EasyAi 颇为高调。在其 Gitee 主页介绍一栏,写着“国内人气最高的 Java人工智能算法框架”,是“Java 版的 PyTorch”。
Java 在企业级开发中一直占据统治地位,但是在 Ai 领域却一直薄弱。在很多 Java 项目中,许多 AI 功能依赖调用 Python 库来实现。有了 Java 原生 的 EasyAi 之后,只需用 Maven 工具就能将它一键引入到 Java 项目,无需任何额外的环境配置与依赖,做到了开箱即用,很适合用来开发适合自家业务的小微模型。
![]()
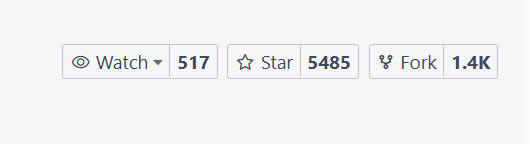
在Gitee 上超过 5K 个 Star
此外,EasyAi 包含了一些已经封装好的图像目标检测及人工智能客服的模块,同时提供各种深度学习、机器学习、强化学习、启发式学习、矩阵运算、求导函数、求偏导函数等底层算法工具。
EasyAi 的作者李大鹏,网名“唯一解”,他的经历也颇为传奇:大专毕业后写小说,曾经短暂地做过平面设计,后来自学转码农。先是搞前端开发,接着又从 Java 业务开发到游戏开发,最后做算法研发。到现在已经有十二年码龄了。这期间,李大鹏还做过销售,写过小说,当过牛马,也创过业。
![]()
李大鹏说,想走一条不一样的路——专注底层算法,尽管他自称是“公司常年最低学历保持者”。
“当我第一次看到社区的小伙伴用 Easyai——而不是靠调用,靠自身的技术能力开发出一套人脸检测模块在公司线上服务器运行时,当我第一次看到有小伙伴使用 Easyai 开发出一套智能客服以极低的成本完成公司知识体构建时,我知道,我初步的设想逻辑成功了。”
事实上,李大鹏对于 EasyAi 的定位很明确,也知道它与 PyTorch 二者之间的差距。“ 在人工智能主流领域,EasyAi 目前不可能是 PyTorch 的对手,但它有独特优势:支持 JDK 1.6 及以上版本,采用原生 Java 构建,通过一次 Maven 引入,可以无缝集成到任何由 Java 构建的企业级服务中。凭借非常低廉的使用成本,在中小企业内的ai模块开发中撬开了一席之地。”
EasyAi 并不是对主流算法 Java 的无差别重新实现,而是根据应用场景对主流算法进行优化与魔改,保证普通服务器或个人电脑 CPU 下依然达到可用性能的流畅运行。 “easy”并不是只是指的简单,而是对算法进行了廉价,低成本方向的优化。"如果我没有办法对某种算法做到廉价,我也不会放入 EasyAI 里面。"
对于 EasyAi 的未来,李大鹏的愿望很朴素:将 AI 模型开发技术作为 Java 程序员未来全栈能力之一,让 AI 开发就跟普通业务开发一样,给 Java 程序员带来新的饭碗。
2 月 21 日,开源中国将邀请 EasyAi 作者李大鹏, 做客 “OSC 开源社区” 视频号直播栏目【开源项目老牌与新秀】第 6 期,聊一聊 EasyAi,看看这个敢自称“ Java 版的 PyTorch”“ 国内人气最高的 Java人工智能算法框架”,到底有几斤几两!
直播亮点:
预约直播
![]()
另外,我们还建了一个交流群,一起聊聊自己喜欢的开源项目~~当然啦,如果你有什么特别棒的开源项目,可以推荐过来呀~
![]()
另外,本次直播得到了诸多社区或组织的大力支持,在此特别表示感谢:
Gitee
Gitee(码云)是开源中国于 2013 年推出的基于 Git 的代码托管平台、企业级研发效能平台,提供中国本土化的代码托管服务。
目前,Gitee 已经有超过 1350 万名开发者,累计托管超过 3600 万个代码仓库,是中国境内规模最大的代码托管平台。同时,旗下企业级 DevOps 研发效能管理平台 Gitee 企业版已服务超过 36 万家企业。
网址:https://gitee.com/
Dromara 社区
Dromara 社区是一个自组织的开源社区,由顶级开源项目维护者创立。社区目前拥有 10 多个顶级开源项目和 30 多个优秀开源项目,涵盖热门工具、分布式事务日志、企业级鉴权、运维监控、调度编排等。这些开源项目服务于数百万个人和中小企业。
官网:https://dromara.org/
“开源项目老牌与新秀” 是开源中国 OSCHINA 推出的一档直播栏目,旨在为开源项目提供一个展示平台,每周五晚上开播。栏目邀请开源项目的作者、核心团队成员或资深用户作为嘉宾,通过路演式直播分享项目的亮点和经验,有助于提高项目的知名度,吸引更多的用户和开发者关注。
如果你手上也有好的开源项目,想要跟同行交流分享,欢迎联系我,栏目随时开放~
![]()