QwQ-32B推理模型正式发布并开源,凭借其卓越的性能和广泛的应用场景,迅速在全球范围内获得了极高的关注度。基于阿里云函数计算 FC提供算力,Serverless+ AI 云原生应用开发平台 CAP现已提供模型服务、应用模板两种部署方式辅助您部署QwQ 32B系列模型。您选择一键部署应用模板与模型进行对话或以API形式调用模型,接入AI应用中。欢迎您立即体验QwQ-32B。
QwQ-32B更小尺寸,性能比肩全球最强开源推理模型
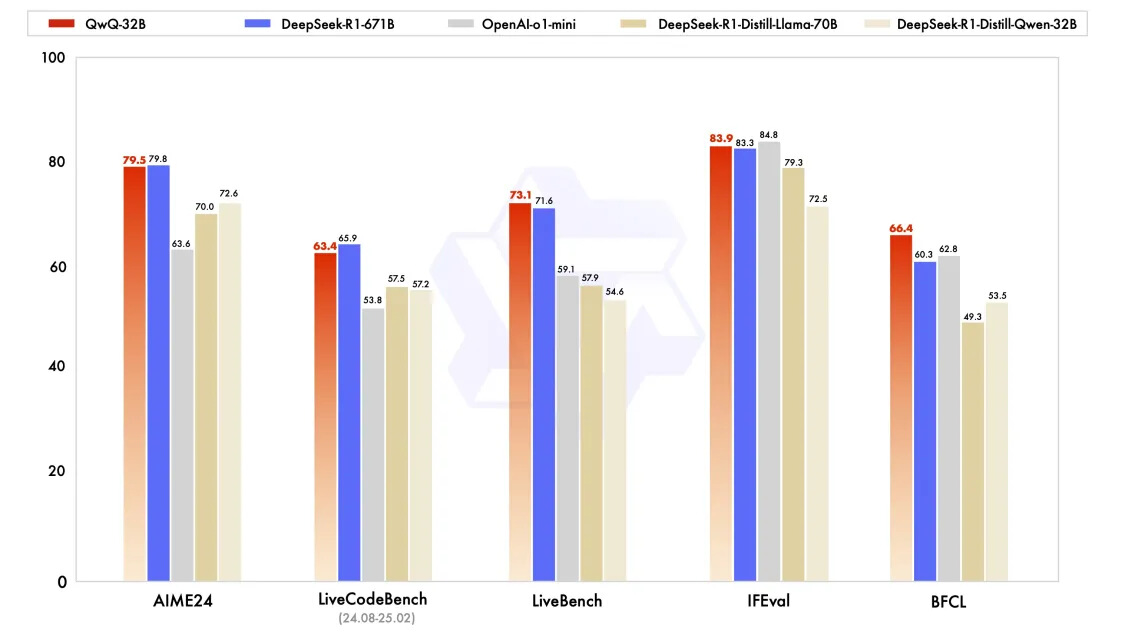
QwQ-32B在一系列基准测试中进行了评估,包括数学推理、编程和通用能力。以下结果展示了QwQ-32B与其他领先模型的性能对比,包括 DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、OpenAI-o1-mini以及原始的DeepSeek-R1-671B。
![]()
在测试数学能力的AIME24评测集上,以及评估代码能力的LiveCodeBench中,千问QwQ-32B表现与DeepSeek-R1-671B相当,远胜于OpenAI-o1-mini及相同尺寸的R1蒸馏模型。在由Meta首席科学家杨立昆领衔的"最难LLMs评测榜" LiveBench、谷歌等提出的指令遵循能力IFEval评测集、由加州大学伯克利分校等提出的评估准确调用函数或工具方面的BFCL测试中,千问QwQ-32B的得分均超越了DeepSeek-R1-671B。
前置准备
1.首次使用云原生应用开发平台 CAP会自动跳转到访问控制快速授权页面,滚动到浏览器底部单击确认授权,等待授权结束后单击返回控制台。
2.本教程在函数计算中创建的GPU函数,函数运行使用的资源按照函数规格乘以执行时长进行计量,如果无请求调用,则只收取闲置预留模式下预置的快照费用,CAP中的极速模式通过预置实例快照实现毫秒级响应,其技术原理对应函数计算的闲置预留模式,适用于需要快速冷启动的场景。建议您领取函数计算的试用额度抵扣资源消耗,超出试用额度的部分将自动转为按量计费,更多计费详情,请参见计费概述。
方式一:应用模板部署
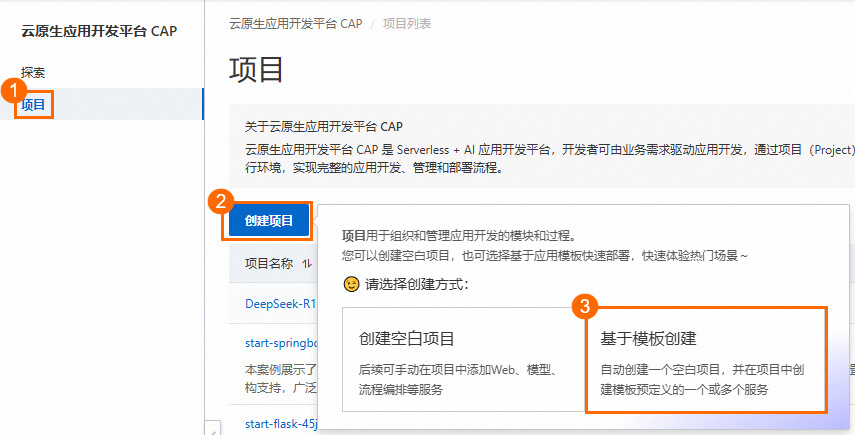
创建项目
进入CAP控制台单击基于模板创建开始创建。
![image]()
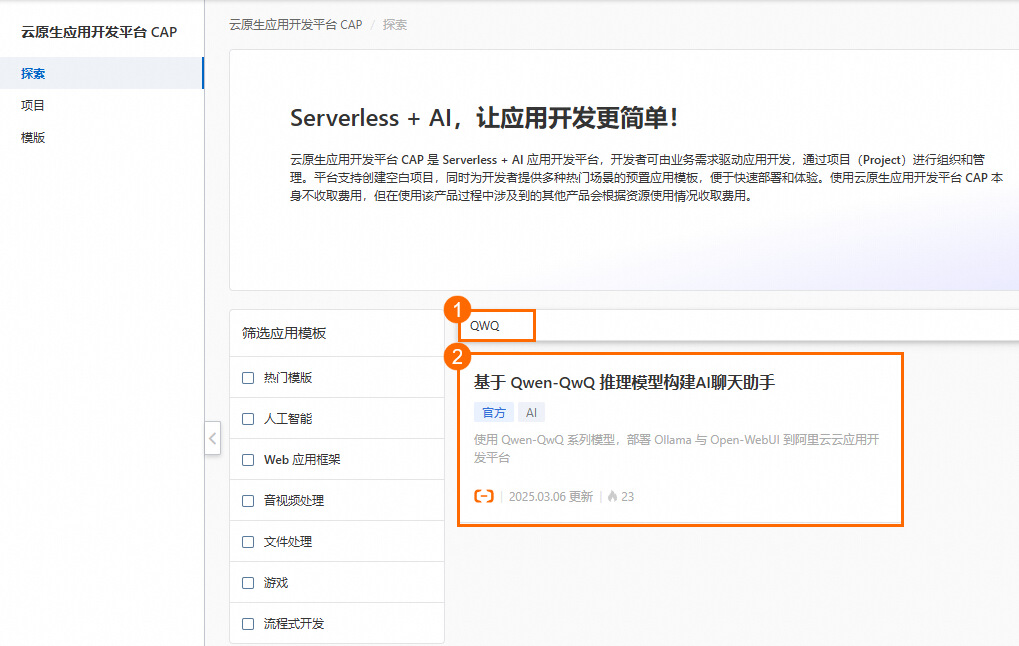
