摘要:Java 程序 Hang 是应用运维中经常遇到的故障类型,由于此类故障与操作系统调度、应用代码逻辑等均有复杂的相互催化关系,故障触发条件极难确定,因此也是故障诊断中最难啃的骨头之一。在此篇案例中您将看到,某银行在分布式核心系统“认证网关 Hang” 故障的诊断过程中,如何使用 DeepFlow 大模型智能体快速分析 Java 程序 CPU 持续剖析数据,在故障发生后 3 分钟内迅速定位出 Hang 的原因。
01
简介
近日,某银行分布式核心系统安全认证中心频繁遇到认证网关程序 Hang 故障,导致核心交易不定时受损,经过两周时间从认证网关程序自身的追踪、指标、日志定位故障原因,但进展缓慢,因此寻求 DeepFlow 协助。
通过一键部署 DeepFlow Agent,即刻点亮“认证网关”的持续剖析数据,运维人员在故障重现后的 3 分钟内迅速发现“认证网关程序”内 On-CPU 异常函数,并启用大模型智能体对持续剖析结果进行分析,快速确定故障与 “GC”、“正则表达式编译处理”的关系,最终经过开发人员验证证实故障根因。
02
持续剖析及大模型智能体
什么是 DeepFlow 持续剖析
DeepFlow 持续剖析功能通过 eBPF 获取应用程序的函数调用栈快照,形成持续剖析数据,绘制任意应用程序的 On-CPU、Off-CPU、Memory Profiling 火焰图,帮助开发者快速定位程序内的函数性能瓶颈。
DeepFlow 的剖析对象不仅包括 Java 语言应用程序,还包括 C/C++、Golang、Rust 等语言的应用程序。
DeepFlow 的剖析深度不仅包括业务函数,还包括开发框架库函数、动态链接库函数、语言运行时函数、内核函数等。
![DeepFlow Profilling 图解]()
具体的剖析功能包括:
- On-CPU 持续剖析:剖析应用程序函数调用栈的 On-CPU 分布,洞察 CPU 消耗热点函数,诊断与 CPU 资源有关的程序性能故障,帮助开发人员优化程序计算性能;
