一、Disruptor的简介
Disruptor是基于事件异步驱动模型实现的,采用了RingBuffer数据结构,支持高并发、低延时、高吞吐量的高性能工作队列,它是由英国外汇交易公司LMAX开发的,研发的初衷是解决内存队列的延迟问题,不同于我们常用的分布式消息中间件RocketMQ、Kafaka,而Disruptor是单机的、本地内存队列,类似JDK的ArrayBlockingQueue等队列。
Disruptor的使用场景
- 加密货币交易撮合引擎
- Log4j2基于Disruptor实现的异步日志处理
- Canal+Disruptor实现高效的数据同步
- 知名开源框架Apache Strom
2010年在QCon的演讲,介绍了基于Disruptor开发的系统单线程能支撑每秒600万订单,由此可见该组件可以大幅提升系统的TPS,所以对于一些需要大幅提升单机应用的吞吐量的场景可以考虑使用Disruptor。
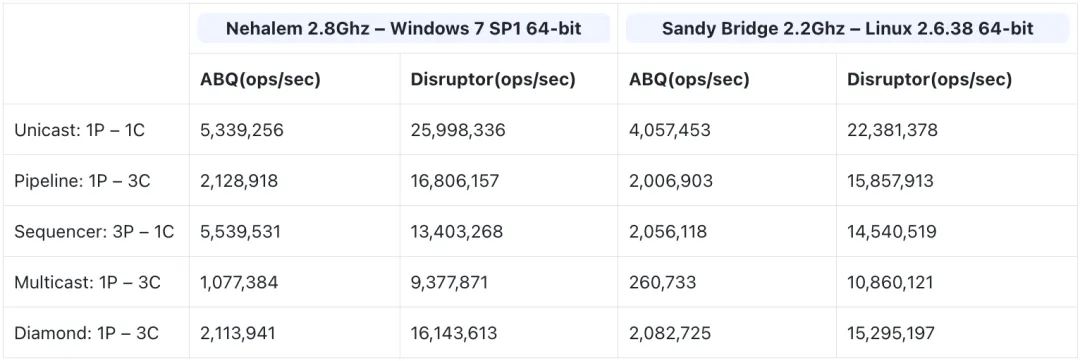
Disruptor和ArrayBlockingQueue性能对比
- ArrayBlockingQueue是基于数组ArrayList实现的,通过ReentrantLock独占锁保证线程安全;
- Disruptor是基于环形数组队列RingBuffer实现的,通过CAS乐观锁保证线程安全。在多种生产者-消费者模式下的性能对比。
![]()
Figure 1. Unicast: 1P--1C
![02.jpg]()
Figure 2. Three Step Pipeline: 1P--3C
![03.jpg]()
Figure 3. Sequencer: 3P--1C
![04.jpg]()
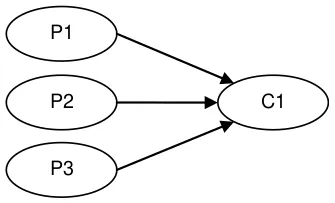
Figure 4. Multicast: 1P--3C
![05.jpg]()
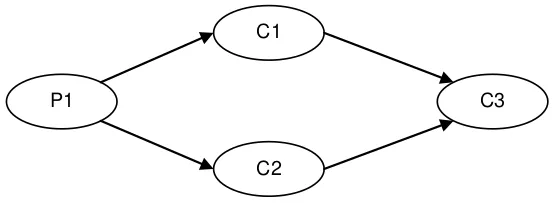
Figure 5. Diamond: 1P--3C
![06.jpg]()
Disruptor快速接入指南
引入Maven依赖
<dependency>
<groupld>com.lmax</groupld>
<artifactld>disruptor</artifactld>
<version>4.0.0</version>
</dependency>
自定义事件和事件工厂
public class LongEvent {
private long value;
public void set(long value) {
this.value = value;
}
[@Override](https://my.oschina.net/u/1162528)
public String toString() {
return "LongEvent{" + "value=" + value + '}';
}
}
public class LongEventFactory implements EventFactory<LongEvent> {
[@Override](https://my.oschina.net/u/1162528)
public LongEvent newInstance() {
return new LongEvent();
}
}
定义事件处理器,即消费者
public class LongEventHandler implements EventHandler<LongEvent> {
[@Override](https://my.oschina.net/u/1162528)
public void onEvent(LongEvent event, long sequence, boolean endOfBatch) {
System.out.println("Event: " + event);
}
}
定义事件生产者
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.examples.longevent.LongEvent;
import java.nio.ByteBuffer;
public class LongEventProducer {
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducer(RingBuffer<LongEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void onData(ByteBuffer bb) {
long sequence = ringBuffer.next();
try {
LongEvent event = ringBuffer.get(sequence);
