在实时开发中,双流join获取目标对应时刻的属性时,经常使用temporary join。笔者在流量升级的实时迭代中,需要让流量日志精准的匹配上浏览时间里对应的商品属性,使用temporary join开发过程中踩坑不少,将一些经验沉淀在此文中,供各位同学参考与交流。
关于实时flinkSQL的双流join的背景知识可以先阅读以下文章:
https://www.51cto.com/article/713922.html
目前我们有一条流量日志明细的TT流A,以及一条商品标签的TT流B,在flink中对A流和B流进行双流join类似于将A流关联一个hbase维表。temporary join有以下特点:
1. 单流驱动:虽然是双流join,但数据下发只由一条流驱动。
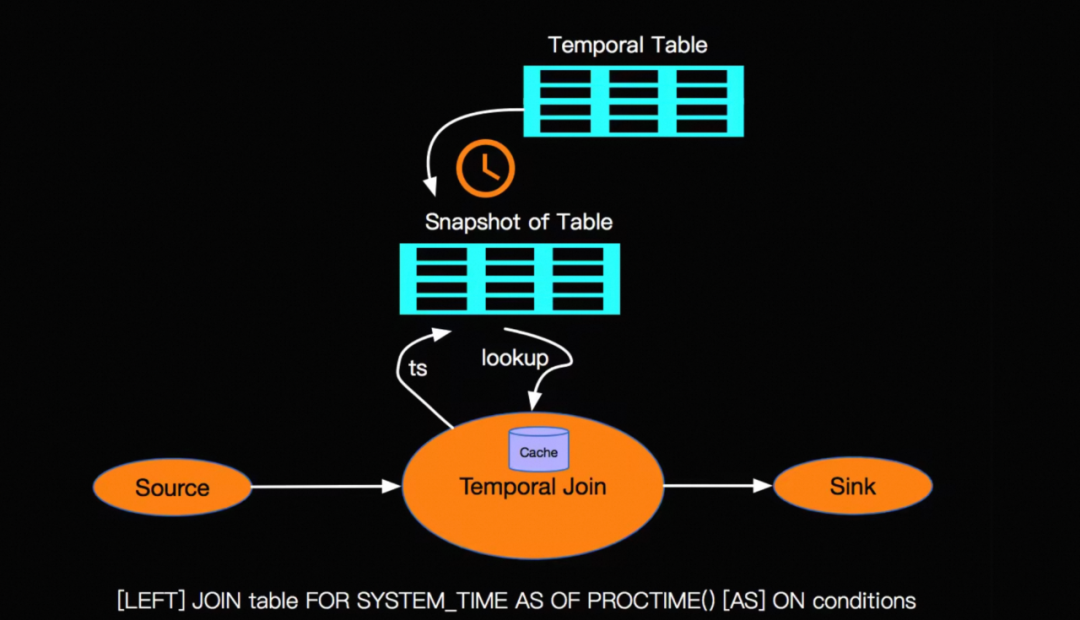
2. 需要定义versioned table,versioned table记录了每个时刻的属性信息,双流join时被动查询。类似于银行汇率表,在货币兑换的时候需要参考兑换时刻的汇率。
3. 查询携带时间版本信息:temporary join携带由两条流的watermark触发,因此查询到的属性是对应时间内的属性。
图片来源:孙金城, 《Blink 漫谈系列 - Temporal Table JOIN》
![]()
应用场景&实例分享
当需要根据实时汇率*货币金额计算总金额,实时商品价格*成交件数计算总成交金额时,经常会使用temporary join获取实时的汇率和价格信息。在笔者的流量升级业务迭代中,我们需要获取实时的商品标签,因此需要定义商品标签的versioned table,写法如下:
CREATE TEMPORARY TABLE `tag_ri` ( `id` VARCHAR, `tag` VARCHAR, `time` VARCHAR, `ts` AS `TO_TIMESTAMP`(`time`, 'yyyy-MM-dd HH:mm:ss'), WATERMARK FOR `ts` AS `withOffset`(`ts`, 0) ) WITH ( 'connector' = 'tt', 'router' = '******', 'topic' = 'tag_ri', 'lineDelimiter' = '\n', 'fieldDelimiter' = '\u0001', 'encoding' = 'utf-8');
