上添加了对MV-HEVC扩展的支持,从而在编码性能和编码速度上都取得了显著提升。在典型测试场景中,MV-HEVC相比SBS-HEVC的BD-Rate降低了33.28%,这意味着在相同画质下,视频带宽可以减少33%;同时,编码速度平均提升了31.62%,具体数据如图11所示。
图11 SBS-HEVC和MV-HEVC的编码RD性能对比
在使用MV-HEVC解决双目3D视频的压缩编码问题后,还需要将视频和音频数据打包存储,以实现在线流媒体播放。苹果为MV-HEVC定制了封装格式,但通过ffmpeg、mp4box等开源媒体工具封装的文件在Vision Pro、iPhone等苹果设备上无法正常显示立体视频。为此,我们对由AVFoundation封装出的正常码流进行了逆向分析,从中提取出与苹果设备兼容的码流格式,并在自研编码器中实现了这一格式。与苹果设备兼容的码流格式为:
• 使用mov格式,整体符合QuickTime File Format Specification;同时符合mp4格式标准ISO/IEC 14496-15的标准定义。
• 在视频轨道的描述信息中,在stsd中重新定义hvc1、hvcC、lhvC,增加对于不同视角视频的描述,其中hvcC描述基本层码流信息,包括VPS, SPS, PPS, SEI这4个HEVC NAL头信息;lhvC描述增强层码流信息,包括 SPS, PPS信息。
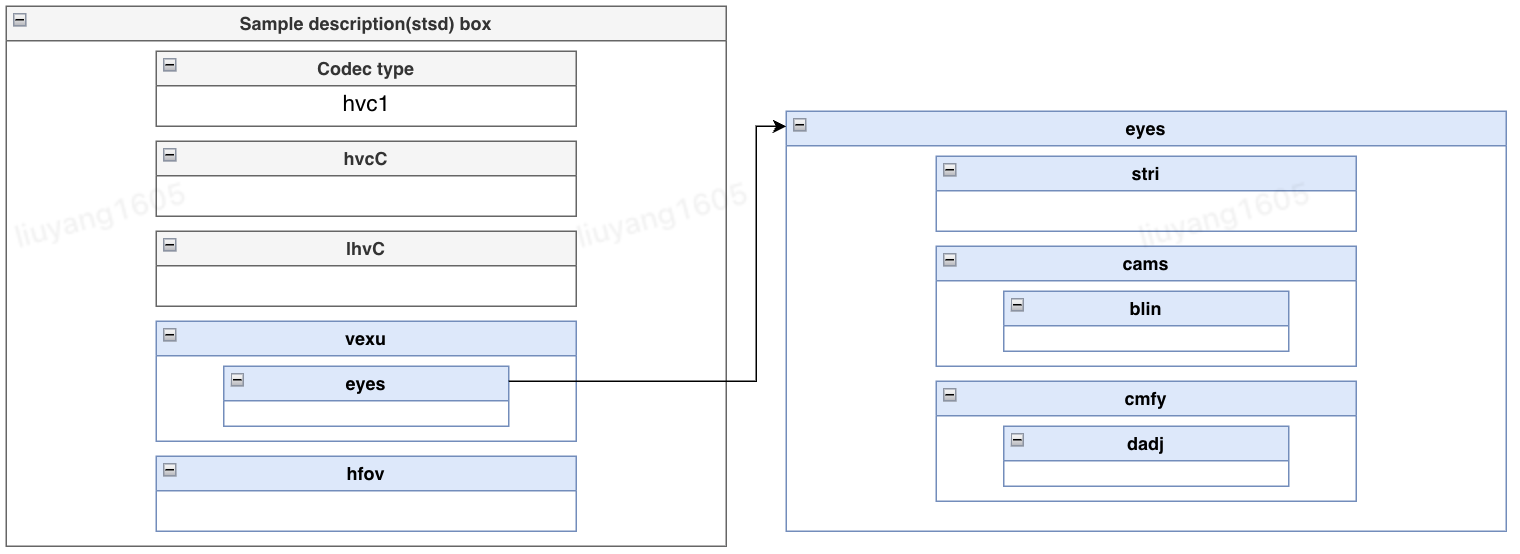
• 增加苹果自定义信息vexu、hfov,用于描述自定义信息,其数据结构如图12所示,其中关键字段有:
◦ blin:定义baseline,表示相机基线,以实际数值的1000倍来记录,例如Vision Pro的63.54mm记录为63540。
◦ dadj:定义disparity,表示水平视差调整,以实际数值的10000倍来记录,例如Vision Pro的2.93%记录为293。
◦ hfov:表示水平视场角,以实际数值的1000倍来记录,例如Vision Pro的71.59度记录为71590。
图12 苹果自定义信息vexu、hfov示意图
2.4 应用与落地
为了在实际业务中落地,我们首先简化了单目深度估计模型的尺寸,采用ViT-S作为特征编码器,并对模型进行了SFT微调。随后,我们在自建的StereoV1K数据集上训练了多分支InPaint模型,并将论文中的InPaint基础模型更换为更轻量的Transformer网络。通过这些手段,我们实现了速度与质量的平衡。在对实际业务中的大量视频进行测试后,我们发现我们的算法生成的3D空间视频很好地满足了业务需求,但仍有少数生成结果存在一些不理想的情况。未来,我们将持续迭代优化相关模型。此外,当前的生成速度也是一个重点优化方向。