event.set(bb.getLong(0));
}
finally {
ringBuffer.publish(sequence);
}
}
}
编写启动类
public class LongEventMain {
public static void main(String[] args) throws InterruptedException {
// 消费者线程池
Executor executor = Executors.newCachedThreadPool();
// 事件工厂
LongEventFactory eventFactory = new LongEventFactory();
// 指定RingBuffer大小
int bufferSize = 1024;
// 构造事件分发器
Disruptor<LongEvent> disruptor = new Disruptor<>(eventFactory
, bufferSize
, executor
, ProducerType.SINGLE // 1.ProducerType.SINGLE 单生产者模式 2.ProducerType.MULTI 多生产者模式
, new YieldingWaitStrategy());//消费者等待策略
// 注册消费者
disruptor.handleEventsWith(new LongEventHandler());
// 启动事件分发
disruptor.start();
// 获取RingBuffer 用于生产事件
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
LongEventProducer producer = new LongEventProducer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);
for (long i=0;true; i++) {
bb.putLong(0, i);
// 发送事件
producer.onData(bb);
Thread.sleep(1000);
}
}
}
Disruptor消费者等待策略
等待策略WaitStrategy是一种决定一个消费者如何等待生产者将event对象放入Disruptor的方式/策略。
下面是常见的4种消费者等待策略:
![07.jpg]()
Disruptor灵活的消费者模式
支持单生产者和多生产者
构造Disruptor时指定生产者类型即可:ProducerType.SINGLE 和 ProducerType.MULTI 单消费者
单消费者
//注册单个消费者
disruptor.handleEventsWith(new LongEventHandler());
多消费者:并行的、广播模式
同一个事件会同时被所有消费者处理,同组内消费者之间不存在竞争关系。
//注册多个消费者
disruptor.handleEventsWith(new LongEventHandler()
, new LongEventHandler1()
, new LongEventHandler2());
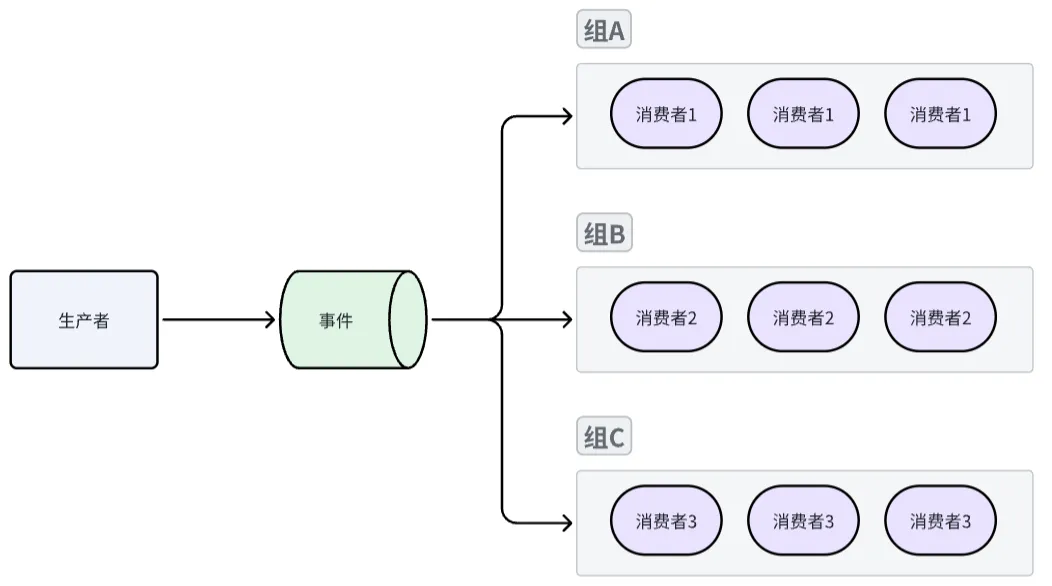
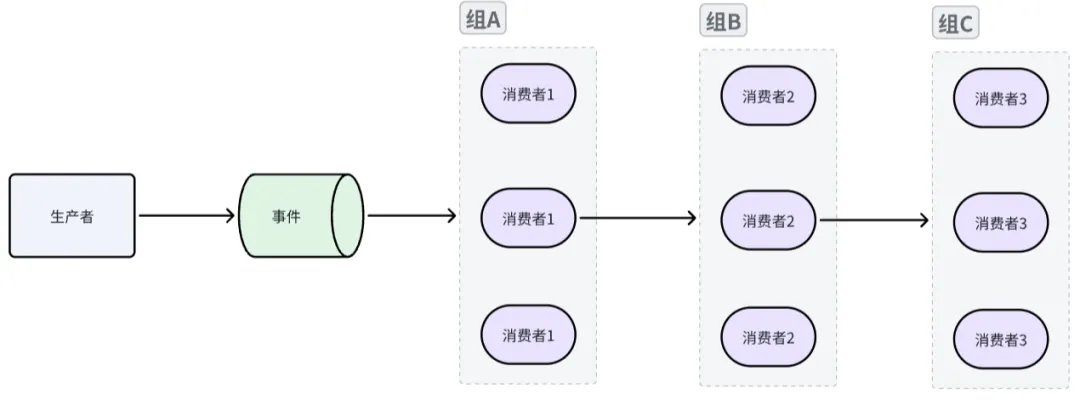
多消费者:并行的、消费者组模式
同组内消费者之间互斥,一个事件只会被同组内单个消费者处理,但可以支持多个消费者组,消费者组之间完全隔离,互不影响,代码实现方式有两点不同之处:
- 消费者需要实现WorkHandler接口,而不是 EventHandler 接口;
- 使用handleEventsWithWorkerPool设置Disruptor的消费者,而不是handleEventsWith方法
public class LongWorkHandler implements WorkHandler<LongEvent> {
[@Override](https://my.oschina.net/u/1162528)
public void onEvent(LongEvent longEvent) throws Exception {
System.out.println("Event: " + logEvent);
}
}
public class OtherWorkHandler implements WorkHandler<LongEvent> {
[@Override](https://my.oschina.net/u/1162528)
public void onEvent(LongEvent longEvent) throws Exception {
System.out.println("Event: " + logEvent);
}
}
//注册消费者组
