一、前言
随着近几年得物的业务和技术的快速发展,我们不管是在面向C端场景还是B端供应链;业务版本的迭代更新,技术架构的不断升级;不管是业务稳定性还是架构稳定性,业务灰度的能力对我们来说都是一项重要的技术保障,越来越受到我们业务研发的关注。然而,传统的灰度发布服务往往过于定制化,缺乏灵活性和通用性,无法满足不断变化的业务需求,往往灰度的场景可能通过代码硬编码或者简单的配置中心配置。在这样的背景下,本文将介绍一种全新的、轻量级的灰度平台,它将为大家的业务带来全新的灰度体验。
二、总体架构设计
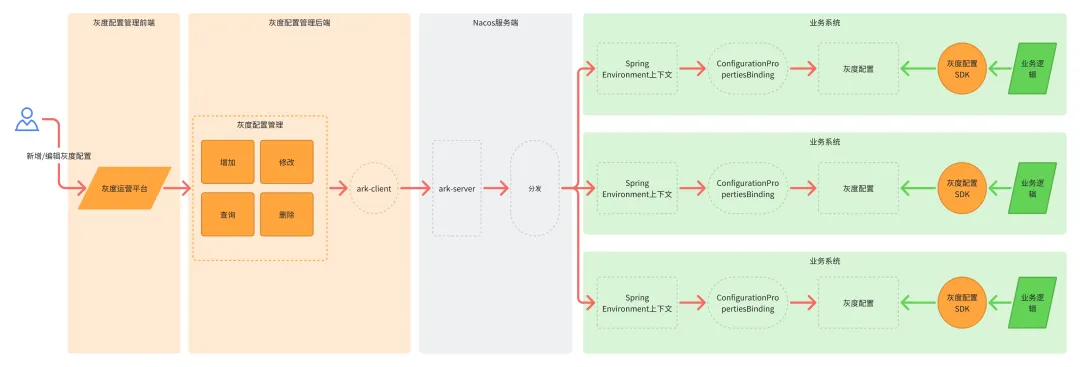
![01.jpg]()
整体架构模块的概览
主要由如下模块组成:
-
灰度运营平台:为用户提供增删查改的灰度发布管理和UI界面;
-
灰度服务端:为灰度运营平台提供标准的增删查改功能、权限控制、灰度场景管理和应用接入命名空间;
-
Nacos&Ark: 提供高性能的灰度配置读取和存储服务;
-
灰度SDK: 为研发提供轻量级高性能的灰度判断API和配置服务。
功能特性说明:
-
系统灰度开关可以在后台运营页面上进行可视化管理;
-
配置类型可以支持多种开关、灰度、业务配置;
-
配置的值可以采用富文本形式来进行编辑;
-
能够支持自定义维度白名单的方式进行灰度;
-
能够支持自定义多个分组的方式进行灰度;
-
能够支持自定义分组实验的方式进行灰度;
-
能够支持按照指定维度 以一定比例进行灰度;
-
能够支持自定义维度进行灰度配置;
-
能够支持历史配置一键回滚和追溯配置;
-
能够方便灰度配置信息进行生命周期管理。
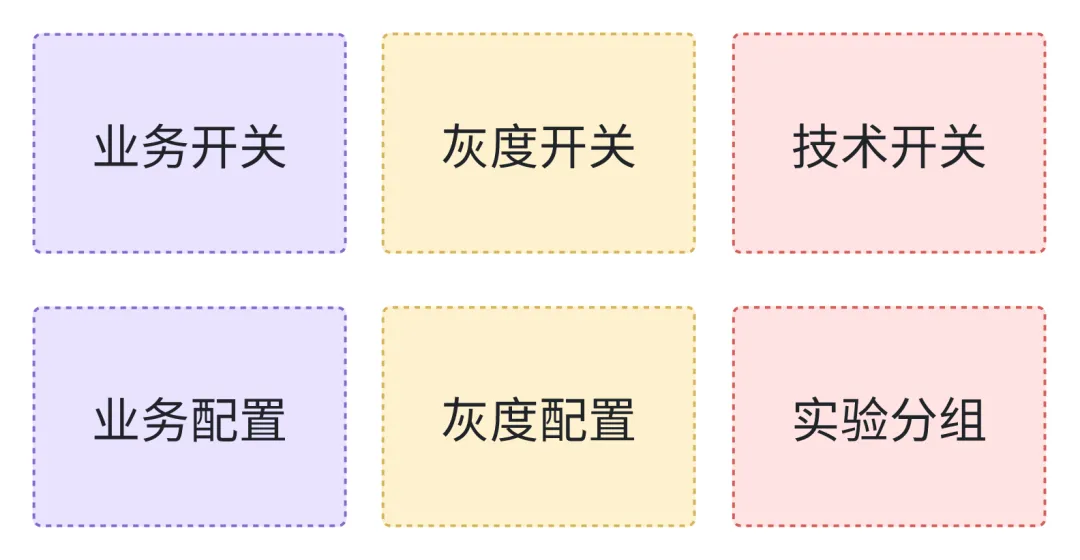
适用的场景:
![02.jpg]()
三、灰度服务关键设计
我们参考上面的总体架构设计可知,灰度配置的存储不是关键,复用已有的Nacos等或者自研的配置服务中心即可,重点是在SDK和灰度数据结构的设计上。
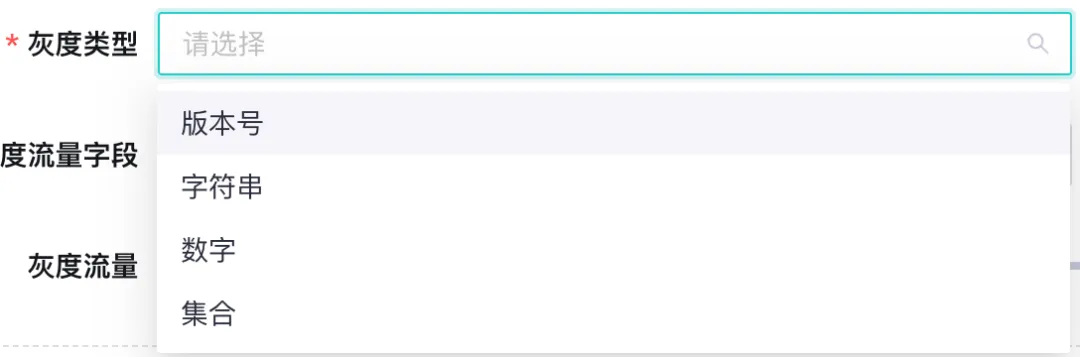
灰度数据类型设计
首先我们针对不同的场景可能会遇到不同的数据类型灰度,不同的数据类型在规则处理中可能也有特点场景的实现,所以先定义灰度数据类型参考如下:
/**
* 版本号
*/
VERSION("version"),
/**
* 字符串类型
*/
STRING("string"),
/**
* 集合类型
*/
SEGMENT("segment"),
/**
* 数字类型
*/
NUMBER("number"),
/**
* 非法规则
*/
NONE("none"),
;
![03.jpg]()
灰度规则设计
有了灰度数据类型的定义,我们需要针对不同的字段数据类型使用不同的灰度规则,如包含关系、完全匹配、正则表达式等。于是就可以自定义各种规则,根据实际的业务场景抽象,规则完全可以再自定义。
IS_IN("in"),
IS_NOT_IN("notIn"),
REGEX("regex"),
NREGEX("nregex"),
EQ("eq"),
NEQ("neq"),
EQUAL_TO("="),
NOT_EQUAL_TO("!="),
GREATER_THAN(">"),
GREATER_OR_EQUAL(">="),
LESS_THAN("<"),
LESS_OR_EQUAL("<="),
NONE("none"),
![04.jpg]()
灰度类型实现的规则对应级联关系:
![05.jpg]()
![06.jpg]()
![07.jpg]()
![08.jpg]()
简单灰度触发器模型
根据上面定义的数据结构和灰度规则,很容易抽象出我们需要定义的灰度模型,简单数据结构参考如下:
[@Data](https://my.oschina.net/difrik)
@NoArgsConstructor
public class Toggle implements Serializable {
/**
* 默认不配置该字段,如果启用该字段fullGray=1,则全量开关不进行后续的版本判断
*/
private Integer fullGray = 0;
/**
* 是否生效;1:生效;0:不生效
*/
