![]()
前言
前段时间写过一篇《线程池没你想的那么简单》,和大家一起撸了一个基本的线程池,具备:
- 线程池基本调度功能。
- 线程池自动扩容缩容。
- 队列缓存线程。
- 关闭线程池。
这些功能,最后也留下了三个待实现的 features 。
- 执行带有返回值的线程。
- 异常处理怎么办?
- 所有任务执行完怎么通知我?
这次就实现这三个特性来看看 j.u.c 中的线程池是如何实现这些需求的。
再看本文之前,强烈建议先查看上文《线程池没你想的那么简单》
任务完成后的通知
大家在用线程池的时候或多或少都会有这样的需求:
线程池中的任务执行完毕后再通知主线程做其他事情,比如一批任务都执行完毕后再执行下一波任务等等。
![]()
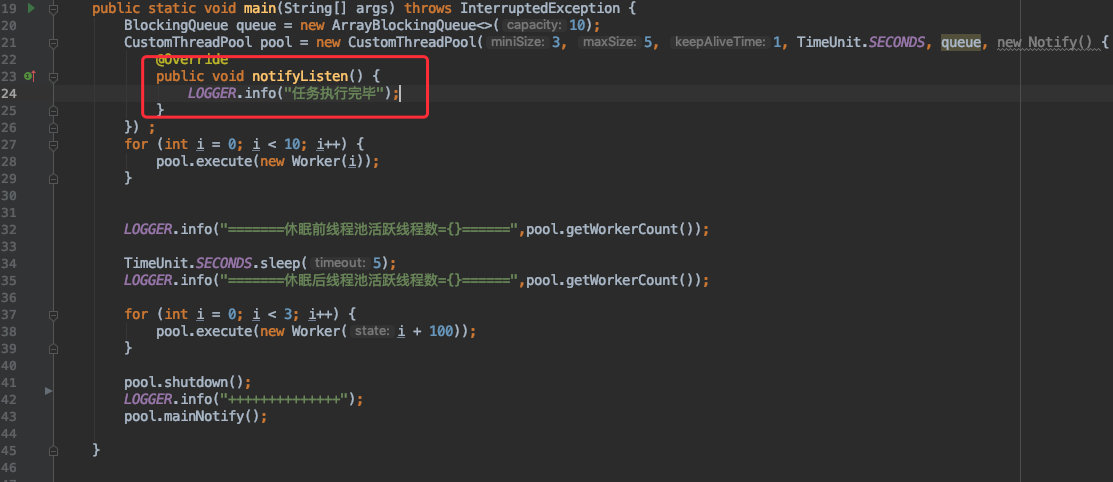
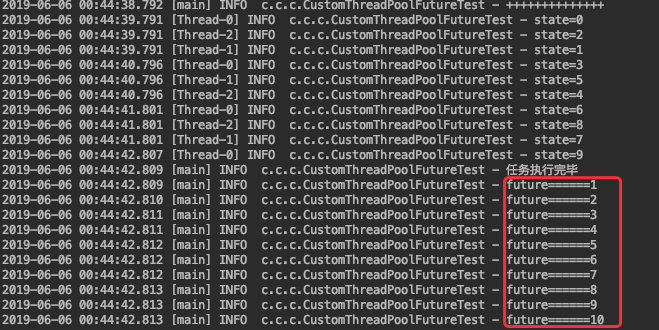
