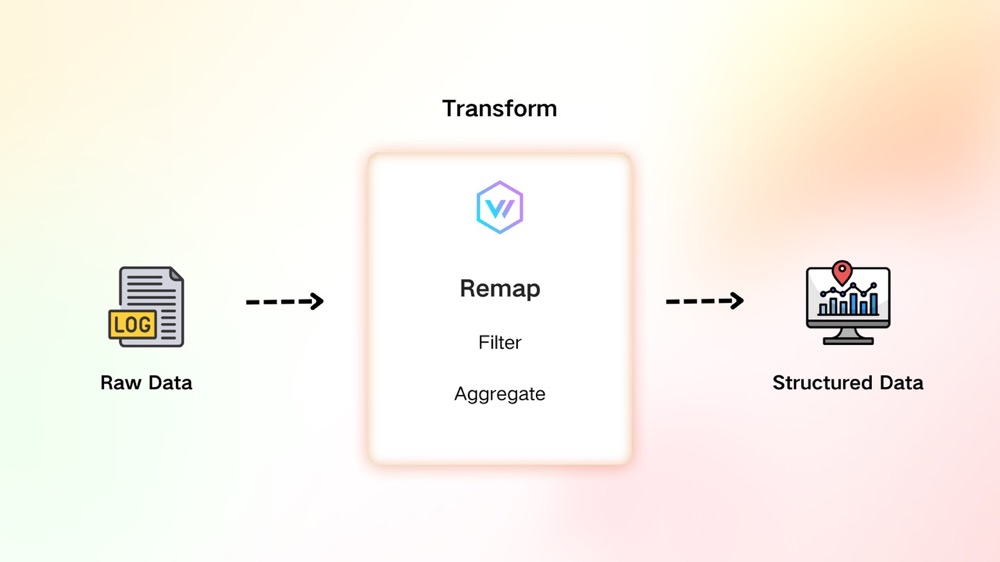
在现代可观测性领域,采集器收集到的原始数据往往需要裁剪或重组,才能形成我们关注的关键数据,并根据内容分发到不同的存储系统。这样的处理不仅让数据更加结构化,便于查询,还能减少无关数据对存储资源的占用。
为了解决这一需求,Vector 提供了 Transforms 功能,并配套了功能强大的 VRL(Vector Remap Languag),允许用户自定义数据处理逻辑,以灵活应对各种数据处理场景。
VRL 是一种面向表达式的语言,旨在以安全、高效的方式转换可观测性数据(Logs 和 Metrics)。它具有简单的语法和丰富的内置函数集,专为可观测性用例量身定制。
在上周发布的 《实战 Vector:开源日志和指标采集工具》一文中,我们已经介绍了 Vector 中的各个基本概念,并且初步的使用了简单的 Transform 来处理了 nginx 日志。Vector Transform 提供了 aggregate,dedupe,filter,remap 等方法。本章我们详细介绍 Transform 中的 remap 功能。
![]()
(图 1 :Remap 在整个 Pipeline 中的位置和作用)
TL;DR
Remap 是通过编写 VRL 语言来定制 Transform 的逻辑,首先我们看一个简单的例子:
[sources.demo_source]
type = "demo_logs"
format = "apache_common"
lines = [ "line1" ]
[transforms.transform_apache_common_log]
type = "remap"
inputs = [ "demo_source" ]
drop_on_error = true
drop_on_abort = true
reroute_dropped = true
source = """
log = parse_apache_log!(.message,format: "common")
if to_int(log.status) > 300 {
abort
}
. = log
.mark = "transform_apache_common_log"
"""
[sinks.transform_apache_common_log_sink]
type = "console"
inputs = [ "transform_apache_common_log" ]
encoding.codec = "json"
[sinks.demo_source_sink]
type = "console"
inputs = [ "demo_source" ]
encoding.codec = "json"
[transforms.transform_apache_common_log_dropped]
type = "remap"
inputs = [ "transform_apache_common_log.dropped" ]
source = """
.mark = "dropped"
"""
[sinks.dropped_msg_sink]
type = "console"
inputs = [ "transform_apache_common_log_dropped" ]
encoding.codec = "json"
然后使用此配置文件启动 Vector ,可以看到在标准输出里出现了三种类型的 JSON,我们会结合这三种类型的的 JSON 来描述 VRL 代码的逻辑。
VRL 基本介绍
通过上述的例子我们对 transform 有了一个简单直观的认识,在上述配置中的 16 行到 19 行,我们主要定义了名为 transform_apache_common_log 的 Transform。
以下我们详细描述一下这个 Transform 到底做了什么。Transform 的定义的基本格式这里不再赘述,我们重点介绍 source 的字段中 VRL 的内容。
上述例子中 source 中的 VRL 可以分为三个部分:
1. 解析
log = parse_apache_log!(.message, format: "common")
同大部分编程语言的赋值语句类型。这一句是把等号右边表达式产生的结果赋值给 log 变量。等号右边整体的意思是按照 Apach Common 的格式解析原 event 中的 message 字段转化为更结构化的键值对结构。
我们再细化一点。这里是调用了一个内置函数 parse_apache_log 他接收两个参数:
-
.message
-
format: "common"
这里的 .message 是对当前 event 取 message 字段的操作。当前 event 的格式如下:
{
"host": "localhost",
"message": "218.169.11.238 - KarimMove [25/Nov/2024:04:21:15 +0000] \"GET /wp-admin HTTP/1.0\" 410 36844",
"service": "vector",
"source_type": "demo_logs",
"timestamp": "2024-11-25T04:21:15.135802380Z"
}
可我们观察到除了 message 字段还包含了一些 host source_type 等元信息。apache log 格式除了 common 还有 combined 格式,这里的第二个参数表示用 common 的格式来解析传入的日志内容。
除此之外,我们还会观察到 parse_apache_log 后有一个 ! 。这个感叹号并不是类似 Rust 中宏的标记,而是代表了一种错误处理逻辑。我们会在后面的 VRL 错误处理小结进行详述。
如果解析成功,Log 将会被赋值为结构化的 Apach Common 格式的数据,可以看到本来单一的字符串内容变成了结构化的键值对,后续可以很方便的进行过滤和聚合等操作。
{
"host": "67.210.39.57",
"message": "DELETE /user/booperbot124 HTTP/1.1",
"method": "DELETE",
"path": "/user/booperbot124",
"protocol": "HTTP/1.1",
"size": 14865,
"status": 300,
