作者:来自 Elastic Han Xiang Choong
仅靠向量搜索无法考虑时间、空间或意图,限制了其有效性。值得庆幸的是,解决方案在于将 Elastic 的传统搜索功能与智能体驱动的 LLMs 结合使用。
今天,我们将论证采用智能体驱动的 LLM 方法来提升搜索相关性并解决复杂的用例问题,并以“了解你的客户”(Know-Your-Customer - KYC)用例来展示这些优势。
这是之前在 Searchlabs 发布的 Agentic RAG 文章的后续内容。前文介绍了代理在 RAG 用例中的实现,并提供了必要的背景知识。在此基础上,我们进一步扩展了该实现,并集成了一个 Streamlit UI,界面如下所示:
![]()
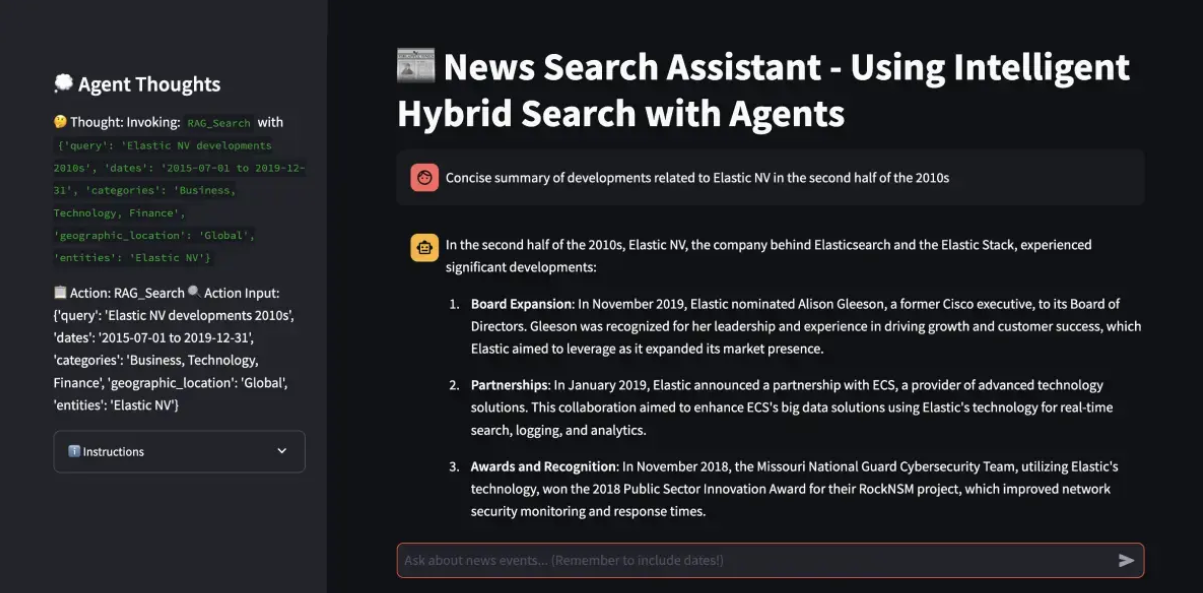
智能混合搜索用户界面。关键兴趣点是左边的代理思想/动作,它强调了代理如何制定更复杂的查询。
完整代码位于此 Github repo 中。
首先,运行以下命令来安装依赖项:
pip install elasticsearch==8.17.1 langchain==0.3.15 streamlit==1.37.1
并运行以下命令来启动应用程序:
streamlit run news_search_agent.py
有关设置和数据的更多详细信息,请参阅原始博客。
我们开始吧!
引言
我有一个包含 756,880 篇新闻文章的索引,这些文章来自 POLITICS 数据集。
我已经为所有文章的文本内容生成了嵌入向量,现在我希望使用它进行检索增强生成(Retrieval-Augmented Generation,RAG),就像你所做的那样。或许可以参考其他 SearchLabs 文章中记录的流程。
我们将输入一个查询,执行向量搜索,将搜索结果传递给 LLM(本例中是托管在 Azure OpenAI 上的 GPT-4o mini),然后请求其生成答案。不做额外优化,只是纯粹的 RAG。
让我们想一个查询来测试……这个怎么样?
Query 1:
Review Singapore's economic state in 2020
完美!我们会得到什么答案?
Answer 1:
The context provided does not contain specific information about Singapore's economic state in 2020. Therefore, I am unable to provide a review of Singapore's economy for that year based on the given context. If you have more specific information or another document, I would be happy to help with that.
嗯,这很奇怪。让我们看看搜索结果……
Search results 1:
Result 1:
Singapore's trade-driven economy shrank for the first time since 2003
in the fourth quarter as weak manufacturing dragged on growth.
Momentum is expected to weaken further in 2008.
Result 2:
DUBLIN--(BUSINESS WIRE)--Jan 11, 2019--The “The Payments Landscape
in Singapore: Opportunities & Risks to 2022” report has been added
to ResearchAndMarkets.com’s offering.
Result 3:
World markets retreated Tuesday after the International Monetary
Fund trimmed its global outlook for 2019 and 2020.
看起来这些文章的时间段都不对,真让人头疼!也许只是个巧合。让我们换个查询试试。
Query 2:
Investor centric review of magnachip, 2018
答案有没有更好一些?
Answer 2:
In 2018, Microchip Technology Inc. (NASDAQ: MCHP) faced significant challenges following its acquisition of Microsemi Corp. for approximately $10.15 billion, which was completed on May 29, 2018. The acquisition was presented as a strategic move that would be "immediately accretive" to Microchip's earnings.