disruptor.handleEventsWithWorkerPool(new LongWorkHandler()
, new LongWorkHandler()
, new LongWorkHandler());
![08.jpg]()
//注册消费者组1
disruptor.handleEventsWithWorkerPool(new LongWorkHandler()
, new LongWorkHandler()
, new LongWorkHandler());
//注册消费者组2
disruptor.handleEventsWithWorkerPool(new OtherWorkHandler()
, new OtherWorkHandler()
, new OtherWorkHandler());
![09.jpg]()
//注册消费者
disruptor.handleEventsWithWorkerPool(new LongWorkHandler(), new LongWorkHandler(), new LongWorkHandler())
.thenHandleEventsWithWorkerPool(new OtherWorkHandler(), new OtherWorkHandler(), new OtherWorkHandler());
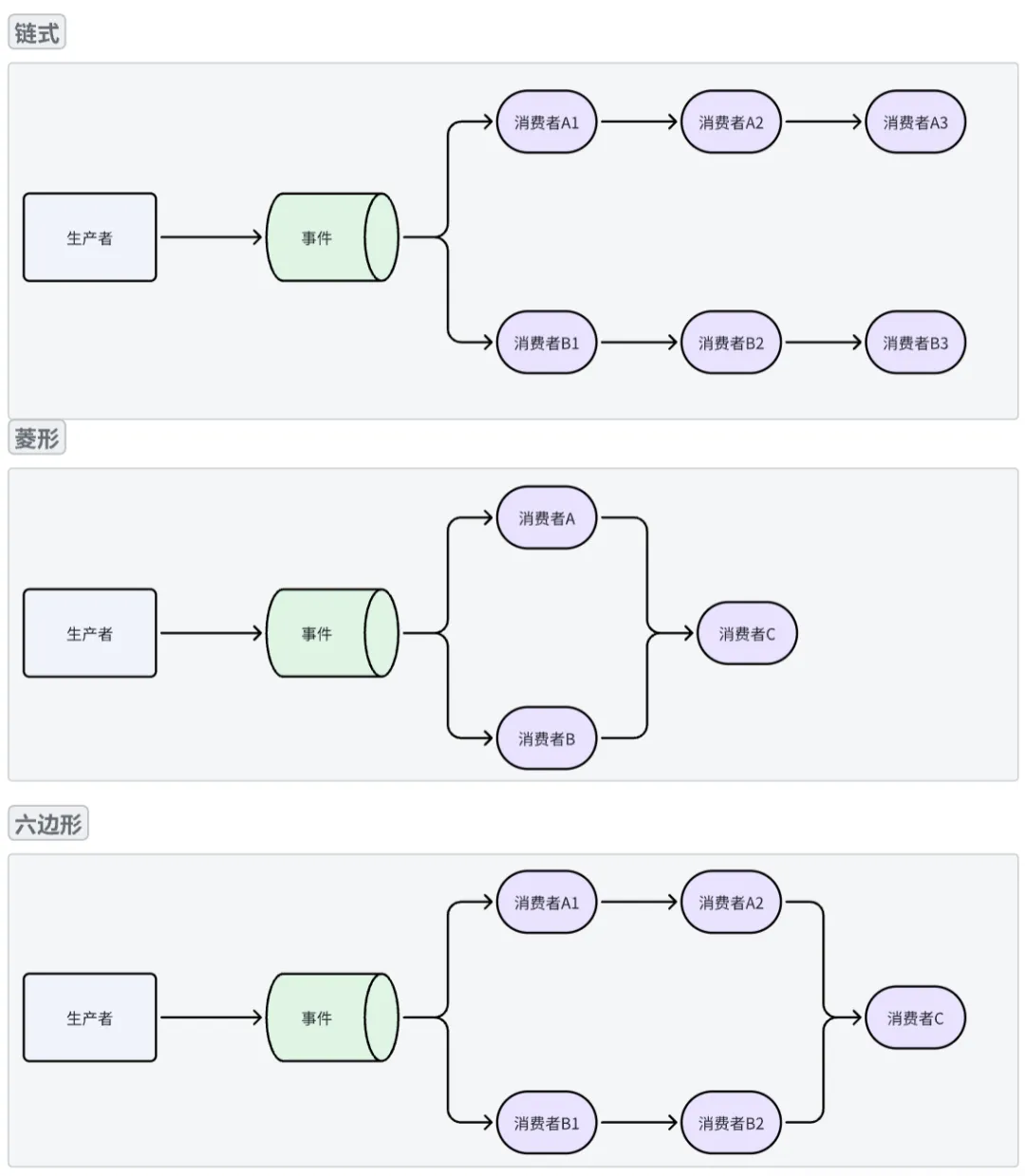
多消费者:链式、菱形、六边形执行模式
通过多种组合方式,可实现灵活的消费者执行顺序,如下:
![10.jpg]()
//链式
disruptor.handleEventsWith(new LongEventHandler11()).then(new LongEventHandler12());
disruptor.handleEventsWith(new LongEventHandler21()).then(new LongEventHandler22());
//菱形
disruptor.handleEventsWith(new LongEventHandler1(), new LongEventHandler2())
.then(new LongEventHandler3());
//六边形
LongEventHandler handler11 = new LongEventHandler();
LongEventHandler handler12 = new LongEventHandler();
LongEventHandler handler21 = new LongEventHandler();
LongEventHandler handler22 = new LongEventHandler();
LongEventHandler handler3 = new LongEventHandler();
disruptor.handleEventsWith(handler11, handler21);
disruptor.after(handler11).handleEventsWith(handler12);
disruptor.after(handler21).handleEventsWith(handler22);
disruptor.after(handler12, handler22).handleEventsWith(handler3);
二、Disruptor的核心概念
Disruptor内部组件交互图
![11.jpg]()
核心概念
有些概念前面已经介绍过,在此不再赘述,说一说还未介绍的几个概念:
Sequence
Sequence本身就是一个序号管理器,它是严格顺序增长的,Disruptor通过它标识和定位RingBuffer中的每一个事件,每个Consumer都维护一个Sequence,通过Sequence可以跟踪Consumer事件处理进度,它有AtomicLong的大多数功能特性,而且它消除了CPU伪共享的问题。
Sequencer
Sequencer是一个接口,它有两个实现类:SingleProducerSequencer(单生产者实现)、MultiProducerSequencer(多生产者实现),它主要作用是实现生产者和消费者之间快速、正确传递数据的并发算法。
Sequencer是生产者与缓冲区RingBuffer之间的桥梁。生产者可以通过Sequencer向RingBuffer申请数据的存放空间,并使用publish()方法通过WaiteStrategy通知消费者。
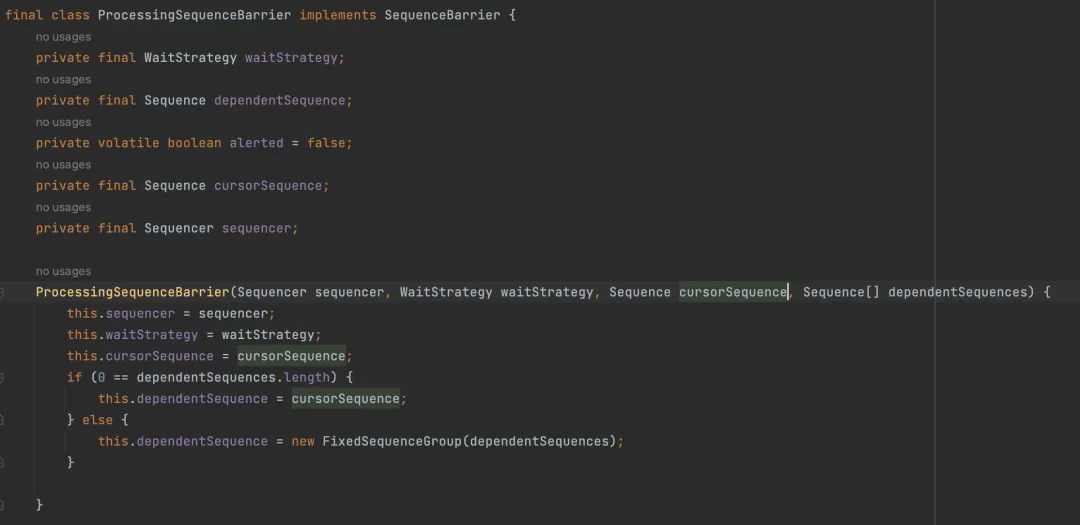
SequenceBarrier(序列屏障)
SequenceBarrier用于保证事件的有序性。它通过维护一组Sequence来跟踪消费者的进度,当生产者发布新的事件时,序列屏障会检查是否所有消费者都已处理完前面的事件,如果是,则通知生产者可以发布新的事件。
