最近,开源中国 OSCHINA、Gitee 与 Gitee AI 联合发布了《2024 中国开源开发者报告》。报告聚焦 AI 大模型领域,对过去一年的技术演进动态、技术趋势、以及开源开发者生态数据进行多方位的总结和梳理。查看完整报告:2024 中国开源开发者报告.pdf
在第二章《TOP 101-2024 大模型观点》中,趋境科技探讨了大模型基础设施建设的未来趋势以及如何落地。全文如下。
推理中心化:构建未来AI基础设施的关键
文/趋境科技
相比于2023年的参数量快速扩张,2024年以来,大模型迭代动力更多源于大模型应用落地、端侧部署的需求,大模型正往更加广泛的行业应用发展。然而,大模型的成功落地并非易事,尤其是在为大模型提供算力的稳固底座——基础设施的建设环节中,推理的算力需求日益增加,将成为制约大模型广泛应用的关键因素。本文将探讨大模型基础设施建设的未来趋势,以及大模型在落地层面,要如何做基础设施建设。
推理算力的爆发式增长,将会转移基础设施建设的重心
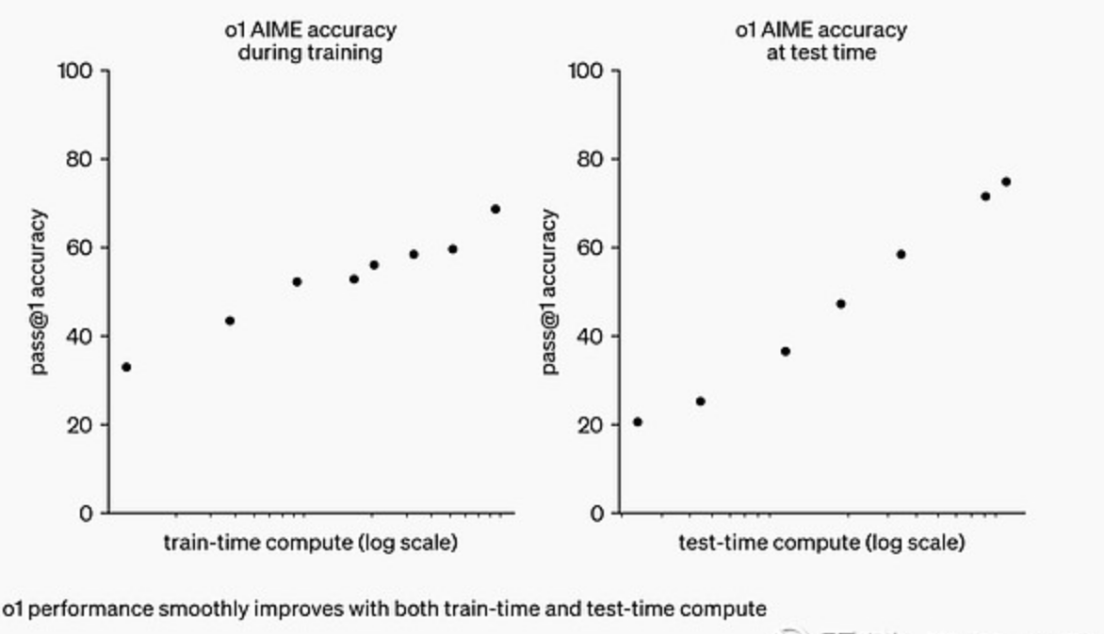
OpenAI的o1模型以其思维链式思考(Chain of Thought)模式,为大模型的推理带来了新的方向。这种模式通过模拟人类解决问题的思维方式,显著提升了模型的推理能力,使大模型在解决复杂的推理任务上表现出了超越以往的卓越性能,其效率也远超其他模型。
![]()
但这意味着,类o1大模型在推理阶段需要更多的计算资源,思维链的推理模式相当于从原来的单次推理变成了多次推理,推理端对算力的需求大幅增加。原有大模型的推理模式更多是一般推断,即大模型只进行单次的简单推理,加入链式思考之后,不仅是思考次数成倍数增加,每次思考还会将上一次的思考结果作为Prompt再次输入,对推理的算力需求将是原来的数十倍。
除了对推理算力的爆发式增长,推理还将成为高质量的数据来源。英伟达高级科学家Jim Fan表示,大量计算将被转移到服务推理而不是训练前/后,o1将成为数据飞轮,反过来将进一步优化GPT未来版本的推理核心。
