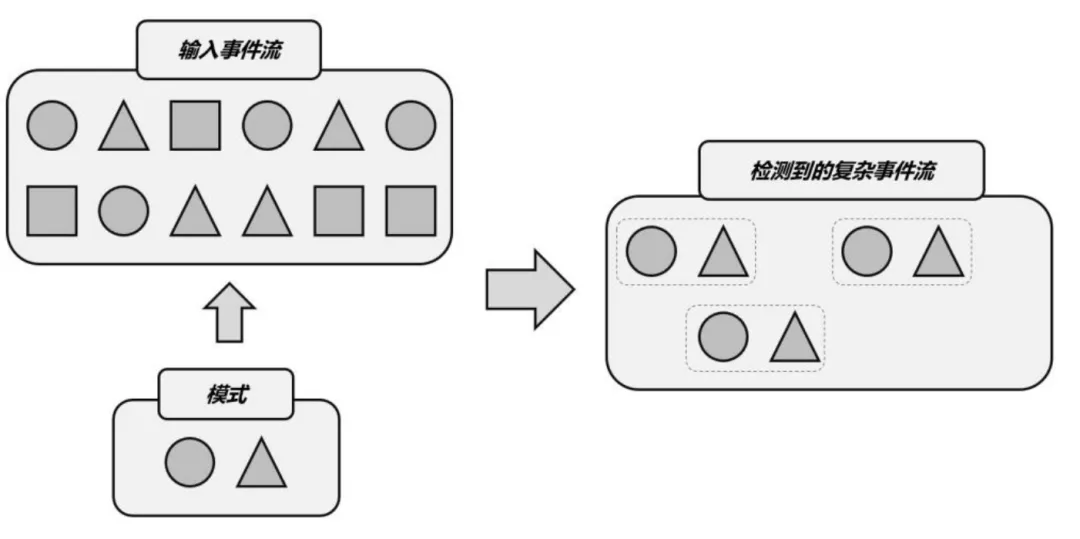
本文通过实际案例深入探讨了 Flink CEP 在复杂事件处理中的核心作用,详细分析了其优缺点,并探讨了在实时计算平台中规则热更新的重要性和创新实现方式,旨在帮助读者更好地理解和应用 Flink CEP。 Flink CEP 1.1 什么是 Flink CEP FlinkCEP 是在 Flink 上层实现的复杂事件处理库。它可以让你在无限事件流中检测出特定的事件模型,并允许用户做出针对性的处理。它更多被应用在实时营销、实时风控和物联网等场景。 在传统的数据处理中,用户更多关注于单一数据的特征,而忽略了数据间的特征。随着业务的不断扩展和数据量的快速增长,用户在某些业务场景中不再满足于单一数据特征的处理,而是需要基于多个数据特征之间的关联进行更复杂的响应处理。 Flink CEP 则基于此需求而诞生。在 Flink CEP 中,每一个数据被视为一个事件,由众多数据组成的数据流就是一串事件流,Flink CEP 能够根据用户提供的事件流匹配规则,在一串事件流中进行摄取。 ![file]() 在实际应用中,Flink CEP 的优势主要体现在以下几个方面: (1)高性能:Flink CEP 在底层使用 Flink 的分布式计算框架,能够高效地处理大规模数据流。它支持实时流处理和批处理,并能够根据业务需求进行灵活的扩展。 (2)事件模式匹配:Flink CEP 提供了一组事件模式匹配器,可以根据预设的模式规则来匹配事件序列中的特定模式。这些规则可以是简单的模式(如出现特定事件),也可以是复杂的模式(如多个事件按照特定顺序发生)。 (3)事件时间戳和时间窗口:Flink CEP 支持事件时间戳和时间窗口的概念,能够根据事件的实际时间戳进行时间相关的计算和分析。有助于处理具有时间相关性的复杂事件序列。 (4)自定义逻辑:Flink CEP 允许用户根据具体需求编写自定义逻辑来处理复杂事件。用户可以通过扩展 Flink CEP 的 API 来实现自己的事件处理逻辑,从而更好地满足业务需求。在实际案例中,Flink CEP 可以应用于多个领域。例如,在金融领域中,它可以用于实时监测交易异常行为,如识别出可能存在欺诈行为的交易模式;在物联网领域中,它可以用于实时分析传感器数据流,如监测设备的运行状态和预警故障;在社交媒体领域中,它可以用于实时分析用户行为和舆情趋势,为营销策略提供支持。 总的来说,Flink CEP 是一种强大的复杂事件处理工具,能够应对传统数据处理方式难以应对的问题。通过关注并捕获一系列有特定规律的事件,Flink CEP 可以帮助我们提供更深入的业务洞察和实时决策支持。未来,随着业务需求的不断变化和技术的发展,Flink CEP 在数据处理和分析中的应用将会更加广泛和深入。 1.2 Flink CEP 现有的缺点 用户可以通过 DataStream API 或者 Flink SQL 进行 Flink CEP 任务的编写,然后通过数栈将任务提交到 Yarn 上运行。但是对于一些复杂多变的应用场景,用户可能需要针对业务变更,频繁地对 Flink CEP 任务进行规则修改,规则修改之后又需要先停止正在运行中的任务,然后重新提交任务。这一业务变更流程通常至少需要5-10分钟的变更时间,在此期间没有办法对事件进行捕获处理。这样做的时间成本非常高,对于延迟敏感的作业来说是很难接受的。此外,如果我们的事件规则窗口设置的比较长,并且在运行过程中产生了比较大的状态的话,重启作业的时间、代价会进一步更高。 因此 Flink CEP 的规则热更新对于提高 Flink CEP 的生产可用能力是一个很重要的功能。
在实际应用中,Flink CEP 的优势主要体现在以下几个方面: (1)高性能:Flink CEP 在底层使用 Flink 的分布式计算框架,能够高效地处理大规模数据流。它支持实时流处理和批处理,并能够根据业务需求进行灵活的扩展。 (2)事件模式匹配:Flink CEP 提供了一组事件模式匹配器,可以根据预设的模式规则来匹配事件序列中的特定模式。这些规则可以是简单的模式(如出现特定事件),也可以是复杂的模式(如多个事件按照特定顺序发生)。 (3)事件时间戳和时间窗口:Flink CEP 支持事件时间戳和时间窗口的概念,能够根据事件的实际时间戳进行时间相关的计算和分析。有助于处理具有时间相关性的复杂事件序列。 (4)自定义逻辑:Flink CEP 允许用户根据具体需求编写自定义逻辑来处理复杂事件。