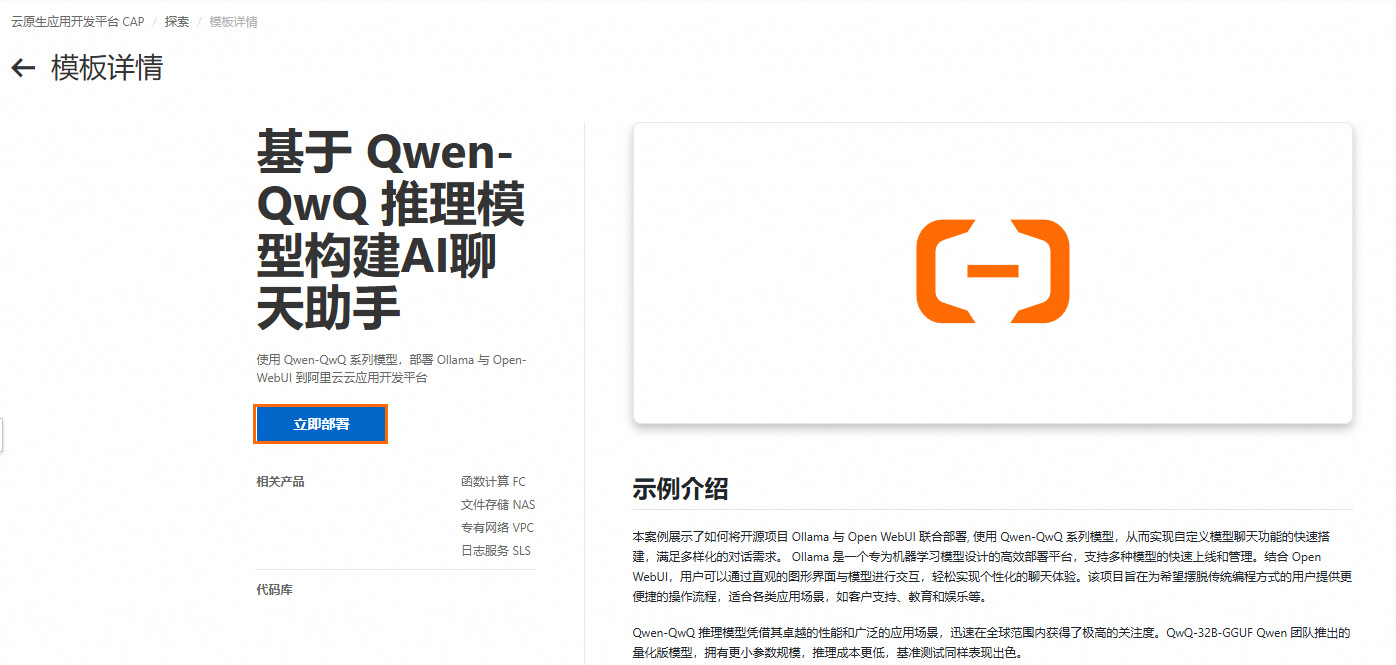
部署模板
1.在搜索栏输入QWQ进行搜索,单击基于 Qwen-QwQ 推理模型构建AI聊天助手 ,进入模板详情页 ,单击立即部署。
![image]()
![image]()
2.选择地域,目前支持 北京、上海、杭州,单击部署项目,在项目资源预览对话框中,您可以看到相关的计费项,详情请见计费涉及的产品。单击确认部署,部署过程大约持续 10 分钟左右,状态显示已部署表示部署成功。
说明
- 选择地域时,一般是就近选择地域信息,如果已经开启了NAS文件系统,选择手动配置模型存储时,请选择和文件系统相同的地域。
- 如果您在测试调用的过程中遇到部署异常或模型拉取失败,可能是当前地域的GPU显卡资源不足,建议您更换地域进行重试。