这样的发展趋势预示着大模型的基础设施建设将向推理转移。传统的AI算力设施主要围绕模型训练构建,但在新的范式下,要求我们重新思考和设计AI基础设施去适应这一变化。未来的AI基础设施将更加注重推理能力,以支持大模型的广泛应用。
算力需求的增加导致的挑战
在大模型落地行业中,效果、效率与成本之间存在着难以调和的“不可能三角”。企业往往希望获得更好的模型效果,即生成内容的准确性高、无幻觉问题且对用户有实际帮助;同时也追求更高的处理效率,以便快速响应市场需求和用户反馈;然而,还需要控制成本。
举个例子来说,参数越大的模型有越高的推理性能,但成本也极高,部署千亿大模型动辄需要成数百万元至数千万元,此外还需较高的人员成本来做模型维护和应用开发。
效率、成本、效果这三个点本就难以调和,随着推理思维链带来的新范式,虽然模型效果有了更大的提升,但同时对算力的需求爆发,导致成本数十倍增加,使得这一平衡更加难以实现。在保证同样的性能条件下,如何平衡成本,成为了大模型落地的关键问题。
如何降低大模型的推理成本
平衡效果、效率与成本三者间,本质是在于如何在有限的成本里做到最优的性能。加之大模型的算力建设重点转移到推理侧,因此,如何优化推理算力成为大模型落地的关键点。
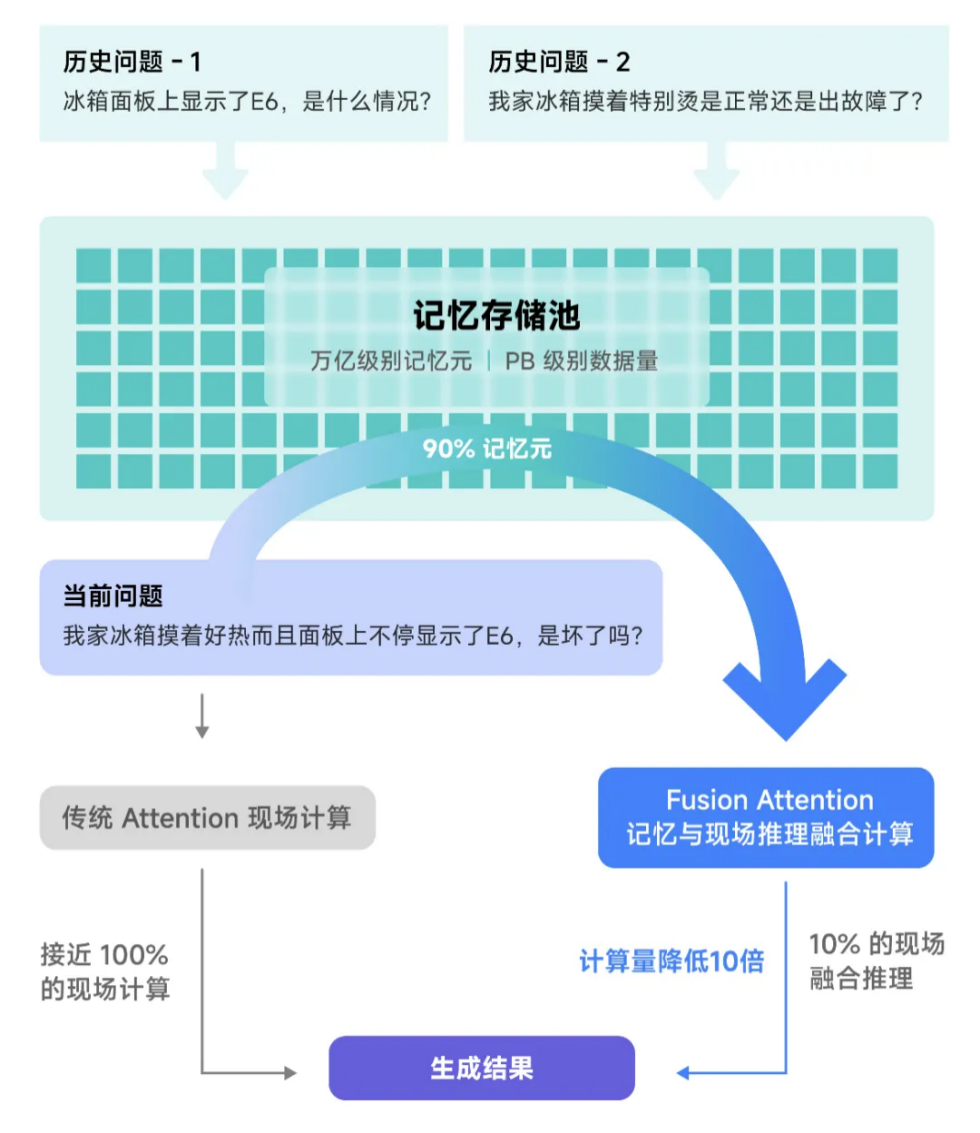
以存换算:在大模型的推理任务中,尤其在实际的应用中,大量的推理任务间往往会有关联,因此如果将计算的中间结果存储,遇到相似的问题,甚至是全新的问题,也能让大模型从历史记忆中提取相应的计算结果,结合部分现场计算,融合推理得出结论,那么推理任务的计算量将会大大降低。
这一思路的本质是调用存储空间,存储复用KVCache,来置换部分的算力。存储设备的成本相对算力而言要低得多,从而进一步降低成本。
![]()
全系统异构协同推理:大模型算力最主要是来源于GPU,当前传统的算力优化方案主要是提升GPU的利用率。然而,仅针对GPU优化所带来的性能提升空间非常有限。此外,据财通证券发布的行业深度分析报告统计显示,国产GPU产品在单精度/半精度浮点算力、制程及显存容量上都与英伟达有2-4倍的显著差距。因此,单单依靠GPU单点优化,短时间内很难赶超英伟达GPU方案。
