DeepFlow 可观测性平台以 eBPF 技术实现的零侵扰(Zero Code)分布式追踪为核心,不仅实现了面向应用的全栈(Full Stack)观测能力,同时通过开放的数据集成接口和智能标签(SmartEncoding)技术支持汇聚外部的 Metrics、Tracing、Logging、Profiling 等各类的海量观测数据,消除运维数据孤岛,为 IT 系统的运行维护、安全监测、运营分析提供统一的可观测性数据综合解决方案。
在本篇实践案例中,将向您介绍如何在 DeepFlow 可观测性平台快速集成主机指标数据,补充、丰富可观测性数据湖的信号种类,在业务异常的诊断过程中,对应用指标监测、分析的同时,快速调阅主机指标数据,快速分析业务异常与主机指标的关联关系,增强 IT 系统监控、诊断的全面性和工作效率。
01|DeepFlow 主机指标集成方案
整体架构
本次实践中,使用 DeepFlow Agent + Grafana Alloy 在 CentOS 环境中实现了主机指标数据的快速集成,要点包括:
- Alloy 的 unix_exporter 模块采集主机指标数据;
- Alloy 通过 Prometheus Remote Write 接口将采集的主机指标数据发送到 DeepFlow Agent;
- DeepFlow Agent 接收到主机指标数据后,与各类观测数据统一回送到 DeepFlow Server;
- DeepFlow Server 对各类观测数据打上统一的标签,并构建统一的数据观测能力。
![]()
主机指标数据集成部署架构
部署 DeepFlow Agent
安装指导链接[1]
部署并运行后,DeepFlow Agent 开始对云端 K8s 集群中的应用服务进行零侵扰的 eBPF 数据采集,支持获取的数据主要包括:
- 应用调用的 RED 指标(支持的应用协议详见链接[2])
- 分布式调用链追踪数据
- 应用实例 CPU、Memory Profiling 数据
- 慢文件读写事件
- 网络流量的 L3 吞吐、L4 吞吐、TCP 性能、TCP 异常、TCP 时延等指标
同时 DeepFlow Agent 默认开启数据集成接口(默认端口号为 38086)用于其他 Metrics、Tracing、Logging、Profiling 等数据的接收,其中用于 Prometheus 指标数据 Remote Write 的接口 API 为:/api/v1/prometheus。
部署 Grafana Alloy
第 1 步:安装 Grafana Alloy
安装指导链接[3]
第 2 步:修改运行配置文件
cat << EOF > /etc/alloy/config.alloy