- Off-CPU 持续剖析:剖析应用程序函数调用栈的 Off-CPU 分布,洞察 Off-CPU 态热点函数,诊断慢 I/O、锁竞争、计数器、换页等原因造成的程序性能故障,帮助系统运维人员、开发人员优化系统性能和程序性能;
- Memory 持续剖析:剖析应用程序的内存消耗分布,洞察内存使用热点,诊断内存高消耗、慢泄露、OOM 等应用程序的运行异常,帮助开发人员快速找到内存问题根因;
- 实时剖析:打印 Java 程序的线程调用栈瞬时快照,诊断 Java 应用程序的性能异常和线程调度异常。
延伸阅读:DeepFlow 持续剖析功能使用指导
什么是 DeepFlow 大模型智能体
DeepFlow 大模型智能体(即 DeepFlow Stella)通过 RAG + 大模型自动化智能分析 DeepFlow 可观测性数据,实现基于可观测性数据的大模型 AI 运维。
03
持续剖析 + 大模型智能体故障诊断
运维人员快速部署 DeepFlow Agent 对“认证网关程序”所在节点进行覆盖后,即刻热加载并点亮程序的持续剖析数据,开始对程序函数调用栈的深度观测。
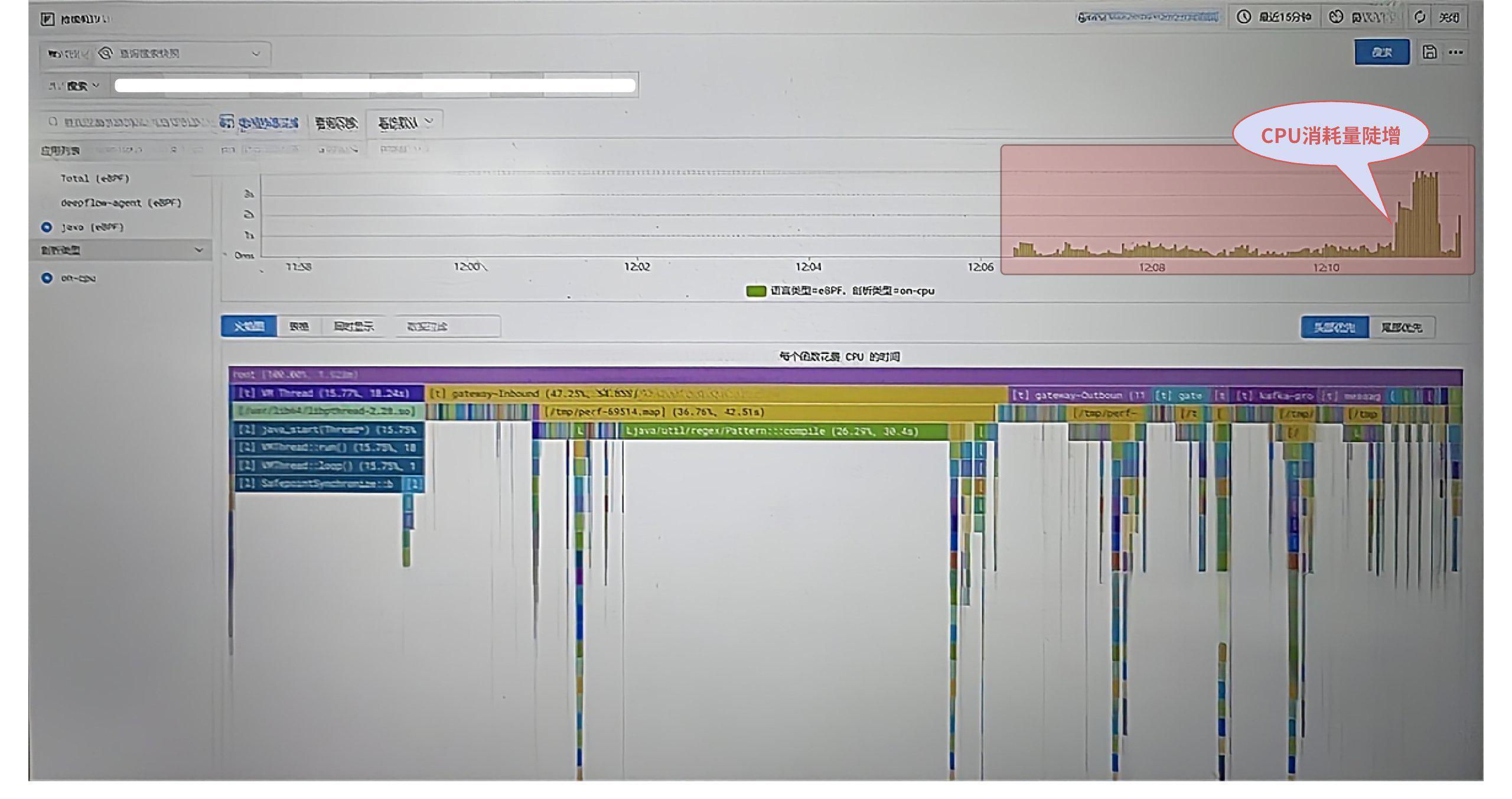
1)On-CPU 用量趋势发现飙升
打开 DeepFlow 的「持续剖析」功能,**过滤“认证网关程序”**的 On-CPU 持续剖析数据,发现 12:11 前后应用程序 On-CPU 用量飙升。
![On-CPU 剖析结果]()
2)Hang 前剖析发现热点函数
将 On-CPU 剖析的时间范围缩小到问题时段(12:10:40~12:11:20),发现“认证网关程序”的两个函数耗时占比异常(色块长度明显),但运维工程师很难理解这两个函数的异常说明什么问题。
![问题时段 On-CPU 剖析结果]()
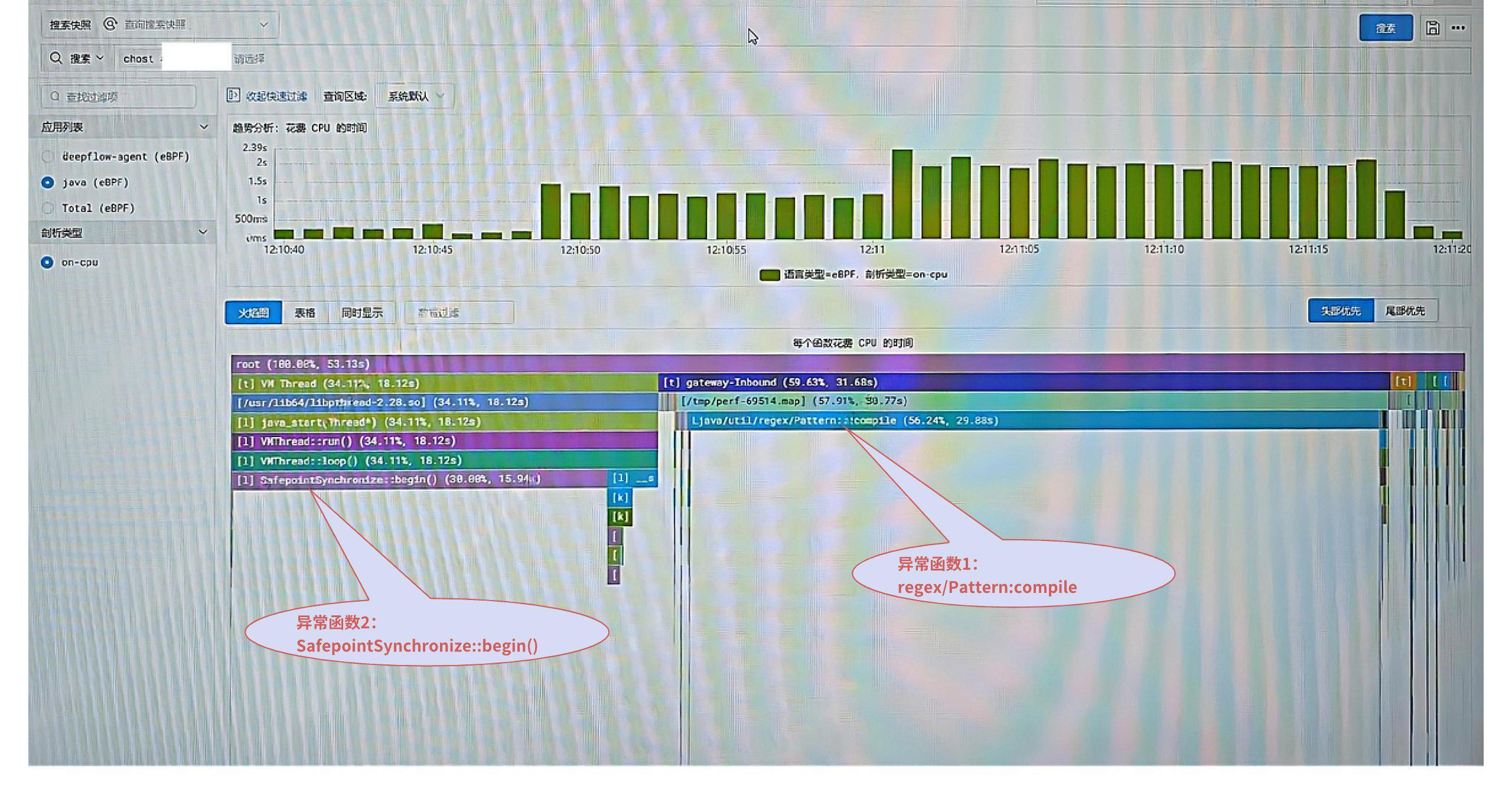
3)大模型智能体诊断根因
