2月26日 2025 阿里云PolarDB开发者大会上,云原生数据库PolarDB正式推出内置大模型的PolarDB AI版本,帮助个人和企业开发者快速部署并上线AI应用。PolarDB AI节点采用模型算子化形态,支持用户在数据库内部直接进行搜索推理优化,在线推理吞吐量可提升10倍以上,显著降低用户部署成本。
![]()
“阿里云PolarDB将Data+AI全面融合,旨在为用户提供更普惠、易用的数据管理平台,帮助个人开发者和企业用户用数据驱动创新”,阿里云副总裁、数据库产品事业部负责人李飞飞表示。我们将面向云原生、AI驱动持续演进,让AI时代的数据库开发像‘搭积木’一样简单,显著降低数据库的应用门槛。
据悉,云原生数据库PolarDB用户数已突破1万家,部署量超100万核,覆盖全球80多个可用区。目前,PolarDB AI节点已助力100余家大型客户提高在线推理效率,大幅提升业务效果。
1、AI时代,PolarDB持续拓展云原生边界
![]()
阿里云市场营销总裁刘湘雯
阿里云市场营销总裁刘湘雯在大会致辞中表示:“无论在互联网时代还是AI时代,数据都是技术发展的基石,开发者都是价值创造的先锋。阿里云坚持以技术创新和共享,为开发者提供成长平台,让开发者能像搭积木一样用好数据库、用好人工智能,共创AI时代的新未来。”
![]()
中国工程院院士、清华大学教授郑纬民
中国工程院院士、清华大学教授郑纬民发表《AI训练与推理中的数据存储和处理》主题演讲,他表示:“智能算力的软件生态是当前决定我国人工智能发展的关键因素,优秀的系统软件能够充分释放底层硬件算力的潜力。PolarDB作为云原生数据库的中坚力量,拥有先进的技术架构,通过融合Data+AI,为大规模、实时的数据处理提供了高效支持,代表了国产基础软件在核心技术领域的强劲实力。”
![]()
Gartner高级研究总监、全球云数据库魔力象限主笔人顾星宇
“聚焦于公有云的研发与生态建设战场,趋向融合统一的数据库功能,以及具备应对AI企业级应用的数据管理能力,这三大趋势已经成为了全球数据库巨头差异化竞争的主战场。”Gartner高级研究总监、全球云数据库魔力象限主笔人顾星宇在会上指出。
针对AI需求的爆发式增长,阿里云在会上重磅发布内置大模型的PolarDB AI新版本,该版本提供3大Data+AI特性:植入通义千问和DeepSeek全系产品,同时支持用户自定义模型,帮助个人和企业开发者快速部署并上线AI应用;PolarDB AI节点采用模型算子化(Model as an Operator)形态,支持客户直接在数据库内部(In-DB)进行搜索推理优化,推动用户进入数智时代;通过基于KV Cache等技术优化,在相同GPU条件下,PolarDB在线推理吞吐量可提升10倍以上,同时帮助客户降低部署成本。