而且对于推理而言,算力要求相较于训练较低,因为推理仅涉及前向计算,无需复杂的反复试错和参数调整。
底层的硬件,除GPU之外,还有存储、CPU、NPU等。从这些角度考虑,降低GPU算力的占比,释放设备中其他硬件的隐藏算力的方法成为最优解。
通过以存换算利用存储的算力,加入高性能算子充分调用CPU和GPU算力,增加算力利用率,再加上更科学的算力调度和分配系统,充分并高效释放了全设备的算力,这就是全系统异构协同推理架构。
这种架构不仅提高了整体算力利用率,还突破了GPU单点优化的瓶颈,能够为大模型的推理提供强大的支持。
推理新架构的开源项目实践
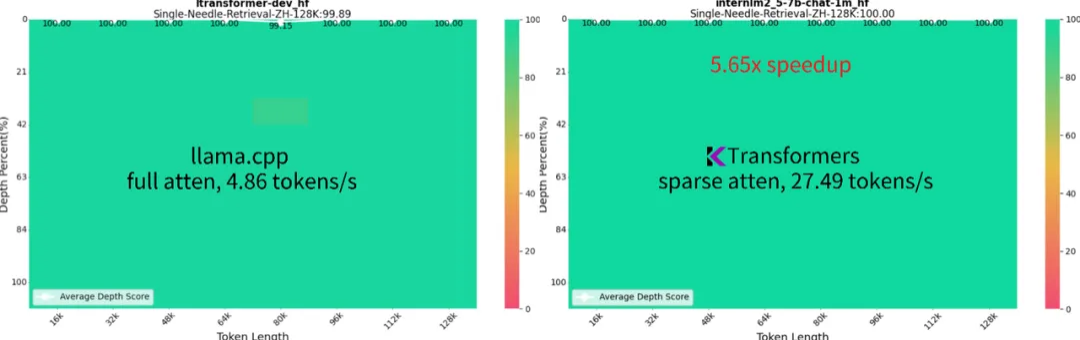
趋境科技与清华KVCache.AI团队共同开源的项目KTransformers,便是采用了异构协同的推理新框架:仅需单个4090即可在本地运行Mixtral 8x22B和DeepSeek-Coder-V2等千亿级大模型,性能远超Llama.cpp数倍。
![]()
同时,KTransformers成为业界首个仅需单张4090即可完成长达1M的超长上下文推理任务的高性能推理框架,且生成速度达到16.91 token/s,比Llama.cpp快10倍以上,同时维持接近满分的“大海捞针”能力。更进一步的,KTransformers可以兼容各种模型和算子,在Transformers之上,兼顾了兼容性、灵活性、易用性和性能。在框架中可以集成各种各样的算子,不管是放到CPU还是GPU,都能够做各种组合测试。
KTransformers在发布后仍在不停地迭代更新,根据开发者们的需求提供了对Windows、Linux平台的支持、实现了对主流开源MoE大模型的支持等,非常方便开发者根据本地环境进行调整。未来还将根据开发者的不同诉求持续完善。