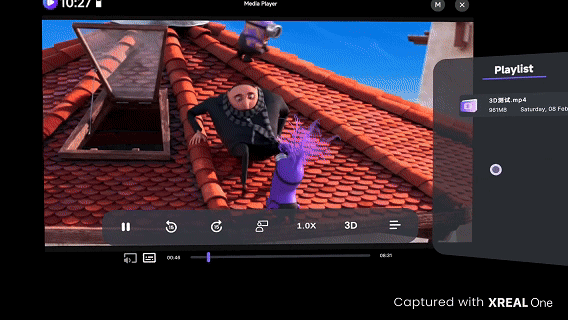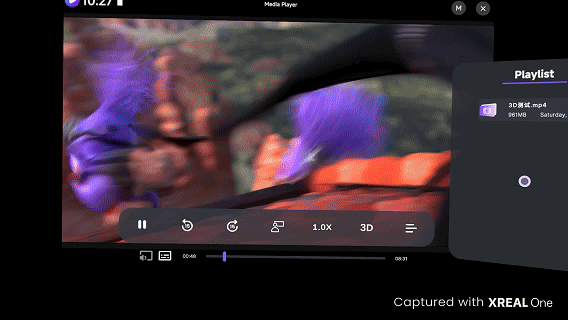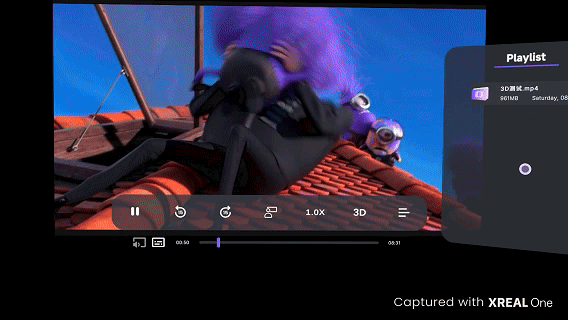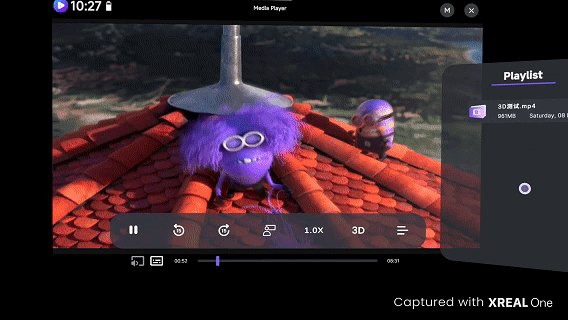
当前,3D空间视频可以在多种XR设备上观看与体验,包括Vision Pro、Pico、Quest以及AI眼镜等双目设备。例如,我们为京东.Vision视频频道提供了空间视频内容的算法服务。Vision Pro视频频道的效果如图13左图所示:通过将2D商品短视频、宣传片和发布会等资源转换为3D立体空间视频,极大提升了用户的沉浸式和立体观看体验。此外,在更轻量的AI/AR眼镜中,用户也可以方便地体验到3D视频内容带来的震撼与沉浸感,如图13右图所示。
图13 京东.Vision视频频道以及XREAL AR眼镜观看效果(图中无法显示3D效果,实际体验为3D效果)
3. 未来展望
上述介绍的3D空间视频为用户带来了全新的沉浸式体验,并为3D视频域提供了批量内容供给。然而,3D领域的内容表现形式还有很多种,例如3D模型、3D/4D空间和完整世界等。随着大模型的快速发展,算法对人类世界的建模正经历以下几个阶段:大语言生成模型 → 图像生成模型 → 视频、3D/4D生成模型 → 世界模型。可以预见,未来将有更多的工作集中在AIGC 3D/4D和世界模型生成等方向。
3.1 AIGC 3D/4D
2024年,3D/4D领域的AIGC发展迅速,尤其是从下半年开始,呈现出加速趋势。同时,新的发展方向也开始显现。从技术路线来看,有Google的CAT3D,通过单图到多图再到3D表示的方式;还有使用LRM的单图到3D表示的方案,如InstantMesh,以及近期基于结构化3D表征的Trellis。此外,一些学者正在基于4D Gaussian Splatting实现空间序列的建模。值得一提的是,3D/4D模型的可编辑性是一个重要的关注点,因为即使是专业建模师也要在生产过程中需要不断编辑和修改。最新的研究方向也开始关注生成过程的可控性与可编辑性等属性。图14所示为AIGC 3D模型与4D视频生成示例。