好吧,日期没问题,主题也算相关。但提到的公司不对,这让人困惑。快速浏览搜索结果后,发现竟然没有任何结果与 MagnaChip 相关。
这就奇怪了,发生了什么?
搜索在规模上遇到了问题
![]()
这两段内容都来自年度报告。如果没有标签,你能分辨出一段来自 2023 年,另一段来自 2024 年吗?可能不能。同样,LLM 也无法做到,而向量搜索也无济于事。
我们可以猜测向量搜索表现不佳的几个原因。其中最明显的是:向量搜索没有时间概念,无法阻止检索到语义上相似但时间错误的新闻文章。例如,你可能在索引中有多个银行的年度财报。当你搜索其中一个时,所有这些报告可能都会被返回,因为它们的内容、用词和 “语气” 非常相似。这种混合检索的内容基本上是在为 LLM 产生幻觉创造条件,显然不理想。
尽管时间维度问题至关重要,但它只是更大问题的一部分。
在这个例子中,我们有 756,880 篇 来自 Bloomberg、HuffPost、Politico 等新闻网站的文章,并为每篇文章生成了嵌入向量。随着文章数量的增加,具有 相似语义内容 的文档对也会越来越多。它们可能共享相同的术语、措辞、语法结构,甚至话题。也许它们反复提及相同的人物或事件,甚至在语气和风格上也相似。
当这种相似文章的数量增加时,向量之间的距离将变得越来越不可靠,无法很好地衡量真正的语义相似性,导致搜索质量下降。而且,随着数据规模的扩大,这个问题会变得越来越严重。
总结:
搜索质量会随着数据规模的增长而恶化,因为无关文档会干扰相关文档的检索。
那么,如果问题的核心是 无关文档过多,为什么不在搜索时直接移除它们呢?
听起来很简单?叮咚,当然不是。(事实证明,这远比想象中复杂。)
解决方案:增强数据处理
![]()
通过添加额外的元数据丰富数据,我们可以利用过滤器、范围以及其他传统搜索功能来提高搜索相关性。
Elasticsearch 起初是作为一个功能齐全的搜索引擎开发的。日期范围和过滤器、几何/地理空间搜索、关键词、术语和模糊匹配与布尔运算符,以及通过提升特定字段来微调搜索相关性的能力。其功能列表非常庞大。我们可以依靠这些功能来精细化和优化搜索,即使是仅包含文本内容的文档也能应用这些功能。
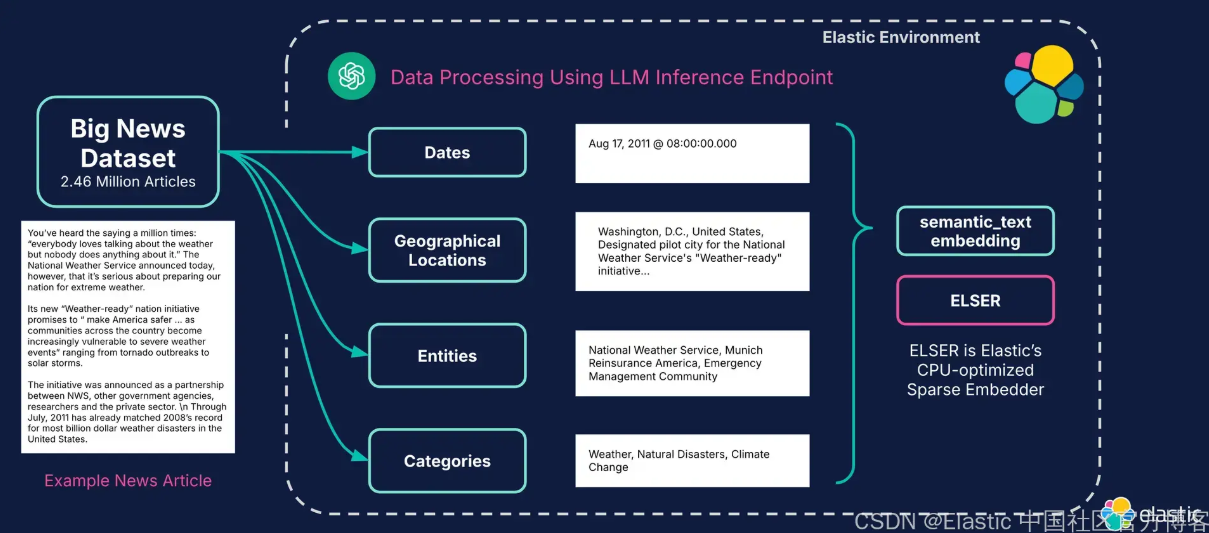
过去,我们需要应用一系列自然语言处理(NLP)功能来提取实体、对文本进行分类、执行情感分析,并建立词汇片段之间的关系。这是一个复杂的任务,涉及多个不同的组件,其中一些很可能是基于变换器架构的专用深度学习模型。
Elastic 允许通过 Eland 上传这些模型,并在数据接入管道中利用它们的 NLP 功能。而有了大语言模型(LLMs),这个任务就变得更加简单了。
我可以像这样定义一个 LLM 推理端点:
PUT _inference/completion/azure_openai_gpt4o_completion
{
"service": "azureopenai",
"service_settings": {
"api_key": "------------",
"resource_name": "ca-shared",
"deployment_id": "gpt-4o",
"api_version": "2024-06-01"
}
}
然后,我可以将其添加到数据接入管道中,这样就能从我的文章中提取有趣的元数据。在这个例子中,我将提取一个实体列表,其中可能包括人物、组织和事件。我还会提取地理位置,并尝试对文章进行分类。这只需要进行提示工程(prompt engineering),在文档上下文中定义一个提示,并使用推理处理器调用 LLM,并将其应用到提示中,如下所示:
PUT _ingest/pipeline/bignews_pipeline
{
"processors": [
{
"script": {
"source": """
ctx.entities_prompt = 'Instructions: - Extract the top 1 to 20
most significant entities from the news story.