![image]()
![image]()
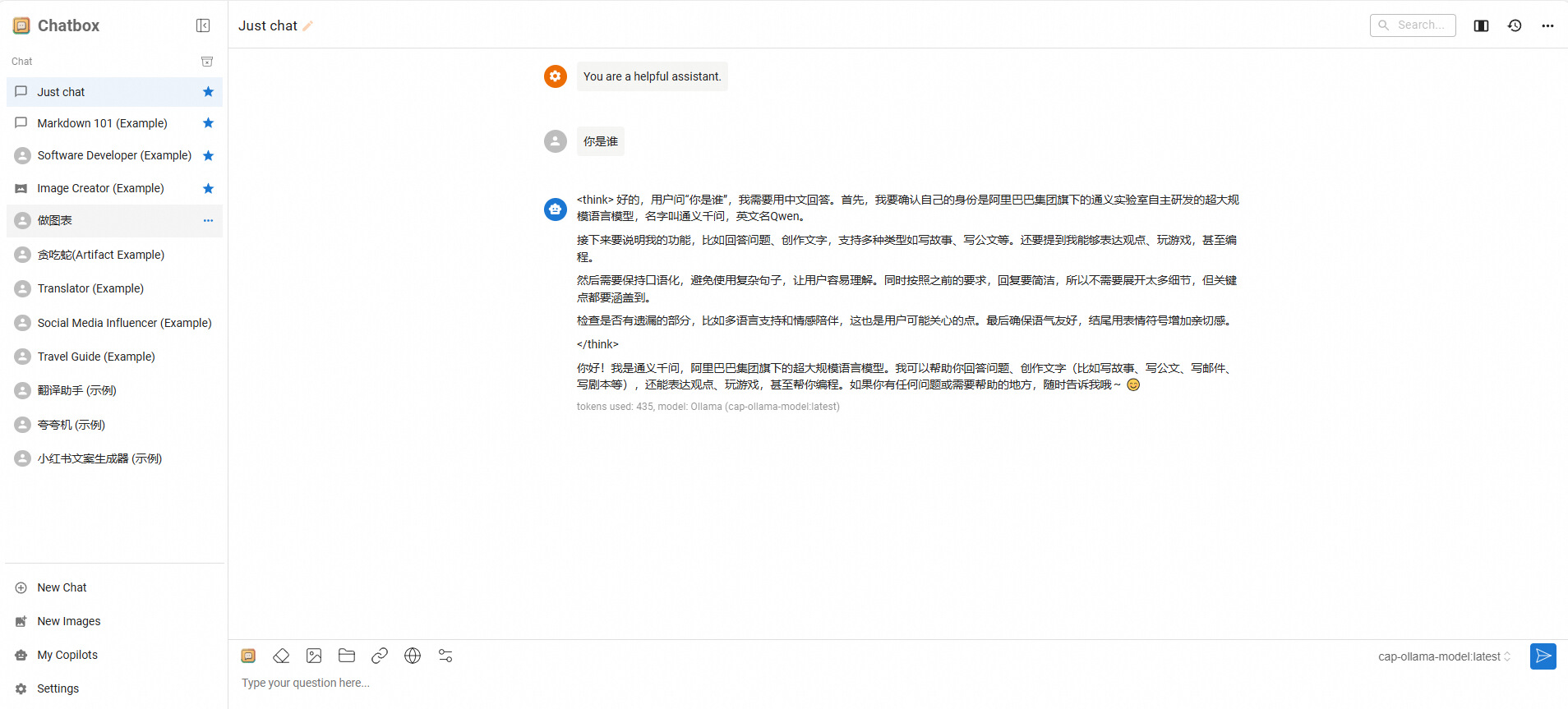
3.验证应用 部署完毕后,点击 Open-WebUI 服务,在访问地址 内找到公网访问单击访问。在OpenWebUI界面体验QwQ模型进行对话。
![image]()
方式二:模型服务部署
使用API形式进行模型调用,接入线上业务应用。
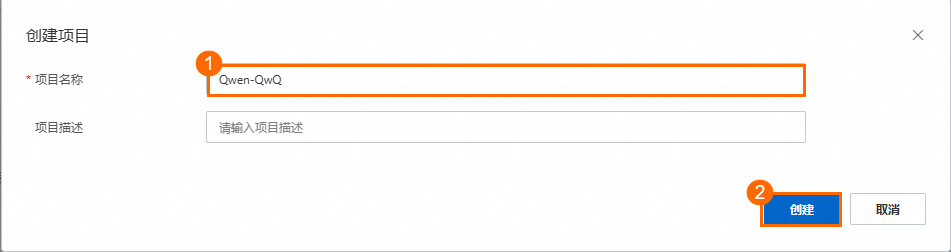
创建空白项目
进入CAP控制台单击创建空白项目开始创建,并为项目命名。
![image]()
![image]()
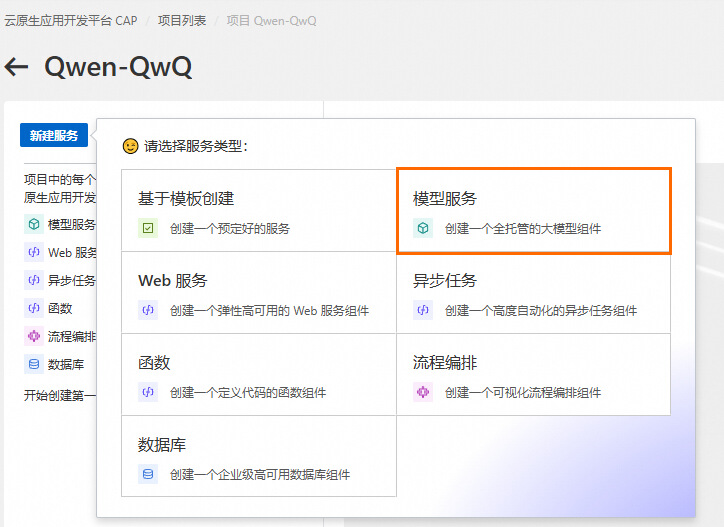
选择模型服务
![image]()
