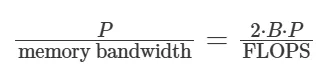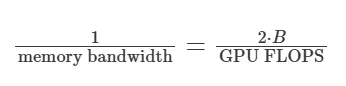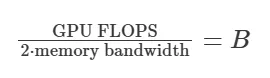编者按:你是否曾在优化深度学习模型时感到困惑,明明增加了 batch size,GPU 利用率却没有如预期提升?在实际项目中,这个问题可能导致资源浪费、训练效率低下,甚至影响整个 AI 产品的交付周期。
本文作者深入剖析了现代 GPU 批处理的工作原理,揭示了内存带宽与计算能力之间的微妙关系。通过建立理论模型并结合实际实验,作者不仅解释了为什么某些 batch size 会突然导致性能下降,还提供了如何找到最佳 batch size 的方法。
作者 | Finbarr Timbers
编译 | 岳扬
一般来说,对于现代深度学习系统而言,你能做的第一个也是最重要的优化措施就是实现批处理(batching)。在进行推理时,不是单独处理单个输入,而是同时处理包含 N 个输入的一批数据。大多数情况下,这个操作是无需额外成本的 ------ 无论是处理单个输入还是 N 个输入,推理所需的时间几乎相同。这又是为何呢?表面上看,批量处理数据似乎应该消耗更多资源,毕竟,工作量增加了 N 倍。
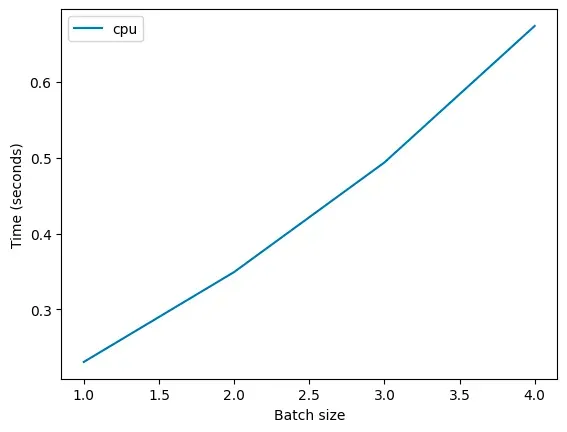
然而,如果我们使用一个简单或者不成熟的模型来理解神经网络的工作方式,那么批处理(batching)的计算并不是没有成本的。实际上,批处理确实需要 N 倍的计算能力。如果你在 CPU 上运行某个特定的计算任务,你会发现前文提到的这一点是成立的。
![]()
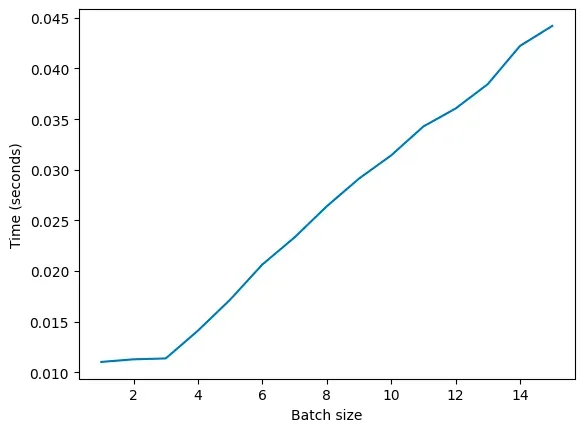
然而,在现代 GPU 上运行相同的计算任务时,情况却并非如此。以下是我们在一款 T4 GPU 上观察到的情况:
![]()
从图中可以看到,batch size 从 1 到 3 时,所消耗的时间并不会增加。但是,一旦 batch size 超过 3,时间消耗就会呈线性增长。
这是什么原因呢?关键在于并发处理能力。现代 GPU 能够同时执行多次运算(尽管在单线程处理时,它们其实比 CPU 要慢)。
通常,当我们谈论"用模型对单个数据样本进行推理"时,容易把模型看作一个整体块(single block)。但实际上,模型是由众多矩阵组成的。推理过程中,每个矩阵都会被加载到内存中。具体来说,矩阵的每个块都会被加载到设备的共享内存单元(在 A100 显卡上仅有 192 kb)。这个块随后用于计算 batch 中每个元素的结果。需要注意的是,这与 GPU RAM(即 HBM)不同。A100 显卡根据型号不同,配备了 40 GB 或 80 GB 的 HBM,但设备内存仅有 192 kb。这导致在执行数学运算时,内存带宽成为了性能瓶颈,因为数据需要不断地在设备内存中读写。我们可以通过模型大小除以内存带宽来估算传输权重所需的时间,通过模型的浮点运算次数(FLOPS)除以 GPU 的 FLOPS 来估算计算所需的时间。