依托自研、成熟的云原生架构,阿里云PolarDB在业界已开创性地落地了“三层解耦”架构、多主多写等一系列前沿技术,帮助客户以50%成本、实现6倍于商业和开源数据库的性能。日前,PolarDB还刷新了数据库界的“奥林匹克”记录,可从容应对全球最大规模的业务场景。
![]()
据国际数据库事务处理性能委员会(TPC)官网披露,PolarDB以每分钟20.55亿笔交易(tpmC)和0.8元人民币/tpmC的成绩,登顶TPC-C基准测试的性能和性价比排行榜,成本相比原纪录降低近40%,刷新了双榜世界纪录。李飞飞强调,该记录是中国基础软件取得的又一里程碑式成就,标志着PolarDB创新的云原生架构、软硬件结合的方式,成功抗住了全球最大规模的并发交易峰值,在性能、可扩展性等多个维度均处于全球领跑者行列。
![]()
英特尔资深首席工程师程从超
“英特尔借助更多的内核、更灵活的微架构、更大的内存带宽以及更出色的输入/输出 (I/O) 性能,英特尔®至强®处理器为各种工作负载提供了卓越的性能表现。此外,英特尔®至强®处理器的HW-PGO(硬件性能指导优化)技术,通过分析和优化数据库的执行热点,进一步提升了数据库系统的整体效率,从而提高了数据库处理复杂查询和高并发操作时的响应速度。”英特尔资深首席工程师程从超在演讲中介绍,凭借这些先进技术,英特尔®至强®处理器助力PolarDB在TPC-C基准测试中展现出卓越的性能。
![]()
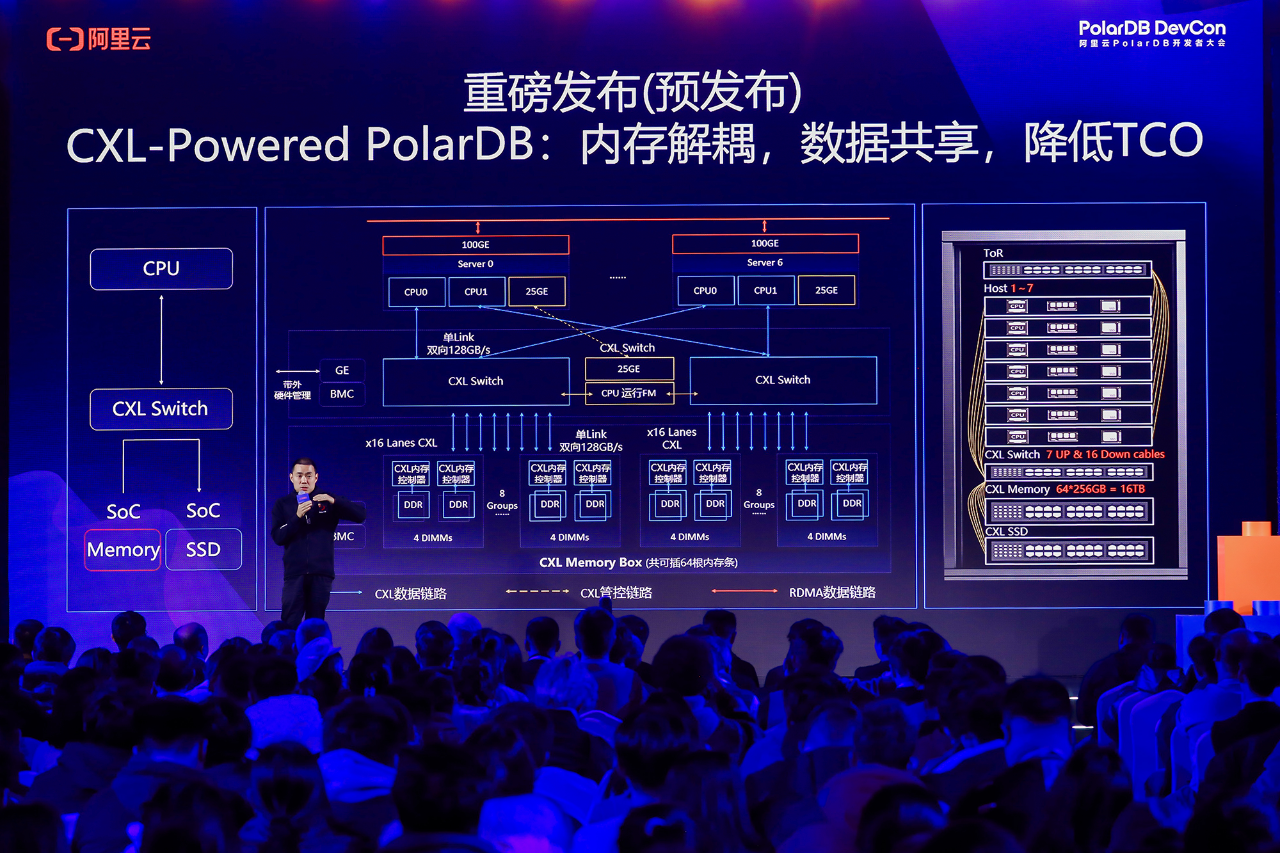
云原生数据库对于降低跨机延迟、提升通信效率有着无止境的追求。阿里云在会上发布重磅“剧透”,PolarDB秉承软硬件协同设计理念,即将于2025年下半年发布全球首款基于CXL(Compute Express Link)交换机的数据库专用服务器。利用CXL高速互联技术,进一步提升三层分离架构下计算与内存之间的通信带宽与效率。与传统的RDMA高速网络相比,CXL技术将内存交互的性能提升了一个数量级,跨机交互延迟缩短至百纳秒级别。在相同配置下,PolarDB的扩展性提升了三倍,成本降低了50%。
2、与用户同行,共赴AI就绪的新未来
目前,阿里云PolarDB用户数已突破10000家,深受市场青睐。产品的高速发展,离不开广大用户和开发者的支持。
![]()
绝区零资深服务器专家车振磊
