栏目介绍:“玩转OurBMC”是OurBMC社区开创的知识分享类栏目,主要聚焦于社区和BMC全栈技术相关基础知识的分享,全方位涵盖了从理论原理到实践操作的知识传递。OurBMC社区将通过“玩转OurBMC”栏目,帮助开发者们深入了解到社区文化、理念及特色,增进开发者对BMC全栈技术的理解。
欢迎各位关注“玩转OurBMC”栏目,共同探索OurBMC社区的精彩世界。同时,我们诚挚地邀请各位开发者向“玩转OurBMC”栏目投稿,共同学习进步,将栏目打造成为汇聚智慧、激发创意的知识园地。
在OpenBMC的众多使用C++开发的软件包中,广泛采用了智能指针,如shared_ptr和unique_ptr,以实现对象的有效管理和自动释放。本期内容,我们将重点介绍shared_ptr的使用。我们将概述shared_ptr的基本概念、结构和使用方法,然后分享一些实践经验和总结,以帮助读者更好的理解和运用shared_ptr。
shared_ptr 与裸指针
智能指针shared_ptr相比于传统的裸指针,显著增强了对象管理的能力,通过引入引用计数机制,实现了对象的自动释放,从而避免了内存泄漏等问题。本节内容,我们基于64位系统环境,利用GDB调试工具,深入shared_ptr的内部数据结构,详细解析shared_ptr与裸指针在内存管理和功能上的差异。
![]()
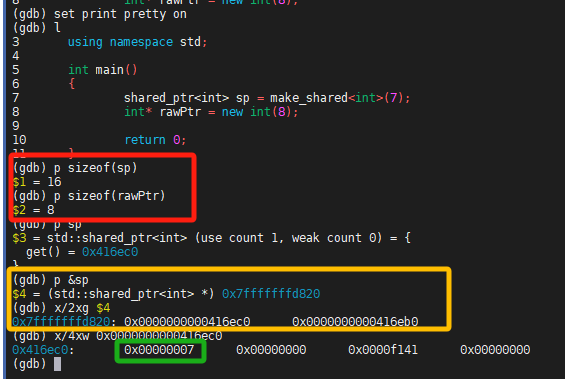
图 1 shared_ptr与裸指针的区别
使用图 1 中的示例程序进行简单的调试分析。定义为shared_ptr类型的变量sp,如图 1 红色方框所示,其占用的内存大小为16字节,即为两个裸指针的大小。黄色方框表示shared_ptr内部有一个指向对象本身的裸指针(如 0x0000000000416ec0),这个指针指向了一个整型对象(值为7,绿色方框所示)。此外,shared_ptr还包含或指向一个控制块(control block),该控制块通过另一个内部指针(如 0x0000000000416eb0)访问,用于管理对象的引用计数和其他可能的元数据。
![]()
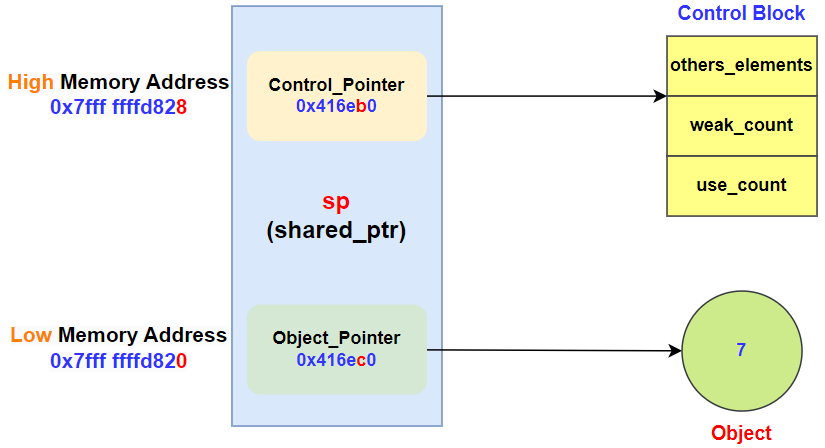
