GreatSQL 构建高效 HTAP 服务架构指南(主从复制)
![]()
引言
全文约定:$为命令提示符、greatsql>为 GreatSQL 数据库提示符。在后续阅读中,依据此约定进行理解与操作
Rapid 引擎
从 GreatSQL 8.0.32-25 版本开始,新增Rapid存储引擎,该引擎使得 GreatSQL 能满足联机分析(OLAP)查询请求。
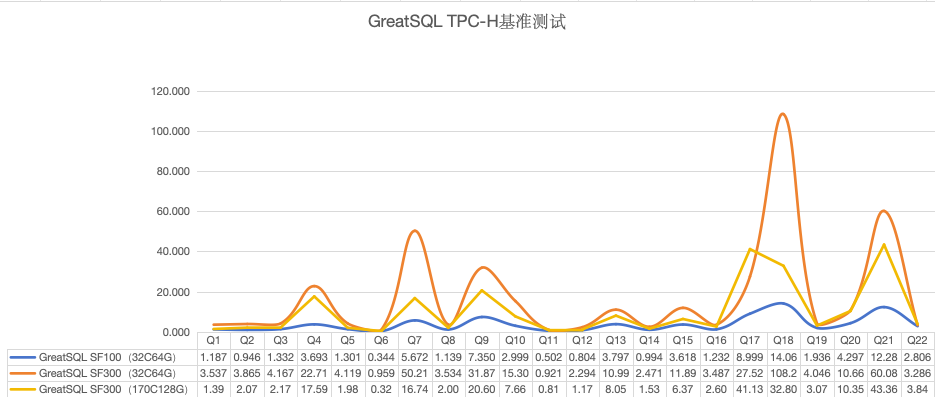
GreatSQL Rapid引擎性能表现优异,在32C64G测试机环境下,TPC-H 100G测试中22条SQL总耗时仅需不到80秒
![file]()
Rapid 引擎更多介绍可前往查看:
有了 Rapid 引擎的加持,便可使用 GreatSQL 构建一个高效的 HTAP 服务架构,以此来提升 GreatSQL 的查询效率。
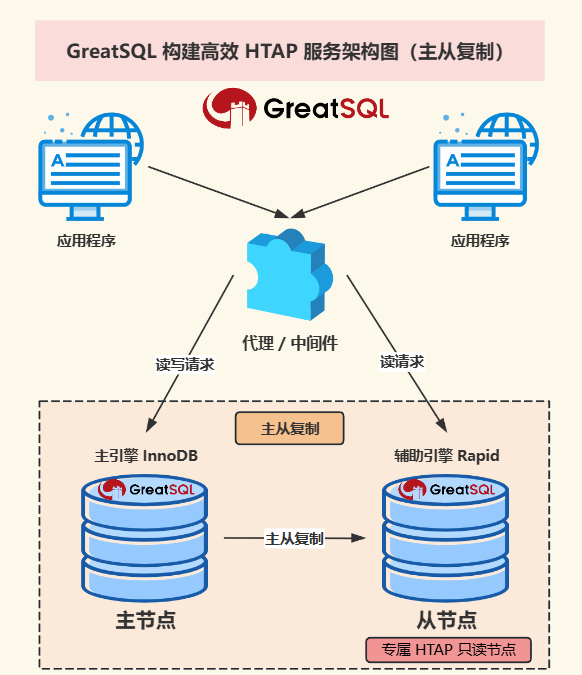
服务架构图
![file]()
本服务架构采用的是 GreatSQL 主从复制,主节点采用默认 InnoDB 引擎,从节点使用辅助引擎 Rapid 加速查询构建专属 HTAP 只读节点。加上 MySQL Router 等之类的代理/中间件负责读写分离来完成 HTAP 服务架构。
采用此 HTAP 架构可获得以下收益
- 高查询效率 :
- Rapid 引擎的引入使得从节点能够加速查询处理,特别适用于 OLAP(联机分析处理)场景。
- 高负载均衡 :
- 利用代理/中间件实现读写分离,确保主节点(写操作)和从节点(读操作)负载均衡。
- 高并发性能 :
- 主节点上采用 InnoDB 响应高并发事务请求,确保业务需求写入性能。
- 高灵活和扩展 :
- GreatSQL 的可插拔存储引擎架构使得系统可以根据需要选择适合的存储引擎。Rapid 引擎作为辅助引擎,可以动态安装或卸载,为用户提供了极大的灵活性和可扩展性。
部署主从复制
环境准备及版本介绍
服务器配置
$ uname -a
Linux gip 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
$ cat /etc/centos-release
CentOS Linux release 7.6.1810 (Core)
主从库与中间件配置
| IP | 角色 | 版本 | 备注 | | ------------------ | ------------- | ------------------ | ------------------------------- | | 192.168.6.215:3306 | GreatSQL 主库 | GreatSQL 8.0.32-25 | | | 192.168.6.214:3306 | GreatSQL 从库 | GreatSQL 8.0.32-25 | 专属 HTAP 只读节点 | | 192.168.6.215:3306 | MySQL Router | 8.4.0 TLS | 代理/中间件。可根据需求灵活替换 |
安装 GreatSQL
GreatSQL 安装版本为 8.0.32-25 版本,并分别安装两个实例 GreatSQL
安装步骤详见:https://greatsql.cn/docs/8.0.32-25/4-install-guide/0-install-guide.html
部署主从复制
主节点建立账户并授权
# 建立复制账户
greatsql> ALTER USER 'slave'@'%' IDENTIFIED WITH mysql_native_password BY 'GreatSQL@2024';
Query OK, 0 rows affected (0.01 sec)
# 授权
greatsql> GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%';
greatsql> FLUSH PRIVILEGES;
然后查看主节点状态,记录二进制文件名 binlog.000002 和位置 2027
greatsql> SHOW MASTER STATUS\G
*************************** 1. row ***************************
File: binlog.000002
Position: 2027
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: e766387a-2d3f-11ef-8435-00163e8e122e:1-8
1 row in set (0.00 sec)
从节点服务器配置,并开启从服务器复制
greatsql> CHANGE MASTER TO master_host='192.168.6.215',master_port=3306,master_user='slave',master_password='GreatSQL@2024',master_log_file='binlog.000002',master_log_pos=2027;
greatsql> START REPLICA
检查主从复制情况
greatsql> SHOW REPLICA STATUS\G
*************************** 1. row ***************************
Replica_IO_State: Waiting for source to send event
Source_Host: 192.168.6.215
Source_User: slave
Source_Port: 3306
Connect_Retry: 60
Source_Log_File: binlog.000002
Read_Source_Log_Pos: 2027
Relay_Log_File: gip-relay-bin.000002
Relay_Log_Pos: 323
