前言
OpenTelemetry Collector 是 OpenTelemetry 的核心组件,但在底层基础设施(如 Kubernetes 节点)故障时,可能暴露出阻塞或延迟问题。本文通过一次因 Sampling 服务节点宕机引发的故障,结合代码分析其原因,并提供临时和长期解决方案。
问题描述
一天,收到告警,OpenTelemetry 出现 Exporter Trace 异常的情况,具体表现为:
- OpenTelemetry Collector 的负载均衡器指标
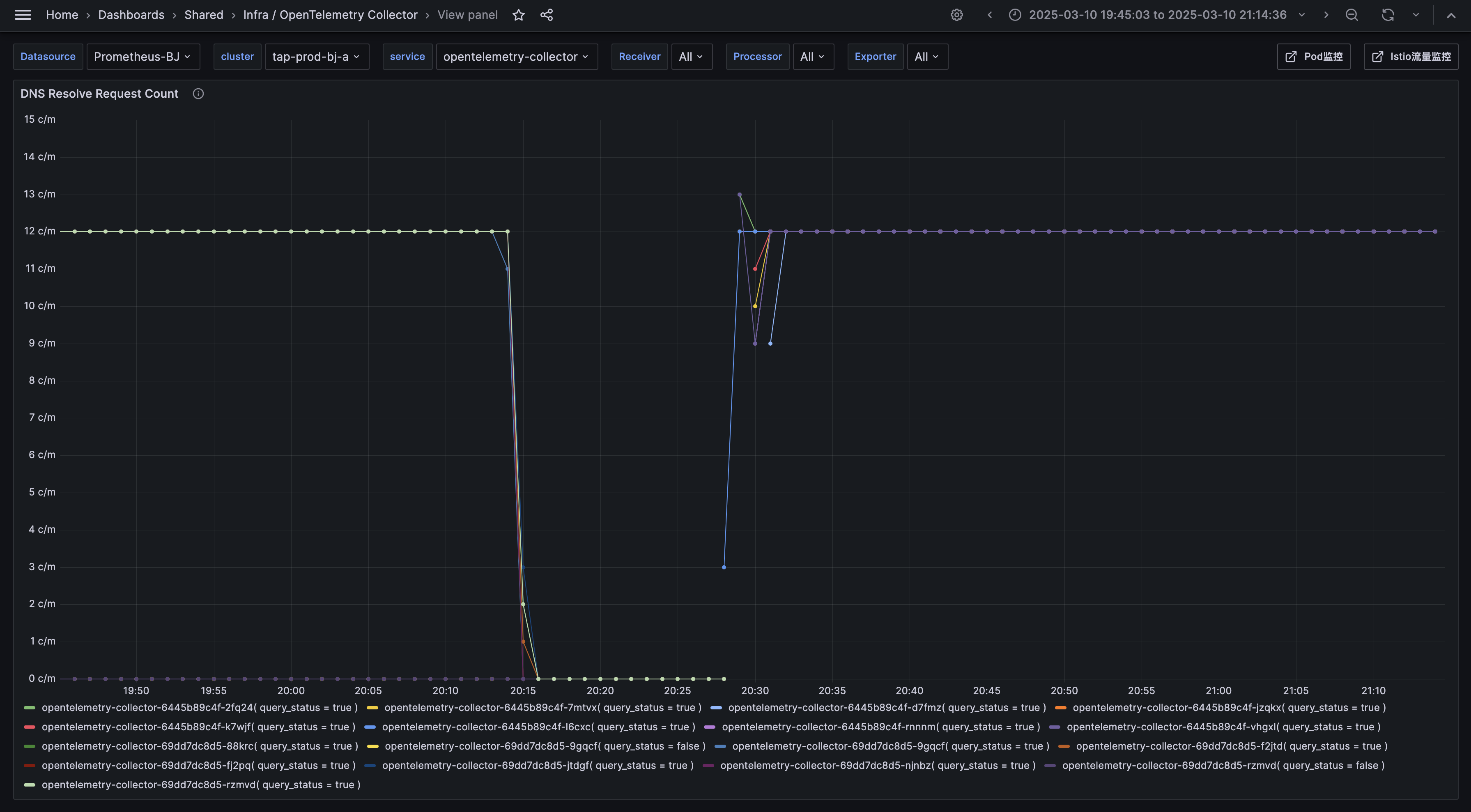
otelcol_loadbalancer_num_resolutions 变为 0,表明 DNS 解析更新停止。 ![]()
- OpenTelemetry Collector 的负载均衡器指标
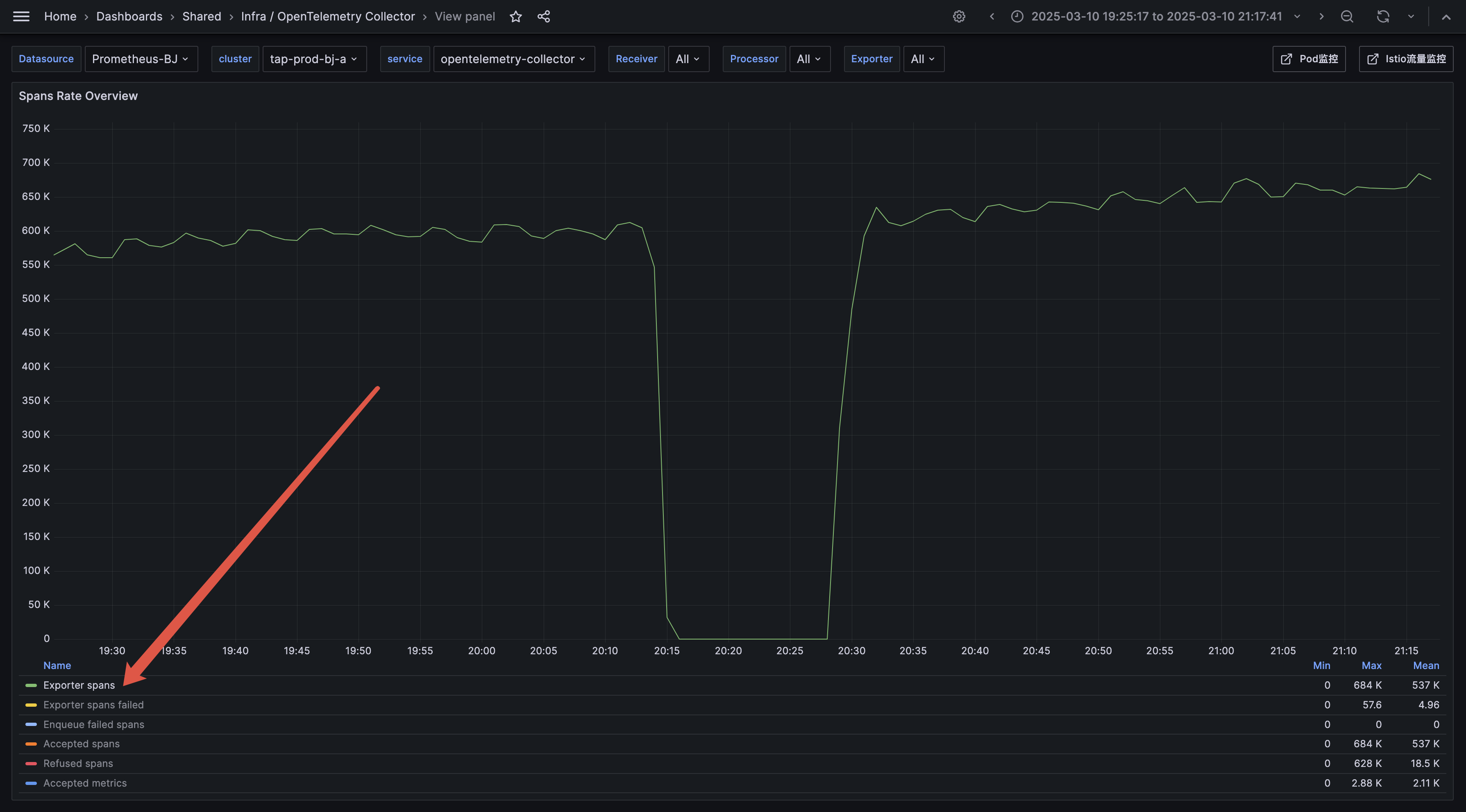
otelcol_exporter_sent_spans 变为 0, 表明所有 Exporter停止发送数据。![]()
- 系统恢复时间异常长,至少需要 15 分钟以上才能恢复。
架构背景
故障发生在一个多层遥测数据处理架构中,具体流程如下:
客户端 -> OpenTelemetry-Collector -> OpenTelemetry-Collector-Sampling -> Trace 后端服务
- 客户端:应用程序或服务,生成并发送 Trace 数据。
- OpenTelemetry-Collector:第一层 Collector,接收客户端数据,使用负载均衡器分发到下游服务。
- OpenTelemetry-Collector-Sampling:第二层 Collector,负责采样处理(基于 Trace ID 进行采样),运行在 Kubernetes 集群中。
- Trace 后端服务:最终存储和分析遥测数据的服务。
初步排查确认,此次故障影响了第一层 Collector 的正常运行。
版本背景
触发本次问题的 OpenTelemetry Collector 版本为 0.73.0(发布于 2023 年初)。此版本的负载均衡器实现存在已知问题,尤其是在处理端点下线时的阻塞行为尚未优化(后续版本通过 PR #31602 修复)。
原因分析
通过日志、指标和代码分析,我们锁定了问题根源: Sampling 服务的一个 Pod 因所在节点宕机下线,节点宕机后,导致第一层 Collector 的 gRPC 连接未正常关闭,Collector 的数据发送和 DNS 解析组件在处理下线端点时发生阻塞。以下是详细故障链条,结合代码剖析:
1. 节点宕机,gRPC 连接未正常关闭
Sampling 服务的一个 Pod 因节点宕机下线。由于是意外故障,gRPC 连接未执行正常关闭流程,客户端(第一层 Collector)gRPC 未立即感知服务器不可用。
2. DNS Resolver 检测到端点变化
dnsResolver 组件每 5 秒解析 DNS,监控 Sampling 服务端点:
func (r *dnsResolver) resolve(ctx context.Context) ([]string, error) {
r.shutdownWg.Add(1)
defer r.shutdownWg.Done()
addrs, err := r.resolver.LookupIPAddr(ctx, r.hostname)
if err != nil {
_ = stats.RecordWithTags(ctx, resolverSuccessFalseMutators, mNumResolutions.M(1))
return nil, err
}
_ = stats.RecordWithTags(ctx, resolverSuccessTrueMutators, mNumResolutions.M(1))
var backends []string
for _, ip := range addrs {