此外,趋境科技深度参与的开源项目Mooncake,以超大规模KVCache缓存池为中心,通过以存换算的创新理念大幅度减少算力开销,显著提升了推理吞吐量。其中Mooncake Store组件可以充分利用推理集群中的CPU、DRAM和SSD资源形成一个高效的多级KVCache缓存池。通过共享KVCache,大幅度减少对于GPU资源的消耗。
大模型的未来与算力基础设施的转型
AI大模型是未来的趋势,随着大模型更加广泛地落地到各种应用中,对大模型的性能要求会越来越高,推理任务也变得越来越复杂。因此在上层能力与应用高速发展的状态下,底层对算力的基础设施建设,尤其以推理为中心的基础设施建设变得尤为关键。
以存换算和全系统异构协同推理是当前应对大模型落地挑战的创新解法,能够在大模型的部署阶段有效平衡效果、效率和成本三者间的关系,将成为推理基础设施建设的一种新方式,助力大模型更广泛的应用。
正如中国工程院院士郑纬民在数据存储专业委员会中所提到的:内存型长记忆存储以存换算,是AI推理新趋势。AI存储是人工智能大模型的关键基座,存储系统存在于大模型生命周期的每一环,是大模型的关键基座,通过以存强算、以存换算,先进的AI存储能够提升训练集群可用度,降低推理成本,提升用户体验。
公司简介:
![]()
趋境科技成立于 2023 年底,基于业界首创的以存换算和全系统异构协同推理架构推出“大模型知识推理一体机”,为用户提供开箱即用的大模型落地解决方案。公司创始团队均来自清华大学,在 AI、体系结构、系统软件等相关的技术系统和软件领域,有多年学术与产业实践经验。
《2024 中国开源开发者报告》由开源中国 OSCHINA、Gitee 与 Gitee AI 联合出品,聚焦 AI 大模型领域,对过去一年的技术演进动态、技术趋势、以及开源开发者生态数据进行多方位的总结和梳理。
报告整体分为三章:
- 中国开源开发者生态数据
- TOP 101-2024 大模型观点
- 国产 GenAI 生态高亮瞬间
查看完整报告,请点击 :2024 中国开源开发者报告.pd