Relay_Source_Log_File: binlog.000002
Replica_IO_Running: Yes # 为 Yes 即表示构建成功
Replica_SQL_Running: Yes # 为 Yes 即表示构建成功
生成测试数据
主库写入数据
往主库生成数据
-- 创建测试数据库
CREATE DATABASE IF NOT EXISTS htap_test_db;
USE htap_test_db;
-- 创建接近生产环境的表
CREATE TABLE `orders` (
`order_id` int NOT NULL AUTO_INCREMENT,
`customer_id` int NOT NULL,
`product_id` int NOT NULL,
`order_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`order_status` char(10) NOT NULL DEFAULT 'pending',
`quantity` int NOT NULL,
`order_amount` decimal(10,2) NOT NULL,
`shipping_address` varchar(255) NOT NULL,
`billing_address` varchar(255) NOT NULL,
`order_notes` varchar(255) DEFAULT NULL,
PRIMARY KEY (`order_id`),
KEY `idx_customer_id` (`customer_id`),
KEY `idx_product_id` (`product_id`),
KEY `idx_order_date` (`order_date`),
KEY `idx_order_status` (`order_status`)
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
往该表插入十万行数据
# 主库
greatsql> SELECT COUNT(*) FROM htap_test_db.orders;
+----------+
| COUNT(*) |
+----------+
| 100000 |
+----------+
1 row in set (0.01 sec)
从库此时也会复制主库的十万行数据
# 从库
greatsql> SELECT COUNT(*) FROM htap_test_db.orders;
+----------+
| COUNT(*) |
+----------+
| 100000 |
+----------+
1 row in set (0.01 sec)
如果在主库或从库进行一个复杂 SQL 查询,需要用时 4~5 秒左右
SELECT
order_id,customer_id,product_id,order_date,order_status,
quantity,order_amount,shipping_address,billing_address,
order_notes,
SUM( order_amount ) OVER ( PARTITION BY customer_id ) AS total_spent_by_customer,
COUNT( order_id ) OVER ( PARTITION BY customer_id ) AS total_orders_by_customer,
AVG( order_amount ) OVER ( PARTITION BY customer_id ) AS average_order_amount_per_customer
FROM
orders
WHERE
order_status IN ( 'completed', 'shipped', 'cancelled' )
AND quantity > 1
ORDER BY
order_date DESC,
order_amount DESC
LIMIT 100;
在从库运行三次结果平均值为 4.91 秒
# 第一次
100 rows in set (4.99 sec)
# 第二次
100 rows in set (4.59 sec)
# 第三次
100 rows in set (5.15 sec)
构建专属 HTAP 只读节点
以下所有操作都在 GreatSQL 从库中进行
使用 Rapid 引擎
进入 GreatSQL 从库,加载 Rapid 引擎
greatsql> INSTALL PLUGIN Rapid SONAME 'ha_rapid.so';
为 orders 表加上 Rapid 辅助引擎
greatsql> ALTER TABLE htap_test_db.orders SECONDARY_ENGINE = rapid;
将表中数据一次性全量导入到 Rapid 引擎中
greatsql> ALTER TABLE htap_test_db.orders SECONDARY_LOAD;
Query OK, 0 rows affected (1.72 sec)
检查导入情况,注意关键词 SECONDARY_ENGINE="rapid" SECONDARY_LOAD="1"
greatsql> SHOW TABLE STATUS like 'orders'\G
*************************** 1. row ***************************
Name: orders
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 99381
Avg_row_length: 142
Data_length: 14172160
Max_data_length: 0
Index_length: 9502720
Data_free: 3145728
Auto_increment: 100001