用户可以通过扩展 Flink CEP 的 API 来实现自己的事件处理逻辑,从而更好地满足业务需求。在实际案例中,Flink CEP 可以应用于多个领域。例如,在金融领域中,它可以用于实时监测交易异常行为,如识别出可能存在欺诈行为的交易模式;在物联网领域中,它可以用于实时分析传感器数据流,如监测设备的运行状态和预警故障;在社交媒体领域中,它可以用于实时分析用户行为和舆情趋势,为营销策略提供支持。 总的来说,Flink CEP 是一种强大的复杂事件处理工具,能够应对传统数据处理方式难以应对的问题。通过关注并捕获一系列有特定规律的事件,Flink CEP 可以帮助我们提供更深入的业务洞察和实时决策支持。未来,随着业务需求的不断变化和技术的发展,Flink CEP 在数据处理和分析中的应用将会更加广泛和深入。 1.2 Flink CEP 现有的缺点 用户可以通过 DataStream API 或者 Flink SQL 进行 Flink CEP 任务的编写,然后通过数栈将任务提交到 Yarn 上运行。但是对于一些复杂多变的应用场景,用户可能需要针对业务变更,频繁地对 Flink CEP 任务进行规则修改,规则修改之后又需要先停止正在运行中的任务,然后重新提交任务。这一业务变更流程通常至少需要5-10分钟的变更时间,在此期间没有办法对事件进行捕获处理。这样做的时间成本非常高,对于延迟敏感的作业来说是很难接受的。此外,如果我们的事件规则窗口设置的比较长,并且在运行过程中产生了比较大的状态的话,重启作业的时间、代价会进一步更高。 因此 Flink CEP 的规则热更新对于提高 Flink CEP 的生产可用能力是一个很重要的功能。 ![file]() 数栈对于 Flink CEP 规则热更新的扩展 数栈基于 Flink 1.16 并借鉴学习了业界现有的方案后实现了 Flink CEP 规则热更新。 2.1 Flink CEP 使用案例 在介绍 Flink CEP 规则热更新之前我们先来看下 Flink CEP 常规的 DataStream API 和 SQL 是怎么处理以下一个场景的: 针对于一条包含了复数个 Event(id int, volume double, name varchar) 对象的事件流,我们希望能在流中找到一条子流,该子流中第一个 Event 对象的 id 为 42,然后紧接着第二个 Event 对象的 volume 大于 10.0,然后紧接着第二个 Event 对象的 name 必须是 "end"。对于这样的一个子流,我们要获得子流中所有 value 的值的总和。 基于 Data Stream API 开发 DataStream input = ...;
数栈对于 Flink CEP 规则热更新的扩展 数栈基于 Flink 1.16 并借鉴学习了业界现有的方案后实现了 Flink CEP 规则热更新。 2.1 Flink CEP 使用案例 在介绍 Flink CEP 规则热更新之前我们先来看下 Flink CEP 常规的 DataStream API 和 SQL 是怎么处理以下一个场景的: 针对于一条包含了复数个 Event(id int, volume double, name varchar) 对象的事件流,我们希望能在流中找到一条子流,该子流中第一个 Event 对象的 id 为 42,然后紧接着第二个 Event 对象的 volume 大于 10.0,然后紧接着第二个 Event 对象的 name 必须是 "end"。对于这样的一个子流,我们要获得子流中所有 value 的值的总和。 基于 Data Stream API 开发 DataStream input = ...;
Pattern<Event, ?> pattern = Pattern.begin("start") .where( new SimpleCondition() { @Override public boolean filter (Event event) { return event.getId() == 42; } ) .next("middle").where( new SimpleCondition { @Override public boolean filter(SubEvent subEvent) { return subEvent.getVolume() >= 10.0; } } ).next("end" ).where ( new SimpleCondition() { @Override public boolean filter (Event event) { return event.getName().equals("end"); } } );