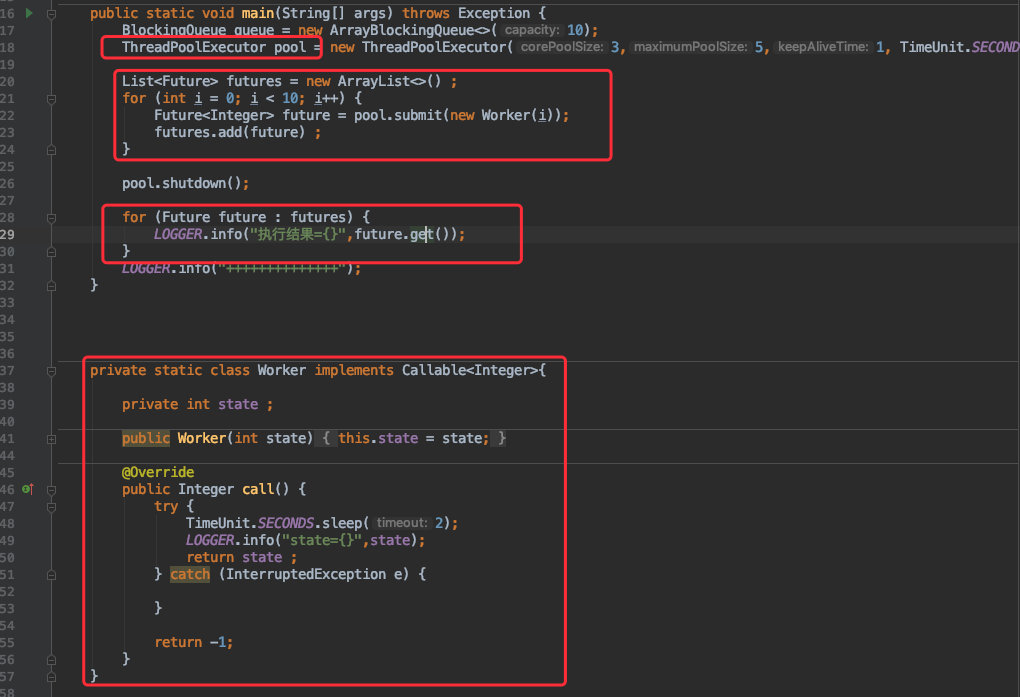
以我们之前的代码为例:
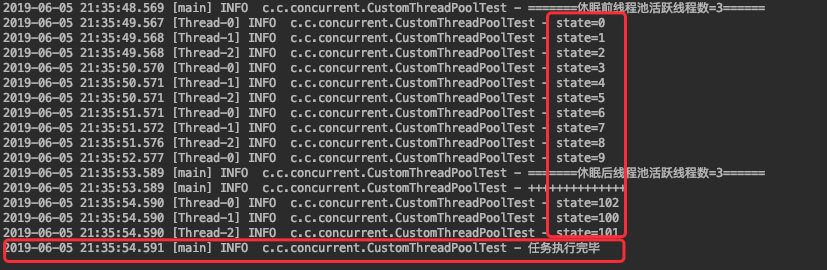
总共往线程池中提交了 13 个任务,直到他们都执行完毕后再打印 “任务执行完毕” 这个日志。
执行结果如下:
![]()
为了简单的达到这个效果,我们可以在初始化线程池的时候传入一个接口的实现,这个接口就是用于任务完成之后的回调。
![]()
public interface Notify {
/**
* 回调
*/
void notifyListen() ;
}
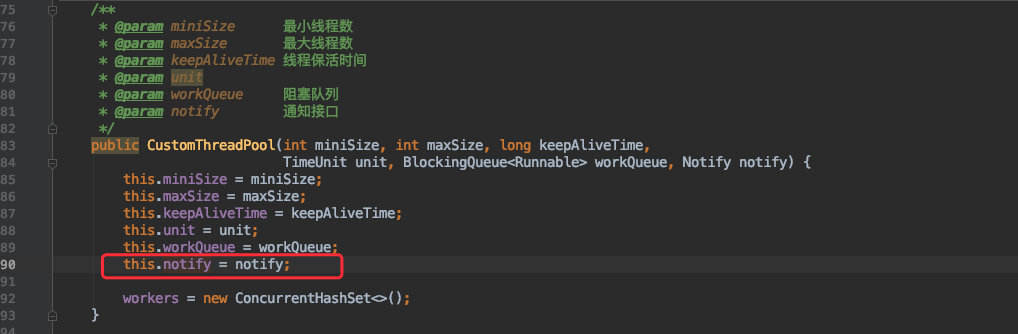
以上就是线程池的构造函数以及接口的定义。
所以想要实现这个功能的关键是在何时回调这个接口?