Create_time: 2024-06-19 11:11:27
Update_time: NULL
Check_time: NULL
Collation: utf8mb4_0900_ai_ci
Checksum: NULL
Create_options: SECONDARY_ENGINE="rapid" SECONDARY_LOAD="1"
Comment:
1 row in set (0.00 sec)
打开 Rapid 引擎的总控制开关,并把启用阈值调小
greatsql> SET GLOBAL use_secondary_engine = ON;
greatsql> SET GLOBAL secondary_engine_cost_threshold = 0;
secondary_engine_cost_threshold 的值可根据实际情况设置
查看该 SQL 的执行计划,注意关键词 Using secondary engine RAPID 表示使用了 Rapid 引擎
greatsql> EXPLAIN SELECT ... 省略 ... ORDER BY order_date DESC,order_amount DESC LIMIT 100;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: orders
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 99381
filtered: 33.33
Extra: Using where; Using filesort; Using secondary engine RAPID
1 row in set, 2 warnings (0.00 sec)
执行三次结果平均值为 0.12 秒,比之前提升近 41 倍!
# 第一次
100 rows in set (0.17 sec)
# 第二次
100 rows in set (0.10 sec)
# 第三次
100 rows in set (0.10 sec)
启动增量导入任务
因为在生产环境中数据是无时不刻在产生,所以需要启用增量导入,才可保证最新数据始终在 Rapid 引擎内
启动增量导入任务
greatsql> SELECT START_SECONDARY_ENGINE_INCREMENT_LOAD_TASK('htap_test_db', 'orders');
+----------------------------------------------------------------------+
| START_SECONDARY_ENGINE_INCREMENT_LOAD_TASK('htap_test_db', 'orders') |
+----------------------------------------------------------------------+
| success |
+----------------------------------------------------------------------+
查看增量导入任务状态
greatsql> SELECT * FROM information_schema.SECONDARY_ENGINE_INCREMENT_LOAD_TASK\G
*************************** 1. row ***************************
DB_NAME: htap_test_db
TABLE_NAME: orders
START_TIME: 2024-06-19 14:13:53
START_GTID: e766387a-2d3f-11ef-8435-00163e8e122e:9-100010:100012,
f4248873-2d46-11ef-90f8-00163e832e1f:1-8
COMMITTED_GTID_SET: e766387a-2d3f-11ef-8435-00163e8e122e:9-100010:100012,
f4248873-2d46-11ef-90f8-00163e832e1f:1-8
READ_GTID:
READ_BINLOG_FILE: /data/GreatSQL/binlog.000003
READ_BINLOG_POS: 1906
DELAY: 0
STATUS: RUNNING
END_TIME:
INFO:
在给主库插入 1 万条数据,确认主从复制和 Rapid 引擎的增量导入没有问题,产生的新数据也可以使用 Rapid 引擎加速查询。
请注意,Rapid 引擎在增量导入数据时可能存在短暂延迟。大量 Insert、Delete 数据,可能无法立即通过 Rapid 引擎查询到这些最新变动的数据。等增量任务导入完成后 Rapid 引擎才能查询到最新变动的数据。
# 从机查看数据是 110000 条和主库一致
greatsql> SELECT COUNT(*) FROM htap_test_db.orders;
+----------+
| COUNT(*) |
+----------+
| 110000 |
+----------+
1 row in set (0.01 sec)
此处启用了 Rapid 引擎所以COUNT(*)速度会很快,若没启用 Rapid 引擎则可能耗时较长
查看执行计划,从 rows 列可以看到,扫描的行数增加了,表示新数据已经增量导入到 Rapid 引擎中
greatsql> EXPLAIN SELECT ... 省略 ... ORDER BY order_date DESC,order_amount DESC LIMIT 100;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: orders
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 109381 # 扫描的行数也增加了