使用多层感知机(MLP),浮点运算次数(FLOPS)大约是参数数量的两倍乘以 batch 中元素的数量[1](即为 2 * m * n * b,数据批次大小(batch size)为 b ,矩阵为 m x n )。因此,当传输时间等于计算时间时,意味着:
![]()
在此,我们可以观察到左右两边的参数数量是可以相互抵消的:
![]()
同时,我们可以根据 batch size 来重新排列:
![]()
当 batch size 小于 FLOPS 与内存带宽的比值时,内存带宽将成为性能瓶颈。而一旦 batch size 超过了这个比值,计算能力(FLOPS)则成为新的瓶颈。 请注意,这一分析仅适用于多层感知机(MLP),对于像 ResNet50 这样的卷积神经网络来说,情况会更为复杂。
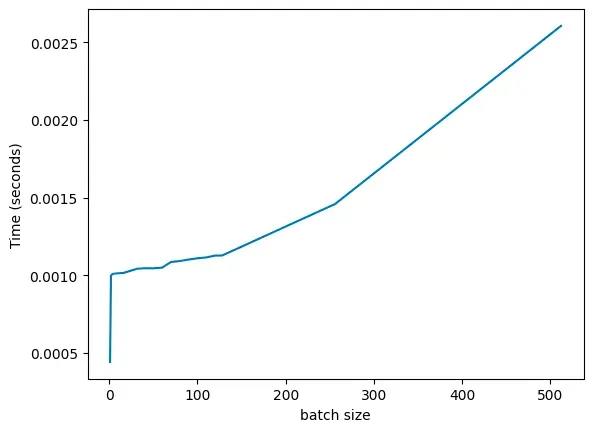
在 T4 GPU(产品规格表[2])上,其浮点运算能力达到 65 TFLOPS(32位浮点数),内存带宽则是 300 GB/s,按照这个数据,理想的运算效率比(magic ratio)应该是 216。实际运行一个深度为 8、宽度为 1024 的多层感知机(MLP)模型时,我们得到的结果与预期相吻合。
![]()
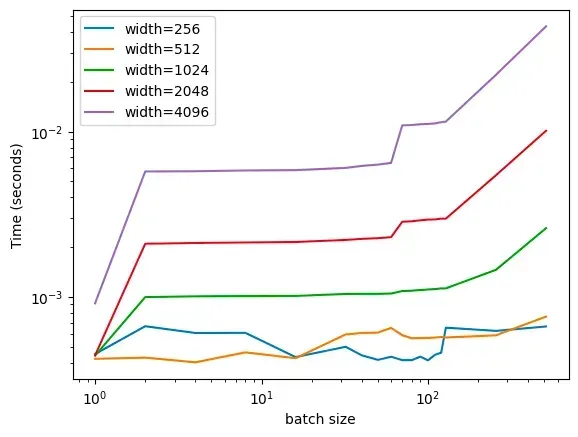
尽管数据中存在一些噪声干扰,但总体趋势与我们的预测一致:推理时间在接近 128 的阈值时开始急剧增加(在此,我们采取逐步加倍的方式来观察和记录不同 batch size 对推理时间(inference time)的影响)。如果我们改变 MLP 层的宽度,会发现这一现象在多种架构中都存在(下面是一张对数-对数(log-log)坐标图,以便所有的数据点都能在图表中清晰地显示)。
![]()
这真是太酷🆒了!我们可以看到在多种不同的模型架构中,都存在一个关键的阈值。有趣的是,较小的网络在处理速度上并没有随着 batch sizes(从 1 到 512)的增加而变化,基本保持恒定。 我对此的初步解释是,这是因为 GPU 在执行数学运算时速度极快,而其他硬件(如 CPU)则相对较慢。在实验初期,我们观察到了大量的噪声干扰,对于这一现象,我暂时只能归咎于"系统开销(overhead)"。
对于许多机器学习工程师而言,他们的时间往往没有花在机器学习本身,而是花在消除这些系统开销上,这些开销大多出现在非机器学习相关的代码中。在强化学习(RL)研究领域,尤其是那些专注于持续学习问题(continual learning problems)的研究者,除非1)他们拥有一个非常大的神经网络,或者2)对整个技术栈进行了极致优化,否则在实验中使用 GPU 往往并不划算。如果你想让一位曾在 DeepMind 工作过的工程师感到尴尬,可以问他们关于"内置计算图环境"(in-graph environments)的问题------在某个阶段,我们甚至是在 TensorFlow 的计算图中实现 RL 环境。
那么,卷积神经网络的情况又是如何呢?