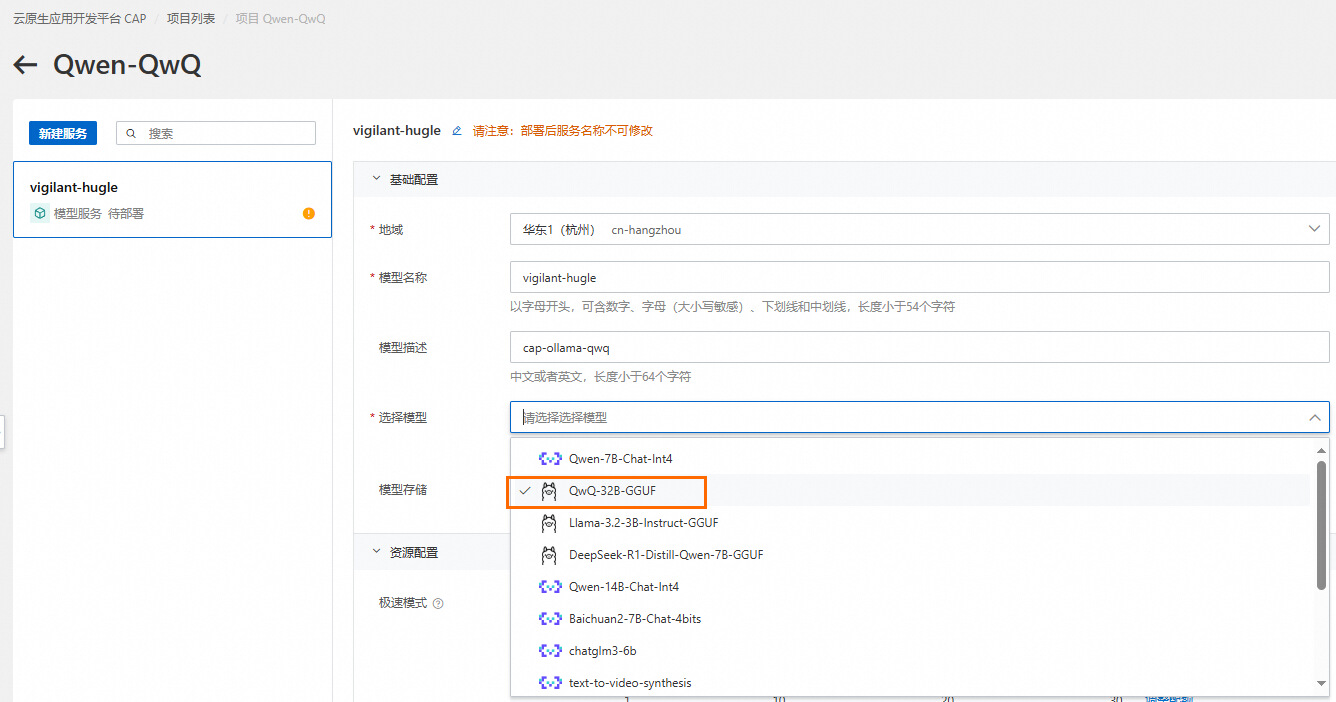
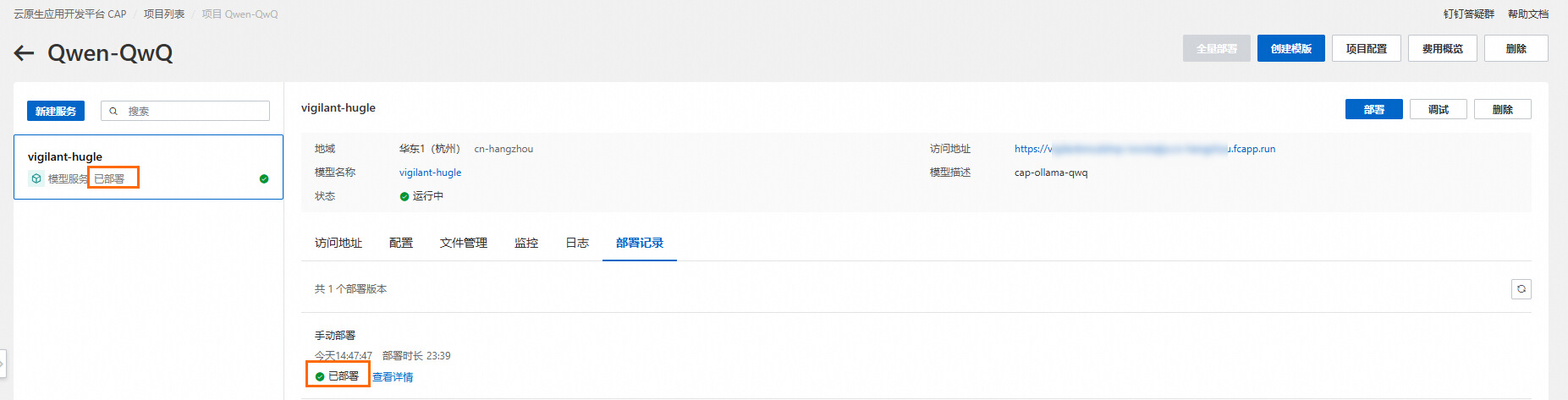
部署模型服务
1.选择模型QwQ-32B-GGUF,目前仅支持杭州地域。
![image]()
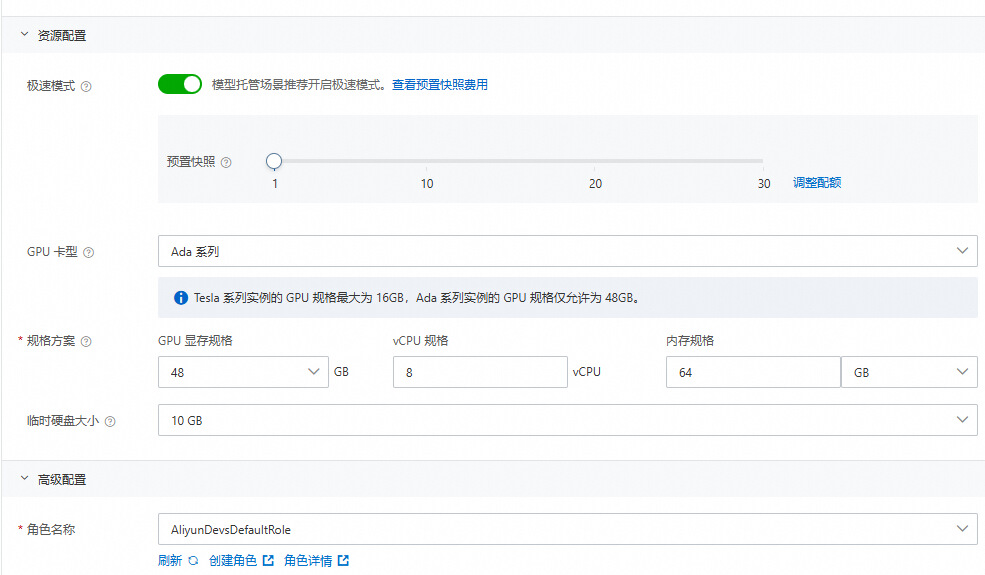
2.单击资源配置,QwQ-32B-GGUF推荐使用 Ada 系列,可直接使用默认配置。您可以根据业务诉求填写需要的卡型及规格信息。
![image]()
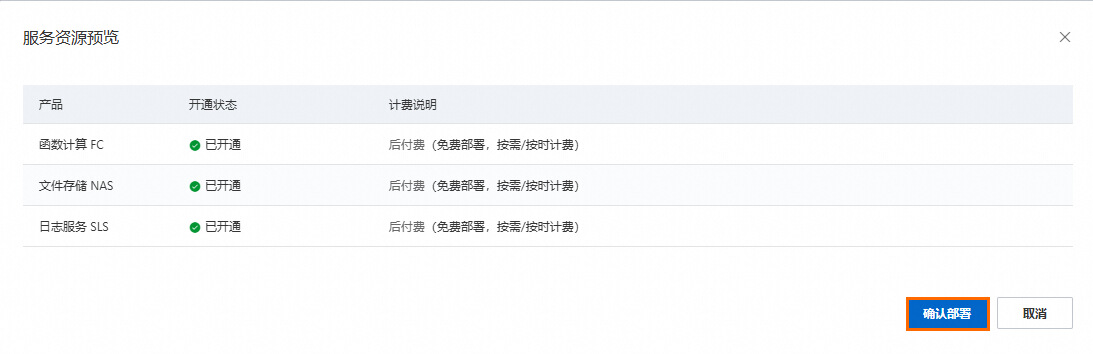
3.单击预览并部署 ,在服务资源预览 对话框中,您可以看到相关的计费项,详情请见计费涉及的产品。单击确认部署,该阶段需下载模型,预计等待10~30分钟即可完成。
