引言
大模型应用的春天来了。在人工智能的浪潮中,大模型正成为推动技术变革的核心力量。春节前,DeepSeek R1 的发布在全球范围内引发了巨大轰动,它不仅在性能上与 OpenAI 的模型不相上下,更凭借其基于 CoT(Chain of Thought)的推理过程,展现出强大的逻辑能力,同时,开源和低成本的优势,让众多企业迅速接入。DeepSeek 已然成为各行业关注的焦点,今年无疑是大模型应用爆发的关键一年。
一、大模型应用的爆发:为什么是2025?
技术的发展并非一蹴而就,而是经历从萌芽到成熟,再到广泛应用的过程。20多年前的PC互联网和10多年前的移动互联网的兴起,都经历了这样的阶段,如今,从周期和技术成熟度来看,AI大模型也正站在爆发的前夜。
DeepSeek R1 的出现,不仅展示了大模型的强大能力,更以开源和低成本的姿态,为更多企业和开发者提供了平等的机会。短短一个多月,国内众多公司纷纷接入,甚至包括腾讯、阿里等行业巨头。这种现象表明,大模型的应用已经具备了广泛落地的基础,从金融风控到投资决策,从智能家居到医疗辅助,大模型的应用场景正在不断拓展。2025年,或许就是这场技术变革的“临界点”。
二、大模型的应用价值:不只是“通用聊天”
很多人可能会问:既然 DeepSeek、ChatGPT 等聊天类App已经如此强大,为什么还要开发基于大模型的应用呢?原因主要有两个方面:一是通用聊天应用虽然灵活,但在很多专业领域,普通用户并不具备问正确问题的能力;二是大模型推理需要基于场景的相关数据,通用聊天工具从互联网搜索到的数据,可能不全或者不准确,在医疗、投资等大部分专业领域需要准确数据的场景,并不可靠。
在当下的技术发展阶段,大模型尚未真正具备智能,其核心价值在于卓越的数据处理能力。这种能力在众多专业领域中展现出巨大的潜力,能够显著提升工作效率。以医疗领域为例,大模型能够基于患者的病历、检查报告、生理数据等多维度信息,快速进行病情分析和辅助诊断,为医生提供精准的决策支持。在投资领域,它也能迅速获取市场动态数据,完成基本面与技术面的深度分析,为投资者提供科学的决策参考。这些应用场景充分证明,大模型的价值远不止于简单的“聊天”。
三、做好大模型应用的关键:四大要素
过去两年,我们在积极探索大模型的应用过程中:从营销运营领域的热搜机器人、到 Coding 领域的 JoyCoder,金融科技领域从社区的热点话题生成、到基金/保险产品解读。DeepSeek R1 的出现,让我们更加意识到,目前的应用还非常初级,只是有,离好还有很大的差距和空间。基于过往的这些场景探索,大模型应用要取得更好的效果,我们认为需要综合考虑以下4大要素:好的效果 = 大模型 + 专业知识 + 知识库 + 工程架构。