var backend string
if ip.IP.To4() != nil {
backend = ip.String()
} else {
backend = fmt.Sprintf("[%s]", ip.String())
}
if r.port != "" {
backend = fmt.Sprintf("%s:%s", backend, r.port)
}
backends = append(backends, backend)
}
sort.Strings(backends)
if equalStringSlice(r.endpoints, backends) {
return r.endpoints, nil
}
// **关键点 1:端点变化触发回调**
r.updateLock.Lock()
r.endpoints = backends
r.updateLock.Unlock()
_ = stats.RecordWithTags(ctx, resolverSuccessTrueMutators, mNumBackends.M(int64(len(backends))))
r.changeCallbackLock.RLock()
for _, callback := range r.onChangeCallbacks {
callback(r.endpoints) // 调用 onBackendChanges
}
r.changeCallbackLock.RUnlock()
return r.endpoints, nil
}
- 逻辑 :检测到 Sampling 端点减少后,触发
onBackendChanges 更新负载均衡器。
- 指标 :
mNumResolutions 若为 0,表明 5s 一次的 resolve 解析被 onBackendChanges 阻塞。
3. 负载均衡器更新后端
onBackendChanges 处理端点变化:
func (lb *loadBalancerImp) onBackendChanges(resolved []string) {
newRing := newHashRing(resolved)
if !newRing.equal(lb.ring) {
// **关键点 2:加锁更新**
lb.updateLock.Lock()
defer lb.updateLock.Unlock()
lb.ring = newRing
ctx := context.Background()
lb.addMissingExporters(ctx, resolved)
lb.removeExtraExporters(ctx, resolved)
}
}
- 逻辑 :在
onBackendChanges 中,加了 updateLock 写锁,因为 removeExtraExporters 需要排空队列中的数据,等 updateLock 锁的操作都要被阻塞等待。
4. 移除下线 Exporter
removeExtraExporters 下线多余端点:
func (lb *loadBalancerImp) removeExtraExporters(ctx context.Context, endpoints []string) {
endpointsWithPort := make([]string, len(endpoints))
for i, e := range endpoints {
endpointsWithPort[i] = endpointWithPort(e)
}
for existing := range lb.exporters {
if !endpointFound(existing, endpointsWithPort) {
// **关键点 3:Shutdown 清理积压数据**
_ = lb.exporters[existing].Shutdown(ctx)
delete(lb.exporters, existing)