PatternStream patternStream = CEP.pattern(input, pattern); DataStream result = patternStream.process ( new PatternProcessFunction<Event, Double>() { @Override public void processMatch( Map<String, List> pattern, Context ctx, Collector out) throws Exception { Double total = 0d; for (Map.Entry<String, List> entry : pattern.entrySet()) ‹ total = total + entry.getValue().get(0).getVolume(); } out.collect(total); }); 基于 SQL 开发 CREATE TABLE source ( id INT, name VARCHAR, volume DOUBLE procTime AS PROCTIME () ) WITH ( 'connector' = 'kafka', 'topic' = 'dtstack', 'properties.group.id' = 'dtstack', 'scan.startup.mode' = 'latest-offset', 'properties.bootstrap.servers' = '127.0.0.1:9092', 'format'= 'json' )
SELECT total FROM source MATCH_RECOGNIZE ( ORDER BY procTime MEASURES A. volume + B.volume + C.volume as total ONE ROW PER MATCH PATTERN (A B C) DEFINE A AS A. id == 42, B AS B. volume >= 10.0 C AS C. name == 'end' ) 在 Data Stream API 的案例中,3-25 行的代码描述了子流的一个捕获规则,28-40 行的代码描述了对捕获到的子流如何处理的,并将处理完成后的数据发送给下游的算子。 在 SQL 案例中 ,22-26 行 SQL 描述了子流的一个捕获规则,19-20 行的 SQL 描述了对捕获到的子流如何处理的。 如果用户对于上述 CEP 规则有变更,则需要修改相对应的代码或者 SQL。 2.2 Flink CEP 规则热更新使用案例 2.2.1 任务本体和规则剥离 Flink CEP 规则热更新功能在上层提供了相应的 Data Stream API 以及的 SQL 语法扩展用于用户编写能够使用 Flink CEP 热更新的程序。用户所需要做的是对上述代码进行改造,将代码中的规则(子流捕获逻辑)以及规则处理逻辑的代码片段去掉,因为这两块逻辑将储存在外部存储中。 对于 Data Stream API DataStream input = ...;
PatternStream output = CEP.dynamicPatterns( input, new JDBCPeriodicPatternProcessorDiscovererFactory<>( JDBC_URL, JDBC_DRIVE, TABLE_NAME, null, JDBC_INTERVAL_MILLIS), TimeBehaviour.ProcessingTime, TypeInformation.of(new TypeHint(){}) ) 对于 SQL CREATE TABLE source ( id INT, name VARCHAR, volume DOUBLE procTime AS PROCTIME () ) WITH ( 'connector' = 'kafka', 'topic' = 'dtstack', 'properties.group.id' = 'dtstack', 'scan.startup.mode' = 'latest-offset', 'properties.bootstrap.servers' = '127.0.0.1:9092', 'format'= 'json' )