logging {
level = "warn"
}
prometheus.exporter.unix "local_system" {
include_exporter_metrics = true
disable_collectors = ["mdadm"]
}
prometheus.scrape "scrape_metrics" {
targets = prometheus.exporter.unix.local_system.targets
forward_to = [prometheus.relabel.filter_metrics.receiver]
scrape_interval = "10s"
}
prometheus.relabel "filter_metrics" {
rule {
action = "replace"
replacement = "IP_OF_HOST"
target_label = "instance"
}
forward_to = [prometheus.remote_write.deepflowagent.receiver]
}
prometheus.remote_write "deepflowagent" {
endpoint {
url = "http://127.0.0.1:38086/api/v1/prometheus"
}
}
EOF
DEFAULT_INTERFACE=$(ip route | grep default | awk '{print $5}')
DEFAULT_IP=$(ip -4 addr show $DEFAULT_INTERFACE | grep -oP '(?<=inet\s)\d+(\.\d+){3}')
sed -i "s|IP_OF_HOST|$DEFAULT_IP|g" /etc/alloy/config.alloy
DeepFlow Server 收到 DeepFlow Agent 回送的 Metrics 数据后,会尝试根据数据中的 instance 标签值标记更多的 DeepFlow 原生的可观测性标签(比如 chost、vpc、az、cloud、region 等),因此在 Metrics 数据集成时,上述 "filter_metrics" 的 "relabel" 策略用于确保 instance 填入正确的主机 IP。否则,在 DeepFlow 平台中将产生数据孤岛,且只能通过 tag.instance、tag.agent_hostname、tag.*** 等原生 Prometheus 标签检索分析所集成的 Metrics 数据。
第 3 步:启动服务
sudo systemctl start alloy