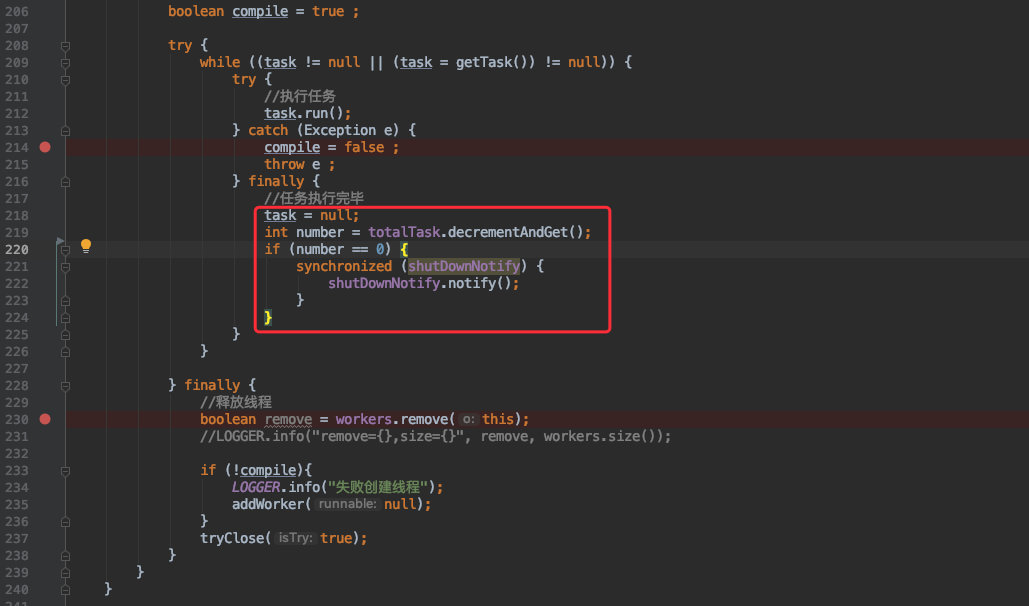
仔细想想其实也简单:只要我们记录提交到线程池中的任务及完成的数量,他们两者的差为 0 时就认为线程池中的任务已执行完毕;这时便可回调这个接口。
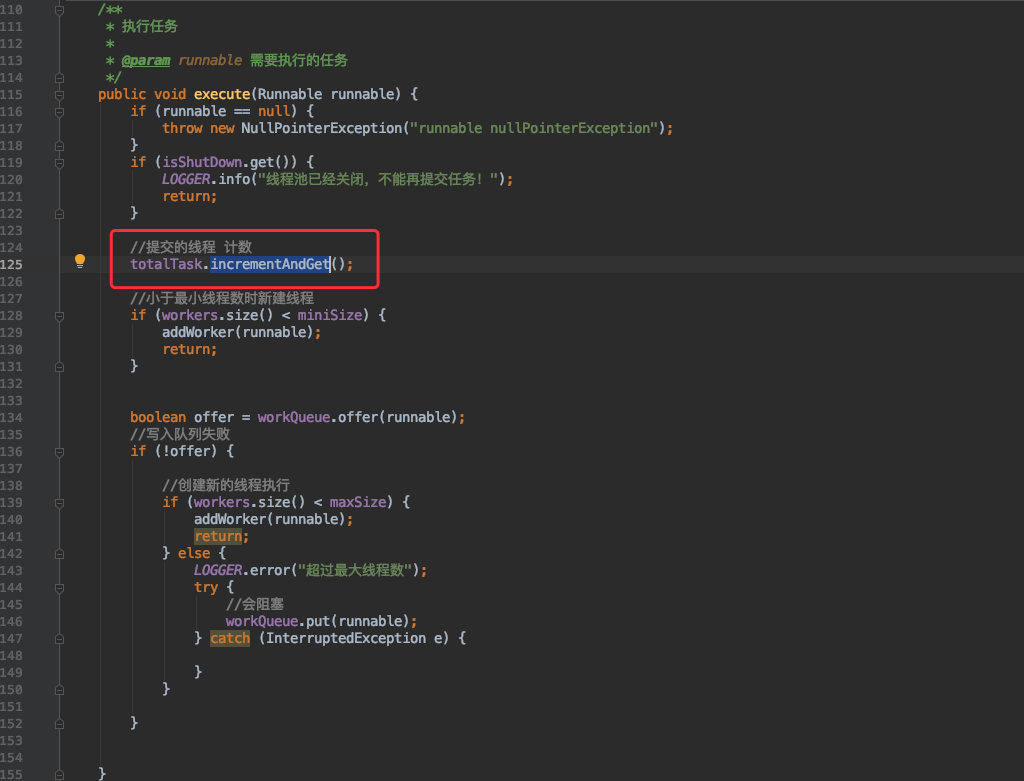
所以在往线程池中写入任务时我们需要记录任务数量:
![]()
为了并发安全的考虑,这里的计数器采用了原子的 AtomicInteger 。
![]()
而在任务执行完毕后就将计数器 -1 ,一旦为 0 时则任务任务全部执行完毕;这时便可回调我们自定义的接口完成通知。
JDK 的实现
这样的需求在 jdk 中的 ThreadPoolExecutor 中也有相关的 API ,只是用法不太一样,但本质原理都大同小异。
我们使用 ThreadPoolExecutor 的常规关闭流程如下:
executorService.shutdown();
while (!executorService.awaitTermination(100, TimeUnit.MILLISECONDS)) {
logger.info("thread running");
}
线程提交完毕后执行 shutdown() 关闭线程池,接着循环调用 awaitTermination() 方法,一旦任务全部执行完毕后则会返回 true 从而退出循环。
这两个方法的目的和原理如下:
- 执行