SELECT total FROM source DYNAMIC MATCH_RECOGNIZE ( ORDER BY procTime OUTPUT (total double) WITH_PATTERN ( 'tableName' = 'dynamic_cep', 'user' = 'dtstack', 'password' = '***', 'driver' = 'com.mysql.cj jdbc.Driver', 'jdbcUrl' = 'jdbc:mysql://127.0.0.1:3306/cep', 'jdbcIntervalMillis' = '1000' ) ) AS T; 将规则从任务本体中剥离之后,任务侧可以单独通过数栈提交到 Yarn 上,但是此时若用户还没有为任务设置规则,任务将会进入一种 block 的状态,不会从对上游的数据进行处理。 ![file]() 2.2.2 CEP 规则 JSON 描述文件编写 外部化的规则将通过特定的 JSON 格式进行描述并将其存储到数栈中。用户在数栈上可以通过编辑器对 JSON 格式的规则进行编辑保存以及更新。 CEP 规则使用 JSON 描述文件编写。每一个规则可以被描述为一个规则节点,多个规则节点可以组合成一个有向图(Graph)。"图"可以被视为一种特殊的复合规则节点,因此"图"与"图"之间、"图"与规则节点之间也可以相互组合。 通过规则节点的配置用户可以匹配到 n 个数据流中的节点,再通过规则节点之间的组合搭配用户可以实现更加复杂的规则逻辑匹配。 比如下面的一个规则描述文件: 通过定义一个 COMPOSITE 类型的规则节点即上文中的"图","图"中的 edges 定义了"图"中的子节点的顺序:start -> middle -> end。 然后在其 nodes 中会定义每个节点的匹配细节:start 规则匹配一个 id 字段为 45 的事件,middle 规则匹配一个 volume >= 10.0 的事件,end 规则匹配一个 name 为 "end" 的事件。 {
2.2.2 CEP 规则 JSON 描述文件编写 外部化的规则将通过特定的 JSON 格式进行描述并将其存储到数栈中。用户在数栈上可以通过编辑器对 JSON 格式的规则进行编辑保存以及更新。 CEP 规则使用 JSON 描述文件编写。每一个规则可以被描述为一个规则节点,多个规则节点可以组合成一个有向图(Graph)。"图"可以被视为一种特殊的复合规则节点,因此"图"与"图"之间、"图"与规则节点之间也可以相互组合。 通过规则节点的配置用户可以匹配到 n 个数据流中的节点,再通过规则节点之间的组合搭配用户可以实现更加复杂的规则逻辑匹配。 比如下面的一个规则描述文件: 通过定义一个 COMPOSITE 类型的规则节点即上文中的"图","图"中的 edges 定义了"图"中的子节点的顺序:start -> middle -> end。 然后在其 nodes 中会定义每个节点的匹配细节:start 规则匹配一个 id 字段为 45 的事件,middle 规则匹配一个 volume >= 10.0 的事件,end 规则匹配一个 name 为 "end" 的事件。 {
"name": "rule",
"type": "COMPOSITE", "edges": [{
"source": "start",
"target": "middle",
"type": "SKIP_TILL_NEXT"
},{
"source": "middle",
"target": "end",
"type": "SKIP_TILL_NEXT"
}],
"nodes": [{
"name": "start",
"condition": {
"expression": "id == 45",
"type": "AVIATOR"
},
"type": "ATOMIC"
},
{
"name": "middle",
"condition": {
"expression": "volume >= 10.0",
"type": "AVIATOR"
},
"type": "ATOMIC"
}, {
"name": "end",
"condition": {
"expression": "name == 'end'",
"type": "AVIATOR"
},
"type": "ATOMIC"
}
]...