在卷积神经网络中,权重的总数是滤波器数量与滤波器尺寸的乘积。以 torch.nn.Conv2d 为例,权重的计算方式是 kernel_size^2 乘以 out_channels。假设我们处理的是一张分辨率为 (224, 224) 的图像,步长为 1,卷积核大小为 3,那么每个滤波器会被重复使用 224 次。这就意味着,在卷积层中,批处理的优势并不明显,因为我们会反复使用相同的权重。至于池化层,其处理计算量与像素数量呈线性关系,这一点与你所想的相符。
Transformers 的情况又是怎么样呢?
Transformers 本质上就是多层感知机(MLPs),我们可以将它们视为相同的东西。它们具有注意力机制,但是,由于有了 KV 缓存(能够将计算数据保留在内存中),注意力机制所消耗的时间被大幅减少。我之前已经撰写文章对此进行了深入的探讨[3]。
这一观点同样适用于混合专家模型(Mixture of Experts model)。在许多 Transformers 的实现中,KV 缓存是内置于注意力类中的(例如,MaxText[4] 就是一个典型案例[5])。由于 MoE 模型与普通解码器之间的差异仅在于,某些前馈网络层被替换为了 MoE 层,因此 KV 缓存的表现将保持一致,推理过程也是如此,但有一点不同。
MoE 层中的门控机制会将数据批次(batch)分配到不同的专家上。如果门控没有均匀分配数据批次,就可能会引发一些问题。虽然有避免这种情况的路由机制(如"expert's choice"),但在自回归解码器中,我们通常只能采用"token's choice",这可能会导致门控出现偏差。强制门控均匀分配 tokens 是1)当前研究的焦点,并且是2)在训练过程中需要优化的一个重要目标。
Thanks for reading!
Hope you have enjoyed and learned new things from this blog!
About the authors
Finbarr Timbers
empiricist. ml researcher. previously: engineering at deepmind 🧠
END
本期互动内容 🍻
❓你在实际项目中是如何选择 batch size 的?有没有遇到过意外的性能瓶颈?
🔗文中链接🔗
[1]https://www.stat.cmu.edu/~ryantibs/convexopt-F18/scribes/Lecture_19.pdf
[2]https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-t4/t4-tensor-core-datasheet-951643.pdf
[3]https://www.artfintel.com/p/where-do-llms-spend-their-flops
[4]https://github.com/google/maxtext
[5]https://github.com/google/maxtext/blob/main/MaxText/layers/attentions.py#L91
原文链接:
https://www.artfintel.com/p/how-does-batching-work-on-modern