...
Return your answer in this format: Entity1, Entity2,...,nEntity10
Example: Jane Doe, TechCorp, Tech Expo 2023
If there are less than 20 of such entities, then stop when appropriate.
Anywhere from 1 to 20 entities is acceptable.
News Story: [News Story] ' + ctx.text
"""
}
},
{
"inference": {
"model_id": "azure_openai_gpt4omini_completion",
"input_output": {
"input_field": "entities_prompt",
"output_field": "entities"
},
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{
{
{ _index }}}"
}
}
]
}
},
...
{
"script": {
"source": """
ctx.categories_prompt = 'Here is a list of categories:
Politics, Business, Technology, Science, Health, ...
**Instructions:** - Extract between 1 and 20
most important categories from the news story.
- **Use only the listed categories**. -
Return your answer in this format: Category1
Category2 Category3 Category4 Category5
**Example:** Technology Business Innovation
Economics Marketing **News Story:** [News Story] ' + ctx.text
"""
}
},
...
{
"script": {
"source": """
ctx.geographic_location_prompt = 'Instructions:
- Extract geographic locations from the news story: -
For each location, provide: - The **location name**
as precisely as possible (include city, state/province, country, etc.).
- Return your answer in this format: London, United Kingdom,
Paris, France, Berlin, Germany **News Story:** [News Story] ' + ctx.text
"""
}
},
...
我可以通过如下的重新索引操作来启动它:
POST _reindex?slices=auto&wait_for_completion=false
{
"conflicts": "proceed",
"source": {
"index": "bignews",
"size": 24
},
"dest": {
"index": "bignews_enriched",
"pipeline": "bignews_pipeline",
"op_type": "create"
}
}
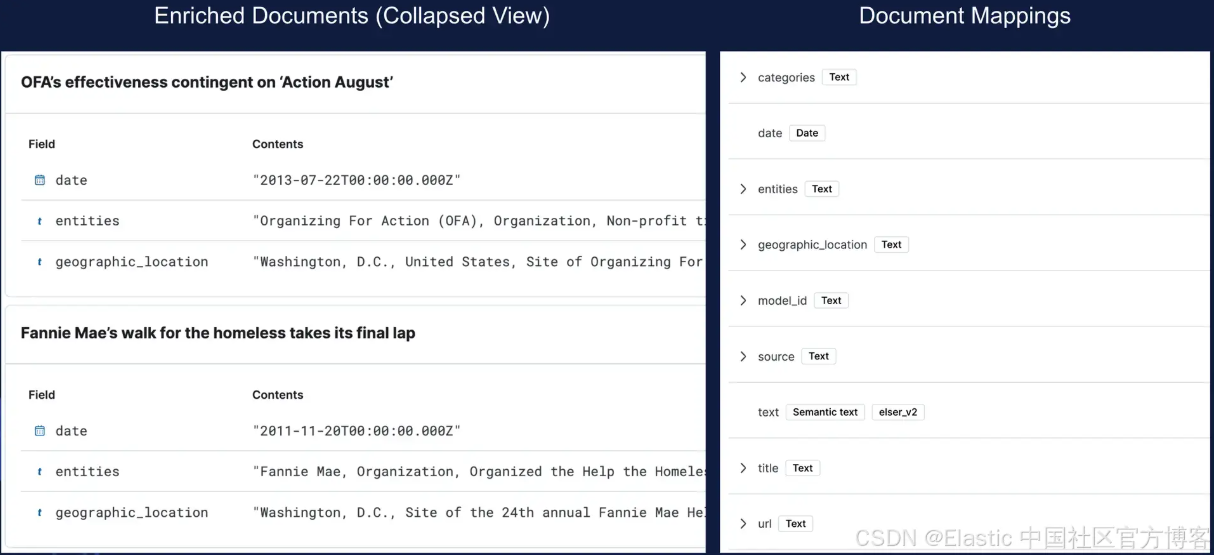
经过一段时间,我将得到丰富的文档,包含有用的元数据,可以用来优化和改进我的搜索结果。例如:
title: "Kane Co. president John Kane on giving - Innovations"
categories: "Philanthropy, Business, Education, Human Interest"
entities: "Tom Heath, John Kane, Kane Co. "
geographic_location: "Maryland, Washington DC, United States"
date: "2011-11-20T00:00:00.000Z"
text: ...
幸运的是,我使用的这个数据集带有时间戳。如果没有时间戳,我可能会尝试让 LLM 根据内容推断出大致的日期。我还可以使用开源数据集或像 Google 的地理编码 API 这样的应用,通过坐标进一步丰富元数据。我还可以为实体和类别本身添加描述,或者与我拥有的其他数据源(如数据库和数据终端)进行交叉关联。可能性是无限的,而且各式各样。
![]()
文档视图和在丰富后的映射
在对文档进行分块和嵌入(使用 semantic_text),这个过程已经有很好的文档说明之后,问题仍然存在:我如何真正利用这些新元数据呢?