(1)专业知识和交互设计:让大模型“容易使用”
DeepSeek 等通用聊天类App虽然简单,但要用好的话往往需要用户具备专业知识,看似普惠,事实上门槛比较高,交互体验也不够便捷。例如在投资领域,普通用户可能并不知道该问什么问题,如果只是问“今天的市场行情怎么样,这只股票是买入还是卖出”,大模型并不能给出能赚到钱的答案。而稍有一些投资经验的人,可以问“分析一下沪深300指数的技术面,时间从2021年到现在,从形态、均线、趋势等看走势是反弹还是反转,并用MACD、背离、量能等交叉确认”等更复杂的问题。如果涉及到更具体买卖决策和调仓建议,可能需要更加深入和专业的问题。
此外,交互不够便捷也是一大问题。用户需要组织语言、打字输入,还要在聊天工具和具体的如券商的App之间来回切换,体验较差。今日头条等之所以能取代门户网站,正是因为其在交互上体验更好。因此,交互设计和专业知识的结合是大模型应用成功的关键,场景化的AI是探索的一个方向。
(2)领域知识库和搜索能力:让大模型“有据可依”
问准确的问题还不够,还需要有充分的上下文信息以及准确获取的能力。首先,信息的及时、准确和丰富至关重要。大模型是神经网络,仿照大脑的原理构建,可以看作一个看完了互联网上所有数据的超级专家。就像让医生看病或操盘手交易,需要告知其“病情”或“行情”才能开展工作,信息越及时和全面,专家的决策就越准确、可靠。
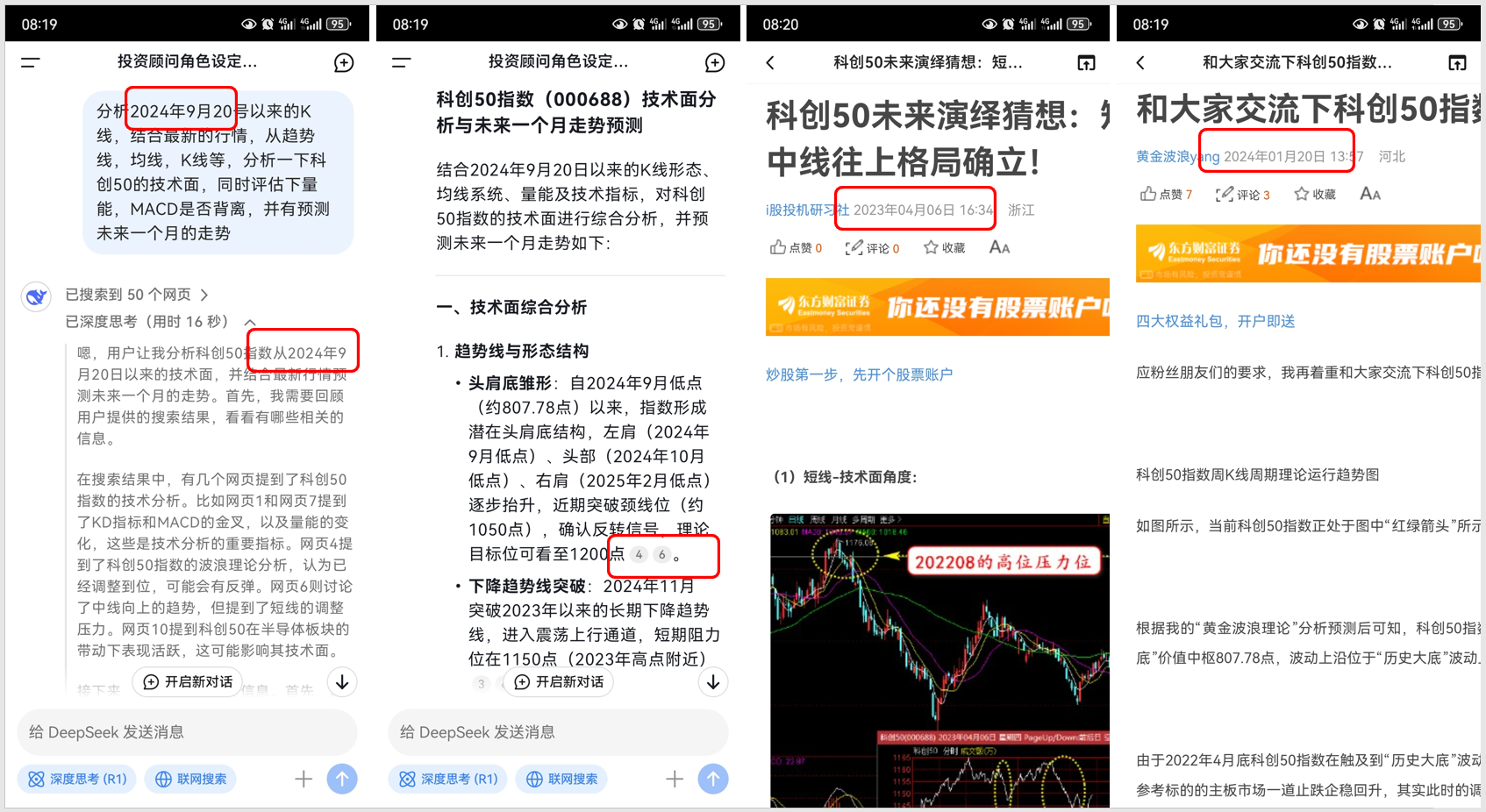
DeepSeek App 虽然具有联网能力,能在回答问题前搜索相关信息,但搜索回来的数据可能存在问题,如数据过期或数据较少,导致推理结果不够准确。比如下图案例,做出推理结论而引用的数据4和6是过期的,导致看起来完美的推理逻辑也是无法用的。企业要想用好大模型,必须建立本地知识库,确保数据的数量和质量。在 DeepSeek 这类大模型开源后,算法已经平权,企业之间的竞争又回到了数据这个生产力要素。
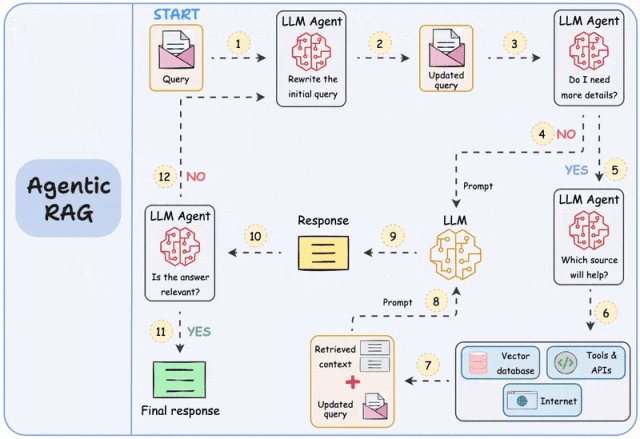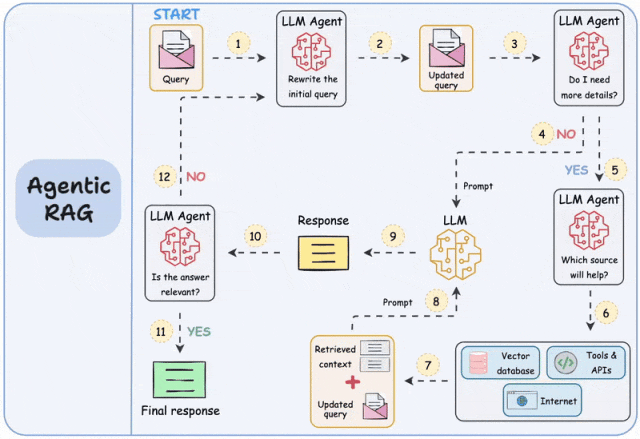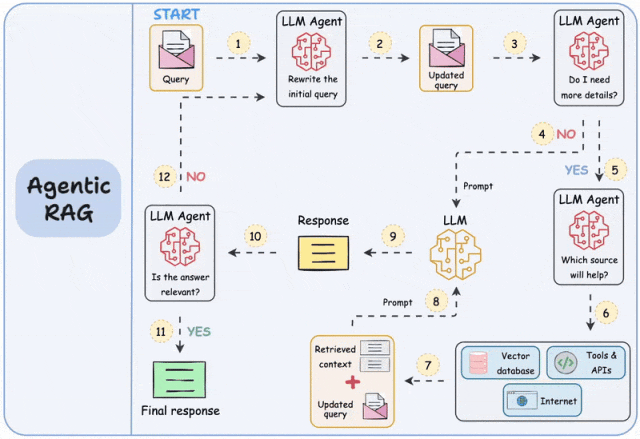
其次,高效准确地获取数据也极为关键。即使知识库建的很大、很丰富,搜索能力也至关重要,这是百度、谷歌等深耕多年的能力,技术门槛比较高,要做好并不容易。知识库本身的架构,访问权限设计,以及各种RAG技术,都极为关键。(图片来自于网络)