}
}
}
- 问题 :在 0.73.0 版本中,
Shutdown 清理 boundedMemoryQueue 时,因 gRPC 服务器不可用,每次发送等待超时,加重试逻辑,耗时极长。
5. Trace ID 路由与 Exporter 调用
数据路由到 Sampling 服务的逻辑在 traceExporterImp.consumeTrace 中实现:
func (e *traceExporterImp) consumeTrace(ctx context.Context, td ptrace.Traces) error {
var exp component.Component
routingIds, err := routingIdentifiersFromTraces(td, e.routingKey)
if err != nil {
return err
}
for rid := range routingIds {
endpoint := e.loadBalancer.Endpoint([]byte(rid)) // 获取端点
// **关键点 4:根据 endpoint 获取 Exporter**
exp, err = e.loadBalancer.Exporter(endpoint) // 获取 Exporter
if err != nil {
return err
}
te, ok := exp.(exporter.Traces)
if !ok {
return fmt.Errorf("unable to export traces, unexpected exporter type: expected exporter.Traces but got %T", exp)
}
start := time.Now()
// **关键点 5:发送数据到 Sampling 服务**
err = te.ConsumeTraces(ctx, td)
duration := time.Since(start)
if err == nil {
_ = stats.RecordWithTags(
ctx,
[]tag.Mutator{tag.Upsert(endpointTagKey, endpoint), successTrueMutator},
mBackendLatency.M(duration.Milliseconds()))
} else {
_ = stats.RecordWithTags(
ctx,
[]tag.Mutator{tag.Upsert(endpointTagKey, endpoint), successFalseMutator},
mBackendLatency.M(duration.Milliseconds()))
}
}
return err
}
获取 Exporter 的具体实现
loadBalancer.Exporter 方法负责返回指定端点的 Exporter:
func (lb *loadBalancerImp) Exporter(endpoint string) (component.Component, error) {
// NOTE: make rolling updates of next tier of collectors work. currently, this may cause
// data loss because the latest batches sent to outdated backend will never find their way out.
// for details: https://github.com/open-telemetry/opentelemetry-collector-contrib/issues/1690
// **关键点 6:根据 endpoint 获取 Exporter 时加读锁**
lb.updateLock.RLock()
exp, found := lb.exporters[endpointWithPort(endpoint)]