超越向量搜索:复杂查询
标准的向量搜索可能如下所示。假设我已经使用 semantic_text 和 ELSER_V2 对数据进行了分块和嵌入,我可以像这样使用稀疏向量查询:
GET bignews_final/_search
{
"query": {
"nested": {
"path": "text.inference.chunks",
"query": {
"sparse_vector": {
"inference_id": "elser_v2",
"field": "text.inference.chunks.embeddings",
"query": "what weather event happened
in the caribbean in 2012"
}
},
"inner_hits": {
"size": 2,
"name": "bignews_embedded.text",
"_source": false
}
}
}
}
这样就会给我返回以下标题的搜索结果:
Hurricane Matthew to Smash into Gitmo by Tuesday Evening (2016 Oct)
AP Fact Check: Clinton on Hurricane Matthew, climate change (2016 Oct)
As Matthew churns toward U.S., more than 1 million ordered
evacuated in S.C. (2016 Oct)
Tropical Storm Isaias: Americans should start preparing for 'winds,
heavy rainfall and storm surge,' hurricane center says (2020 Jul)
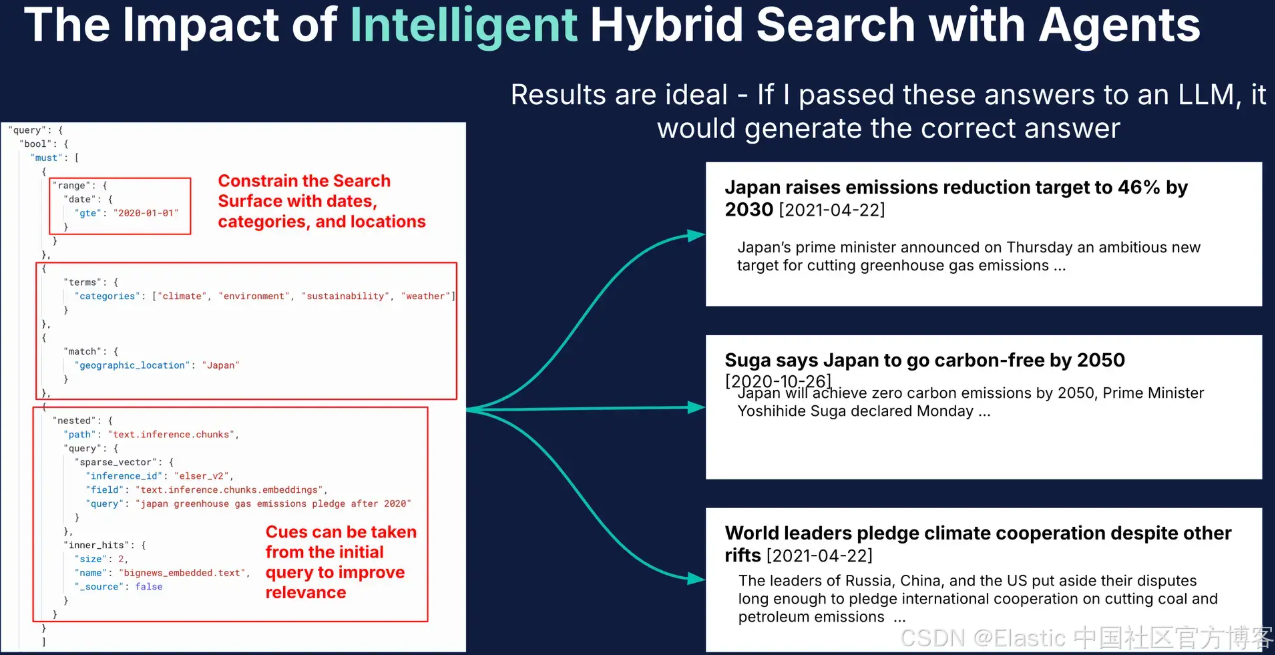
好的。返回的结果日期都不对,而且是错误的 hurricanes(我在找的是 Isaac 和 Sandy)。这个向量搜索不够好,可以通过在日期范围内进行过滤,并且在我新的元数据字段上进行搜索来改进。也许实际需要的查询看起来像这样:
GET bignews_final/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"date": {
"gte": "2012-01-01",
"lte": "2012-12-31"
}
}
},
{
"match": {
"categories": "Climate, Weather"
}
},
{
"match": {
"geographic_location": "Caribbean"
}
},
{
"nested": {
"path": "text.inference.chunks",
"query": {
"sparse_vector": {
"inference_id": "elser_v2",
"field": "text.inference.chunks.embeddings",
"query": "what weather event happened
in the caribbean in 2012"
}
},
"inner_hits": {
"size": 2,
"name": "bignews_embedded.text",
"_source": false
}
}
}
]
}
}
}
这些是我得到的搜索结果:
Tropical Storm Isaac poses potential threat (2012 Jul)
A look at Caribbean damage from Hurricane Sandy (2012 Oct)
Green Stories Of 2012: Environmental News In Review (2012 Dec)
情况确实有所改善,得到了准确的新闻报道。
现实中,如何动态生成这样更复杂的查询呢?标准的查询条件会根据用户的具体需求而变化。也许有些用户的问题会指定日期,而其他问题则没有。可能会提到特定的实体,也可能没有。或许可以推断出像文章类别这样的细节,也可能没有。一个统一的 Elastic Query DSL 请求可能并不总是有效,可能需要根据需求和上下文动态适应。
有一篇关于使用 LLMs 生成 Query DSL 的博客。尽管这种方法有效,但始终存在括号错位或请求格式错误的风险。由于查询 DSL 的复杂性和长度,执行时间较长,这也会影响用户体验。
那为什么不使用一个代理呢?