![image]()
![image]()
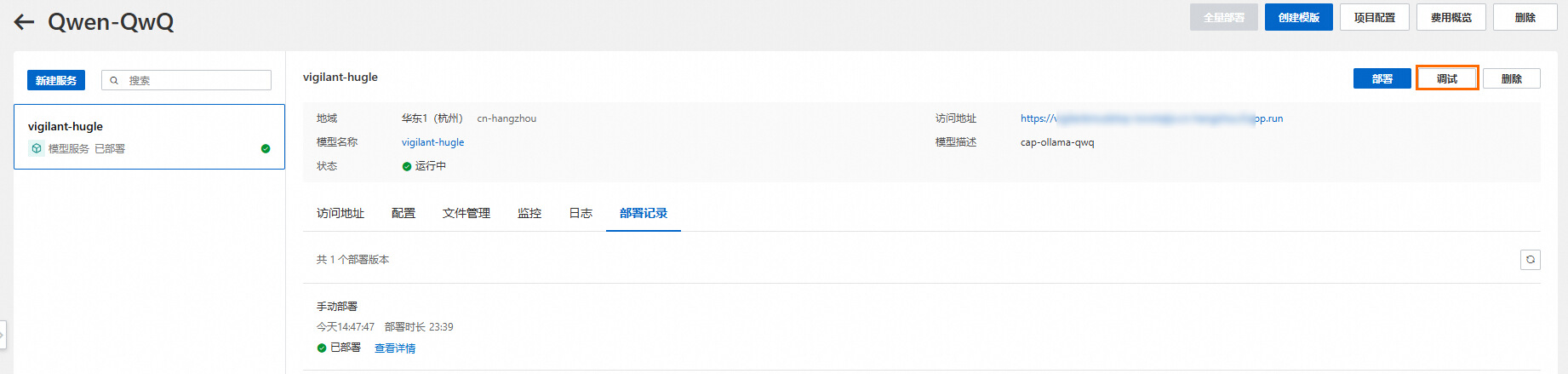
验证模型服务
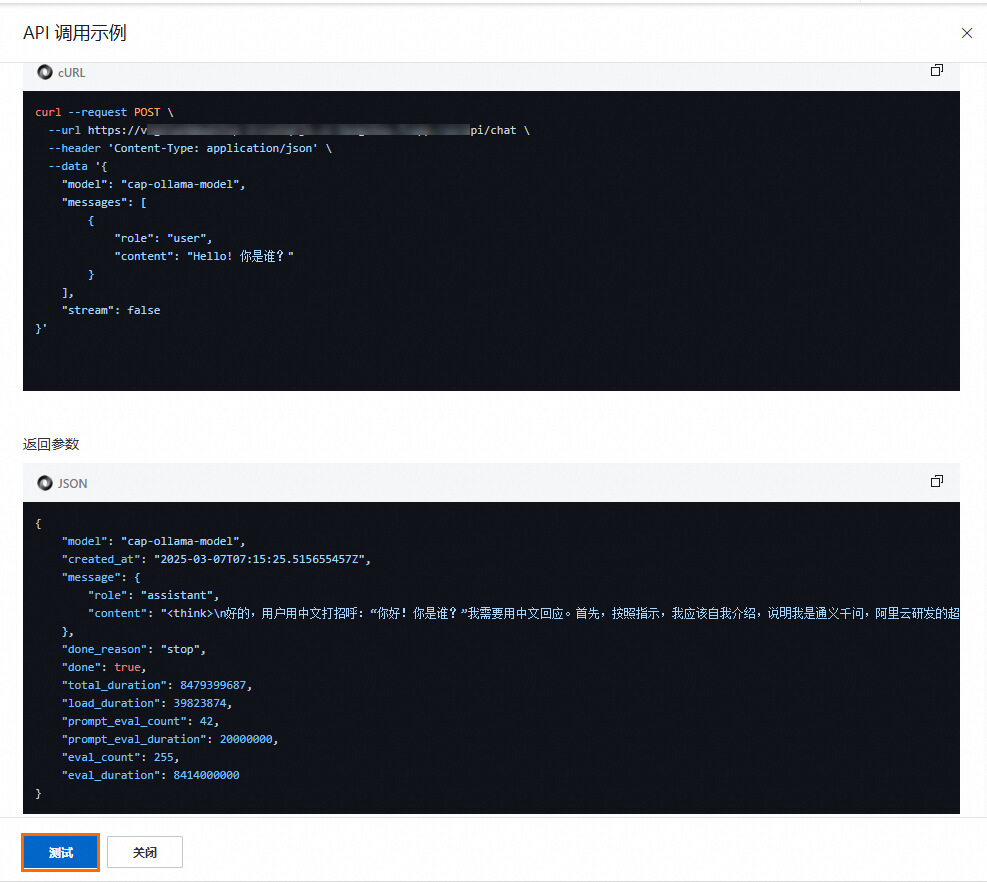
单击调试,即可测试和验证相关模型调用。
![image]()
![image]()
在本地命令行窗口中验证模型调用。
![image]()
第三方平台 API 调用
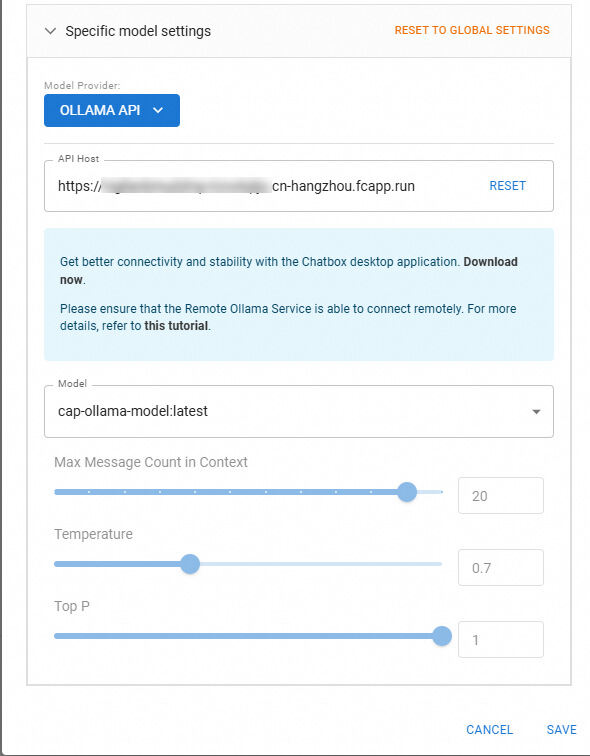
您可以选择在Chatbox等其他第三方平台中验证和应用模型调用,以下以Chatbox为例。
![image]()
![image]()
删除项目
您可以使用以下步骤删除应用,以降低产生的费用。