shutdown() 后会将线程池的状态置为关闭状态,这时将会停止接收新的任务同时会等待队列中的任务全部执行完毕后才真正关闭线程池。
awaitTermination 会阻塞直到线程池所有任务执行完毕或者超时时间已到。
为什么要两个 api 结合一起使用呢?
主要还在最终的目的是:所有线程执行完毕后再做某件事情,也就是在线程执行完毕之前其实主线程是需要被阻塞的。
shutdown() 执行后并不会阻塞,会立即返回,所有才需要后续用循环不停的调用 awaitTermination(),因为这个 api 才会阻塞线程。
其实我们查看源码会发现,ThreadPoolExecutor 中的阻塞依然也是等待通知机制的运用,只不过用的是 LockSupport 的 API 而已。
带有返回值的线程
接下来是带有返回值的线程,这个需求也非常常见;比如需要线程异步计算某些数据然后得到结果最终汇总使用。
先来看看如何使用(和 jdk 的类似):
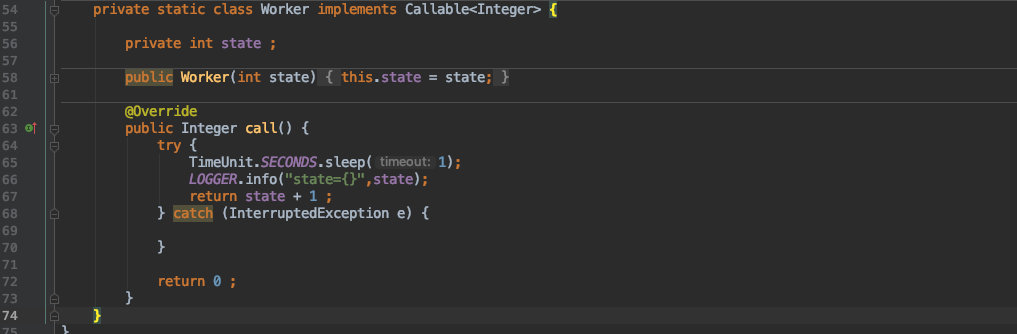
首先任务是不能实现 Runnable 接口了,毕竟他的 run() 函数是没有返回值的;所以我们改实现一个 Callable 的接口:
![]()
这个接口有一个返回值。
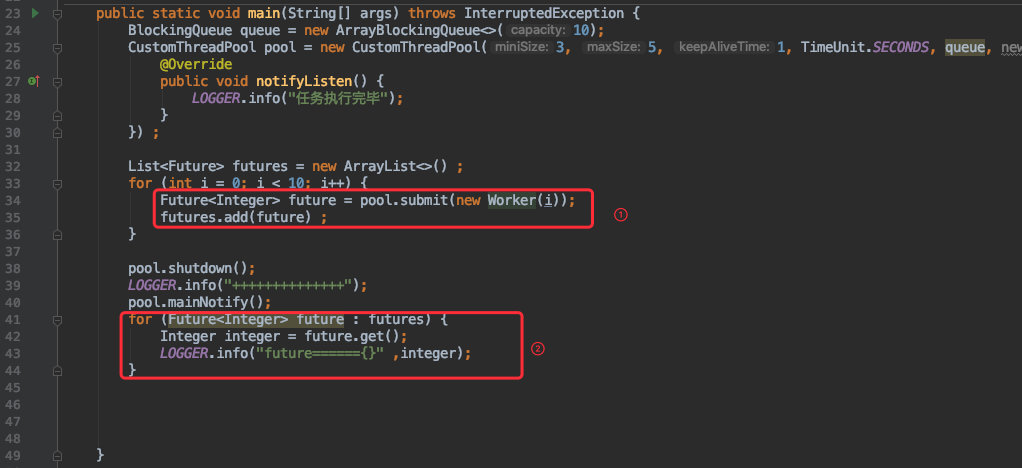
同时在提交任务时也稍作改动:
![]()
首先是执行任务的函数由 execute() 换为了 submit(),同时他会返回一个返回值 Future,通过它便可拿到线程执行的结果。