SequenceBarrier是消费者与RingBuffer之间的桥梁。在Disruptor中,消费者直接访问的是SequenceBarrier,而不是RingBuffer,因此SequenceBarrier能减少RingBuffer上的并发冲突,当消费者的消费速度大于生产者的生产速度时,消费者就可以通过waitFor()方法给予生产者一定的缓冲时间,从而协调了生产者和消费者的速度问题。
SequenceBarrier同时也是消费者与消费者之间消费依赖的抽象,SequenceBarrier只有一个实现类,即ProcessingSequenceBarrier。ProcessingSequenceBarrier由生产者Sequencer、消费定位cursorSequence、等待策略waitStrategy、还有一组依赖Sequence(dependentSequence)组成。
![12.jpg]()
三、Disruptor的特点
环形数组结构
- 采用首尾相接的数组而非链表,无需担心index溢出问题,且数组对处理器的缓存机制更加友好;
- 在RingBuffer数组长度设置为2^N时,通过sequence & (bufferSize-1)加速定位元素实际下标索引,通过结合左移(<<)操作实现乘法;
- 结合SequenceBarrier机制,实现线程与线程之间高效的数据交互。
无锁化设计
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据,整个过程通过原子变量CAS,保证操作的线程安全,即Disruptor的Sequence的自增就是CAS的自旋自增,对应的ArrayBlockQueue的数组索引index是互斥自增。
独占缓存行的方式消除伪共享
什么是伪共享
出现伪共享问题(False Sharing)的原因:
- 一个缓存行可以存储多个变量(存满当前缓存行的字节数);64个字节可以放8个long,16个int;
- 而CPU对缓存的修改又是以缓存行为最小单位的;不是以long 、byte这样的数据类型为单位的;
- 在多线程情况下,如果需要修改"共享同一个缓存行的其中一个变量",该行中其他变量的状态就会失效,甚至进行一致性保护。
所以,伪共享问题(False Sharing)的本质是:
CPU针对缓存的操作是以Cache Line为基本单位,对缓存行中的单个变量进行修改,会导致整个缓存行其他不相关的数据也都失效了,需要从主存重新加载,这个过程会带来性能损耗。
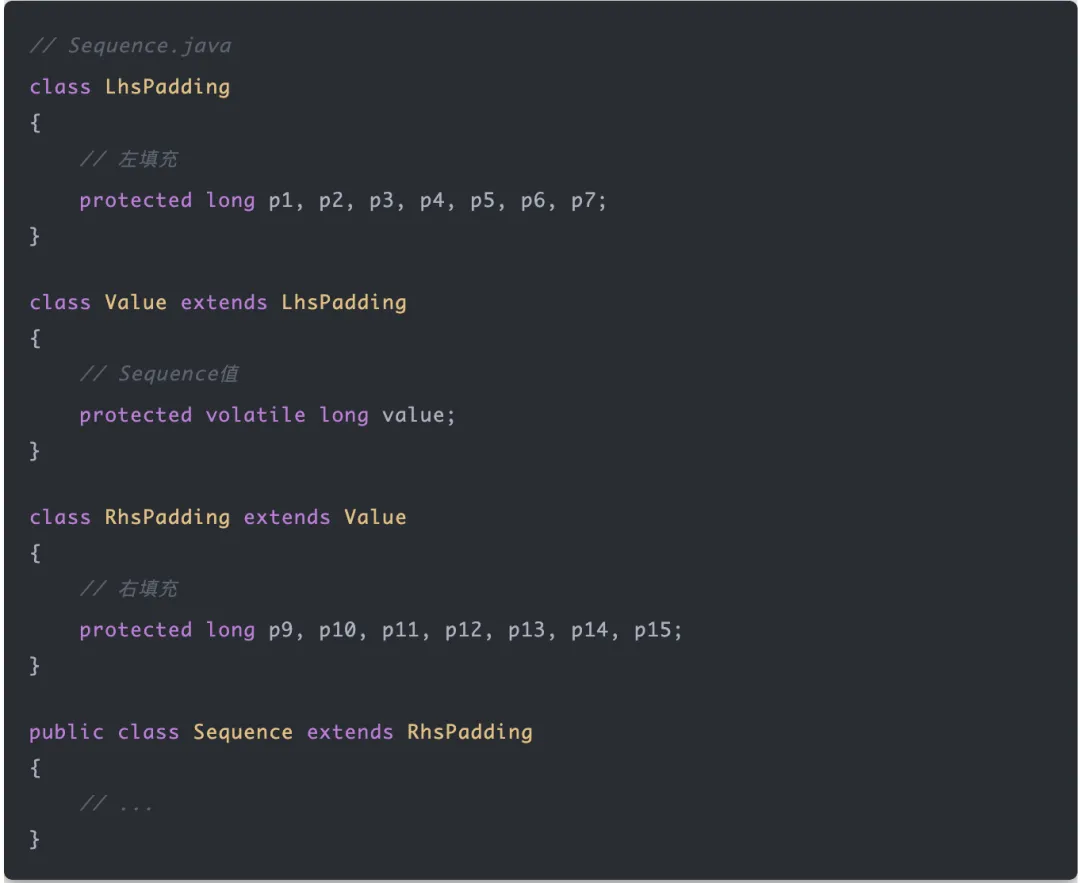
Disruptor是如何解决伪共享的
Sequence是标识RingBuffer环形数组的下标,同时生产者和消费者也会维护各自的Sequence,最重要的是,Sequence通过填充CPU缓存行避免了伪共享带来的性能损耗,来看下其填充缓存行源码:
![13.jpg]()
预分配内存
环形队列存放的是Event对象,而且是在Disruptor创建的时候调用EventFactory创建并一次将队列填满。Event保存生产者生产的数据,消费者也是通过Event获取数据,后续生产者只需要替换掉Event中的属性值。这种方式避免了重复创建对象,降低JVM的GC频率,带来系统性能的提升。后续我们在做编码的时候其实也可以借鉴这种实现思路。
见com.lmax.disruptor.RingBuffer.fill(EventFactoryeventFactory)
![14.jpg]()
四、Disruptor在撮合引擎中的应用
数字货币交易系统的简介
背景&价值
为用户提供数字虚拟货币的实时在线交易平台,实现盈亏。
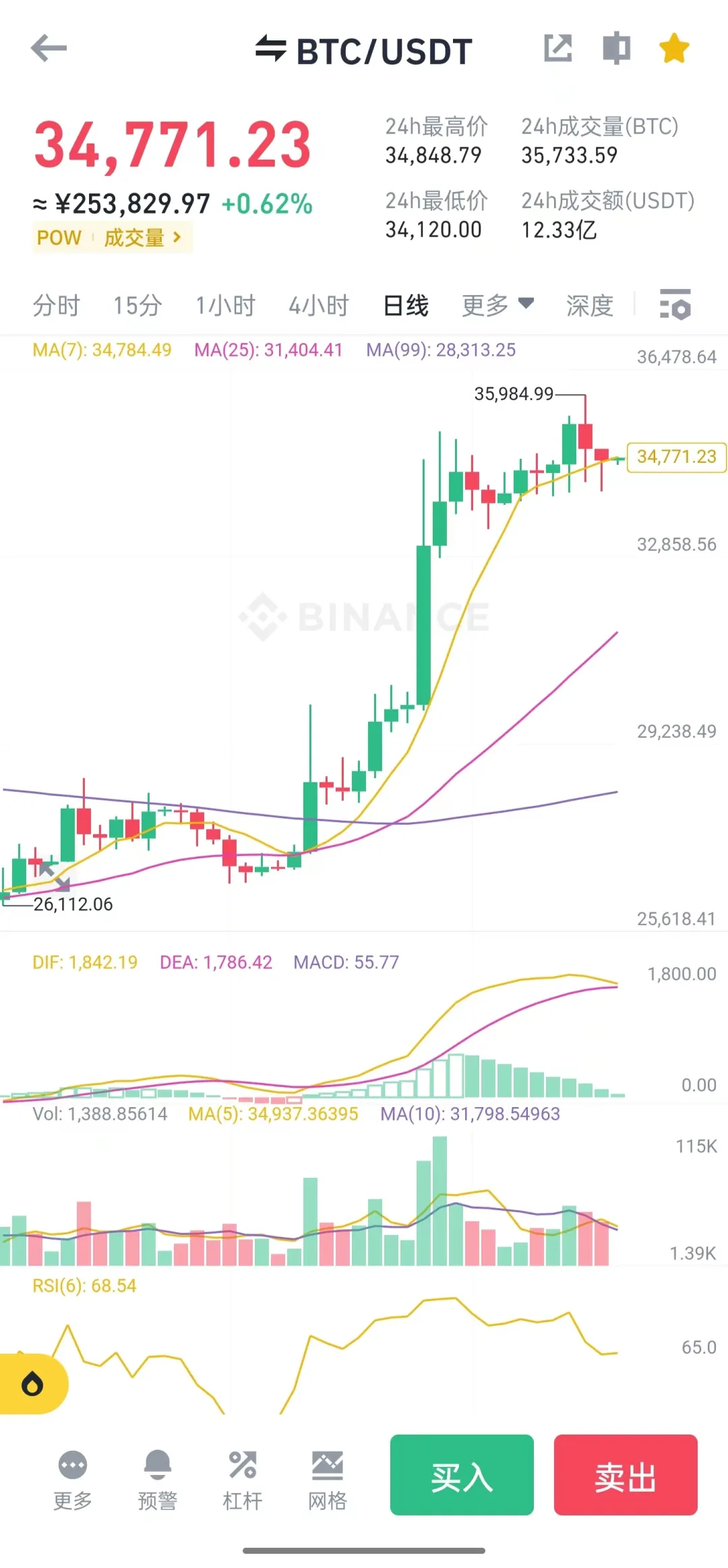
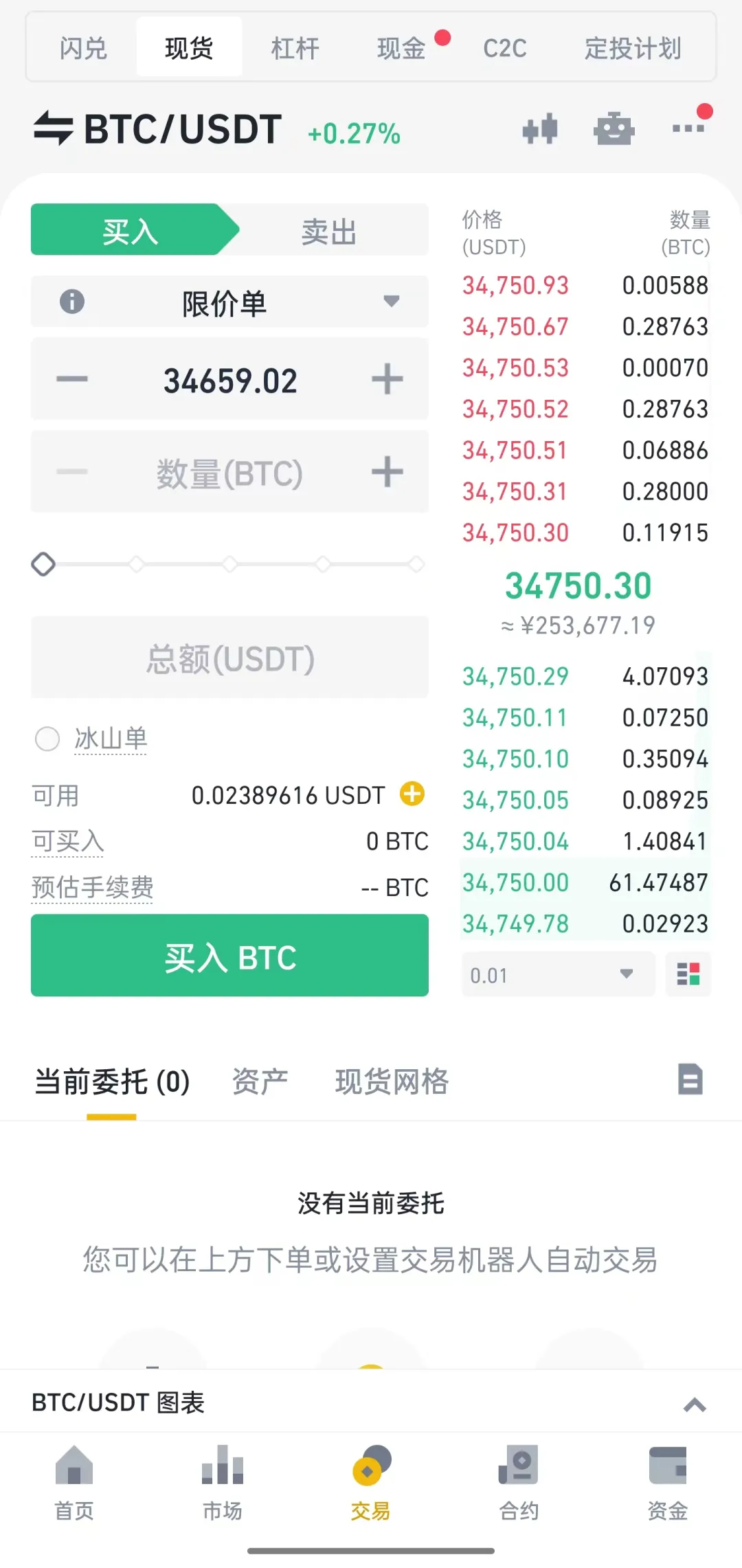
C端核心界面
![15.jpg]()
![16.jpg]()
以上截图仅用于技术展示,不构成投资建议
交易系统简化交互图
为了便于理解,简单列举交易系统的核心服务和数据流向,见下图:
![17.jpg]()
撮合应用的特点
应用启动时加载数据库未处理订单、写日志、撮合成功发送消息到MQ会涉及IO操作。
正因为应用是有状态的,所以需要通过Disruptor提升单机的性能和吞吐量。
为什么撮合应用不设计成无状态的?