private Integer enabled = 1;
/**
* 规则列表,每一项都是或的关系
*/
private List<Rule> rules;
/**
* 规则列表
* 每一项是或的关系
*/
[@Data](https://my.oschina.net/difrik)
public static class Rule implements Serializable {
/**
* 规则字段条件,每一项是且的关系
*/
private List<Condition> conditions;
}
/**
* 条件列表
*/
[@Data](https://my.oschina.net/difrik)
public static class Condition implements Serializable {
/**
* 规则解析类型
*
* [@see](https://my.oschina.net/weimingwei) ConditionType
*/
private String type;
/**
* 规则解析字段
*
* @see GrayFields
*/
private String subject;
/**
* 条件判断
*
* @see PredicateType
*/
private String predicate;
/**
* 条件判断内容
*/
private List<Object> objects;
}
}
灰度触发器模型和规则实现
灵活的灰度规则实现,我们针对以上定义的好的数据模型和灰度规则需要进行映射实现。整体的架构实现需要考虑,每新增一种规则实现代码量都非常少,极具扩展性,后续如有不满足的规则场景也容易扩展。
定义灰度规则匹配器:
public interface Matcher {
ConditionType getConditionType();
Map<PredicateType, PredicateMatcher> getPredicateMatcher();
}
数字类型灰度规则匹配
/**
* 数字类型匹配
*/
@Component
public class NumberMatch implements Matcher {
@Override
public ConditionType getConditionType() {
return ConditionType.NUMBER;
}
@Override
public Map<PredicateType, PredicateMatcher> getPredicateMatcher() {
EnumMap<PredicateType, PredicateMatcher> matcherEnumMap = new EnumMap<>(PredicateType.class);
matcherEnumMap.put(PredicateType.EQUAL_TO, ((target, objects) -> objects.stream()
.filter(Objects::nonNull)
.map(Objects::toString)
.filter(StringUtils::isNotBlank)
.map(Long::valueOf)
.anyMatch(t -> Objects.equals(Long.valueOf(String.valueOf(target)), t))));
// ...... 此处后续的代码省略,设计和上面的实现雷同....
return matcherEnumMap;
}
}
字符串类型灰度规则匹配
/**
* 字符串匹配
*/
@Component
public class StringMatch implements Matcher {
@Override
public ConditionType getConditionType() {
return ConditionType.STRING;
}
@Override
public Map<PredicateType, PredicateMatcher> getPredicateMatcher() {