图 2 shared_ptr结构示意图
基于图 1 的调试结果,我们可以使用图 2 来对shared_ptr的结构进行分析总结。变量sp占用0x7fff ffffd820~0x7fff fffd830,共16字节大小的内存。在这16字节的内存中,shared_ptr内部包含两个裸指针:
(1)低地址部分(0x7fffffffd820):这部分存储了一个指向整型对象的指针值(0x416ec0)。这个指针直接指向了由shared_ptr管理的整型对象(值为7)。
(2)高地址部分(0x7fffffffd828):紧接着低地址部分之后,这部分存储了一个指向控制块的指针值(0x416eb0)。控制块负责维护对象的引用计数和其他可能的元数据,以确保在最后一个shared_ptr被销毁时能够自动释放对象。
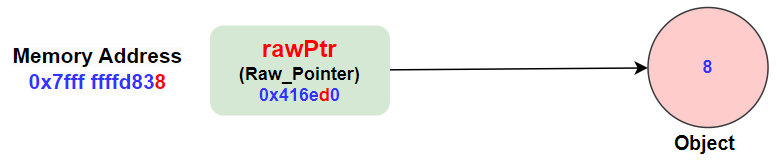
相比之下,图 3 展示的裸指针结构,仅包含一个指向整型对象的指针值(0x416ed0),没有自动内存管理的功能,需要程序员手动管理对象的生命周期。
![]()
图 3 裸指针结构示意图
shared ptr 与 make shared
构造shared_ptr对象,通常有如下两种方式:
(1)auto sp = shared_ptr<T>(new T(… args));
(2)auto sp = make_shared<T>(… args);
接下来,将通过具体的代码示例来阐述这两种构造shared_ptr对象方式的优缺点。
![]()
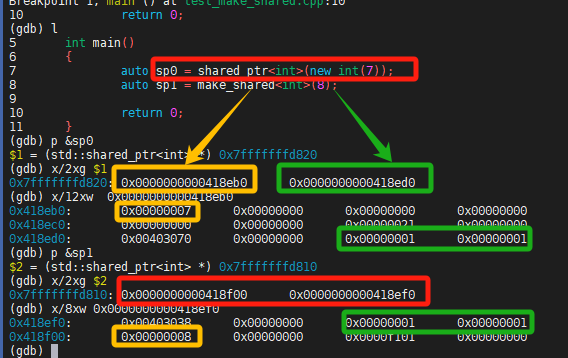
图 4 shared_ptr对象构造方式
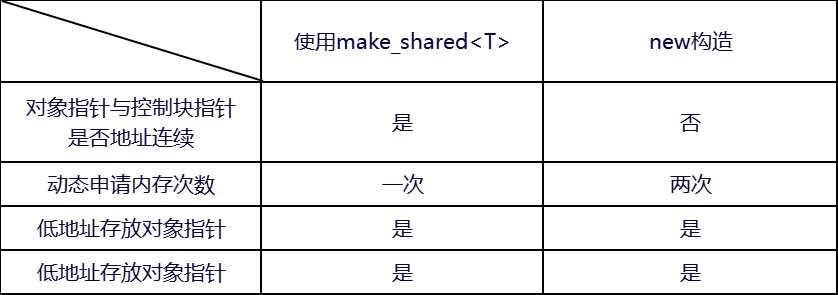
从图 4 可以看出,使用裸指针方式直接构造shared_ptr对象时,其指向对象的指针地址,和指向控制块的指针地址通常不是连续分配的。这是因为首先通过new操作符单独为对象分配内存,构造整型对象整数7(地址为:0x418eb0);随后 shared_ptr构造函数内部再为控制块分配内存(地址:0x418ed0),共申请了两次内存。而使用make_shared方式构造shared_ptr对象时,指向对象的指针,和指向控制块的指针地址值是连续分配的。这两种方式,都是低地址存放对象指针值,高地址存放控制块指针值。