filtered: 33.33
Extra: Using where; Using filesort; Using secondary engine RAPID
至此,主从复制和构建 HTAP 专属只读节点完成,接下来是实现读写分离,当然一主一从的情况下是不太需要读写分离中间件的,要中间件的情况是怕 HTAP 专属服务器宕机,这时候主节点就要负责读写了。
实现读写分离
这里使用的是 MySQL Router 中间件实现的读写分离,如果有其它读写分离中间件,例如 MySQL Proxy 等也可以替换。
安装 MySQL Router
下载过程省略,可自行到 MySQL 网站上下载
这里选择的是最新的长期支持版 MySQL Router 8.4.0 版本
解压安装包,并进入 MySQL Router 的 bin 目录
$ tar -xvJf mysql-router-8.4.0-linux-glibc2.17-x86_64.tar.xz
把 MySQL Router 配置模板拷贝出来放到 /etc/mysqlrouter 目录下,并改名为 mysqlrouter.conf
$ cp /usr/local/mysql-router-8.4.0-linux-glibc2.17-x86_64/share/doc/mysqlrouter/sample_mysqlrouter.conf /etc
$ mv /etc/sample_mysqlrouter.conf /etc/mysqlrouter.conf
修改 MySQL Router 配置文件
$ vim /etc/mysqlrouter.conf
[DEFAULT]
logging_folder = /usr/local/mysql-router-8.4.0-linux-glibc2.17-x86_64/log/mysql-router
plugin_folder = /usr/local/mysql-router-8.4.0-linux-glibc2.17-x86_64/lib/mysqlrouter/
runtime_folder = /var/run
config_folder = /etc/
[logger]
level = debug
# 主节点故障转移配置
[routing:basic_failover]
# 写节点地址
bind_address=192.168.6.215
# 写节点端口
bind_port = 7001
# 模式,读写
mode = read-write
destinations = 192.168.6.215:3306
routing_strategy=first-available
# 从节点负载均衡配置
[routing:balancing]
# 绑定的IP地址
bind_address=192.168.6.215
# 监听的端口
bind_port = 7002
# 连接超时时间
connect_timeout = 3
# 后端服务器地址
destinations = 192.168.6.214:3306,192.168.6.215:3306
# 模式:读还是写
mode = read-only
routing_strategy=first-available
[keepalive]
interval = 60
这里从节点负载均衡配置采用first-available,优先使用 HTAP 服务器。若专属 HTAP 服务器宕机,可自动切换使用主节点查询
启动 MySQL Router
$ mysqlrouter --config /etc/mysqlrouter.conf &
查看监听端口是否启用
$ netstat -ntlp |grep mysqlrouter
tcp6 0 0 ::1:7001 :::* LISTEN 14404/./mysqlrouter
tcp6 0 0 ::1:7002 :::* LISTEN 14404/./mysqlrouter
这里演示的是主从复制模式,所以有读写两个端口。在新版本的 MySQL Router 中,在原先的6446、6447端口上,新增一个6450端口,支持读写分离
测试只读端口是否只连接专属 HTAP 节点
$ for ((i=0;i<=3;i++));do mysql -h192.168.6.215 -uroot -p -P7002 -e"select @@server_id;";done;
+-------------+
| @@server_id |
+-------------+
| 2 |
+-------------+
+-------------+
| @@server_id |
+-------------+
| 2 |
+-------------+
+-------------+
| @@server_id |
+-------------+
| 2 |
+-------------+
自此构建高效 HTAP 服务器架构(主从复制)完成!
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL是适用于金融级应用的国内自主开源数据库,具备高性能、高可靠、高易用性、高安全等多个核心特性,可以作为MySQL或Percona Server的可选替换,用于线上生产环境,且完全免费并兼容MySQL或Percona Server。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
![image]()
社区有奖建议反馈: https://greatsql.cn/thread-54-1-1.html
社区博客有奖征稿详情: https://greatsql.cn/thread-100-1-1.html
(对文章有疑问或者有独到见解都可以去社区官网提出或分享哦~)
技术交流群:
微信&QQ群:
QQ群:533341697
微信群:添加GreatSQL社区助手(微信号:wanlidbc )好友,待社区助手拉您进群。