最后通过第二步将所有执行结果打印出来:
![]()
实现原理
再看具体实现之前先来思考下这样的功能如何实现?
- 首先受限于
jdk 的线程 api 的规范,要执行一个线程不管是实现接口还是继承类,最终都是执行的 run() 函数。
- 所以我们想要一个线程有返回值无非只能是在执行
run() 函数时去调用一个有返回值的方法,再将这个返回值存放起来用于后续使用。
比如我们这里新建了一个 Callable<T> 的接口:
public interface Callable<T> {
/**
* 执行任务
* @return 执行结果
*/
T call() ;
}
它的 call 函数就是刚才提到的有返回值的方法,所以我们应当在线程的 run() 函数中去调用它。
接着还会有一个 Future 的接口,他的主要作用是获取线程的返回值,也就是 再将这个返回值存放起来用于后续使用 这里提到的后续使用。
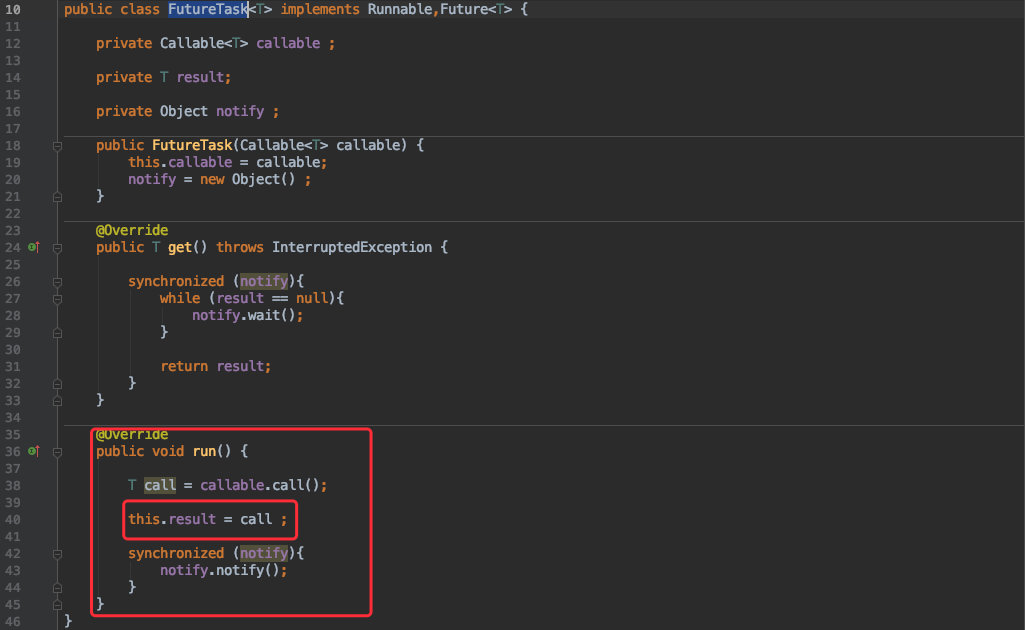
既然有了接口那自然就得有它的实现 FutureTask,它实现了 Future 接口用于后续获取返回值。
同时实现了 Runnable 接口会把自己变为一个线程。
![]()
所以在它的 run() 函数中会调用刚才提到的具有返回值的 call() 函数。
再次结合 submit() 提交任务和 get() 获取返回值的源码来看会更加理解这其中的门道。