EnumMap<PredicateType, PredicateMatcher> matcherEnumMap = new EnumMap<>(PredicateType.class);
matcherEnumMap.put(PredicateType.EQ, ((target, objects) -> objects.stream()
.filter(Objects::nonNull)
.map(Objects::toString)
.filter(StringUtils::isNotBlank)
.anyMatch(t -> String.valueOf(target).equalsIgnoreCase(t))));
// ...... 此处后续的代码省略,设计和上面的实现雷同....
return matcherEnumMap;
}
}
客户端版本号灰度规则类型匹配
/**
* @author feel
*/
@Component
public class VersionMatch implements Matcher {
@Override
public ConditionType getConditionType() {
return ConditionType.VERSION;
}
@Override
public Map<PredicateType, PredicateMatcher> getPredicateMatcher() {
EnumMap<PredicateType, PredicateMatcher> matcherEnumMap = new EnumMap<>(PredicateType.class);
matcherEnumMap.put(PredicateType.EQUAL_TO, ((target, objects) -> objects.stream()
.filter(Objects::nonNull)
.map(Objects::toString)
.filter(StringUtils::isNotBlank)
.anyMatch(t -> VersionUtils.compareMajorVersion(String.valueOf(target), t) == 0)));
// ...... 此处后续的代码省略,设计和上面的实现雷同....
return matcherEnumMap;
}
}
复杂集合类型灰度规则匹配
/**
* 集合列表匹配
*/
@Component
public class SegmentMatch implements Matcher {
@Override
public ConditionType getConditionType() {
return ConditionType.SEGMENT;
}
@Override
public Map<PredicateType, PredicateMatcher> getPredicateMatcher() {
EnumMap<PredicateType, PredicateMatcher> matcherEnumMap = new EnumMap<>(PredicateType.class);
matcherEnumMap.put(PredicateType.IS_IN, ((target, objects) -> objects.stream()
.filter(Objects::nonNull)
.map(Objects::toString)
.filter(StringUtils::isNotBlank)
.anyMatch(t -> {
if (target instanceof List || target instanceof Set) {
return ((Collection<Object>) target).stream()
.filter(Objects::nonNull)
.map(Objects::toString)
.anyMatch(v -> String.valueOf(v).equalsIgnoreCase(t));
}
return String.valueOf(target).equalsIgnoreCase(t);
})));
// ...... 此处后续的代码省略,设计和上面的实现雷同....