代理模型
简而言之,代理是一个具有一定决策能力的 LLM。为其提供一组工具,定义每个工具可能使用的参数,建立目的和范围,然后允许 LLM 根据情况动态选择每个工具。
一个工具可以是知识库、传统数据库、计算器、网页爬虫等。可能性是无穷无尽的。我们的目标是提供一个接口,使代理能够以结构化的方式与工具进行交互,然后利用工具的输出。
使用代理创建复杂的查询 DSL(智能混合搜索)
![]()
使用 Langchain,我们可以将工具定义为 Python 函数。在这里,我有一个函数,它接收一些参数,这些参数将由 LLM 提供,然后构建一个 Elasticsearch 查询并使用 Python 客户端发送。如果每个变量存在,它将被添加到查询条件中,然后这些条件将附加到一个条件列表中。这些条件将被组装成一个完整的 Elasticsearch 查询,其中包括一个向量搜索组件,最终作为搜索请求的一部分发送出去。
def rag_search(query: str, dates: str, categories: str, geographic_location: str, entities: str):
if es_client is None:
return "ES client is not initialized."
else:
try:
# Build the Elasticsearch query
should_clauses = []
must_clauses = []
# If dates are provided, parse and include in query
if dates:
# Dates must be in format 'YYYY-MM-DD' or 'YYYY-MM-DD to YYYY-MM-DD'
date_parts = dates.strip().split(' to ')
if len(date_parts) == 1:
# Single date
start_date = date_parts[0]
end_date = date_parts[0]
elif len(date_parts) == 2:
start_date = date_parts[0]
end_date = date_parts[1]
else:
return "Invalid date format. Please use YYYY-MM-DD or YYYY-MM-DD to YYYY-MM-DD."
date_range = {
"range": {
"date": {
"gte": start_date,
"lte": end_date
}
}
}
must_clauses.append(date_range)
supplementary_query=[]
if categories:
supplementary_query.append(categories)
lst=[i.strip() for i in categories.split(',')]
for category in lst:
category_selection = {
"match": {
"categories": category
}
}
should_clauses.append(category_selection)
if geographic_location:
supplementary_query.append(geographic_location)
lst=[i.strip() for i in geographic_location.split(',')]
for location in lst:
geographic_location_selection = {
"match": {
"geographic_location": location
}
}
should_clauses.append(geographic_location_selection)
if entities:
supplementary_query.append(entities)
lst=[i.strip() for i in entities.split(',')]
for entity in lst:
entity_selection = {
"match": {
"entities": entity
}
}
should_clauses.append(entity_selection)
# Add the main query clause
main_query = {
"nested": {
"path": "text.inference.chunks",
"query": {
"sparse_vector": {
"inference_id": "elser_v2",
"field": "text.inference.chunks.embeddings",
"query": query + ' ' + ', '.join(supplementary_query)
}
},
"inner_hits": {
"size": 2,
"name": "bignews_final.text",
"_source": False
}
}
}
must_clauses.append(main_query)
es_query = {
"_source": ["text.text", "title", "date"],
"query": {
"bool": {
"must":must_clauses,
"should":should_clauses
}
},
"size": 10
}
response = es_client.search(index="bignews_final", body=es_query)
... ... ...
搜索结果随后被格式化,连接成一段文本,作为 LLM 的上下文,最后返回给用户。
result_docs = []
for hit in hits:
source = hit["_source"]
title = source.get("title", "No Title")
text_content = source.get("text", {}).get("text", "")
date = source.get("date", "No Date")
categories = source.get("categories", "No category")
# Create result document
doc = {
"title": title,
"date": date,
"categories":categories,
"content": text_content
}
# Add to session state
st.session_state.search_results.append(doc)
# Create formatted string for return value
formatted_doc = f"Title: {title}\nDate: {date}\n\n {text_content}\n"
result_docs.append(formatted_doc)
return "\n".join(result_docs)
该工具/函数有一个明确的目的;它允许代理以一种定义明确且受控制的方式与 Elasticsearch 集群进行交互。由于代理控制用于搜索的参数,因此具有动态行为。与此同时,也有定义和约束,因为查询的整体结构是预先定义好的。无论代理输出什么,都不会产生格式错误的请求来破坏流程,并且会有一定程度的一致性。
因此,当我向代理提问时,比如:“Concise summary of developments related to Elastic NV in the second half of the 2010s”,它将选择使用先前定义的 RAG 工具。它会用如下参数调用该工具:
{
"query ": "Elastic NV developments 2010s ",
"dates ": "2015-07-01 to 2019-12-31 ",
"categories ": "Business, Technology, Finance ",
"geographic_location ": "Global ",
"entities ": "Elastic NV "
}
这将生成一个如下所示的查询:
GET bignews_final/_search
{
"query ": {
"bool ": {
"must ": [
{
"range ": {
"date ": {
"gte ": "2015-07-01 ",
"lte ": "2019-12-31 "
}
}
},
{
"nested ": {
"path ": "text.inference.chunks ",
"query ": {
"sparse_vector ": {
"inference_id ": "elser_v2 ",
"field ": "text.inference.chunks.embeddings ",
"query ": "Elastic NV developments 2010s Business, Technology, Finance, Global, Elastic NV "
}
},
"inner_hits ": {
"size ": 2,
"name ": "bignews_final.text ",
"_source ": false
}
}
}
],
"should ": [
{
"match ": {
"categories ": "Business "
}
},
{
"match ": {
"categories ": "Technology "
}
},
{
"match ": {
"categories ": "Finance "
}
},
{
"match ": {
"geographic_location ": "Global "
}
},
{
"match ": {
"entities ": "Elastic NV "
}
}
]
}
},
"size ": 10
}
运气好的话,这个查询将为我们提供更好的搜索结果,并比仅使用向量搜索提供更令人满意的答案。
让我们来测试一下!