lb.updateLock.RUnlock()
if !found {
return nil, fmt.Errorf("couldn't find the exporter for the endpoint %q", endpoint)
}
return exp, nil
}
- 逻辑 :
routingIdentifiersFromTraces 根据 Trace ID 和路由键生成标识符。loadBalancer.Endpoint 使用一致性哈希映射到端点。loadBalancer.Exporter 获取对应 Exporter,使用读锁(RLock)访问 exporters 映射。ConsumeTraces 通过 gRPC 发送数据到 Sampling 服务。
- 与故障的关联 :
- 当
onBackendChanges 调用 removeExtraExporters 并持有 updateLock 的写锁(Lock)时,Shutdown 的长时间执行会阻塞写锁释放。
Exporter 方法需要获取读锁(RLock),但写锁未释放时,读锁无法获取,导致 consumeTrace 中的 Exporter 调用被阻塞。- 结果是新数据的发送操作(
ConsumeTraces)无法进行,数据积压加剧。
6. 阻塞效应与恢复延迟
- 阻塞 :
Shutdown 持有 updateLock 写锁,阻塞 dnsResolver(需写锁更新端点)和 Exporter(需读锁获取实例)。
- 影响 :
otelcol_loadbalancer_num_resolutions 为 0,dns 服务发现停止工作,不能及时发现 Sampling 的副本变化(当故障触发时,Sampling 服务因为收不到请求, CPU 掉到非常低,因为 HPA ,副本数会缩到特别少)。otelcol_exporter_sent_spans 为 0 ,所有数据发送停止。
- 耗时:在 0.73.0 版本中,清理积压数据耗时 15 分钟以上。
临时解决方案:调整 gRPC Keepalive 参数
在 OpenTelemetry Collector v0.73.0 的故障场景中,Sampling 服务节点宕机导致 gRPC 连接未正常关闭,Shutdown 操作阻塞了负载均衡器的更新和数据发送,恢复时间长达 15 分钟。为缩短恢复时间,我们调整了 gRPC 的 Keepalive 参数,使 gRPC 客户端更快感知连接异常,从而加速端点下线流程。以下是具体的配置和分析。
gRPC 客户端配置 (OpenTelemetry-Collector)
loadbalancing:
protocol:
otlp:
compression: none
tls:
insecure: true
keepalive:
time: 10s
timeout: 3s
permit_without_stream: true
参数解析
time: 10s
- 作用:客户端每 10 秒发送一次保活 ping 到服务器,检查连接是否存活。
- 调整原因:默认情况下,gRPC 客户端可能使用较长的保活间隔(或未启用),导致感知服务器下线的时间过长。缩短到 10 秒后,Collector 能更快发现 Sampling 服务端点不可用。
- 注意事项:gRPC 客户端强制最小值为 10 秒(低于此值会自动调整为 10 秒),因此这是较优的短期选择。
timeout: 3s
- 作用:发送保活 ping 后,客户端等待 3 秒,若无响应则认为连接已死。
- 调整原因 :默认超时(通常 20 秒)过长,导致每次探测等待时间累积,延长了
Shutdown 的执行时间。3 秒的超时能在网络正常时保证响应,又能在异常时快速失败。
- 效果 :结合
time: 10s,最坏情况下 13 秒(10s + 3s)内感知异常,远低于默认配置。
permit_without_stream: true
- 作用:允许客户端在没有活跃 RPC 流时仍发送保活 ping。