在学习或者实际做架构设计时,一般大多数情况都建议将应用设计为无状态的,可以通过水平扩展,实现应用的高可用、高性能。而有状态的应用一般有单点故障问题,难以通过水平扩展提升应用的性能,但是做架构设计的时候,还是需要从实际的场景出发,而撮合应用场景很显然更适合设计成有状态的。在数字加密货币交易平台,每一种数字加密货币都是由唯一的"交易对"去标识的,类似股票交易中的股票代码,针对不同交易对的买卖交易单是天然隔离的,而同种交易对的买卖交易单必须是在同一个应用去处理的,否则匹配撮合的时候是有问题的。如果使用无状态的设计,那么所有的交易对都必须在一个集群内处理,而且每个应用都必须要有全量交易对的订单数据,这样就会存在两个问题:多个应用撮合匹配结果不一致,以哪个为准、热点交易对如何做隔离,所以解决方案就是根据交易对维度对订单做分片,同一个交易对的订单消息路由到同一个撮合应用进行处理,这样其实就是将撮合应用设计成有状态的。每一种交易对每个时刻有且只有一个应用能处理,然后再通过k8s的Liveness和Readiness探针做自动故障转移和恢复来解决单点故障的问题,最后通过本地缓存Caffeine+高性能队列Disruptor提升单pod的吞吐量。16C64G的配置在实际业务场景压测的结果是,单机最大TPS在200w/s左右,对于整个交易系统而言性能瓶颈已经不在撮合应用,因为极端情况下可以配置成一个pod处理一个交易对。
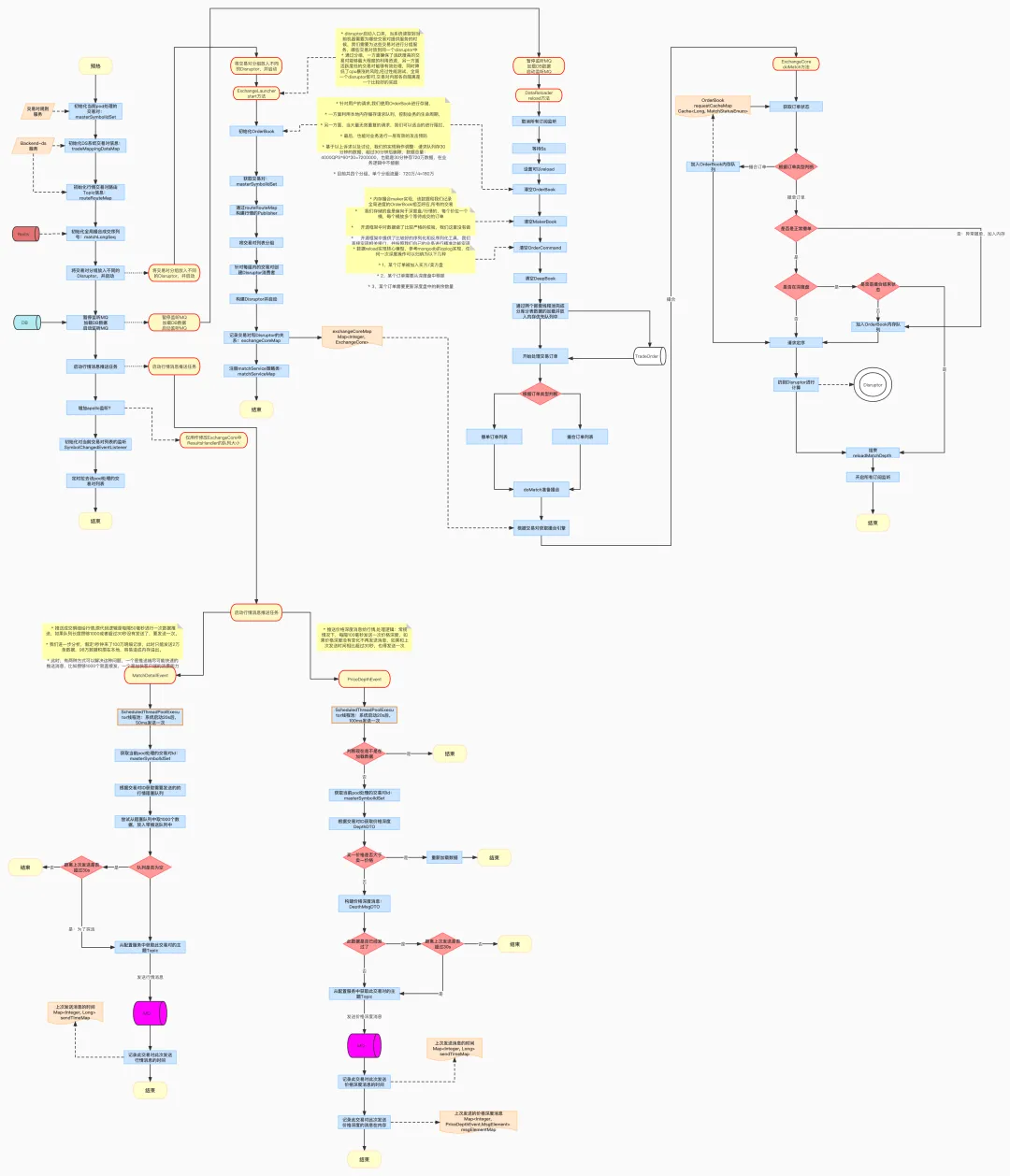
撮合引擎流程图
撮合引擎服务核心链路流程图:
![18.jpg]()
撮合引擎之Disruptor代码
为了便于理解,删除了和Disruptor无关的代码,只列举和Disruptor相关联的代码。
定义事件:用户交易单
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class DisruptorEvent implements Serializable {
private static final long serialVersionUID = -5886259612924517631L;
//成交单
private EntrustOrder entrustOrder;
}
定义事件处理器:对用户买单和卖单进行撮合匹配
//撮合事件处理器
public class ResultsHandler implements EventHandler<DisruptorEvent> {
private final Set<Integer> symbolIdSet = new HashSet<>();
private int workerQueueSize;
public ResultsHandler(Set<Integer> symbolIdSet, int queueSize) {
this.symbolIdSet.addAll(symbolIdSet);
this.workerQueueSize = queueSize;
}
@Override
public void onEvent(DisruptorEvent disruptorEvent, long sequence, boolean endOfBatch) {
try {
//获取订单
EntrustOrder entrustOrder = disruptorEvent.getEntrustOrder();
//常规的撮合,正常撤单,异常撤单
if (OperationTypeEnum.MATCH.getCode() == entrustOrder.getOperationType() ||
OperationTypeEnum.CANCEL.getCode() == entrustOrder.getOperationType()) {
// 取消订单需要在引擎内处理
if (Objects.equals(entrustOrder.getOperationType(), OperationTypeEnum.MATCH.getCode())) {
//更新为处理中
OrderBook.addToOrderBook(entrustOrder.getOrderId(), MatchStatusEnum.MATCH_ING);
} else if (Objects.equals(entrustOrder.getOperationType(), OperationTypeEnum.CANCEL.getCode())) {
//更新为处理中
if (OrderBook.getByOrderId(entrustOrder.getOrderId()) != null) {
OrderBook.addToOrderBook(entrustOrder.getOrderId(), MatchStatusEnum.CANCEL_ING);
}
}
// 执行撮合
this.doMatch(entrustOrder);
}
} catch (Exception e) {
log.error("match disruptor event handler error:{}", e.getMessage(), e);
}
}
/**
* 根据规则选择不同的撮合策略算法,进行撮合处理
* @param takerOrder
*/
public void doMatch(EntrustOrder takerOrder) {