return matcherEnumMap;
}
}
客户端版本号比较算法
目前客户端的版本号存在特殊的灰度版本号,且安卓和iOS由于历史原因存在2套不兼容的情况,我们也做了定制的算法实现。
/**
* 通用版本号比较
* 时间复杂度O(n+m)
* 空间复杂度O(n+m)
*
* @param v1 版本号v1
* @param v2 版本号v2
* @param limit 限制截取长度
* @return
*/
public static int compareVersion(String v1, String v2, Integer limit) {
if (v1 == null || v2 == null) {
return 0;
}
try {
// 处理非法字符和老版本iphone,appversion:"5.16.1(100.0421)" 格式问题
String[] majorV1 = parserPinkAppVersion(v1).split("\\.");
String[] majorV2 = parserPinkAppVersion(v2).split("\\.");
int len = Math.min(Optional.ofNullable(limit)
.orElse(Integer.MAX_VALUE), Math.max(majorV1.length, majorV2.length));
// 一位一位比较,注意:中间不能直接跳出
for (int i = 0; i < len; ++i) {
int x = 0, y = 0;
if (i < majorV1.length) {
x = Integer.parseInt(majorV1[i]);
}
if (i < majorV2.length) {
y = Integer.parseInt(majorV2[i]);
}
if (x > y) {
return 1;
}
if (x < y) {
return -1;
}
}
} catch (NumberFormatException e) {
//ignore
}
return 0;
}
灰度服务SDK接口设计
根据上面的设计,我们也就很容易抽象出一个通用标准的灰度服务接口,打包成SDK供业务研发使用。
/**
* 灰度服务
*/
public interface GrayService {
/**
* 根据灰度场景判断当前请求是否命中灰度
*
* @param sceneKey 灰度场景key
* @param attrs 灰度参数值
* @return
*/
boolean hitGray(String sceneKey, Map<String, Object> attrs);
/**
* 根据规则配置命中灰度
*
* @param toggle
* @param attrs
* @return
*/
boolean hitGray(Toggle toggle, Map<String, Object> attrs);
/**
* 根据灰度场景key判断当前请求命中的的实验分组
*
* @param sceneKey 灰度场景key
* @param attrs 灰度参数值
* @return
* @see MapValueUtils 配置值的获取可以使用该工具方法
*/
HitResult hitExperimentGroup(String sceneKey, Map<String, Object> attrs);
/**
* 根据灰度场景key指定实验分组key,如果命中则返回命中分组都对应的配置;如果没有命中,则配置重置为空字符
*
* @param sceneKey 灰度场景key
* @param experimentGroupKey 实验分组KEY
* @param attrs 灰度参数值
* @return