/**
* 有返回值
*
* @param callable
* @param <T>
* @return
*/
public <T> Future<T> submit(Callable<T> callable) {
FutureTask<T> future = new FutureTask(callable);
execute(future);
return future;
}
submit() 非常简单,将我们丢进来的 Callable 对象转换为一个 FutureTask 对象,然后再调用之前的 execute() 来丢进线程池(后续的流程就和一个普通的线程进入线程池的流程一样)。
FutureTask 本身也是线程,所以可以直接使用 execute() 函数。
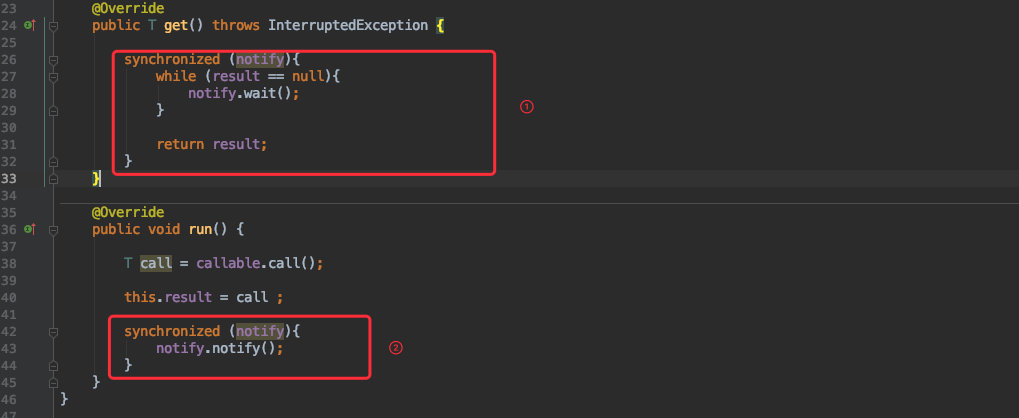
而 future.get() 函数中 future 对象由于在 submit() 中返回的真正对象是 FutureTask,所以我们直接看其中的源码就好。
![]()
由于 get() 在线程没有返回之前是一个阻塞函数,最终也是通过 notify.wait() 使线程进入阻塞状态来实现的。
而使其从 wait() 中返回的条件必然是在线程执行完毕拿到返回值的时候才进行唤醒。
也就是图中的第二部分;一旦线程执行完毕(callable.call())就会唤醒 notify 对象,这样 get 方法也就能返回了。