SideEnum sideEnum = SideEnum.getSideEnum(takerOrder.getSide());
OrderTypeEnum orderTypeEnum = OrderTypeEnum.getOrderTypeEnum(takerOrder.getOrderType());
//选择撮合策略
MatchService matchService = MatchStrategy.router(orderTypeEnum, sideEnum);
MatchContext matchContext = MatchContext.getContext();
matchContext.setTakerOrder(takerOrder);
//执行撮合
matchService.start(matchContext);
//撮合完成
matchService.stop(matchContext);
}
}
事件生产者:构建Disruptor、生产事件
/**
* disruptor启动入口类,当系统读取到当前机器需要为哪些交易对提供服务的时候,
* 我们需要为这些交易对进行分组服务,哪些交易对放到同一个disruptor中
* 通过分组,一方面确保了活跃度高的交易对能够最大程度的利用资源,另一方面活跃度低的交易对能够有效处理,
* 同时降低了cpu暴涨的风险
*/
@Service
@Slf4j
public class ExchangeLauncher {
private static int BUFFER_SIZE = 1024 * 16;
@Resource
private LimitBuyMatchService limitBuyMatchService;
@Resource
private LimitSellMatchService limitSellMatchService;
@Resource
private MarketBuyMatchService marketBuyMatchService;
@Resource
private MarketSellMatchService marketSellMatchService;
@Resource
private MatchClusterConfiguration matchClusterConfiguration;
@Value("${match.worker-queue-size:5}")
private int workSize;
//一个交易对对应一个disruptor
private Map<Integer, ExchangeCore> exchangeCoreMap = new ConcurrentHashMap<>();
private List<ExchangeCore> exchangeCoreList = new CopyOnWriteArrayList<>();
public void start() {
try {
//init order book
OrderBook.init();
Set<Integer> symbolIdListSet = matchClusterConfiguration.getMasterSymbolIdSet();
if (CollectionUtils.isNotEmpty(symbolIdListSet)) {
List<Integer> allSymbolIds = new ArrayList<>(symbolIdListSet);
List<List<Integer>> pageList = ListUtils.partition(allSymbolIds, workSize);
pageList.forEach(symbolIds -> {
ResultsHandler handler = new ResultsHandler(new HashSet<>(symbolIds), workSize);
ExchangeCore exchangeCore = new ExchangeCore(handler, BUFFER_SIZE, new NamedThreadFactory("match", false));
exchangeCore.start();
exchangeCoreList.add(exchangeCore);
symbolIds.forEach(symbolId -> exchangeCoreMap.put(symbolId, exchangeCore));
});
}
// 注册matchService子类
registerMatchServices();
} catch (Exception e) {
log.error("exchangeLauncher start error:{}", e.getMessage(), e);
}
}
private void registerMatchServices() {