表 1 两种构造方式的异同
![]()
表 1 总结了这两种方式区别点和相同点。make_shared<T>的构造方式通过仅执行一次内存申请操作,相比使用new方式构造,其性能会有所提升。这是因为 make_shared能够将对象的内存和控制块(包括引用计数等信息)的内存作为一个整体连续分配,使得对象指针和控制块的指针在物理内存中的地址是连续的。这种内存布局利用了CPU的缓存局部性原理,在程序接连访问对象和引用计数时,能够更有效地利用CPU缓存,从而进一步提升性能。因此,在可能的情况下,推荐使用make_shared<T>的方式来构造shared_ptr对象。
shared_ptr 与 weak_ptr
shared_ptr虽然能够根据引用计数是否为0来自动管理内存释放,从而有效防止内存泄漏。然而,在涉及环状引用结构的场景中,因引用计数无法为0,造成内存无法被释放,导致内存泄漏。
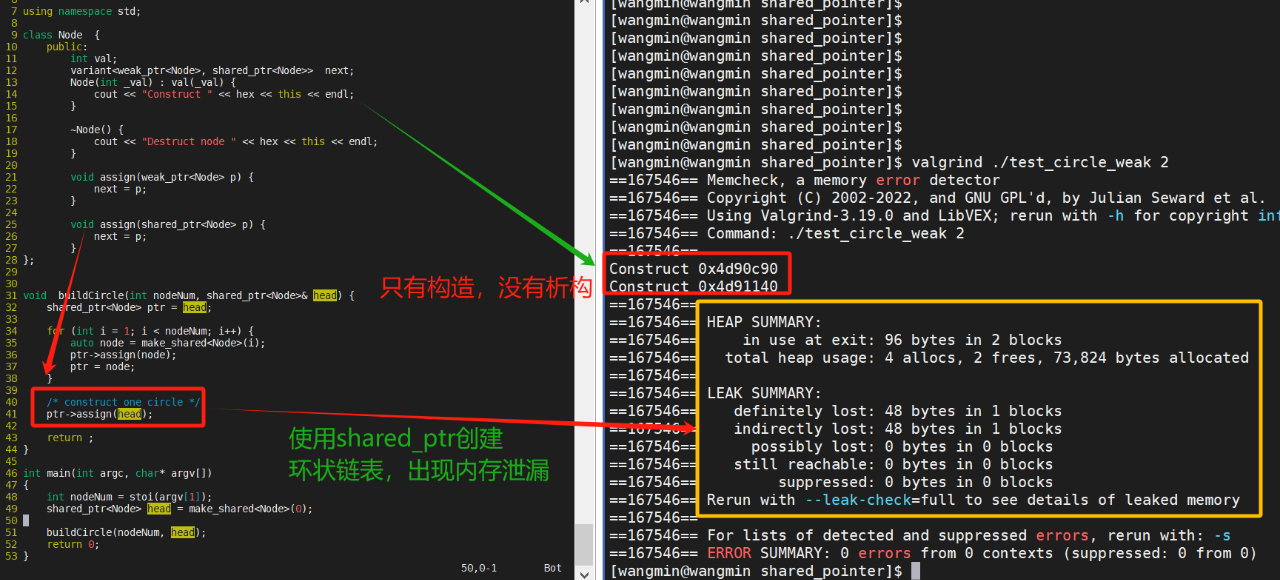
以图 5 左侧的代码做示例,使用shared_ptr构造环状链表后,由于head和ptr相互持有对方的引用,它们的引用计数将永远无法降至0。因此,链表内的两个节点都未调用析构函数释放内存,可被valgrind工具检测到内存泄漏的现象。
![]()
图 5 环状链表出现内存泄漏
为解决此类环状链表问题,需要引入weak_ptr。weak_ptr是一种不增加对象引用计数的智能指针,它指向一个由 shared_ptr管理的对象,但不拥有该对象。通过使用weak_ptr来打破环状引用中的一个或多个链接,可以确保至少有一个shared_ptr的引用计数能够降为0,从而触发内存的释放。
![]()
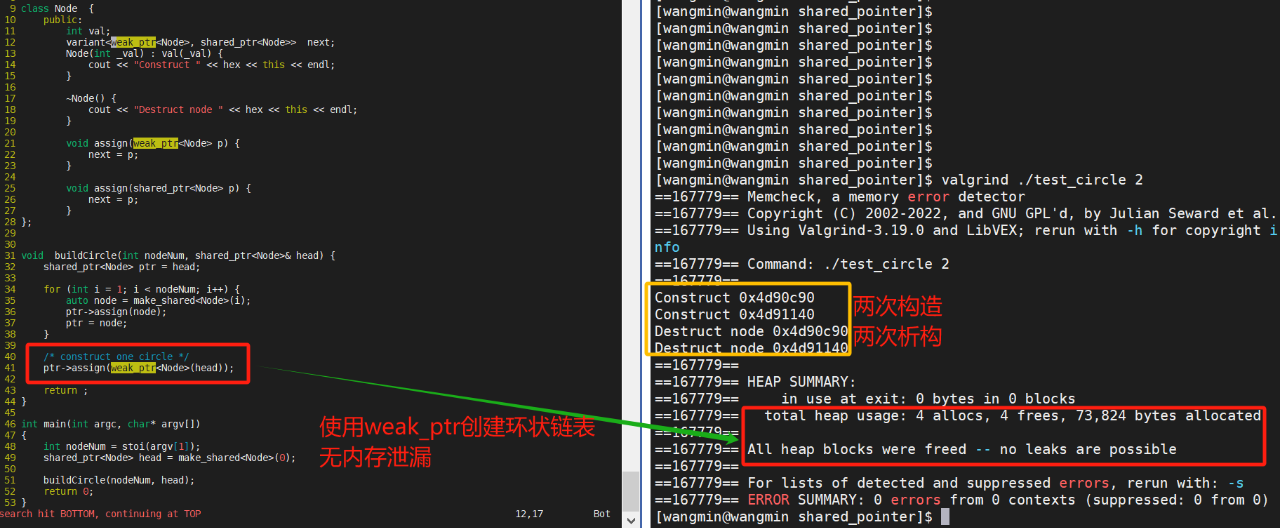
图 6 环状链表无内存泄漏
可将图 5 左侧代码里的第41行,用weak_ptr替换shared_ptr,修改成如图 6 所示的代码。程序运行后,使用valgrind工具检测,发现无内存泄漏的现象。即使用weak_ptr构造环状链表,会构造两个节点,在进程退出时,自动调用析构函数,释放节点的内存。上述示例,可见weak_ptr能实现环状链表自动释放内存,修复内存泄漏的问题。
