DeepSeek 模型近期在全网引发了广泛关注,热度持续攀升。其开源模型 DeepSeek-V3 和 DeepSeek-R1 在多个基准测试中表现优异,在数学、代码和自然语言推理任务上,性能与 OpenAI 的顶尖模型相当。对于期待第一时间在本地进行使用的用户来说,尽管 DeepSeek提供了从1.5B到70B参数的多尺寸蒸馏模型,但本地部署仍需要一定的技术门槛。对于资源有限的用户进一步使用仍有难点。
为了让更多开发者第一时间体验 DeepSeek 模型的魅力,Modelscope 社区 DeepSeek-R1-Distill-Qwen模型现已支持一键部署(SwingDeploy)上函数计算 FC 服务,欢迎开发者立即体验。
魔搭+函数计算,一键部署模型上云
SwingDeploy 是魔搭社区推出的模型一键部署服务,支持将魔搭上的各种(包括语音,视频,NLP等不同领域)模型直接部署到用户指定的云资源上,比如函数计算FC(以下简称FC)GPU算力实例。本文介绍如何通过魔搭SwingDeploy服务,快速将DeepSeek模型部署到阿里云函数计算FC平台的闲置GPU实例,并对部署后的模型进行推理访问。
函数计算平台提供了低成本的闲置 GPU 实例,使用闲置GPU实例,将带来如下优势:
● 实例快速唤醒:函数计算平台会根据您的实时负载水平,自动将GPU实例进行冻结。冻结的实例接受请求前,平台会自动将其唤醒。要注意,唤醒过程会存在2-5秒的延迟。
● 兼顾服务质量与服务成本:闲置GPU实例的计费周期不同于按量GPU实例,闲置GPU实例会在实例闲置与活跃期间以不同的单价进行计费,从而大幅降低用户使用GPU成本。相较于长期自建GPU集群,闲置GPU实例根据GPU繁忙程度提供降本幅度高达80%以上。