- 调整原因 :在 Collector 与 Sampling 服务之间,可能存在空闲连接(无数据传输)。若设为
false,空闲时不会探测,延迟异常检测。设为 true 确保所有连接状态实时更新。
- 场景适用性:此架构中,Collector 可能长时间持有连接但不发送数据,启用此参数尤为重要。
gRPC 服务器配置 (OpenTelemetry-Collector-Sampling)
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:55681
keepalive:
enforcement_policy:
min_time: 8s
permit_without_stream: true
参数解析
enforcement_policy.min_time: 8s
- 作用:服务器要求客户端的保活 ping 间隔不低于 8 秒,若客户端发送过于频繁(例如每 1 秒),服务器会断开连接。
- 调整原因 :客户端的
time: 10s 大于 8 秒,满足服务器要求,避免因违反策略被断开。默认值通常为 5 分钟(300 秒),调整为 8 秒是为了与客户端的短间隔探测兼容。
- 注意事项 :若客户端
time 小于 min_time(例如设为 5 秒),服务器会拒绝连接,客户端需自动加倍 time(如从 5 秒到 10 秒),可能引入额外延迟。
permit_without_stream: true
- 作用:允许服务器接收客户端在无活跃 RPC 流时的保活 ping。
- 调整原因 :与客户端配置保持一致,确保空闲连接也能维持保活探测。若设为
false,服务器可能因未收到预期 ping 而断开空闲连接。
- 效果:增强了架构中空闲连接的稳定性。
效果与验证
- 测试结果:在 RND 环境中复现故障后,调整 Keepalive 参数将恢复时间从 15 分钟缩短到不到 1 分钟。
- 原理 :
- 客户端每 10 秒探测一次,3 秒超时,最多 13 秒内感知 Sampling 服务端点下线。
- gRPC 连接标记为不可用后,
Shutdown 操作无需等待长时间超时,快速完成 boundedMemoryQueue 清理。
updateLock 释放后,dnsResolver 和 Exporter 恢复正常,数据发送不再阻塞。
- 指标验证 :
otelcol_loadbalancer_num_resolutions 从 0 恢复到正常值,mBackendLatency 显示发送延迟下降。
长期解决方案:升级 OpenTelemetry Collector
社区通过 PR #31602 优化了 0.73.0 版本的问题:
- 优化 :
Shutdown 异步执行,不阻塞 updateLock,避免影响 Exporter 调用。
- 版本:2024 年 3 月后(例如 v0.96.0)。
- 建议:升级并测试。
总结与建议
问题回顾
在 客户端 -> OpenTelemetry-Collector (v0.73.0) -> OpenTelemetry-Collector-Sampling -> Trace 后端服务 架构中,Sampling 节点宕机导致 Collector 侧的 gRPC 连接 异常,Collector 的数据发送和 DNS 解析组件在处理下线端点时发生阻塞。恢复时间达 15 分钟。
解决方案
- 临时:调整 Keepalive 参数,恢复时间缩至 1 分钟。
- 长期:升级到 v0.96.0 或更高版本,异步优化解决问题。
建议
- 短期应用 Keepalive 配置。
- 长期升级 Collector,脱离 0.73.0 的局限。
- 监控
otelcol_loadbalancer_num_resolutions 和 mBackendLatency,没有这些指标,问题无从入手。
- 任何优化手段上线前,模拟故障验证效果。
通过版本背景和代码分析,我们理解了 0.73.0 的问题根源,希望这篇博文为类似场景提供参考!