MatchStrategy.register(OrderTypeEnum.LIMIT, SideEnum.BUY, limitBuyMatchService);
MatchStrategy.register(OrderTypeEnum.LIMIT, SideEnum.SELL, limitSellMatchService);
MatchStrategy.register(OrderTypeEnum.MARKET, SideEnum.BUY, marketBuyMatchService);
MatchStrategy.register(OrderTypeEnum.MARKET, SideEnum.SELL, marketSellMatchService);
}
}
public class ExchangeCore extends AbstractLifeCycle {
private final Disruptor<DisruptorEvent> disruptor;
private MatchEventPublisher publisher;
private ResultsHandler eventHandler;
public ExchangeCore(ResultsHandler matchHandler, int ringBufferSize, ThreadFactory threadFactory) {
EventFactory eventFactory = () -> new DisruptorEvent();
this.disruptor = new Disruptor<>(eventFactory, ringBufferSize, threadFactory);
publisher = new MatchEventPublisher(this.disruptor);
disruptor.setDefaultExceptionHandler(new DisruptorExceptionHandler());
this.eventHandler = matchHandler;
disruptor.handleEventsWith(eventHandler);
disruptor.start();
}
@Override
public void start() {
super.start();
}
@Override
public void stop() {
super.stop();
disruptor.shutdown();
}
public BaseResponse doMatch(EntrustOrder taker) {
// 前置处理----start
if (OrderTypeEnum.getOrderTypeEnum(taker.getOrderType()) == null || SideEnum.getSideEnum(taker.getSide()) == null) {
log.error("{} - parameter error:{} or {}", taker.getTraceId(), "orderType", "side");
return BaseResponse.error(TradingMatchCodeEnum.PARAMETER_ERROR);
}
MatchStatusEnum matchStatusEnum = OrderBook.getByOrderId(taker.getOrderId());
MetricService metricService = SpringContextUtil.getBean(MetricService.class);
MatchClusterConfiguration configuration = SpringContextUtil.getBean(MatchClusterConfiguration.class);
// 撮合防重校验,并发存在问题。但是消费的时候,是单线程,做了校验,不存在重复撮合的问题。
if (OperationTypeEnum.MATCH.getCode() == taker.getOperationType()) {
if (matchStatusEnum != null) {
//短时间内重复撮合
log.error("{} - match repeat ,orderId :{}", taker.getTraceId(), taker.getOrderId());
return BaseResponse.error(TradingMatchCodeEnum.REPEAT_REQUEST);
}
//构造对象进入等待队列
OrderBook.addToOrderBook(taker.getOrderId(), MatchStatusEnum.WAIT_ING);