* @see MapValueUtils 配置值的获取可以使用该工具方法
*/
HitResult hitExperimentGroup(String sceneKey, String experimentGroupKey, Map<String, Object> attrs);
}
四、配置服务关键设计
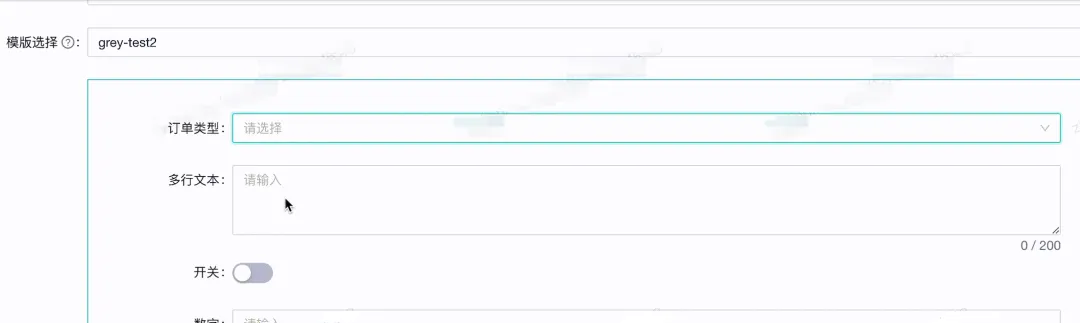
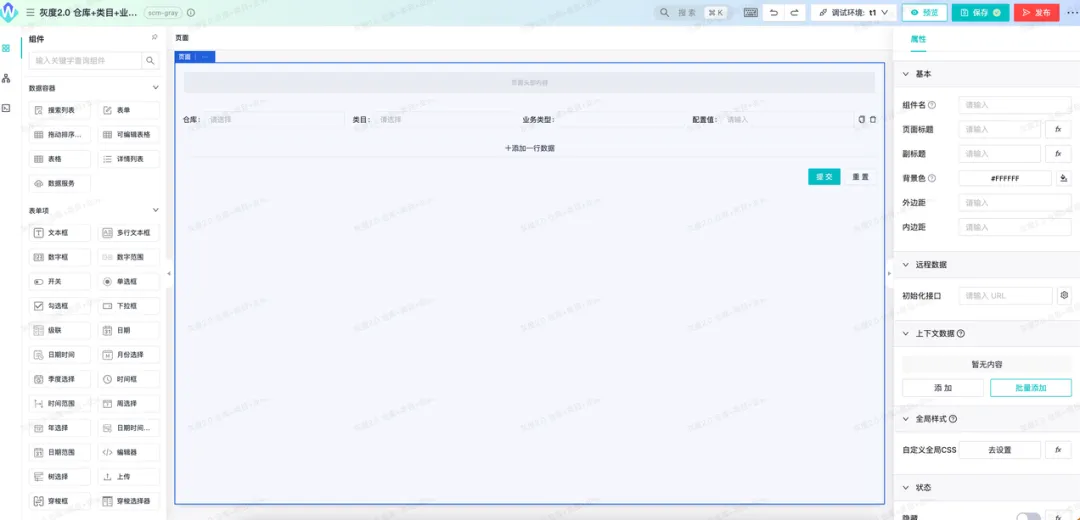
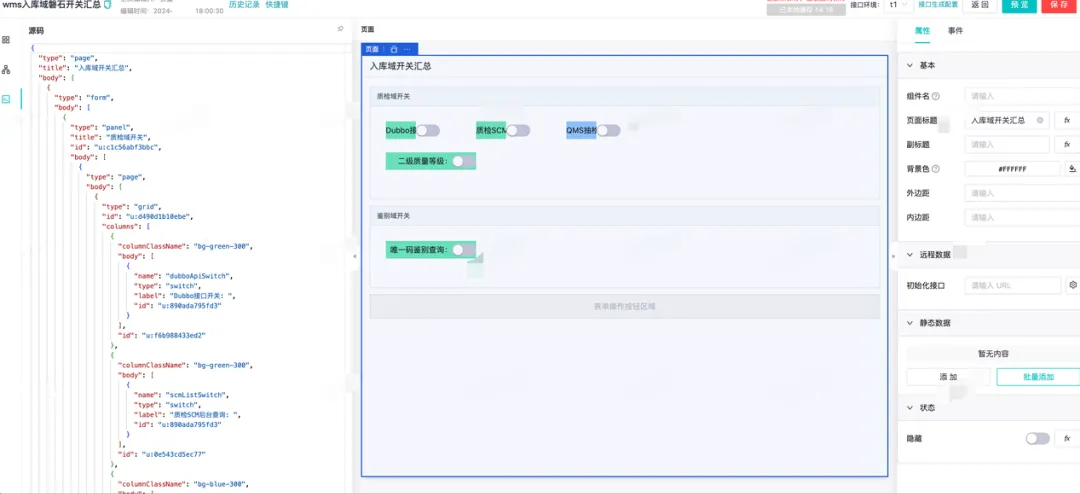
我们很多业务类型场景自定义的配置,早期的设计都是存放在Nacos或者Ark配置平台上。这种配置存在只能面向研发等局限性,尤其在配置复杂时,修改过程需要特别谨慎。为了解决这个问题,我们设计了面向研发和业务的可视化动态表单的配置方式,集成现成的页面表单搭建技术平台或动态表单技术平台,使得配置可以以可视化的形式展示。
配置可视化设计集成
![09.jpg]()
![10.jpg]()
这是我们内部页面表单搭建技术,通过简单配置或者拖拽的方式进行自定义表单。
![11.jpg]()
![12.jpg]()
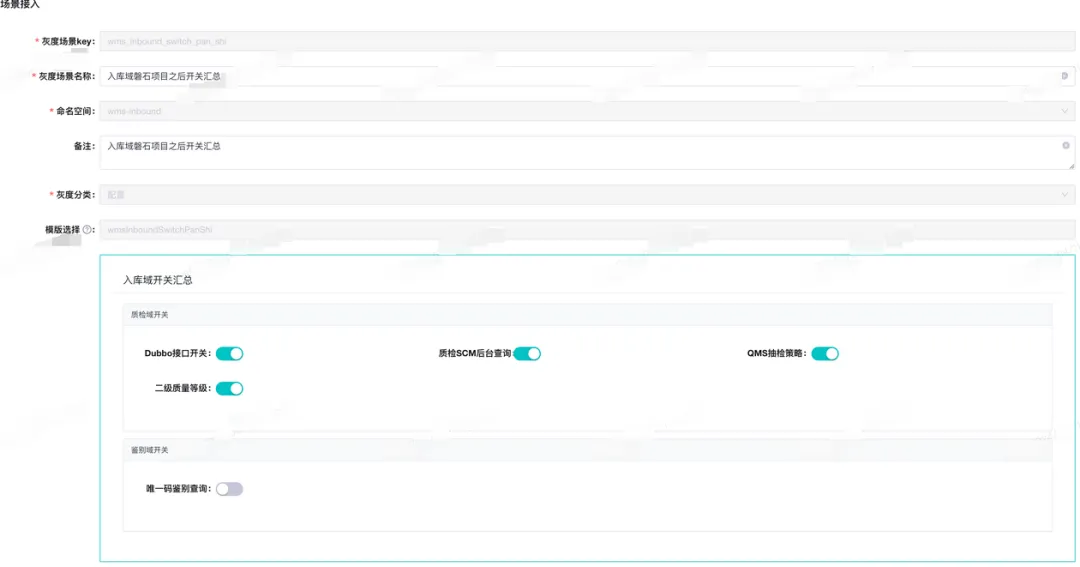
最后在灰度配置里面选择关联上对应的表单模版即可。
![13.jpg]()
灰度服务的接口抽象
/**
* 配置服务
*/
public interface GrayConfigService {
/**
* 获取配置JSON VALUE
*
* @param sceneKey
* @return
*/
String getConfigValue(String sceneKey);
/**
* 根据场景key获取String类型值
*
* @param sceneKey 配置开关配置key
* @param pathKey 字段key,支持路径path查找;字段是"$."前缀表示,则优先使用JSONPATH解析<a href="https://gotest.hz.netease.com/doc/jie-kou-ce-shi/xin-zeng-yong-li/can-shu-xiao-yan/jsonpi-pei/jsonpathyu-fa.html">jsonpath使用用例</a>
* @param defaultValue 默认值
* @return
*/
String getStringValue(String sceneKey, String pathKey, String defaultValue);
/**
* 根据场景key获取boolean类型值
*
* @param sceneKey 配置开关配置key
* @param pathKey 字段key,支持路径path查找;字段是"$."前缀表示,则优先使用JSONPATH解析<a href="https://gotest.hz.netease.com/doc/jie-kou-ce-shi/xin-zeng-yong-li/can-shu-xiao-yan/jsonpi-pei/jsonpathyu-fa.html">jsonpath使用用例</a>
* @param defaultValue 默认值
* @return
*/
boolean getBooleanValue(String sceneKey, String pathKey, boolean defaultValue);
/**
* 根据场景key获取Integer类型值
*
* @param sceneKey 配置开关配置key