1.进入项目详情 > 点击删除,会进入到删除确认对话框。
![image]()
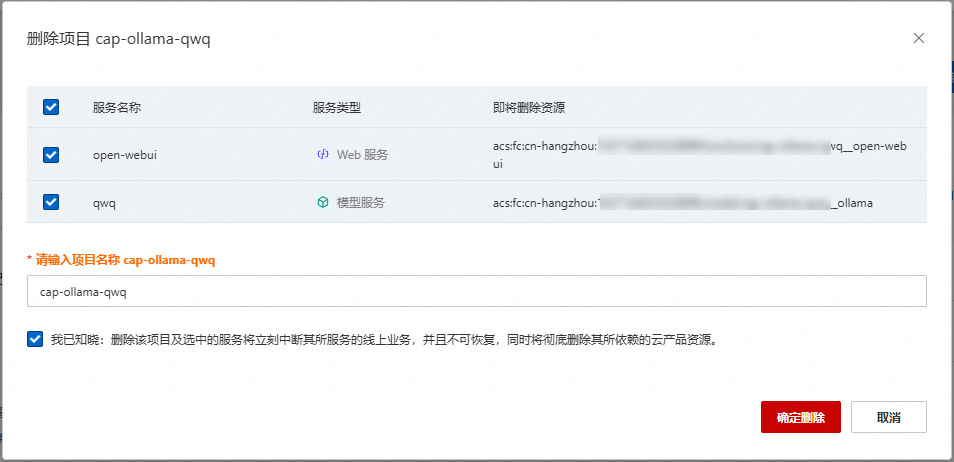
2.您可以看到要删除的资源。默认情况下,云原生应用开发平台 CAP会删除项目下的所有服务。如果您希望保留资源,可以取消勾选 指定的服务,删除项目时只会删除勾选的服务。
![image]()
勾选我已知晓:删除该项目及选中的服务将立刻中断其所服务的线上业务,并且不可恢复,同时将彻底删除其所依赖的云产品资源,然后单击确定删除。
更多内容关注 Serverless 微信公众号(ID:serverlessdevs),汇集 Serverless 技术最全内容,定期举办 Serverless 活动、直播,用户最佳实践。