测试代理与向量搜索在“了解你的客户”(Know-Your-Customer, KYC)应用中的表现
我认为 “了解你的客户” 在金融服务和监管机构中的应用是一个非常有影响力的用例。这个应用涉及大量的人工研究和数据处理,通常仅凭向量搜索难以完成,因为它关注的是特定的实体、时间段和主题内容。我认为这是一个更适合代理模型而不是“纯粹”向量搜索的方法的用例。
这个数据集非常适合用于此场景,包含了从美国新闻媒体抓取的数百万篇新闻文章。这是实现这种用例的一个可能方式;将大量数据汇集到一个索引中,然后按需进行搜索。
测试使用的是部署在 Azure OpenAI 上的 GPT-4o-mini 作为 LLM,以及 ELSER_V2 作为嵌入模型。我们提出查询,使用向量搜索或代理搜索在 Elasticsearch 索引中进行搜索,然后比较答案和搜索结果。
用户查询和 LLM 生成的答案会显示,并且选择的搜索结果也会展示。代理功能调用和代理的答案也会被展示。
Test 1: Singapore economy in review 2020
这是我们提出的第一个查询,它代表了一个非常广泛且开放式的问题,传统上对于基于向量的 RAG 系统来说处理起来较为困难。除非知识库中有关于特定主题的文章。我们的目标是获取一系列至少在某种程度上相关的文章,然后将它们拼接成一个连贯的总结。
向量搜索答案:
向量搜索能够检索到相关的文档,主题上是相关的。然而,所有文档都来自错误的时间段。因此,LLM 无法给出答案。
** LLM Answer **
I couldn't find specific articles that provide a comprehensive review
of Singapore's economy for the year 2020.
** Search Results **
Singapore cuts 2012 growth forecast, outlook dour (2012 Nov)
Singapore's economy shrinks for first time since 2003 (2008 Mar)
In Singapore, Central Bank Eases Currency Policy (2015 Jan)
Agentic 搜索答案:
代理搜索能够从正确的时间段中检索到相关的文档,然后将它们串联成一个连贯的答案。这正是我们所期望的!
** LLM Answer **
In 2020, Singapore's economy faced significant challenges primarily
due to the impact of the COVID-19 pandemic.
Here are some key highlights from the year:
Singapore Airlines Rescue Package: In March 2020, Singapore Airlines (SIA)
secured a massive rescue package of up to $19 billion...
Government Support Measures: The Singapore government announced over S$30
billion in measures to support businesses and households...
Interest Rate Cuts in the Region: In response to the economic downturn,
central banks in the region, including the Monetary Authority of Singapore,
indicated they had room to ease monetary policy...
Economic Contraction: The pandemic led to a significant contraction in
economic activity. Analysts predicted that the economic growth for the
region could slow down considerably due to the effects of the virus...
Impact on Tourism and Exports: The tourism sector, a vital part of
Singapore's economy, was severely affected, with a drastic decline in
visitor arrivals...
Stock Market Volatility: The stock market experienced fluctuations
throughout the year, influenced by global economic conditions and
the ongoing pandemic...
Overall, 2020 was a tumultuous year for Singapore's economy,
marked by unprecedented challenges due to the global pandemic,
leading to significant government intervention and support measures
to stabilize the economy.`
** Search Results **
Singapore Airlines Obtains $13 Billion Rescue Package Amid Coronavirus Shock (2020 Mar)
Asian Economies Cut Rates, Move to Blunt Impact of Virus (2020 Feb)
Asian shares rise after US stocks set records as fears fade (2020 Jan)
** Agent Function Call **
{
'query': 'Singapore economy review 2020',
'dates': '2020-01-01 to 2020-12-31',
'categories': 'Economy',
'geographic_location': 'Singapore',
'entities': ''
}
Test 2: Summarize microsoft strategy in the second half of the last decade
这个查询与第一个查询一样具有开放性,额外的难度在于需要推断正确的日期范围。
向量搜索答案:
这是一个听起来合理且更详细的答案,但有一个警告 —— 大部分内容是不准确的。几乎所有的搜索结果都来自错误的时间段,导致例如,2008 年关于云计算的文章中的事实出现在本应是关于 2015-2020 年的答案中。仔细检查后,内容也很泛泛,缺乏细节。唯一相关且有用的事实是新任首席战略官的任命。
** LLM Answer **
In the second half of the last decade, Microsoft implemented
a multifaceted strategy focused on cloud computing,
organizational restructuring, and adapting to changing market demands.
Cloud Computing Focus: Microsoft significantly shifted its strategy
towards cloud services, particularly with its Azure platform. This
included substantial investments in data centers and a commitment to
transitioning from traditional software sales...
Organizational Restructuring: In 2017, Microsoft announced a major
restructuring...
Leadership Changes: The appointment of Mark Penn as Chief Strategy
Officer in 2014 marked a significant shift in Microsoft's executive
leadership, emphasizing a strategic approach...