同样的道理,ThreadPoolExecutor 中的原理也是类似,只不过它考虑的细节更多所以看起来很复杂,但精简代码后核心也就是这些。
甚至最终使用的 api 看起来都是类似的:
![]()
异常处理
最后一个是一些新手使用线程池很容易踩坑的一个地方:那就是异常处理。
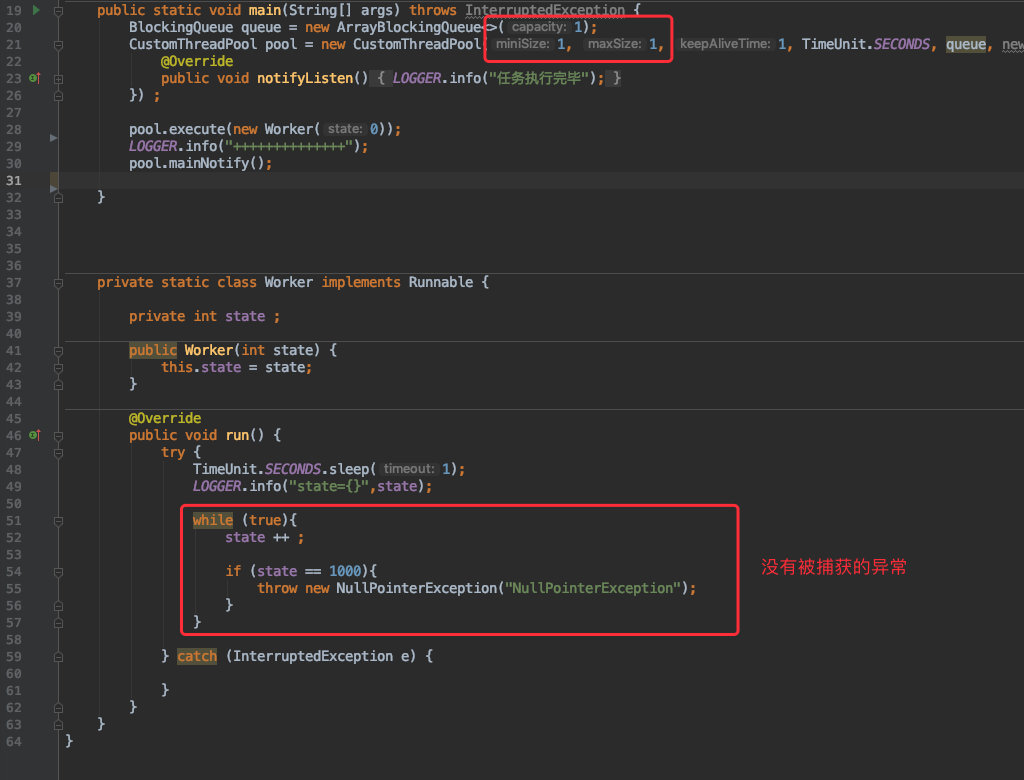
比如类似于这样的场景:
![]()
创建了只有一个线程的线程池,这个线程只做一件事,就是一直不停的 while 循环。
但是循环的过程中不小心抛出了一个异常,巧的是这个异常又没有被捕获。你觉得后续会发生什么事情呢?
是线程继续运行?还是线程池会退出?
![]()
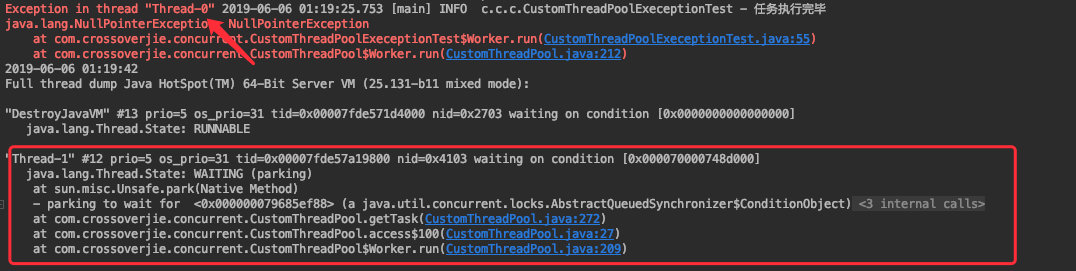
通过现象来看其实哪种都不是,线程既没有继续运行同时线程池也没有退出,会一直卡在这里。
当我们 dump 线程快照会发现:
![]()
这时线程池中还有一个线程在运行,通过线程名称会发现这是新创建的一个线程(之前是Thread-0,现在是 Thread-1)。
它的线程状态为 WAITING ,通过堆栈发现是卡在了 CustomThreadPool.java:272 处。
![]()
就是卡在了从队列里获取任务的地方,由于此时的任务队列是空的,所以他会一直阻塞在这里。
看到这里,之前关注的朋友有没有似曾相识的感觉。
没错,我之前写过两篇:
线程池相关的问题,当时的讨论也非常“激烈”,其实最终的原因和这里是一模一样的。