* @param pathKey 字段key,支持路径path查找;字段是"$."前缀表示,则优先使用JSONPATH解析<a href="https://gotest.hz.netease.com/doc/jie-kou-ce-shi/xin-zeng-yong-li/can-shu-xiao-yan/jsonpi-pei/jsonpathyu-fa.html">jsonpath使用用例</a>
* @param defaultValue 默认值
* @return
*/
Integer getIntegerValue(String sceneKey, String pathKey, Integer defaultValue);
/**
* 根据场景key获取Long类型值
*
* @param sceneKey 配置开关配置key
* @param pathKey 字段key,支持路径path查找;字段是"$."前缀表示,则优先使用JSONPATH解析<a href="https://gotest.hz.netease.com/doc/jie-kou-ce-shi/xin-zeng-yong-li/can-shu-xiao-yan/jsonpi-pei/jsonpathyu-fa.html">jsonpath使用用例</a>
* @param defaultValue 默认值
* @return
*/
Long getLongValue(String sceneKey, String pathKey, Long defaultValue);
/**
* 根据场景key获取String类型值
*
* @param sceneKey 配置开关配置key
* @param pathKey 字段key,支持路径path查找;字段是"$."前缀表示,则优先使用JSONPATH解析<a href="https://gotest.hz.netease.com/doc/jie-kou-ce-shi/xin-zeng-yong-li/can-shu-xiao-yan/jsonpi-pei/jsonpathyu-fa.html">jsonpath使用用例</a>
* @param defaultValue 默认值
* @return
*/
Double getDoubleValue(String sceneKey, String pathKey, Double defaultValue);
/**
* 根据场景key获取BigDecimal类型值
*
* @param sceneKey 配置开关配置key
* @param pathKey 字段key,支持路径path查找;字段是"$."前缀表示,则优先使用JSONPATH解析<a href="https://gotest.hz.netease.com/doc/jie-kou-ce-shi/xin-zeng-yong-li/can-shu-xiao-yan/jsonpi-pei/jsonpathyu-fa.html">jsonpath使用用例</a>
* @param scale 精度
* @return
*/
BigDecimal getBigDecimalValue(String sceneKey, String pathKey, int scale);
/**
* 根据场景key获取String类型值
*
* @param sceneKey 配置开关配置key
* @param pathKey 字段key,支持路径path查找;字段是"$."前缀表示,则优先使用JSONPATH解析<a href="https://gotest.hz.netease.com/doc/jie-kou-ce-shi/xin-zeng-yong-li/can-shu-xiao-yan/jsonpi-pei/jsonpathyu-fa.html">jsonpath使用用例</a>
* @return
*/
JSONArray getJSONArrayValue(String sceneKey, String pathKey);
/**
