
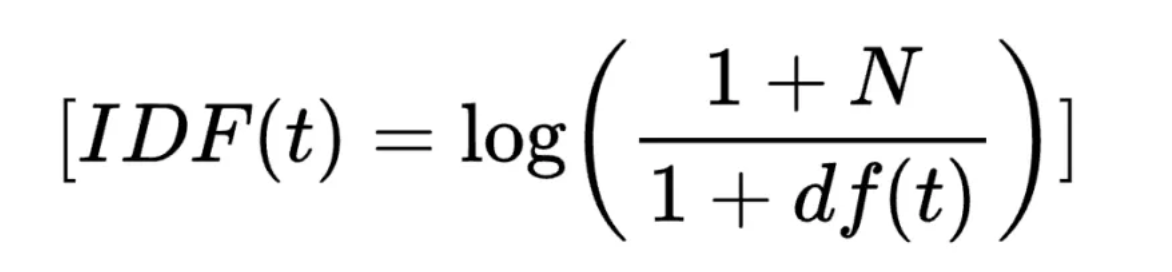
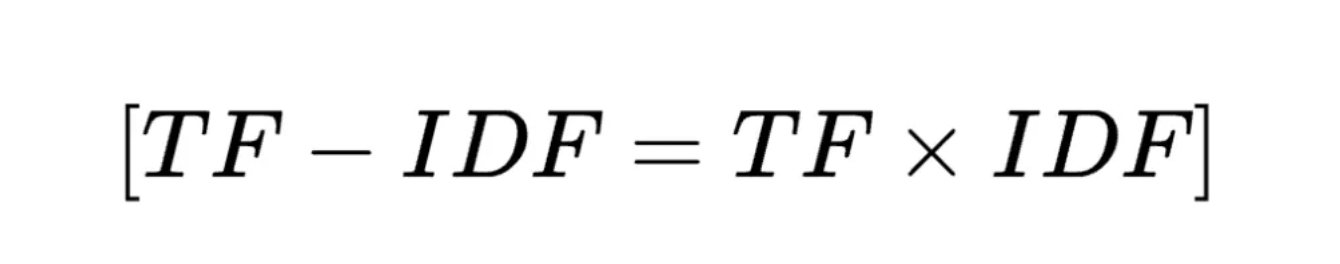

英伟达与美国半导体协会反对新一轮芯片出口禁令
受美国拜登政府计划对人工智能芯片出口实施新限制措施消息的影响,1月10日美股开盘后,英伟达股价大跌超3%,AMD股价大跌近6%,博通股价下跌超2%。 此前有消息称,拜登政府预计最早于1月10日发布一项新的芯片出口禁令,将制定三层芯片限制:美国的少数盟友仍将拥有美国半导体的全部使用权,但大多数国家将面临新的芯片出口限制,并将对另一些国家完全禁止出口数据中心芯片。 英伟达发给第一财经记者的回应中,英伟达政府事务副总裁内德·芬克尔(Ned Finkle)表示,全球用户日常使用的游戏PC已经普遍搭载数据中心计算机和技术,试图对其实施控制是没有意义的。 芬克尔补充道,对国家实施限制的极端政策将对世界各国的主流计算机造成不良影响,会推动世界转向其他替代技术。 “人工智能无疑已经是主流的计算科技,像电力一样必不可少。”他表示,“此时出台这一项政策将会遭到美国工业界和国际社会的批评。我们希望拜登总统不要在此时制定一项只会损害美国经济的政策。” 除了英伟达反对之外,代表亚马逊、微软和Meta等科技巨头公司的信息技术产业委员会(ITIC)表示,拜登政府计划出台的新规将对美国公司向海外销售计算系统任意施加限...