所以就这次简版的代码来看看其中的问题:
![]()
现在又简化了一版代码我觉得之前还有疑问的朋友这次应该会更加明白。
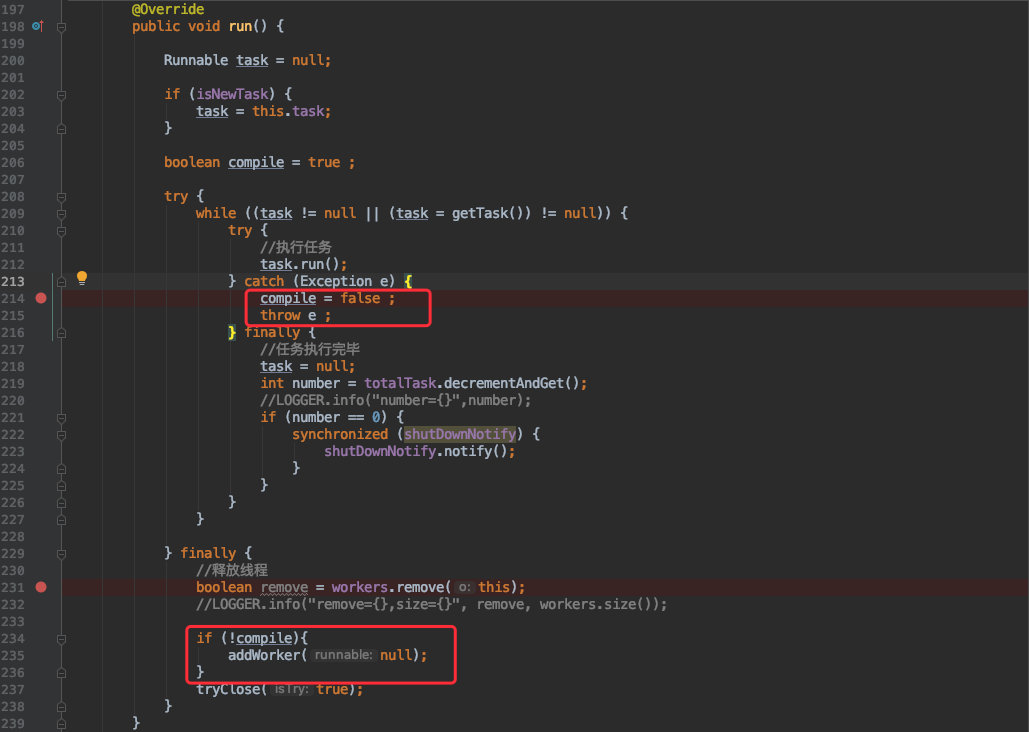
其实在线程池内部会对线程的运行捕获异常,但它并不会处理,只是用于标记是否执行成功;
一旦执行失败则会回收掉当前异常的线程,然后重新创建一个新的 Worker 线程继续从队列里取任务然后执行。
所以最终才会卡在从队列中取任务处。
其实 ThreadPoolExecutor 的异常处理也是类似的,具体的源码就不多分析了,在上面两篇文章中已经说过几次。
所以我们在使用线程池时,其中的任务一定要做好异常处理。
总结
这一波下来我觉得线程池搞清楚没啥问题了,总的来看它内部运用了非常多的多线程解决方案,比如:
ReentrantLock 重入锁来保证线程写入的并发安全。- 利用等待通知机制来实现线程间通信(线程执行结果、等待线程池执行完毕等)。
最后也学会了:
- 标准的线程池关闭流程。
- 如何使用有返回值的线程。
- 线程异常捕获的重要性。
最后本文所有源码(结合其中的测试代码使用):
https://github.com/crossoverJie/JCSprout/blob/master/src/main/java/com/crossoverjie/concurrent/CustomThreadPool.java
你的点赞与分享是对我最大的支持 ![]()