于是调用 DeepFlow 大模型智能体对上述呈现的 On-CPU 火焰图进行分析,得到非常直接、详细的根因诊断报告,关键信息提取如下:
java/util/regex/Pattern:: compile函数占用了 56.24% 的 CPU 时间,可能的原因是“编译了大量的正则表达式,或者是正则表达式的复杂度较高”;SafepointSynchronize::begin函数占用了 30.00% 的CPU时间,可能的原因是“频繁的 GC 引起”。
![大模型智能体分析结果]()
至此,发现“认证网关程序 Hang” 与 “GC” 和“正则表达式编译处理”有直接关系,问题基本清晰,可以确定两者相互作用导致问题发生。
04
结果验证
最终经程序开发人员验证,证实“认证网关程序不定时 Hang” 的具体过程是:
1)JVM 新生代空间满触发 YongGC,YougGC 机制要求所有业务线程必须进入 Safepoint 状态;
2)此时java/util/regex/Pattern:: compile函数正在执行正则匹配计算任务,由于正则匹配对象的长度较长(人脸识别数据),在短时间无法结束此次计算任务以进入 Safepoint 状态,因此阻塞 YougGC 过程,并导致其他业务线程全部进入等待状态(表现为进程 Hang 住),直至正则匹配计算完毕,JVM 完成 YongGC,所有线程恢复工作,进程恢复正常。
GC、YongGC、与 Full GC
- GC(Garbage Collection):是 Java 语言中的特色机制,Java GC 自动识别并回收 Java Heap 中不再使用的对象,实现自动内存管理,防止内存泄漏,并减轻程序员对内存管理的负担。
- YongGC:也称新生代 GC,当 Java Heap 的新生代(Eden)区域没有足够的空间之后自动触发 YongGC,对新生代区域进行垃圾回收,此时会停止系统程序的运行,不允许系统程序执行任何代码逻辑。