sudo systemctl enable alloy
(可选步骤)检查服务状态
sudo systemctl status alloy -l
(可选步骤)检查运行日志
sudo journalctl -u alloy -e
02|统一观测效果
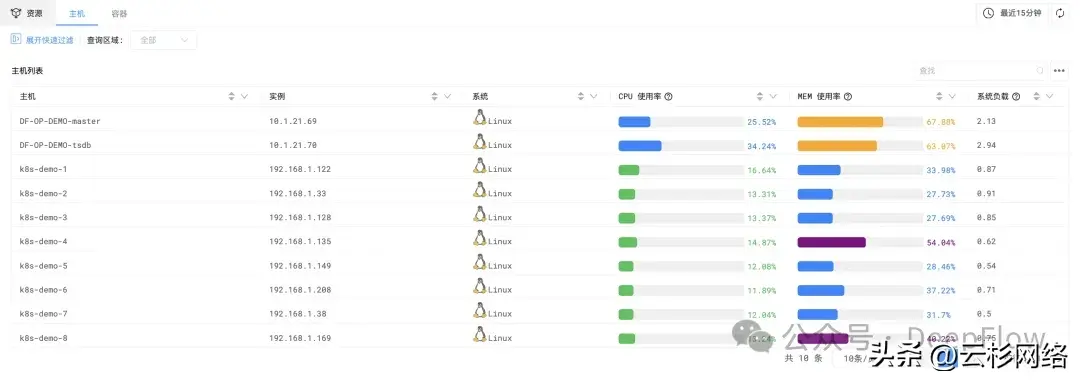
主机指标列表监控
进入 DeepFlow 中的指标-主机功能入口,可以快速调阅所有主机的 CPU 使用率、MEM 使用率、系统负载,用于对 IT 系统全部主机状态的快速浏览。
![]()
主机列表监控
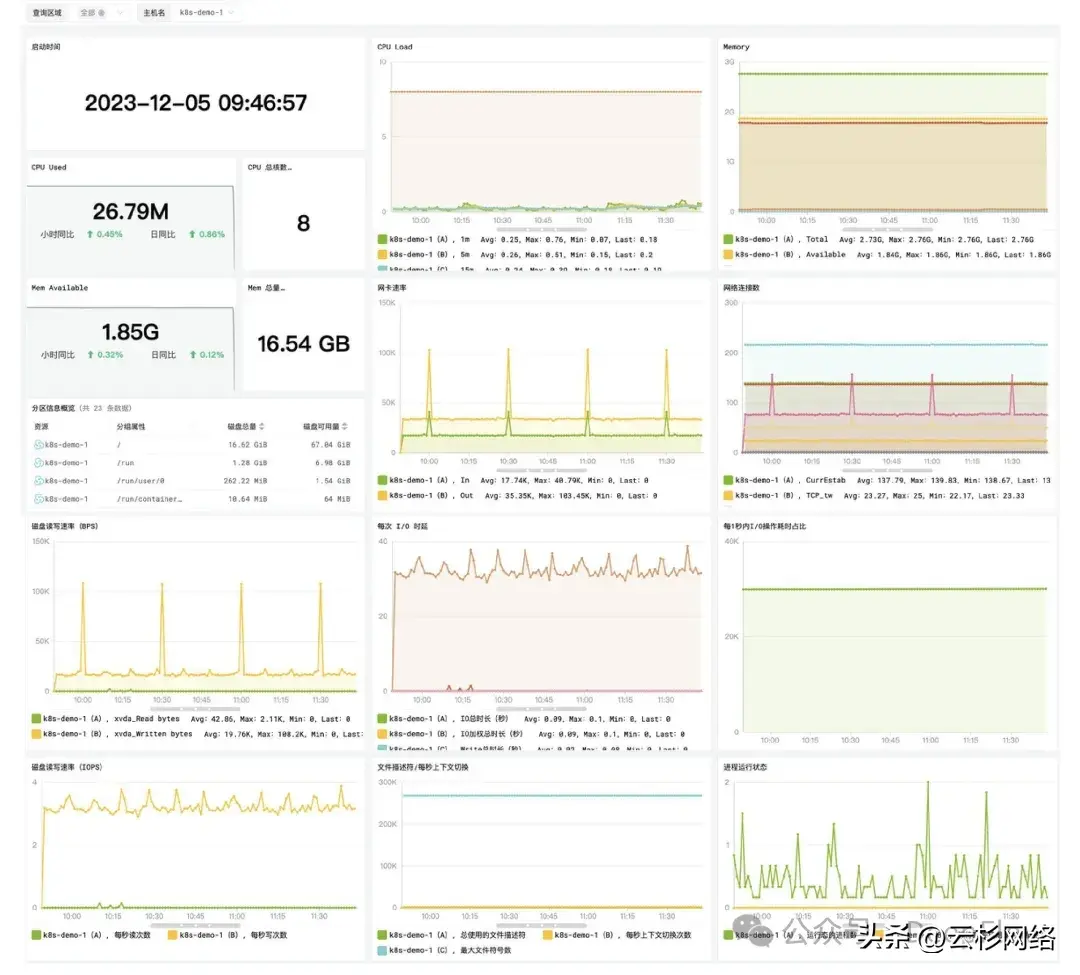
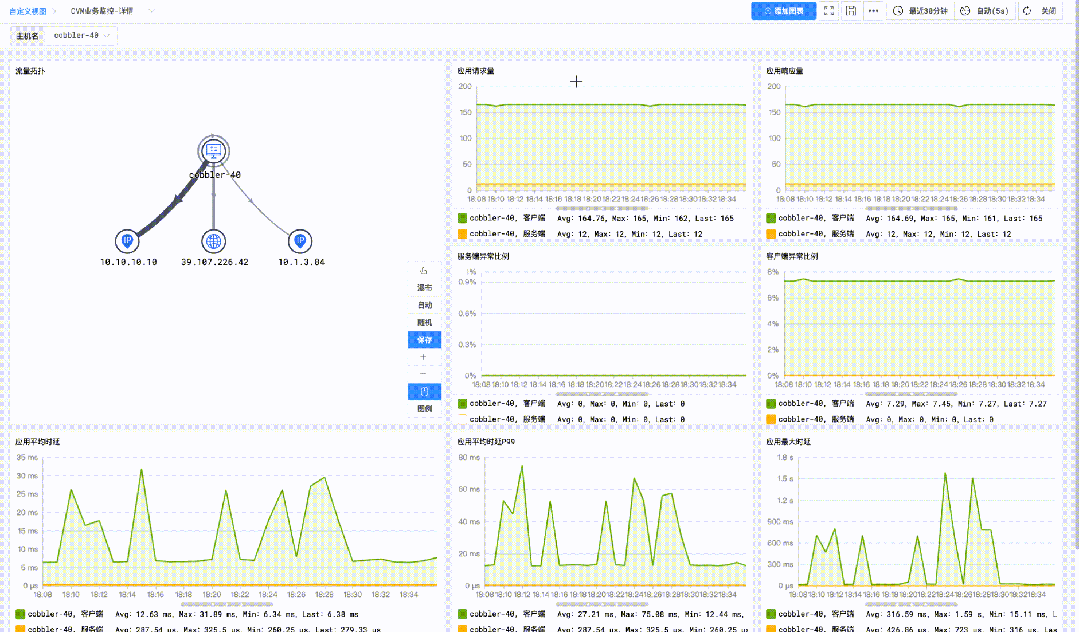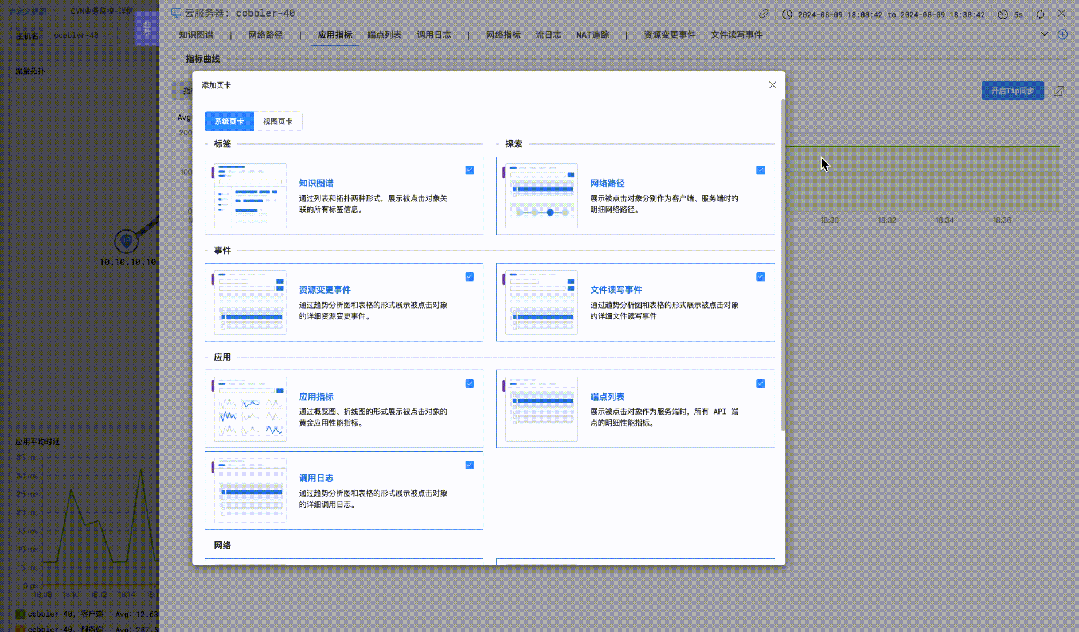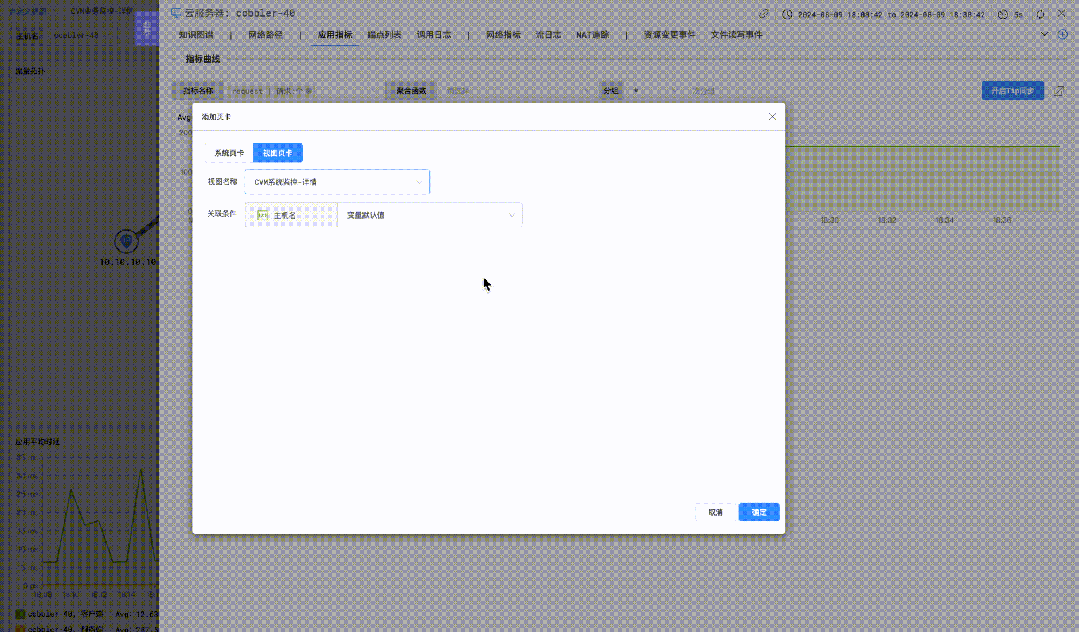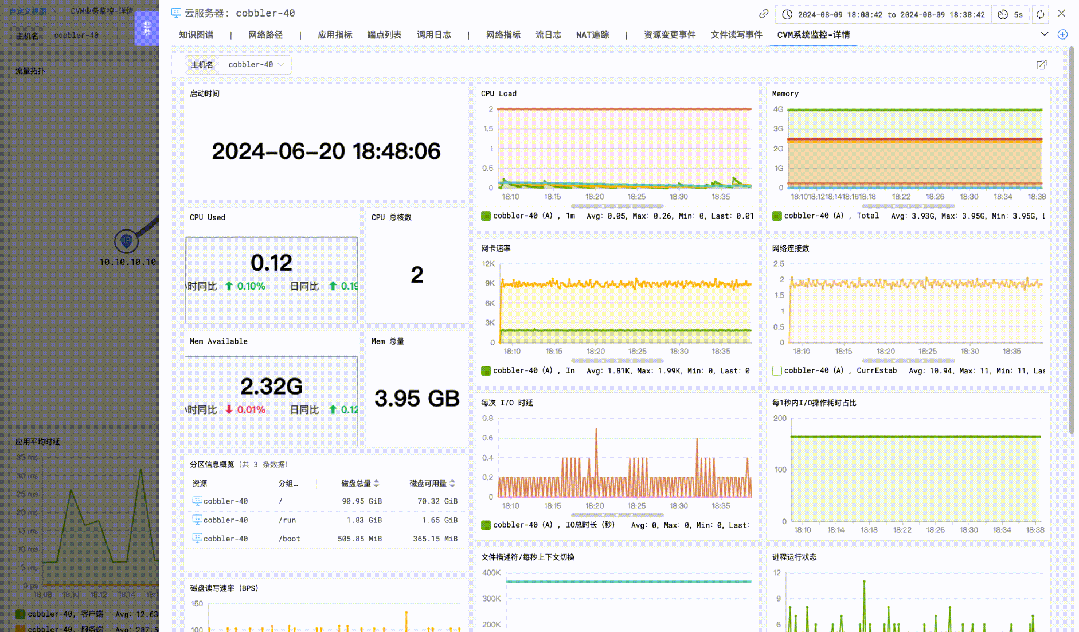
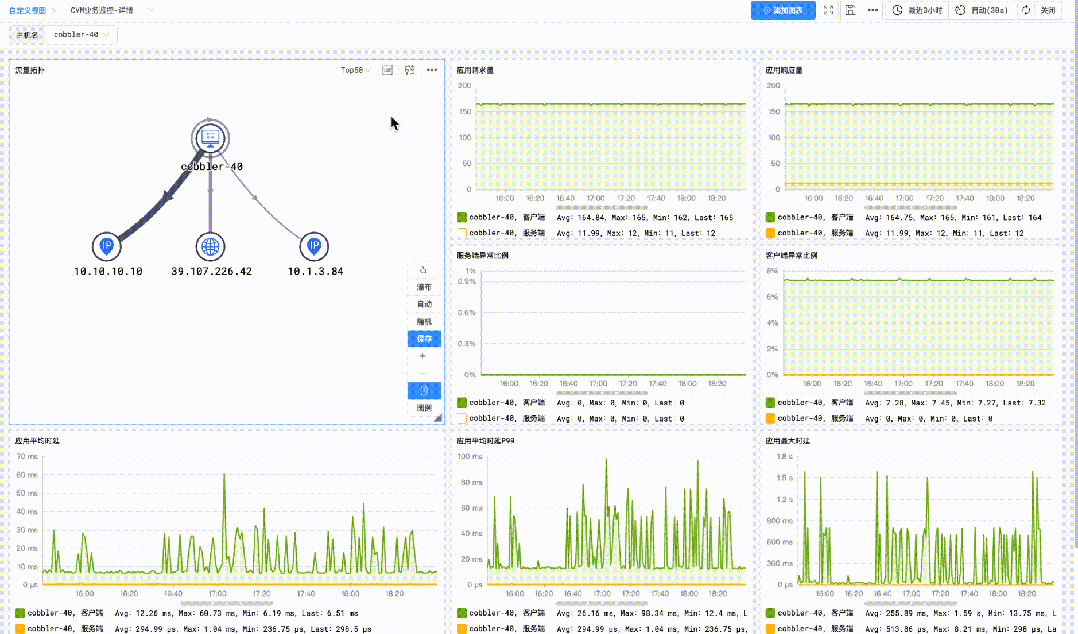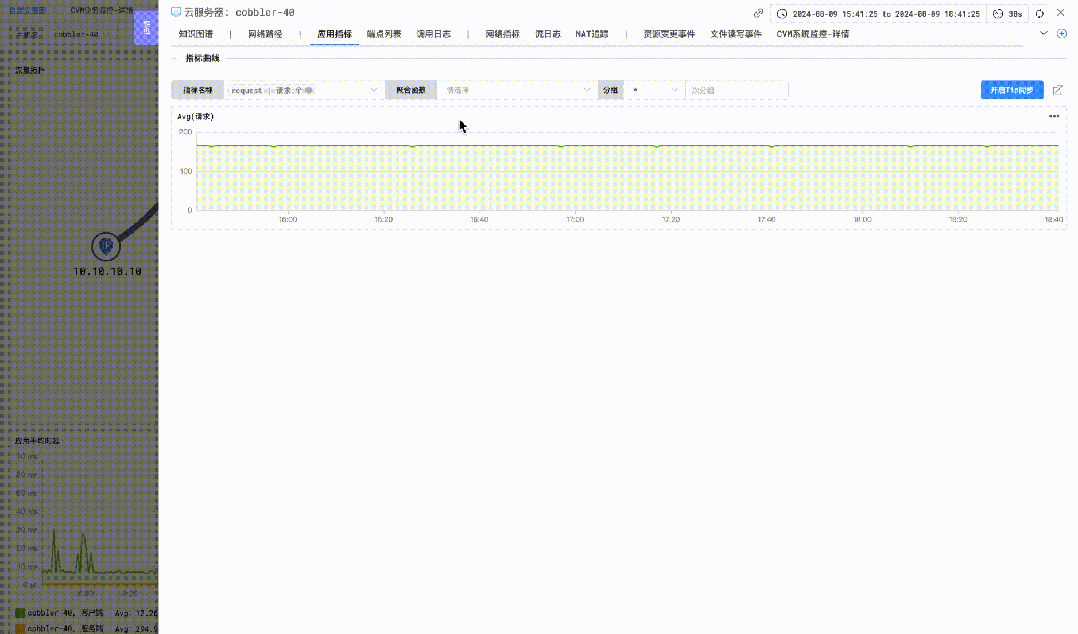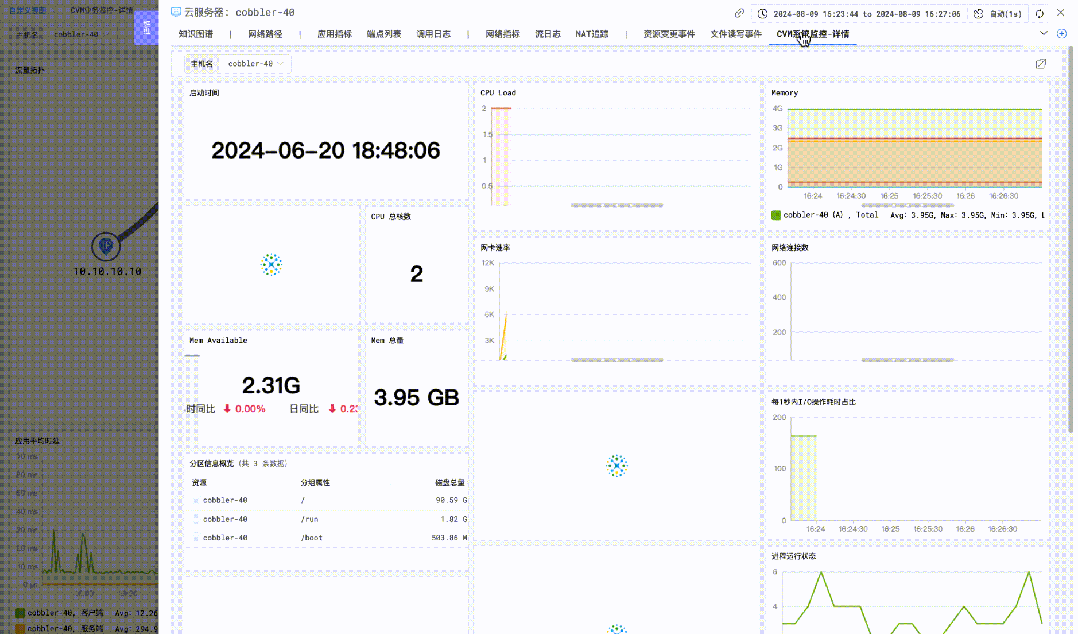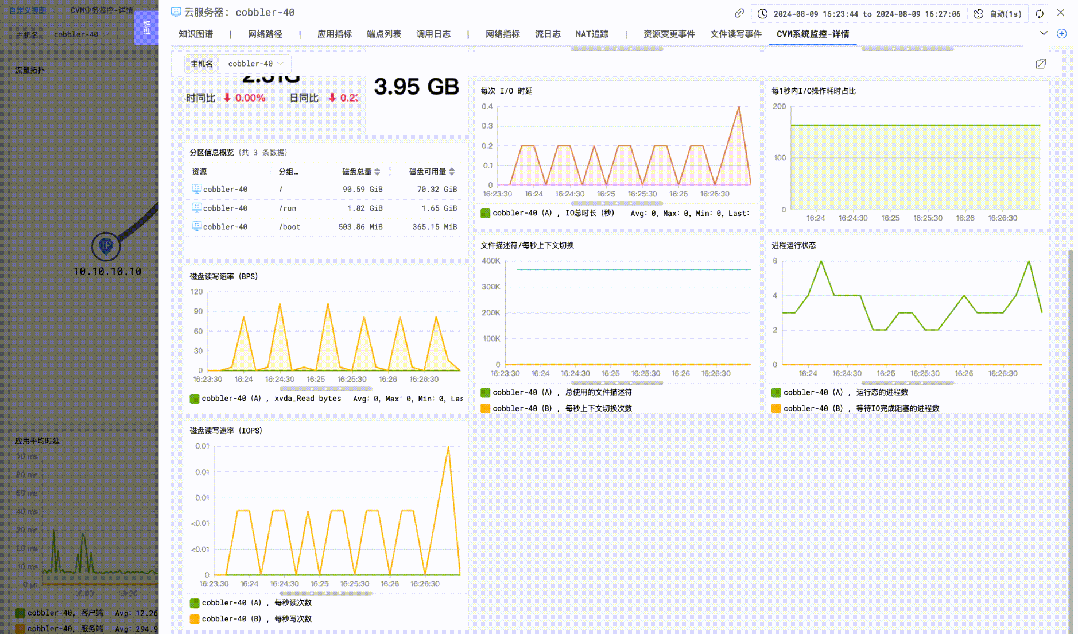