魔搭社区一键部署介绍:https://modelscope.cn/docs/model-service/deployment/intro
函数计算闲置GPU介绍:https://help.aliyun.com/zh/functioncompute/fc-3-0/user-guide/real-time-inference-scenarios-1
DeepSeek模型介绍
性能对齐OpenAI-o1正式版
DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。 ![]() 在此,DeepSeek将 DeepSeek-R1 训练技术全部公开,以期促进技术社区的充分交流与创新协作。
在此,DeepSeek将 DeepSeek-R1 训练技术全部公开,以期促进技术社区的充分交流与创新协作。
论文链接:
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
模型链接:
https://modelscope.cn/collections/DeepSeek-R1-c8e86ac66ed943
蒸馏小模型超越 OpenAI o1-mini
DeepSeek在开源 DeepSeek-R1-Zero 和 DeepSeek-R1 两个 660B 模型的同时,通过 DeepSeek-R1 的输出,蒸馏了 6 个小模型开源给社区,其中 7B 和 14B 模型在多项能力上实现了对标 OpenAI o1-mini 效果、展现了较高的生产环境部署性价比。
![]()
部署步骤
函数计算提供有Ada系列48GB显存的GPU,供DeepSeek-R1-Distill-Qwen如下参数版本的模型运行。
| DeepSeek-R1-Distill-Qwen的不同参数模型 | 模型链接 | | :--- | :--- | | 1.5B | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B | | 7B | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | | 14B | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B | | 32B | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B |
本文将继续以DeepSeek-R1-Distill-Qwen-7B展现部署步骤,相同的部署步骤可应用于1.5B、14B、32B参数量模型的部署。
前置条件:
● 账号绑定与授权:https://modelscope.cn/docs/model-service/deployment/swingdeploy-pipeline
部署步骤:
● 进入DeepSeek-R1-Distill-Qwen-7B模型页:https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
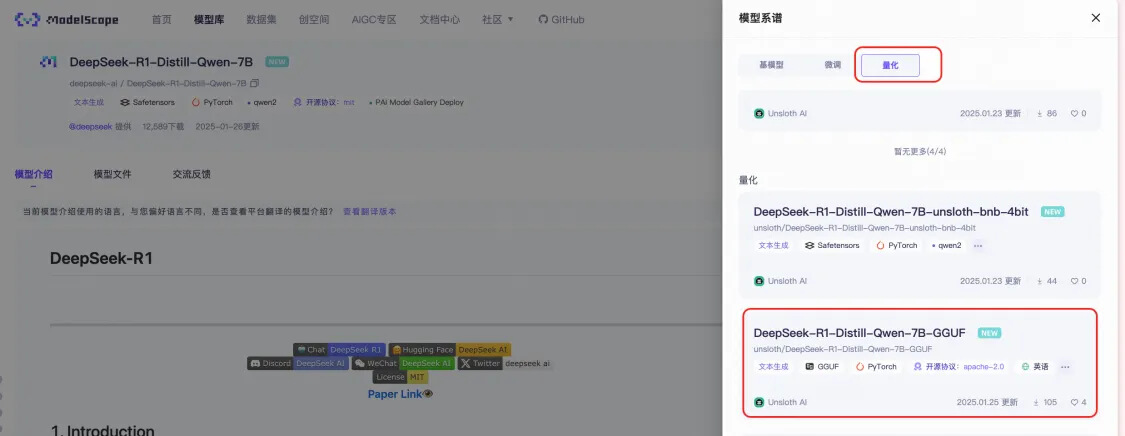
● 请选择GGUF格式的量化版本: ![]()
![]()
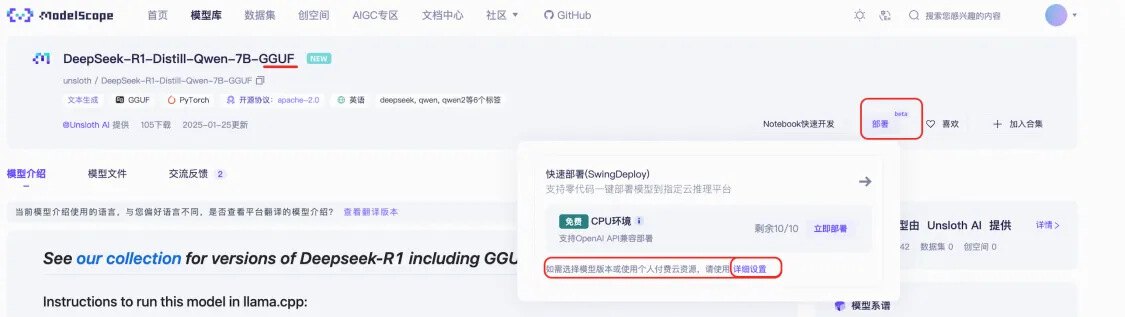
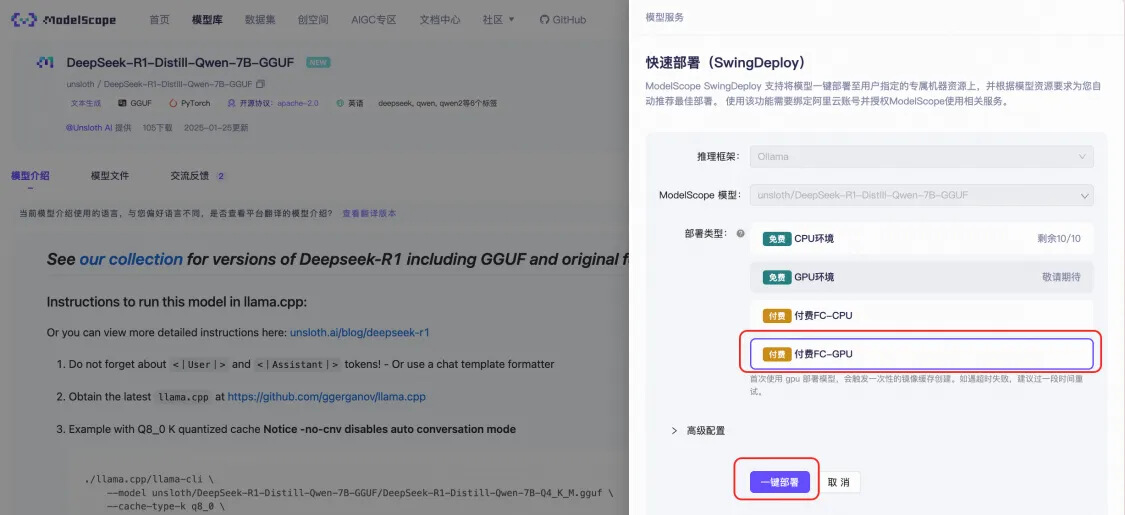
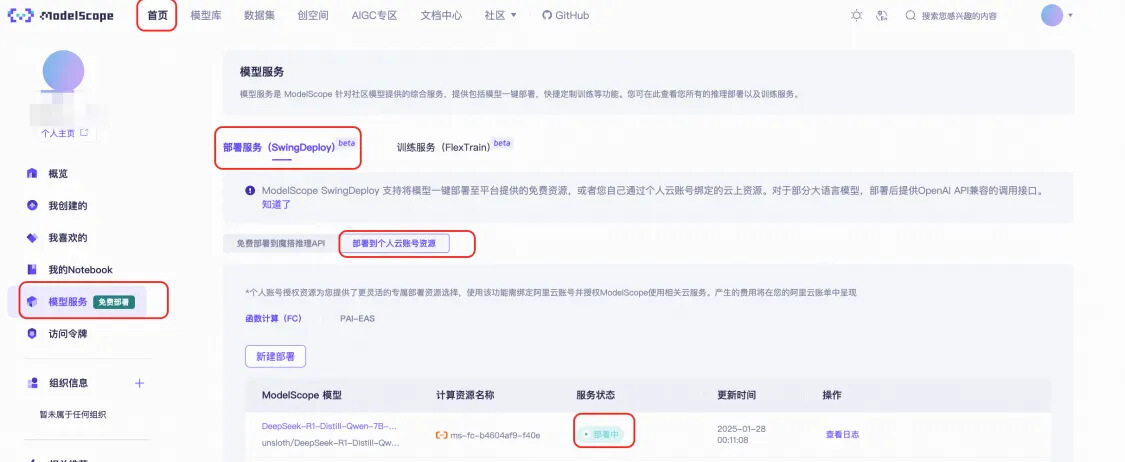