图14 AIGC 3D模型与4D视频生成示例
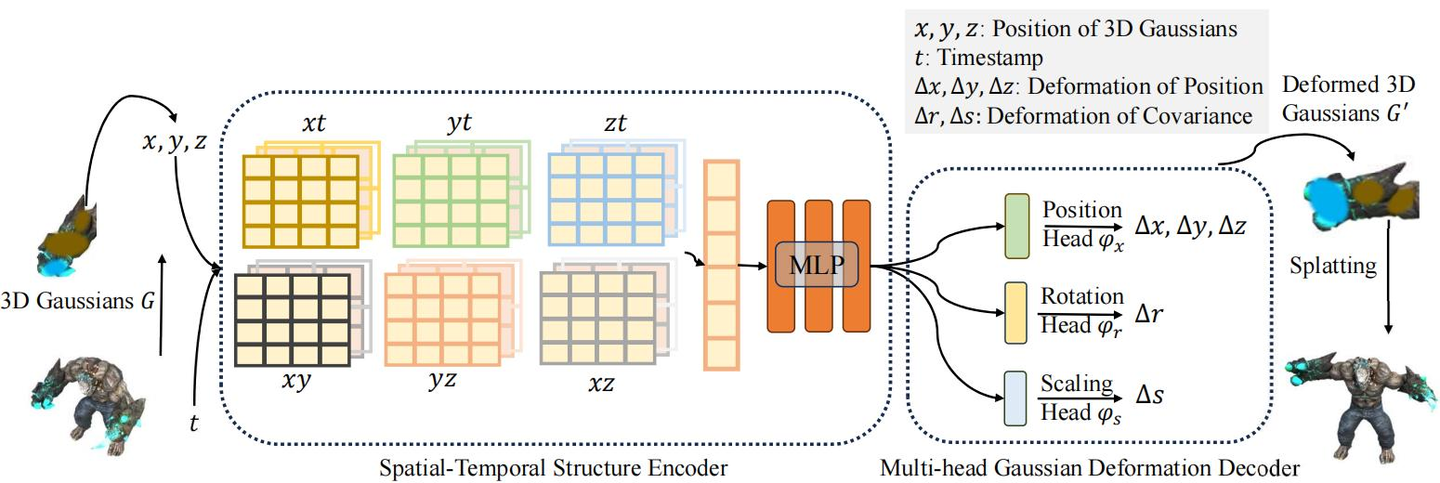
在当前的AIGC 3D模型生成技术中,像Trellis这样采用3D表征的端到端训练方案展现出显著优势。通过对3D表征进行直接的结构化编码,该模型在几何形状和纹理贴图的生成上实现了更高的准确性和鲁棒性,能够生成高质量且多样化的3D资产,具备复杂的形状和纹理细节。此外,由于模型处理的是结构化信息,它支持灵活的3D编辑,例如根据文本或图像提示进行局部区域的删除、添加和替换,如图15左图所示。在4D视频生成技术中,当前主流的方案是采用带有时序的Gaussian Splatting表征进行建模,如图15右图所示。由于高斯表征本身的大小以及存在维度提升,4D视频面临着数据体量大、模型复杂度高、渲染性能压力大等挑战。
图 15 Trellis根据文本提示词进行纹理材质以及几何结构的局部编辑以及典型4D Gaussian Splatting架构
3.2 世界模型
目前,世界模型在学术界和工业界尚未形成明确的概念,关于其是模拟世界还是感知世界也没有统一的范式。然而,从近期的进展来看,世界模型需要具备时序和立体空间的结构化建模能力。建模后的数据应具有稠密的语义表征和局部可编辑性,同时整个时序与空间域需具备可交互性。最终目标是实现对现实空间的复刻,甚至对现实空间进行创作与未来预测。图16所示为World Labs世界模型以及Meta orion AI 眼镜空间万物感知。
图16 World Labs世界模型以及Meta orion AI 眼镜空间万物感知
我们将持续关注并深入跟进3D领域的最新进展,特别是在技术创新和应用实践方面的动态。结合京东广泛的业务场景,我们致力于将这些前沿技术落地并转化为实际应用,以满足用户日益增长的需求。通过不断探索3D技术在电商、广告、内容等多个领域的潜力,我们希望为用户带来全新的体验,提升他们的购物乐趣和互动感。我们的目标是通过创新的解决方案,推动行业的发展,为用户创造更高的价值和更丰富的体验。
4.参考文献
1. Zhang J, Jia Q, Liu Y, et al. SpatialMe: Stereo Video Conversion Using Depth-Warping and Blend-Inpainting[J]. arXiv preprint arXiv:2412.11512, 2024.