- FullGC:当老年代空间不足、方法区空间不足、System.gc()被显式调用或其他情况,会触发 FullGC 清理整个 Java 堆,包括年轻代、老年代和方法区(永久代、元空间)。
05
总结
DeepFlow 通过 eBPF 技术实现了对应用程序随时在线、敏捷高效、全栈函数的性能持续剖析能力,在此类“应用程序 Hang” 的故障诊断过程中,可以为运维人员实时呈现故障阶段应用程序函数调用栈的全貌和性能热点。
但通过函数性能剖析发现代码问题是一件极有挑战的工作,由于函数调用栈涉及业务逻辑、开发框架、共享函数库、系统内核等诸多不同知识领域,全面了解和掌握性能剖析结果中的每个函数是一件不可能完成的任务,通过 DeepFlow 大模型智能体对性能剖析火焰图进行分析和解释,在此次故障定位中快速、清晰地指明了问题所在。
DeepFlow 可观测性数据与大模型相结合,为复杂故障诊断的效率带来质的飞跃!
06
什么是 DeepFlow
DeepFlow 是云杉网络开发的一款可观测性产品,旨在为复杂的云原生及 AI 应用提供深度可观测性。DeepFlow 基于 eBPF 实现了应用性能指标、分布式追踪、持续性能剖析等观测信号的零侵扰(Zero Code)采集,并结合智能标签(SmartEncoding)技术实现了所有观测信号的全栈(Full Stack)关联和高效存取。使用 DeepFlow,可以让云原生及 AI 应用自动具有深度可观测性,从而消除开发者不断插桩的沉重负担,并为 DevOps/SRE 团队提供从代码到基础设施的监控及诊断能力。
GitHub 地址:https://github.com/deepflowio/deepflow
访问 DeepFlow Demo,体验零侵扰、全栈的可观测性。
**成都的朋友注意啦!!**欢迎报名参与9月7日· eBPF 零侵扰可观测性 Meetup ·成都站,本次活动聚焦《开源可观测性工程创新探索》,来自 DeepFlow、OPPO、金山、腾讯等多位可观测领域专家将一起探讨行业发展趋势、应用场景和落地路径。