} Flink Runtime 层通过解析 JSON 并将其转换为 Graph 用于描述规则状态机的状态转换,规则内部的匹配条件使用 Google Aviator 对表达式进行解析并求值计算。 在运行阶段 Flink Jobmanager 一旦检测到 CEP 规则内容变更后,会对新的规则进行校验然后会推送规则更新的系统事件给复数个 Flink Taskmanager,其中规则更新的系统事件中包含着新规则的详细描述信息。Taskmanager 在接受到规则更新的系统事件后会从其中获得新规则的信息并将其应用给 CEP 算子,之后 CEP 算子会将新的规则设置到算子内部的状态机中,完成对事件规则的热更新。 整个更新过程中不涉及到任务的重启,在几秒内就能完成更新,在新规则未更新完成前任务将依旧以旧规则运行直到新规则替换旧规则,新旧规则可以在用户无感的情况下完成替换。
 在实际应用中,Flink CEP 的优势主要体现在以下几个方面: (1)高性能:Flink CEP 在底层使用 Flink 的分布式计算框架,能够高效地处理大规模数据流。它支持实时流处理和批处理,并能够根据业务需求进行灵活的扩展。 (2)事件模式匹配:Flink CEP 提供了一组事件模式匹配器,可以根据预设的模式规则来匹配事件序列中的特定模式。这些规则可以是简单的模式(如出现特定事件),也可以是复杂的模式(如多个事件按照特定顺序发生)。 (3)事件时间戳和时间窗口:Flink CEP 支持事件时间戳和时间窗口的概念,能够根据事件的实际时间戳进行时间相关的计算和分析。有助于处理具有时间相关性的复杂事件序列。 (4)自定义逻辑:Flink CEP 允许用户根据具体需求编写自定义逻辑来处理复杂事件。用户可以通过扩展 Flink CEP 的 API 来实现自己的事件处理逻辑,从而更好地满足业务需求。在实际案例中,Flink CEP 可以应用于多个领域。例如,在金融领域中,它可以用于实时监测交易异常行为,如识别出可能存在欺诈行为的交易模式;在物联网领域中,它可以用于实时分析传感器数据流,如监测设备的运行状态和预警故障;在社交媒体领域中,它可以用于实时分析用户行为和舆情趋势,为营销策略提供支持。 总的来说,Flink CEP 是一种强大的复杂事件处理工具,能够应对传统数据处理方式难以应对的问题。通过关注并捕获一系列有特定规律的事件,Flink CEP 可以帮助我们提供更深入的业务洞察和实时决策支持。未来,随着业务需求的不断变化和技术的发展,Flink CEP 在数据处理和分析中的应用将会更加广泛和深入。 1.2 Flink CEP 现有的缺点 用户可以通过 DataStream API 或者 Flink SQL 进行 Flink CEP 任务的编写,然后通过数栈将任务提交到 Yarn 上运行。但是对于一些复杂多变的应用场景,用户可能需要针对业务变更,频繁地对 Flink CEP 任务进行规则修改,规则修改之后又需要先停止正在运行中的任务,然后重新提交任务。这一业务变更流程通常至少需要5-10分钟的变更时间,在此期间没有办法对事件进行捕获处理。这样做的时间成本非常高,对于延迟敏感的作业来说是很难接受的。此外,如果我们的事件规则窗口设置的比较长,并且在运行过程中产生了比较大的状态的话,重启作业的时间、代价会进一步更高。 因此 Flink CEP 的规则热更新对于提高 Flink CEP 的生产可用能力是一个很重要的功能。