(3)Agent架构与工程能力:让大模型“激发潜能”
对于简单问题,大模型可以通过一轮对话给出答案;而对于复杂问题,如买一张去西藏的便宜机票,或判断中证A500指数基金什么时候买,则需要更加复杂的设计,如果能更好地组织和引导,类似于人类的头脑风暴和专家讨论,把多个专家的智力都激发出来,就有可能找到更好的解决方案。
大模型是一个待机的超级专家,提供简单的API供应用随时调用,如何面向大模型编程,激发其潜力需要研发人员的精心设计,目标是大模型成为真的“大脑”,取代原来预设的业务流程,策略引擎和流程编排工具,让应用具备自主智能。通过Agent架构,甚至多Agent(智能体)交互,可以引导大模型进行多轮交互和逻辑推理,从而获得更准确的结果,工具/MCP,记忆,规划、思维链、反思等架构和设计模式,需要持续探索应用。(图片来自于网络)
(4)大模型自身:“选择比拥有更重要”
大模型是整个应用的核心部件,当然是最重要的。但从应用开发的角度来看,选择合适的大模型并灵活切换更为关键,应用系统的架构,需要更加灵活的支持多个大模型。DeepSeek R1的成功表明,大模型在持续的竞争和迭代,另外,不同大模型在不同领域的潜质也不一样,就像有些人擅长科学,有些擅长经商,有些擅长音乐,多Agent系统中,每个Agent可以使用不同的大模型。未来,大模型的市场竞争将更加激烈,选择比拥有更重要。
四、大模型的未来:探索与展望
DeepSeek R1 是终点吗?当然不是。Transformer 是实现 AGI(通用人工智能)的终极算法架构吗?估计也不是。吴军、杨立琨、王兴兴等专家都曾提出过类似的观点:尽管Transformer架构在自然语言处理等领域取得了巨大突破,但它并非万能。未来仍有可能出现更强大的算法,推动人工智能迈向新的高度。
数据真的已经用完了吗?应该也不是。人类在学习和沉淀规律时,从来不仅仅是依赖过往的书本知识。从开普勒三大定律到牛顿力学,这些伟大的科学发现,都是通过对现实世界中的数据进行获取、分析和总结得出的。无论是日月星辰的运行轨迹,还是潮起潮落风云变幻,亦或是粒子撞击的微观过程,甚至是人类自身的脉搏跳动,只要通过摄像机、传感器等工具进行捕捉,就能从这些更广泛、更丰富的自然界获取数据。这些数据,或许将成为未来人工智能发展的重要“养料”,为模型的训练和优化提供新的思路和方向。
除了算法和数据,大模型的未来发展还需要强大的算力。量子计算或许是解决这一问题的关键方案。哦,还有能源问题,小时候看《变形金刚》,一直不理解他们为什么整天争夺“终极能源”,未来当硅基生命充满大地和天空的时候,能源问题或许将成为制约技术发展的关键瓶颈。
这一天,或许终将会到来。