Financial Performance: Throughout this period, Microsoft experienced
strong financial growth, particularly in its cloud services...
** Search Results **
Microsoft Moves To Weather Time Of Slow Growth (2003 July)
Microsoft airs strategy for 'cloud computing' (2008 October)
Microsoft reveals permanent work-from-home policy (2020 Mar)
Agentic 搜索答案:
这是一个更加令人满意和完整的答案,提供了更多详细的具体信息。搜索结果不仅相关,而且来自正确的时间段。事实核对显示,每个要点都来自搜索结果中的一篇文章。
** LLM Answer **
n the second half of the last decade, Microsoft underwent a
significant strategic transformation under CEO Satya Nadella,
focusing on cloud computing and enterprise services,
which revitalized the company's market position and financial performance.
Shift to Cloud Computing: Microsoft moved away from its traditional
reliance on the Windows operating system and personal computer sales,
which had been declining. By 2019, cloud services accounted for
nearly a third of Microsoft's total revenue, marking a substantial
growth area for the company.
Business-Oriented Services: The company emphasized long-term contracts
with business customers, enhancing its offerings in enterprise software,
including Office 365 and LinkedIn...
Financial Performance: Microsoft's strategic pivot led to impressive
financial results. For instance, in July 2019, the company reported
a quarterly profit of $13.2 billion, driven largely by its cloud business,
which saw a 19% revenue increase year-over-year...
Partnerships and Acquisitions: Microsoft sought partnerships with
other tech companies and made strategic acquisitions to bolster its
cloud capabilities. For example, it partnered with AT&T to migrate
infrastructure to its cloud platform...
Philanthropic Initiatives: In addition to its business strategy,
Microsoft also committed to social responsibility by earmarking
$1 billion for public cloud projects aimed at non-profits and
educational institutions...
Sustainability Efforts: Microsoft made significant investments
in renewable energy, including large wind energy purchases
to power its data centers, aligning its operations with
broader environmental goals.
** Search Results **
Microsoft cloud growth beats expectations (2019 Jul)
Microsoft surpasses Apple as most valuable public company (2018 Nov)
Microsoft earmarks $1B for public cloud projects (2016 Jan)
** Agent Function Call **
{
'query': 'Microsoft strategy second half of the last decade',
'dates': '2015-07-01 to 2019-12-31',
'categories': 'Business, Technology, Corporate Strategy',
'geographic_location': 'Global',
'entities': 'Microsoft'
}
Test 3: Elastic nv investor review 2010-2023
为什么不询问 Elastic 本身呢?我们也使用更大的日期范围。
向量搜索答案:
这个查询仅返回了两篇关于领导层变动的相关文章。结果显得非常有限,可能无法满足这个用例的需求。
** LLM Answer **
The search for news articles specifically related to "Elastic NV investor review"
from 2010 to 2023 yielded limited results. H
owever, here are some relevant articles that mention Elastic NV:
Elastic Announces Transition of Chief Revenue Officer (February 26, 2020)
Elastic N.V. announced that its Chief Revenue Officer, Aaron Katz,
transitioned to an advisory role. The company is searching for his successor,
and CEO Shay Banon expressed confidence in the sales leadership team to
manage the transition without disruption...
Elastic Nominates Alison Gleeson to Board of Directors (November 12, 2019)
Elastic N.V. nominated Alison Gleeson, a former Senior Vice President
at Cisco, to its Board of Directors. Gleeson’s extensive experience
in go-to-market strategies is expected to benefit Elastic as it seeks
to grow and deepen customer relationships. The nomination is subject
to a shareholder vote.
These articles provide insights into Elastic NV's leadership changes
and strategic direction, which are relevant for investors
reviewing the company's performance and governance.
** Search Results **
Elastic Announces Transition of Chief Revenue Officer (2020 Feb)
Elastic Nominates Alison Gleeson to Board of Directors (2019 Nov)
Agentic 搜索答案:
这是一个更完整的答案,带来了关于 ECS 和密苏里州国民警卫队的成功案例的文章。看起来,代理方法通过更全面的搜索查询,显著提升了搜索相关性。
** LLM Answer **
Here is a summary of notable events and developments related to
Elastic NV from 2010 to 2023 based on the news articles:
Leadership Changes:
In February 2020, Elastic announced the transition of its Chief Revenue Officer,
Aaron Katz, to an advisory role, with Shay Banon, the CEO,
expressing confidence in the leadership team to manage the transition without disruption.
Board of Directors:
In November 2019, Alison Gleeson was nominated to join Elastic's Board of Directors.
Gleeson, a former Cisco executive, was expected to contribute significantly
to Elastic's growth strategy.
Partnerships and Innovations:
In January 2019, Elastic partnered with ECS to enhance security and analytics
capabilities using the Elastic Stack, showcasing its technology's versatility across various sectors.
The Missouri National Guard's cybersecurity team, utilizing Elastic's technology,
won the 2018 Government Innovation Award for their RockNSM project, which
improved network security monitoring.
Elastic has maintained a strong commitment to the open-source community,
which is a core part of its business model, allowing users to leverage
its technology for various applications.
This summary encapsulates key developments and strategic moves by Elastic NV over the years,
reflecting its growth trajectory and the challenges it has navigated in the tech landscape.