在实际应用中,Flink CEP 的优势主要体现在以下几个方面: (1)高性能:Flink CEP 在底层使用 Flink 的分布式计算框架,能够高效地处理大规模数据流。它支持实时流处理和批处理,并能够根据业务需求进行灵活的扩展。 (2)事件模式匹配:Flink CEP 提供了一组事件模式匹配器,可以根据预设的模式规则来匹配事件序列中的特定模式。这些规则可以是简单的模式(如出现特定事件),也可以是复杂的模式(如多个事件按照特定顺序发生)。 (3)事件时间戳和时间窗口:Flink CEP 支持事件时间戳和时间窗口的概念,能够根据事件的实际时间戳进行时间相关的计算和分析。有助于处理具有时间相关性的复杂事件序列。 (4)自定义逻辑:Flink CEP 允许用户根据具体需求编写自定义逻辑来处理复杂事件。用户可以通过扩展 Flink CEP 的 API 来实现自己的事件处理逻辑,从而更好地满足业务需求。在实际案例中,Flink CEP 可以应用于多个领域。例如,在金融领域中,它可以用于实时监测交易异常行为,如识别出可能存在欺诈行为的交易模式;在物联网领域中,它可以用于实时分析传感器数据流,如监测设备的运行状态和预警故障;在社交媒体领域中,它可以用于实时分析用户行为和舆情趋势,为营销策略提供支持。 总的来说,Flink CEP 是一种强大的复杂事件处理工具,能够应对传统数据处理方式难以应对的问题。通过关注并捕获一系列有特定规律的事件,Flink CEP 可以帮助我们提供更深入的业务洞察和实时决策支持。未来,随着业务需求的不断变化和技术的发展,Flink CEP 在数据处理和分析中的应用将会更加广泛和深入。 1.2 Flink CEP 现有的缺点 用户可以通过 DataStream API 或者 Flink SQL 进行 Flink CEP 任务的编写,然后通过数栈将任务提交到 Yarn 上运行。但是对于一些复杂多变的应用场景,用户可能需要针对业务变更,频繁地对 Flink CEP 任务进行规则修改,规则修改之后又需要先停止正在运行中的任务,然后重新提交任务。这一业务变更流程通常至少需要5-10分钟的变更时间,在此期间没有办法对事件进行捕获处理。这样做的时间成本非常高,对于延迟敏感的作业来说是很难接受的。此外,如果我们的事件规则窗口设置的比较长,并且在运行过程中产生了比较大的状态的话,重启作业的时间、代价会进一步更高。 因此 Flink CEP 的规则热更新对于提高 Flink CEP 的生产可用能力是一个很重要的功能。  数栈对于 Flink CEP 规则热更新的扩展 数栈基于 Flink 1.16 并借鉴学习了业界现有的方案后实现了 Flink CEP 规则热更新。 2.1 Flink CEP 使用案例 在介绍 Flink CEP 规则热更新之前我们先来看下 Flink CEP 常规的 DataStream API 和 SQL 是怎么处理以下一个场景的: 针对于一条包含了复数个 Event(id int, volume double, name varchar) 对象的事件流,我们希望能在流中找到一条子流,该子流中第一个 Event 对象的 id 为 42,然后紧接着第二个 Event 对象的 volume 大于 10.0,然后紧接着第二个 Event 对象的 name 必须是 "end"。对于这样的一个子流,我们要获得子流中所有 value 的值的总和。 基于 Data Stream API 开发 DataStream input = ...;