* 获取配置JSONObject
*
* @param sceneKey
* @return
*/
JSONObject getConfigJSONObject(String sceneKey);
/**
* 获取配置反序列化对象
*
* @param sceneKey
* @param targetClass
* @param <T>
* @return
*/
<T> T getConfigObject(String sceneKey, Class<T> targetClass);
}
五、稳定的百分比流量调控
我们在场景使用过程中需要实现精确到万分之一的比例调控,session会话稳定,同样的上下文多次请求,命中的结果不变。设计开1万个分桶,分桶算法的实现使用了murmur3_32。
![14.jpg]()
/**
* 高性能的hash分桶算法
*/
private static final HashFunction murmur3 = Hashing.murmur3_32();
/**
* 100_00个分桶
*/
private static final int bucket = 100_00;
/**
* 稳定的流量分桶算法
* 用来调控灰度流量比例
*
* @param attrsContext
* @param bucketKey
* @param rate
* @return
*/
public boolean hitBucket(Map<String, Object> attrsContext, String bucketKey, Integer rate) {
// 全量
if (Objects.equals(Optional.ofNullable(rate).orElse(bucket), bucket)) {
return true;
}
// 灰度流量比例为0
if (Objects.equals(Optional.ofNullable(rate).orElse(bucket), 0)) {
return false;
}
String bucketValue = Optional.ofNullable(attrsContext)
.map(v -> v.get(bucketKey))
.filter(Objects::nonNull)
.map(String::valueOf)
.filter(StringUtils::isNotBlank)
.orElse(String.valueOf(System.currentTimeMillis()));
// [0,10000)
int hash = Hashing.consistentHash(murmur3.hashString(bucketValue, Charsets.UTF_8), bucket);
int rateLimit = bucket;
if (rate >= 0 && rate <= bucket) {
rateLimit = rate;
}
return hash <= rateLimit;
}
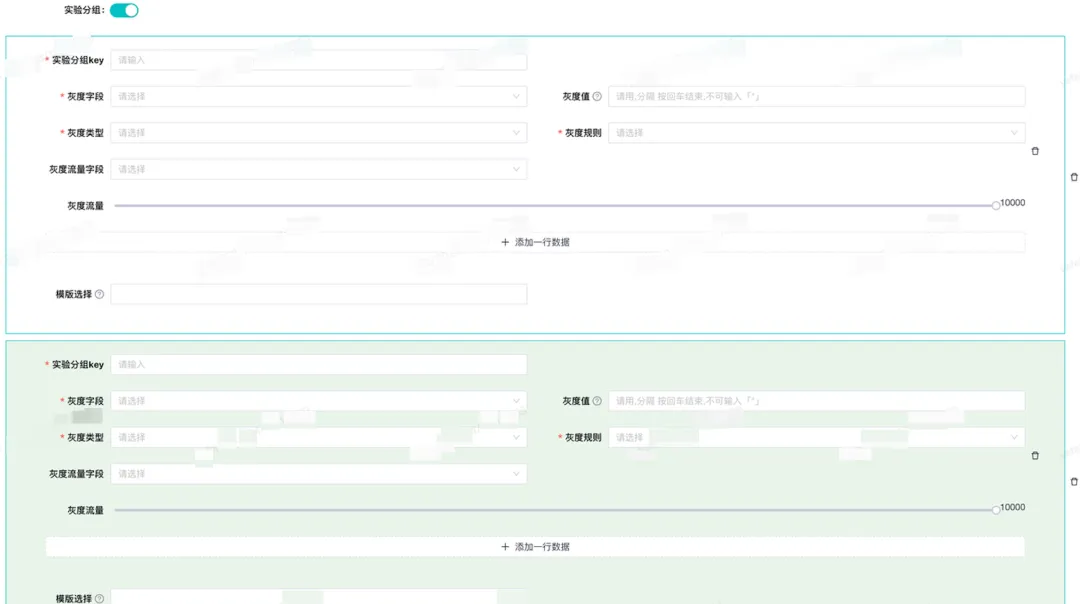
六、灰度分组设计
使用场景一:自定义的灰度规则有多个,每一组都是或的关系,我们需要设计多个灰度分组条件命中;
使用场景二:当有多个灰度分组实验的时候,我们需要指定命中那个条件分组下的规则。
相关的灰度模型设计参考如下:
public class Toggle implements Serializable {
/**
* 规则列表,每一项都是或的关系
*/
private List<Rule> rules;
/**
* 规则列表
* 每一项是或的关系
*/
@Data
public static class Rule implements Serializable {
..............