● 进入DeepSeek-R1-Distill-7B-GGUF模型页后,点击部署,部署类型选择付费的FC GPU算力。 ![]()
![]()
![]()
■ 部署地域:可选择杭州或上海。
■ GPU卡型:默认将DeepSeek模型部署至Ada系列48GB显存GPU,并开启闲置GPU模式,以降低您的运行成本。
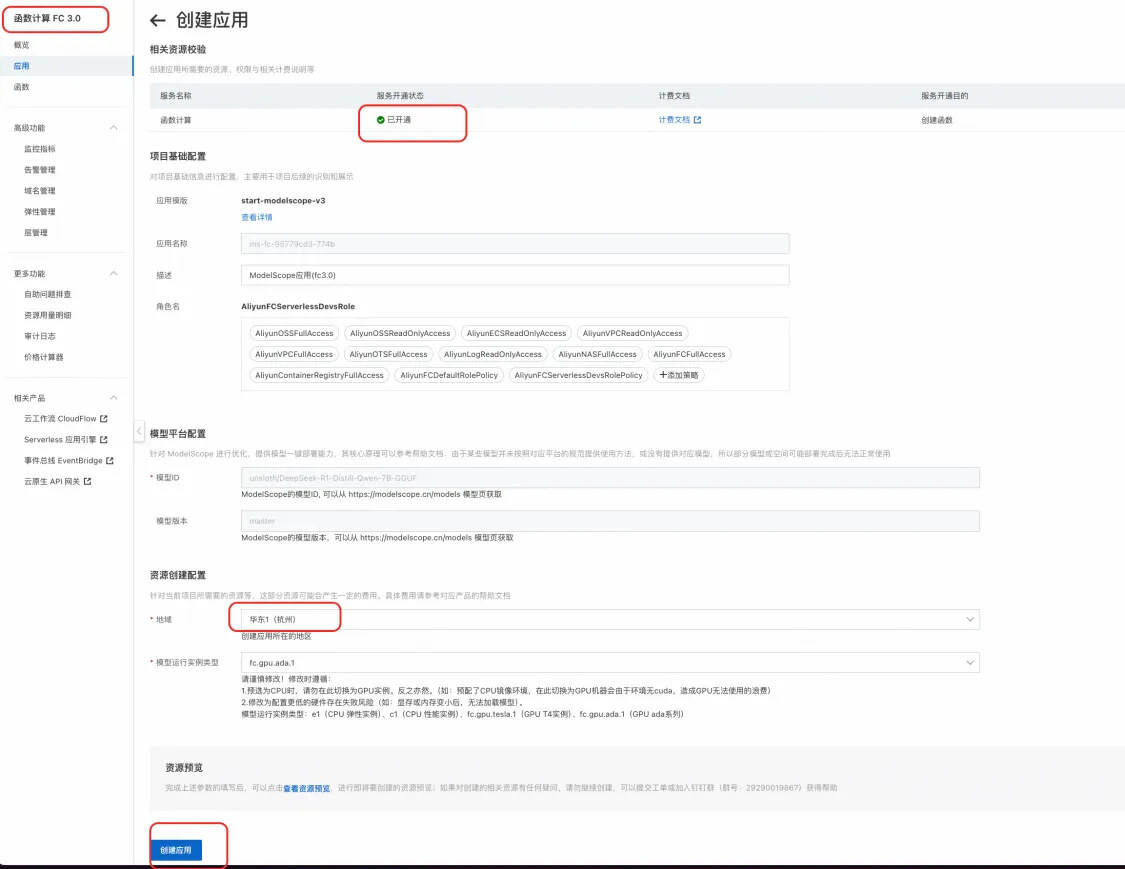
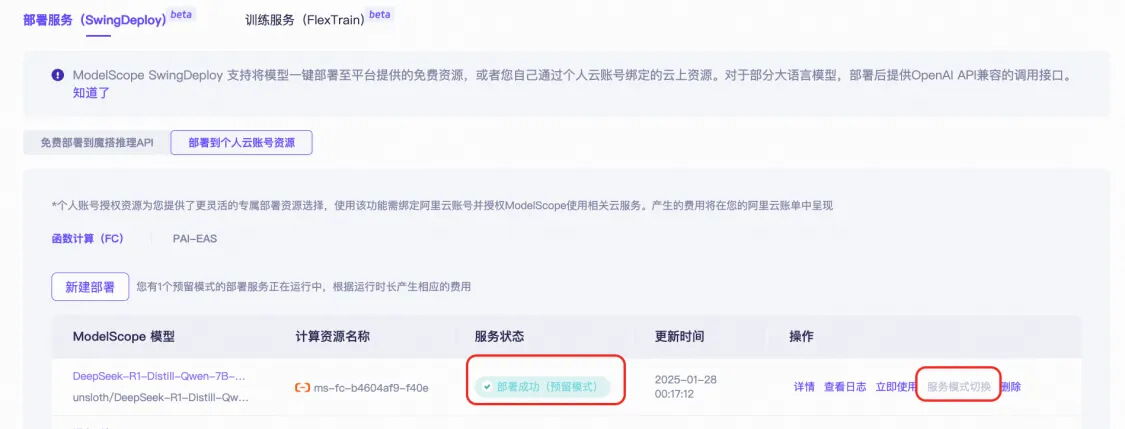
● 查看部署过程,确认部署成功。 ![]()
![]()
■ 确认状态为部署成功(预留模式),如果不是,请点击服务模式切换。
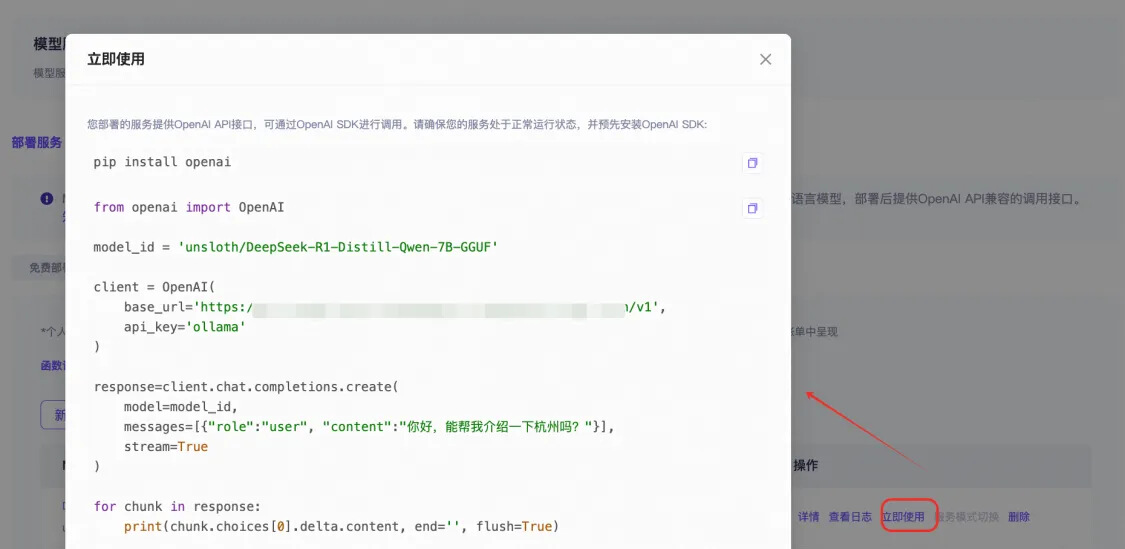
● 模型调用:
○ 查看调用代码示例:
![]()
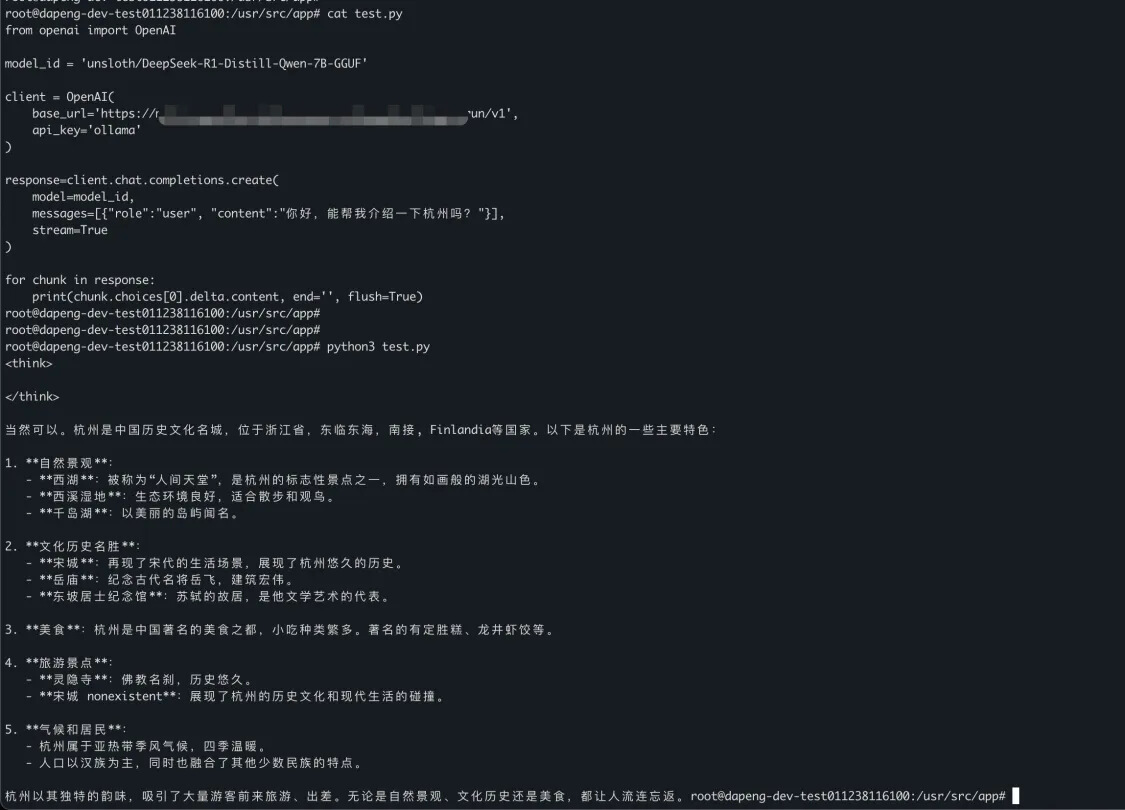
○ 调用模型,进行推理:
![]()
■ 首次调用由于模型加载导致耗时长,后续均为热调用无此问题。
更进一步了解函数计算GPU
● FC GPU实例介绍规格和使用模式介绍:https://help.aliyun.com/zh/functioncompute/fc-3-0/product-overview/instance-types-and-usage-modes
● FC GPU实时推理场景(闲置GPU模式)介绍:https://help.aliyun.com/zh/functioncompute/fc-3-0/use-cases/real-time-inference-scenarios-1
● FC GPU准实时推理场景(按量GPU模式)介绍:https://help.aliyun.com/zh/functioncompute/fc-3-0/use-cases/quasi-real-time-inference-scenarios
● FC GPU异步推理场景介绍:https://help.aliyun.com/zh/functioncompute/fc-3-0/use-cases/offline-asynchronous-task-scenario
● FC GPU镜像说明:https://help.aliyun.com/zh/functioncompute/fc-3-0/use-cases/image-usage-notes-1
● FC GPU模型存储最佳实践:https://help.aliyun.com/zh/functioncompute/fc-3-0/user-guide/gpu-instance-model-storage-best-practices
● FC GPU FAQ(模型托管、模型预热):https://help.aliyun.com/zh/functioncompute/fc-3-0/support/faq-about-gpu-accelerated-instances-1
● FC GPU 应用模板与示例代码:https://github.com/devsapp/start-fc-gpu/tree/v3 更多内容关注 Serverless 微信公众号(ID:serverlessdevs),汇集 Serverless 技术最全内容,定期举办 Serverless 活动、直播,用户最佳实践。
 在此,DeepSeek将 DeepSeek-R1 训练技术全部公开,以期促进技术社区的充分交流与创新协作。
在此,DeepSeek将 DeepSeek-R1 训练技术全部公开,以期促进技术社区的充分交流与创新协作。