CREATE TEMPORARY VIEW `tag`ASSELECT `id` , `tag` , `time` , `ts`FROM ( SELECT `id` , `tag` , `time` , `ts` , ROW_NUMBER() OVER (PARTITION BY `id` ORDER BY `time` DESC) AS `rownum` FROM `tag_ri` )WHERE `rownum` = 1;
同上我们也需要定义流量日志明细流的watermark,并进行双流join
CREATE TEMPORARY TABLE `log_ri` ( `id` VARCHAR, `time` VARCHAR, ...... `ts` AS `TO_TIMESTAMP`(`time`, 'yyyy-MM-dd HH:mm:ss'), WATERMARK FOR `ts` AS `withOffset`(`ts`, 0)) WITH ( 'connector' = 'tt', 'router' = '******', 'topic' = 'log_ri', 'lineDelimiter' = '\n', 'fieldDelimiter' = '\u0001', 'encoding' = 'utf-8',);
select `a`.`id` ,...... ,`b`.`tag`from ( SELECT * FROM `log_ri` ) AS `a`LEFT JOIN `tag` FOR SYSTEM_TIME AS OF `a`.`ts` AS `b` ON `a`.`id` = `b`.`id`
结果如下:
--商品标签信息12:00> SELECT * FROM tag_ri;
id tag(商品标签)======= ======================= t1 A
12:30> SELECT * FROM tag_ri;
id tag(商品标签)======= ======================= t1 B
--流量明细日志查询 t1商品共三条明细SELECT * FROM log_ri;
id time======= ======== t1 12:00 t1 12:15 t1 12:30
--执行temporary joinselect `a`.`id` ,`a`.`time` ,`b`.`tag`from ( SELECT * FROM `log_ri` ) AS `a`LEFT JOIN `tag` FOR SYSTEM_TIME AS OF `a`.`ts` AS `b` ON `a`.`id` = `b`.`id`
id time tag(商品标签)======= ======== ======================= t1 12:00 A t1 12:15 A t1 12:30 B