使用GDB调试图 6 程序,进一步观察环状链表逐个释放节点的步骤。如图 7 所示:
(1)head指向管理对象的地址为0x41bec0,其next指向ptr的管理对象地址0x41c310。而ptr的next指向head的管理对象地址0x41bec0。因此,head与ptr这两个节点,形成了以环状链表。
(2)ptr->next指向的节点,即为头指针head,其引用计数依然为1,head和 ptr没有相互持有对方的引用。
(3)自动释放对象,调用析构函数。
![]()
图 7 释放环状链表的节点
enable shared from this
enable_shared_from_this使用私有成员weak-this,跟踪首次管理对象的shared_ptr控制块。即shared_ptr<T>的构造函数,会主动检测基类enable_shared_from_this<T>实例化的对象,是否存在可访问。若不存在,则构造shared_ptr<T>对象,并实例化私有成员weak-this。
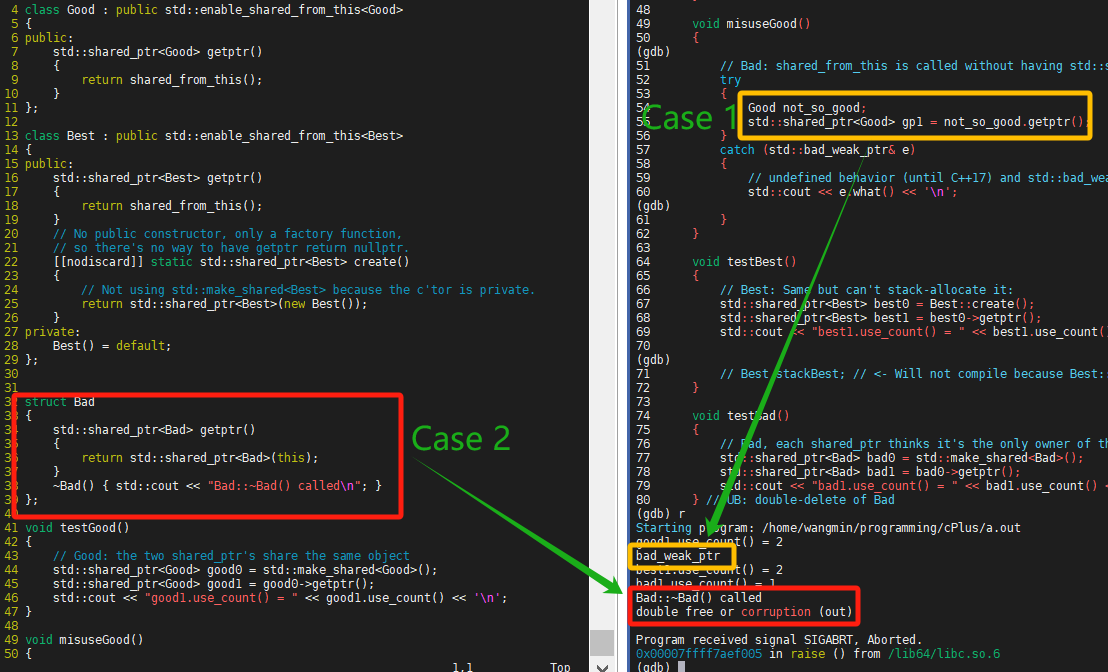
- 使用shared_from_this管理对象时,需要知道该对象是否已经被shared_ptr持有,管理该对象的共享计数,否则会在运行时抛出bad_weak_ptr异常。
- 对shared_ptr提供安全的保护机制,避免多个shared_ptr在没检测到彼此时,导致双重析构、释放内存的问题。
![]()
图 8 enable_shared_from_this示例
图 8 采用CppReference的示例代码,分别说明bad_weak_ptr异常,和双重析构、释放内存问题。
总的来说,shared_ptr是C++中一个非常强大的工具,它可以帮助开发者以更安全、更简洁的方式管理动态内存。同时,它也有一些潜在的问题和限制在使用的过程中需要注意,以确保能够正确的使用它。
欢迎大家关注OurBMC社区,了解更多BMC技术干货。
OurBMC社区官方网站:
https://www.ourbmc.cn/