在游戏行业,PolarDB支持米哈游新游《绝区零》全球开服,见证其全球下载量突破5000万,登顶138个国家和地区下载榜首。绝区零资深服务器专家车振磊在演讲中介绍:“绝区零游戏项目使用PolarDB作为主要数据库,PolarDB的高性能和高可用为游戏线上运营提供了稳健的数据库服务,降低了数据库成本。PolarDB完善的备份恢复和GDN能力,降低了运维复杂度,提高了日常维护和更新的效率。随着游戏行业的快速发展,我们还将与PolarDB一起探索游戏业务场景更多的可能性。”
![]()
雅迪科技集团软件研发负责人吴晨
“雅迪的云销通App集成了基于PolarDB for AI的检索增强生成(RAG)技术,为雅迪经销商老板提供了一键式的自由问答功能,支持生成适用于多种场景的标准化策划和文案。PolarDB for AI的NL2SQL能力,10万+门店导购销售人员能够以口语化提问实时获取批发、销售、库存等全域数据的多模态分析结果(表格/图表/文字),查询准确率超90%。”雅迪科技集团软件研发负责人吴晨在会上分享,PolarDB不仅优化了运营决策流程,更在销售策略制定、活动策划等场景提供智能辅助,加速订单转化,开辟“数据驱动增长”的新范式,显著提升市场竞争力和销售业绩。
PolarDB分布式版数据库,与云基础设施进一步融合,提供自动与手工调优结合的数据分布方式。其集中于分布式一体化的产品形态,事务与分析负载统一处理引擎,为多种规模负载提供最佳适配的解决方案。在原有多层次高可用的基础上,PolarDB分布式版研发了无感切换技术,在高负载场景下进行系统切换,过程中事务处理请求0失败,大幅降低了应用的容错成本。
![]()
飞鹤业务中台项目总监余亚锋
飞鹤集团近日宣布完成业务中台数据库架构全面升级,采用阿里云PolarDB分布式版替代原有分库分表方案,有效解决了性能不佳、容灾能力有限及扩展性不足等痛点,实现全面技术升级。升级后,单位时间业务处理量提升200%,慢SQL减少90%,运营成本降低40%。飞鹤业务中台项目总监余亚锋表示:“对采用新架构支撑集团实现千亿级发展目标信心十足。”飞鹤正通过"3+3+2"战略布局赋能各业务领域,未来还将推进异地多活、多租户隔离等优化,进一步提升系统稳定性和灵活性。此举标志着飞鹤在数字化转型中取得重要进展,为其长远发展奠定坚实技术基础。
作为中国首款自研云原生数据库,阿里云PolarDB已规模化应用于政务、金融、电信、物流、互联网等领域的核心业务系统,服务了自然人税收管理系统、全国60%的省级医保信息平台等机构,以及中国联通、中国石化、友邦保险、米哈游、飞鹤等知名企业,助力业务加速创新升级,抢占市场先机。