![]()
开发经验
▐ 稀疏数据处理
由于temporary join是由两条流的watermark触发,如果versioned table是一条稀疏的流(在一段时间内无数据流入),那么join可能存在等待不下发数据的现象,可以通过设置参数 set table.exec.source.idle-timeout = 10s ,可以让A流数据不进行等待,具体参数介绍可以参考:
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/config/#table-exec-source-idle-timeout
▐ 数据延迟下发
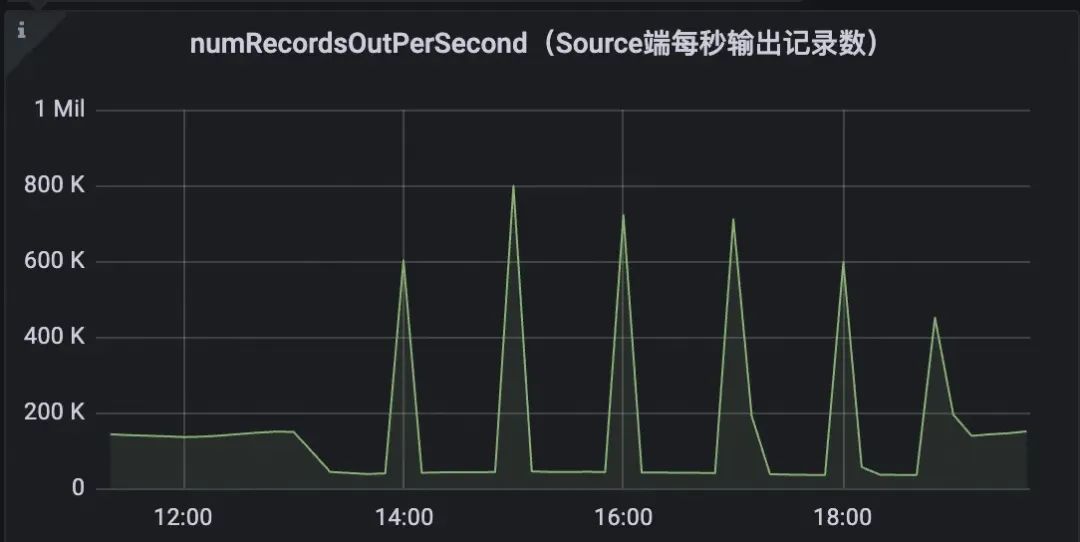
在实际开发中,我们发现temporay join后数据一直等待不下发,整点才会进行下发的现象。
![]()
我们结合SQL语法,对TT日志进行回流分析:代码逻辑是四路source union后, join 定义的versioned table
select a.* ,b.tagfrom(select * from source_1 union all select * from source_2union all select * from source_3union all select * from source_4) atemporay join b流
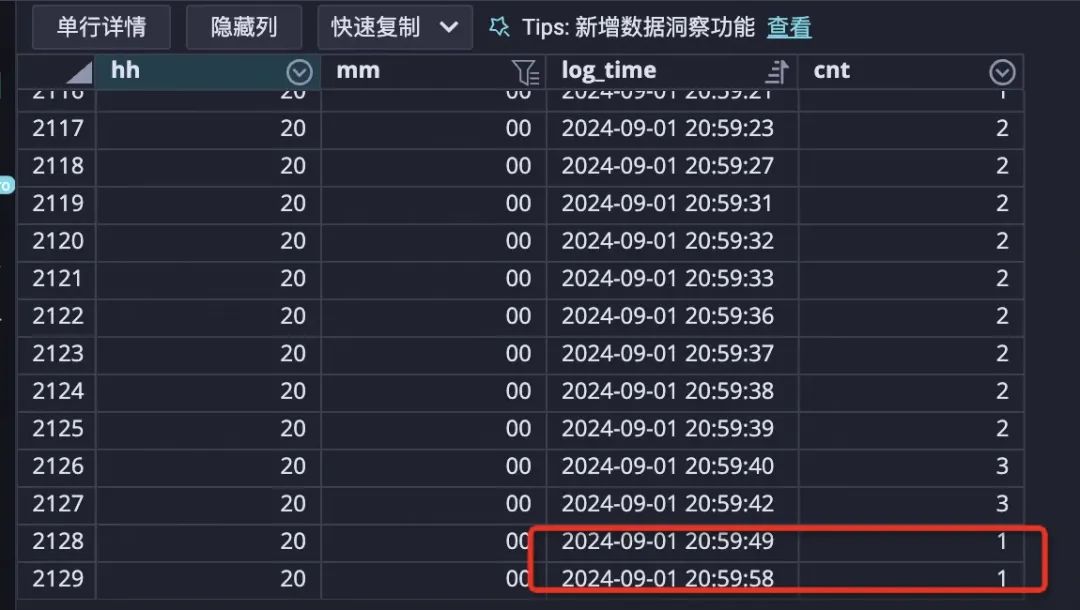
source_4会在整点流入少部分当前小时59分钟的数据,而temporay join 是由两边的watermark所触发,所以会有a流等待b流的时间到达当前小时59分钟后再触发的现象。
对source_4中log_time>当前时间的部分,做temporary join时将log_time置为当前时间,该问题就解决了。
![]()
总结
1. 在单流驱动的双流join场景中,temporary join是一种常见的处理方式。
2. temporary join由两条流的watermark触发,需要对两条流的watermark进行预处理,防止数据稀疏和数据抢跑等现象影响数据下发。
![]()
团队介绍
我们是淘天集团-业务技术-商家数据团队,专注于开发和维护生意参谋这一全渠道、全链路、一站式的数据平台,同时也负责品牌数据银行和策略中心两大产品。旨在为商家提供全面的数据服务,包括但不限于经营分析、市场洞察、客群洞察等,以帮助商家提高商业决策效率。