主机指标详情监控
进入 DeepFlow 中的视图功能入口,可以通过内置的「主机指标详情监控」视图观测更详细的主机指标。
详情监控视图主要包括 CPU、内存、负载、磁盘、文件 IO、网络、进程等相关的监测指标曲线。
![]()
主机指标详情监控
应用观测与主机指标观测的统一
在此基础之上,还可以将内置的「主机指标详情监控」 添加到应用监控子视图的「右滑窗」中,当发现应用指标异常时,便可以在「右滑窗」中一键调阅主机指标详情,快速诊断主机性能与应用服务异常的关联关系。
应用监控子视图「右滑窗」定制「主机指标监控视图」的方法
![]()
应用监控子视图右滑窗定制
应用监控子视图「右滑窗」定制「主机指标监控视图」后的统一观测效果
![]()
统一观测使用效果
03|什么是 DeepFlow
DeepFlow 是云杉网络开发的一款可观测性产品,旨在为复杂的云原生及 AI 应用提供深度可观测性。DeepFlow 基于 eBPF 实现了应用性能指标、分布式追踪、持续性能剖析等观测信号的零侵扰(Zero Code)采集,并结合智能标签(SmartEncoding)技术实现了所有观测信号的全栈(Full Stack)关联和高效存取。使用 DeepFlow,可以让云原生及 AI 应用自动具有深度可观测性,从而消除开发者不断插桩的沉重负担,并为 DevOps/SRE 团队提供从代码到基础设施的监控及诊断能力。
GitHub 地址:https://github.com/deepflowio/deepflow
访问 DeepFlow Demo[4],体验零侵扰、全栈的可观测性。
参考资料
[1]DeepFlow Agent 安装指导链接:
https://www.deepflow.io/docs/zh/ee-install/saas/cloud-host/
[2]应用调用的 RED 指标支持应用协议:
https://www.deepflow.io/docs/zh/features/l7-protocols/overview/
[3]安装 Grafana Alloy 链接:
https://grafana.com/docs/alloy/latest/set-up/install/linux/
[4]DeepFlow Demo: https://deepflow.io/docs/zh/ce-install/overview/
欢迎报名参与8月24日·DeepFlow可观测性Meetup·广州站,本次活动聚焦可观测领域,来自 DeepFlow、Greptime、腾讯云等多位可观测领域行业专家将一起深入探讨可观测领域的创新技术解决方案。