** Search Results **
Elastic Customer, Missouri National Guard Cybersecurity Team,
Wins 2018 Government Innovation Award for Public Sector Innovation (2018 Nov)
ECS Announces Partnership with Real-Time Search Company Elastic (2019 Jan)
Elastic Announces Transition of Chief Revenue Officer (2020 Feb)
Elastic Nominates Alison Gleeson to Board of Directors (2019 Nov)
** Agent Function Call **
{
'query': 'Elastic NV investor review',
'dates': '2010-01-01 to 2023-12-31',
'categories': 'Finance, Business, Technology',
'geographic_location': 'Global',
'entities': 'Elastic NV'
}
结论
通过测试,我们发现向量搜索无法有效处理时间维度,并且不一定能够有效地强调搜索查询中的关键组成部分,这些关键部分能够增强相关性信号并提高整体搜索质量。我们还看到了规模扩展的负面影响,随着语义相似文章数量的增加,可能导致糟糕或不相关的搜索结果。这可能导致最好的情况是没有答案,最坏的情况则是错误的答案。
测试还表明,通过 agentic 方法构建搜索查询,可以在提高整体搜索相关性和质量方面发挥重要作用。它通过有效缩小搜索范围,减少噪音,减少考虑中的候选项数量来实现这一点,并且利用了从 Elastic 最早的日子以来就可用的传统搜索功能。
我觉得这真是太酷了!
有许多方向可以探索。例如,我想尝试一个依赖于地理空间搜索的用例。那些能够利用更多元化元数据来缩小相关文档范围的用例,可能会从这种范式中获得最大收益。我认为这代表了传统 RAG 范式的自然进展,我个人也很期待看到它能被推进多远。
好了,这就是我今天的所有内容。下次见!
附录
用于丰富数据的完整摄取管道,在 Elastic dev tools 控制台内运行。
PUT _ingest/pipeline/bignews_pipeline
{
"processors": [
{
"script": {
"source": """
ctx.entities_prompt = 'Instructions: - Extract the top 1 to 20 most significant entities from the news story. These can be organizations, people, events - For each entity, provide: - The entitys name - Do not include geographic locations; they will be handled separately. - Return your answer in this format: Entity1, Entity2,...,nEntity10 Example: Jane Doe, TechCorp, Tech Expo 2023 If there are less than 20 of such entities, then stop when appropriate. Anywhere from 1 to 20 entities is acceptable. News Story: [News Story] ' + ctx.text
"""
}
},
{
"inference": {
"model_id": "azure_openai_gpt4omini_completion",
"input_output": {
"input_field": "entities_prompt",
"output_field": "entities"
},
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{
{
{ _index }}}"
}
}
]
}
},
{
"remove": {
"field": "entities_prompt"
}
},
{
"script": {
"source": """
ctx.categories_prompt = 'Here is a list of categories: Politics, Business, Technology, Science, Health, Sports, Entertainment, World News, Local News, Weather, Education, Environment, Art & Culture, Crime & Law, Opinion & Editorial, Lifestyle, Travel, Food & Cooking, Fashion, Autos & Transportation, Real Estate, Finance, Religion, Social Issues, Obituaries, Agriculture, History, Geopolitics, Economics, Media & Advertising, Philanthropy, Military & Defense, Space & Astronomy, Energy, Infrastructure, Science & Technology, Health & Medicine, Human Interest, Natural Disasters, Climate Change, Books & Literature, Music, Movies & Television, Theater & Performing Arts, Cybersecurity, Legal, Immigration, Gender & Equality, Biotechnology, Sustainability, Animal Welfare, Consumer Electronics, Data & Analytics, Education Policy, Elections, Employment & Labor, Ethics, Family & Parenting, Festivals & Events, Finance & Investing, Food Industry, Gadgets, Gaming, Health Care Industry, Insurance, Internet Culture, Marketing, Mental Health, Mergers & Acquisitions, Natural Resources, Pharmaceuticals, Privacy, Retail, Robotics, Startups, Supply Chain, Telecommunications, Transportation & Logistics, Urban Development, Vaccines, Virtual Reality & Augmented Reality, Wildlife, Workplace, Youth & Children **Instructions:** - Extract between 1 and 20 most important categories from the news story. - **Use only the listed categories**. - Return your answer in this format: Category1 Category2 Category3 Category4 Category5 **Example:** Technology Business Innovation Economics Marketing **News Story:** [News Story] ' + ctx.text
"""
}
},
{
"inference": {
"model_id": "azure_openai_gpt4omini_completion",
"input_output": {
"input_field": "categories_prompt",
"output_field": "categories"
},
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{
{
{ _index }}}"
}
}
]
}
},
{
"remove": {
"field": "categories_prompt"
}
},
{
"script": {
"source": """
ctx.geographic_location_prompt = 'Instructions: - Extract geographic locations from the news story: - For each location, provide: - The **location name** as precisely as possible (include city, state/province, country, etc.). - Return your answer in this format: London, United Kingdom, Paris, France, Berlin, Germany **News Story:** [News Story] ' + ctx.text
"""
}
},
{
"inference": {
"model_id": "azure_openai_gpt4omini_completion",
"input_output": {
"input_field": "geographic_location_prompt",
"output_field": "geographic_location"
},
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{
{
{ _index }}}"
}
}
]
}
},
{
"remove": {
"field": "geographic_location_prompt"
}
}
]
}
想获得 Elastic 认证吗?了解下一期 Elasticsearch 工程师培训的时间!
Elasticsearch 拥有众多新功能,帮助你为你的用例构建最佳的搜索解决方案。深入了解我们的示例笔记本,开始免费的云试用,或现在就尝试在本地机器上使用 Elastic。
原文:Beyond vectors: Intelligent hybrid search with agents - Elasticsearch Labs