2. Yang, Sung-Pyo, et al. "Optical MEMS devices for compact 3D surface imaging cameras."Micro and Nano Systems Letters7 (2019): 1-9.
3. Bhat S F, Birkl R, Wofk D, et al. Zoedepth: Zero-shot transfer by combining relative and metric depth[J]. arXiv preprint arXiv:2302.12288, 2023.
4. LiheYang, BingyiKang, ZilongHuang, ZhenZhao, XiaogangXu, Jiashi Feng, and Hengshuang Zhao, “Depth anything v2,” arXiv preprint arXiv:2406.09414, 2024.
5. Teed Z, Deng J. Raft: Recurrent all-pairs field transforms for optical flow[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16. Springer International Publishing, 2020: 402-419.
6. Zhang K, Fu J, Liu D. Flow-guided transformer for video inpainting[C]//European conference on computer vision. Cham: Springer Nature Switzerland, 2022: 74-90.
7. Shangchen Zhou, Chongyi Li, Kelvin CK Chan, and Chen Change Loy, “Propainter: Improving propagation and transformer for video inpainting,” in ICCV, 2023, pp. 10477–10486.
8. Han Y, Wang R, Yang J. Single-view view synthesis in the wild with learned adaptive multiplane images[C]//ACM SIGGRAPH 2022 Conference Proceedings. 2022: 1-8.
9. Wang L, Frisvad J R, Jensen M B, et al. Stereodiffusion: Training-free stereo image generation using latent diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 7416-7425.
10. Zhen Lv, Yangqi Long, Congzhentao Huang, Cao Li, Chengfei Lv, and Dian Zheng, “Spatialdreamer: Self-supervised stereo video synthesis from monocular input,” arXiv preprint arXiv:2411.11934, 2024.
11. Mildenhall B, Srinivasan P P, Tancik M, et al. Nerf: Representing scenes as neural radiance fields for view synthesis[J]. Communications of the ACM, 2021, 65(1): 99-106.
12. Kerbl B, Kopanas G, Leimkühler T, et al. 3d gaussian splatting for real-time radiance field rendering[J]. ACM Trans. Graph., 2023, 42(4): 139:1-139:14.
13. Gao R, Holynski A, Henzler P, et al. Cat3d: Create anything in 3d with multi-view diffusion models[J]. arXiv preprint arXiv:2405.10314, 2024.
14. Xu J, Cheng W, Gao Y, et al. Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models[J]. arXiv preprint arXiv:2404.07191, 2024.
15. Xu Z, Xu Y, Yu Z, et al. Representing long volumetric video with temporal gaussian hierarchy[J]. ACM Transactions on Graphics (TOG), 2024, 43(6): 1-18.
16. Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
17. Xiang, Jianfeng, et al. "Structured 3d latents for scalable and versatile 3d generation." arXiv preprint arXiv:2412.01506 (2024).
18. Wu G, Yi T, Fang J, et al. 4d gaussian splatting for real-time dynamic scene rendering[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024: 20310-20320.
21. Gerhard T, Ying Chen, Karsten Müller, et al. Overview of the Multiview and 3D Extensions of High Efficiency Video Coding. IEEE TRANS. ON CSVT, VOL. 26, NO. 1, JANUARY 2016