"timestamp": "2024-11-26T06:24:17Z",
"user": "meln1ks"
}
2. 过滤 & 错误处理
既然 Log 已经是结构化的数据了,我们就可以用更精细的方式来过滤或者裁剪我们关心的数据。假设我们对 status 大于 300 的数据不关心,那就可以设置 log.status > 300 时中断此 transform (这里的谓词可以换成任意你想要的逻辑)。
if to_int(log.status) > 300 {
abort
}
默认逻辑下,如果触发 abort, 当前事件会原封不动地传入下一个处理单元,因为我们不关心这些数据所以我们决定丢掉这部分数据。
可使用如下配置:
drop_on_error = true
drop_on_abort = true
但是,如果有一些我们本来没考虑到的情况,导致了 vrl 执行错误(类型错误,解析错误等),这样我们可能本来所关心的数据就被丢失了,这会造成一些信息上的缺失。为了解决这个问题。我们可以使用 reroute_dropped = true 配置来把 drop 的 event 增加 metadata 后统一分发到一个 <current_transform_id>.dropped 的 input 里(上述例子中的 transform_apache_common_log.dropped)。
{
"host": "localhost",
"mark": "dropped",
"message": "8.132.254.222 - benefritz [25/Nov/2024:07:56:35 +0000] \"POST /controller/setup HTTP/1.1\" 550 36311",
"metadata": {
"dropped": {
"component_id": "transform_apache_common_log",
"component_kind": "transform",
"component_type": "remap",
"message": "aborted",
"reason": "abort"
}
},
"service": "vector",
"source_type": "demo_logs",
"timestamp": "2024-11-25T07:56:35.126819716Z"
}
我们只要关注这个 input 就可以了解哪些数据被我们 drop 了,视情况可以修改 vrl 把那些丢失的数据也利用起来。
3. 替换
. = log
.mark = "transform_apache_common_log"
上述配置中,第一行等号左边的「.」,在 VRL 中表示 VRL 正在处理的当前 event。等号右边的则是之前解析出来的结构化 Log 结果,将会替换掉当前的 event。
第二行表示在已经替换成结构化日志的当前 event 增加一个 mark 字段来标记当前 event 来自 transform_apache_common_log transform。
最终我们得到了如下数据格式的数据,此数据格式的数据会取代原数据格式被下游接收:
{
"host": "67.210.39.57",
"mark": "transform_apache_common_log",
"message": "DELETE /user/booperbot124 HTTP/1.1",
"method": "DELETE",
"path": "/user/booperbot124",
"protocol": "HTTP/1.1",
"size": 14865,
"status": 300,
"timestamp": "2024-11-26T06:24:17Z",
"user": "meln1ks"
}
VRL 错误处理
在上文调用 parse_apache_log 时,我们在其后增加了一个 !,这是 VRL 中的一种错误处理方式。由于 Event 中包含的字段类型多种多样,为了保证其灵活性,许多函数在逻辑处理或数据类型不符合预期时可能会返回错误。因此,需要引入错误处理机制来应对这些情况。
parse_apache_log 其实是返回了两个结果,一个是函数正常返回结果,另一个则是一个错误信息类似于:
result, err = parse_apache_log(log,format:"common")
当 err 不等于 null 时表示函数执行发送了错误。在 VRL 中,在函数名称后面增加 ! 算是一种语法糖,表示当遇到错误时立即中断当前 VRL 片段提前返回错误。
类似如下代码:
result, err = parse_apache_log(log,format:"common")
if err != null {
panic
}
假如你的 message 是多种格式的数据混合在一起,使用 ! 来提前中断解析逻辑就显得不是那么合理了。假设我们的 Event 字段可能是 JSON、Apache Common 格式中的一种,我们可能就需要如下的配置来使日志结构化的输出:
structured, err = parse_json(.message)
if err != null {
log("Unable to parse JSON: " + err, level: "error")
. = parse_apache_log!(.message,format: "common")
} else {
. = structured
}
我们不能在 parse_json 失败的时候就直接终止 transform,需要再尝试按照 apache common 格式解析后再视解析结果而定。
总结
Vector 的 Transform 功能内置了功能强大的 VRL 语言,支持自定义数据处理逻辑。通过 Remap,我们可以对原始数据进行解析、过滤、替换等操作。同时,VRL 提供了完善的错误处理机制,能够确保 Transform 的稳定性,避免因某些数据异常导致任务失败或数据丢失。此外,VRL 拥有丰富的函数库,可以轻松处理大多数常见数据格式,不仅提升了开发效率,还让数据处理更加灵活高效。
更多详情可参考 VRL 的官网文档。
关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
官网:https://greptime.cn/
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/