数栈对于 Flink CEP 规则热更新的扩展 数栈基于 Flink 1.16 并借鉴学习了业界现有的方案后实现了 Flink CEP 规则热更新。 2.1 Flink CEP 使用案例 在介绍 Flink CEP 规则热更新之前我们先来看下 Flink CEP 常规的 DataStream API 和 SQL 是怎么处理以下一个场景的: 针对于一条包含了复数个 Event(id int, volume double, name varchar) 对象的事件流,我们希望能在流中找到一条子流,该子流中第一个 Event 对象的 id 为 42,然后紧接着第二个 Event 对象的 volume 大于 10.0,然后紧接着第二个 Event 对象的 name 必须是 "end"。对于这样的一个子流,我们要获得子流中所有 value 的值的总和。 基于 Data Stream API 开发 DataStream input = ...;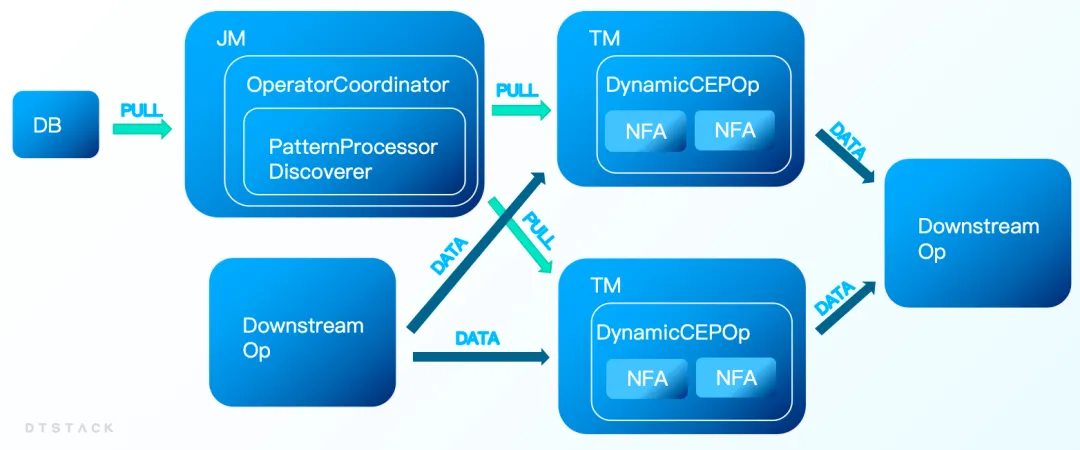 2.2.2 CEP 规则 JSON 描述文件编写 外部化的规则将通过特定的 JSON 格式进行描述并将其存储到数栈中。用户在数栈上可以通过编辑器对 JSON 格式的规则进行编辑保存以及更新。 CEP 规则使用 JSON 描述文件编写。每一个规则可以被描述为一个规则节点,多个规则节点可以组合成一个有向图(Graph)。"图"可以被视为一种特殊的复合规则节点,因此"图"与"图"之间、"图"与规则节点之间也可以相互组合。 通过规则节点的配置用户可以匹配到 n 个数据流中的节点,再通过规则节点之间的组合搭配用户可以实现更加复杂的规则逻辑匹配。 比如下面的一个规则描述文件: 通过定义一个 COMPOSITE 类型的规则节点即上文中的"图","图"中的 edges 定义了"图"中的子节点的顺序:start -> middle -> end。 然后在其 nodes 中会定义每个节点的匹配细节:start 规则匹配一个 id 字段为 45 的事件,middle 规则匹配一个 volume >= 10.0 的事件,end 规则匹配一个 name 为 "end" 的事件。 {
2.2.2 CEP 规则 JSON 描述文件编写 外部化的规则将通过特定的 JSON 格式进行描述并将其存储到数栈中。用户在数栈上可以通过编辑器对 JSON 格式的规则进行编辑保存以及更新。 CEP 规则使用 JSON 描述文件编写。每一个规则可以被描述为一个规则节点,多个规则节点可以组合成一个有向图(Graph)。"图"可以被视为一种特殊的复合规则节点,因此"图"与"图"之间、"图"与规则节点之间也可以相互组合。 通过规则节点的配置用户可以匹配到 n 个数据流中的节点,再通过规则节点之间的组合搭配用户可以实现更加复杂的规则逻辑匹配。 比如下面的一个规则描述文件: 通过定义一个 COMPOSITE 类型的规则节点即上文中的"图","图"中的 edges 定义了"图"中的子节点的顺序:start -> middle -> end。 然后在其 nodes 中会定义每个节点的匹配细节:start 规则匹配一个 id 字段为 45 的事件,middle 规则匹配一个 volume >= 10.0 的事件,end 规则匹配一个 name 为 "end" 的事件。 {