}
/**
* 条件列表
*/
@Data
public static class Condition implements Serializable {
.......
}
}
![15.jpg]()
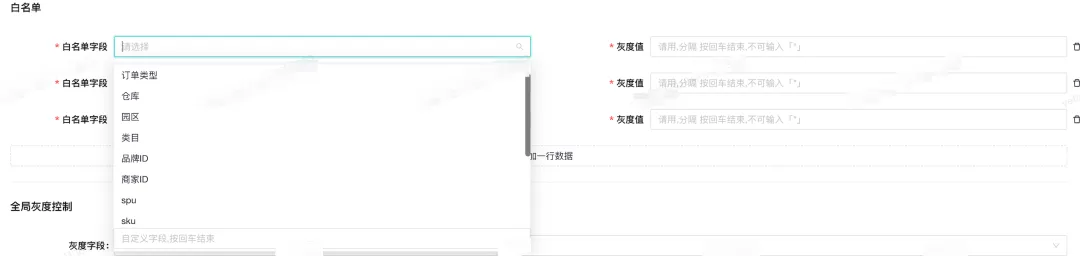
七、白名单设计
有些场景可能需要命中白名单的规则命中全量,无需按照具体的条件命中,这个时候设计一个优先级最高的白名单机制就显得尤为重要。相关数据模型参考如下:
public class Toggle implements Serializable {
/**
* 灰度白名单列表
*/
private List<WhiteList> whiteLists;
/**
* 白名单
* 每一项是或的关系
*/
@Data
public static class WhiteList implements Serializable {
/**
* 白名单解析字段
*
* @see GrayFields
*/
private String subject;
/**
* 白名单内容
*/
private List<Object> values;
}
}
![16.jpg]()
八、其他非功能设计
还有一些非功能性的设计更多是和现有系统能力集成,对接成本和每个公司的技术栈有差异,在此就不展开描述,有兴趣的同学可以自行设计。
九、展望和总结
本文介绍了我们团队所开发的轻量级灰度及配置平台,以及它所带来的创新和优势。通过对业务灰度发布的需求和挑战进行深入剖析,我们意识到传统的灰度服务存在着一系列问题,诸如定制化程度高、缺乏灵活性、无法应对自定义场景等。为解决这些问题,我们研发出了一个高性能轻量级的SDK集成工具,它具有强大的功能,利用表单化的方式实现了灰度服务的产品化能力,使得灰度规则的配置和管理变得简单而直观,大大降低了研发和业务使用的门槛。这个集成工具已经成为我们研发过程中稳定性的三大保障之一,不仅得到了团队的认可,也申请通过了相关专利,目前已被集成到了日常的运营平台中。它的存在使得研发人员和业务使用者能够更轻松地享受到灰度服务的益处。
通过本文,我们希望这个轻量级的灰度配置平台的设计思路对你有所帮助。整体的设计思路非常轻量级,还有很多用户体验和非功能的设计没有在本文中展开描述,这些也并不是这个平台的核心设计内容。如果您有兴趣,可以自行补充;如需进一步的帮助或有其他需求,欢迎随时联系我们。
*文 / feel
本文属得物技术原创,更多精彩文章请看:得物技术
未经得物技术许可严禁转载,否则依法追究法律责任!