metricService.count(MetricNames.ORDER_TYPE_NUM, "type", "match", "group", configuration.getClusterName());
} else if (OperationTypeEnum.CANCEL.getCode() == taker.getOperationType()) {
int cancelType = taker.getCancelType();
/**
异常单-产生情况:收单服务 调用撮合 出现异常,不知道成功没,没有明确响应 开始进行异常撤单
*/
if (CancelTypeEnum.NORMAL_CANCEL.getCode() == cancelType) {
if (matchStatusEnum == null) {
// 数据有可能在请求队列中被逐出,需要继续走逻辑
//
} else {
if (MatchStatusEnum.MATCH_END == matchStatusEnum) {
//重复撤销,深度盘已经没有数据,没必要继续往下,不走disruptor 和撮合直接返回
log.error("{} - cancel failed, match end ,orderId :{}", taker.getTraceId(), taker.getOrderId());
return BaseResponse.error(TradingMatchCodeEnum.REPEAT_REQUEST);
}
OrderBook.addToOrderBook(taker.getOrderId(), MatchStatusEnum.WAIT_CANCEL);
}
} else {
// reload异常撤单,要加入内存
OrderBook.addToOrderBook(taker.getOrderId(), MatchStatusEnum.WAIT_CANCEL);
}
} else {
log.warn("--------can not find the operationType[{}]", taker.getOperationType());
throw new TradingMatchException("can not find the operationType[" + taker.getOperationType() + "]");
}
// 前置处理----end
//Disruptor开始发布事件
publisher.publish(taker);
return BaseResponse.success();
}
public Disruptor<DisruptorEvent> getDisruptor() {
return disruptor;
}
}
public class MatchEventPublisher {
private Disruptor<DisruptorEvent> disruptor;
public MatchEventPublisher(Disruptor<DisruptorEvent> disruptor) {
this.disruptor = disruptor;
}
private static final EventTranslatorOneArg<DisruptorEvent, EntrustOrder> TRANSLATOR =
(event, sequence, entrustOrder) -> {
event.setEntrustOrder(entrustOrder);
};
public void publish(EntrustOrder taker) {
RingBuffer<DisruptorEvent> ringBuffer = disruptor.getRingBuffer();
taker.setSequence(ringBuffer.getCursor());
taker.setArriveTime(System.currentTimeMillis());
ringBuffer.publishEvent(TRANSLATOR, taker);
// ...
}
}
五、总结
Disruptor作为一个以高性能著称的队列,它有很多优秀的设计思想值得我们学习,比如环形数组队列RingBuffer、SequenceBarrier机制、无锁化设计、预分配内存、消除伪共享、以及灵活丰富的生产者和消费者模式。本文只是介绍了一些对Disruptor的基本功能和实际使用场景,后续大家有兴趣可以结合源码去做更加深入的理解。由于本人文笔和经验有限,若有不足之处,还请及时指正,共同学习和进步。
引用: https://lmax-exchange.github.io/disruptor/user-guide/#_advanced_techniques
*文/ 天佑
本文属得物技术原创,更多精彩文章请看:得物技术
未经得物技术许可严禁转载,否则依法追究法律责任!