闲鱼网页版即将上线
继淘宝重启网页版优化工作后,近日官方又宣布了两项重要变化——上线「图片搜索」功能,以及预告闲鱼网页版(PC闲鱼)即将推出初步版本。 下面是官方公告: https://jianghu.taobao.com/detail/10521408 延伸阅读: 淘宝 (taobao.com) 重启网页版优化工作
社区中有两个流行的
本文重点介绍了 Accelerate 对外暴露的这两个后端之间的差异。为了让用户能够在这两个后端之间无缝切换,我们在 Accelerate 中合并了
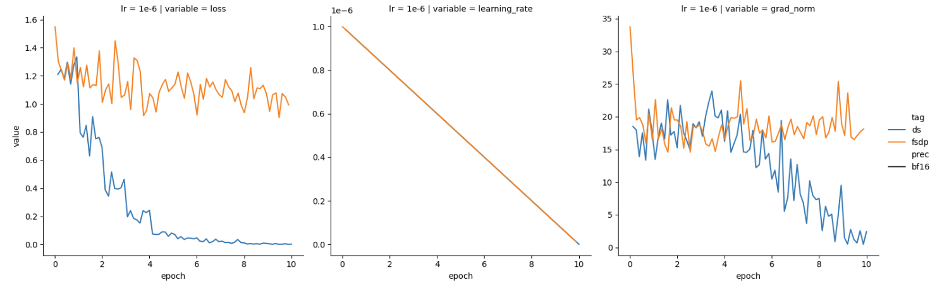
最近,我们尝试分别使用 DeepSpeed 和 PyTorch FSDP 进行训练,发现两者表现有所不同。我们使用的是 Mistral-7B 基础模型,并以半精度 (bfloat16) 加载。可以看到 DeepSpeed (蓝色) 损失函数收敛良好,但 FSDP (橙色) 损失函数没有收敛,如图 1 所示。
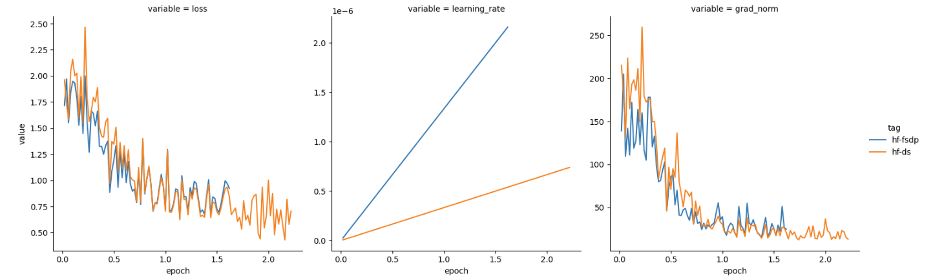
我们猜想可能需要根据 GPU 数量对学习率进行缩放,且由于我们使用了 4 个 GPU,于是我们将学习率提高了 4 倍。然后,损失表现如图 2 所示。
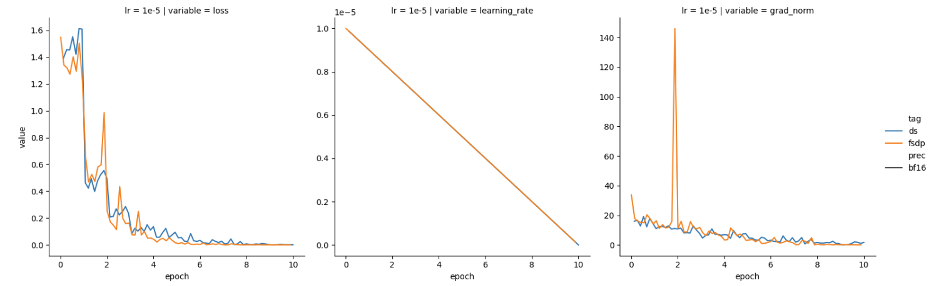
看起来,通过按 GPU 数量缩放 FSDP 学习率,已经达到了预期!然而,当我们在不进行缩放的情况下尝试其他学习率 (1e-5) 时,我们却又观察到这两个框架的损失和梯度范数特征又是趋近一致的,如图 3 所示。
在 DeepSpeed 代码库的 DeepSpeedZeroOptimizer_Stage3 (顾名思义,处理第 3 阶段优化器分片) 实现代码中,我们注意到 trainable_param_groups (可训参数组) 被传入一个内部函数 _setup_for_real_optimizer,该函数会调用另一个名为 _create_fp32_partitions 的函数。正如其名称中的 fp32 所示,DeepSpeed 内部执行了精度上转,并在设计上始终将主权重保持为 fp32 精度。而上转至全精度意味着:同一个学习率,上转后的优化器可以收敛,而原始低精度下的优化器则可能不会收敛。前述现象就是这种精度差异的产物。
在 FSDP 中,在把模型和优化器参数分片到各 GPU 上之前,这些参数首先会被“展平”为一维张量。FSDP 和 DeepSpeed 对这些“展平”参数使用了不同的 dtype,这会影响 PyTorch 优化器的表现。表 1 概述了两个框架各自的处理流程,“本地?”列说明了当前步骤是否是由各 GPU 本地执行的,如果是这样的话,那么上转的内存开销就可以分摊到各个 GPU。
| 流程 | 本地? | 框架 | 详情 |
|---|---|---|---|
模型加载 (如 AutoModel.from_pretrained(..., torch_dtype=torch_dtype)) |
❌ | ||
| 准备,如创建“展平参数” | ✅ | FSDP DeepSpeed |
使用 torch_dtype不管 torch_dtype,直接创建为 float32 |
| 优化器初始化 | ✅ | FSDP DeepSpeed |
用 torch_dtype 创建参数用 float32 创建参数 |
| 训练步 (前向、后向、归约) | ❌ | FSDP DeepSpeed |
遵循 遵循 deepspeed_config_file 中的混合精度设置 |
| 优化器 (准备阶段) | ✅ | FSDP DeepSpeed |
按需上转至 torch_dtype所有均上转至 float32 |
| 优化器 (实际执行阶段) | ✅ | FSDP DeepSpeed |
以 torch_dtype 精度进行以 float32 精度进行 |
表 1:FSDP 与 DeepSpeed 混合精度处理异同
几个要点:
float32。
DeepSpeed 中所做的那样) 对内存消耗的影响可能可以忽略不计。然而,当在少量 GPU 上使用 DeepSpeed 时,内存消耗会显著增加,高达 2 倍。
DeepSpeed 提供了更大的灵活性。
为了在🤗 Accelerate 中更好地对齐 DeepSpeed 和 FSDP 的行为,我们可以在启用混合精度时自动对 FSDP 执行上转。我们为此做了一个 PR,该 PR 现已包含在
有了这个 PR,FSDP 就能以两种模式运行:
混合精度模式
表 2 总结了两种新的 FSDP 模式,并与 DeepSpeed 进行了比较。
| 框架 | 模型加载 (torch_dtype) |
混合精度 | 准备 (本地) | 训练 | 优化器 (本地) |
|---|---|---|---|---|---|
| FSDP (低精度模式) | bf16 |
缺省 (无) | bf16 |
bf16 |
bf16 |
| FSDP (混合精度模式) | bf16 |
bf16 |
fp32 |
bf16 |
fp32 |
| DeepSpeed | bf16 |
bf16 |
fp32 |
bf16 |
fp32 |
表 2:两种新 FSDP 模式总结及与 DeepSpeed 的对比
我们使用
如上文,我们使用 4 张 A100 GPU,超参如下:
torch.bfloat16
torch.bfloat16 混合精度
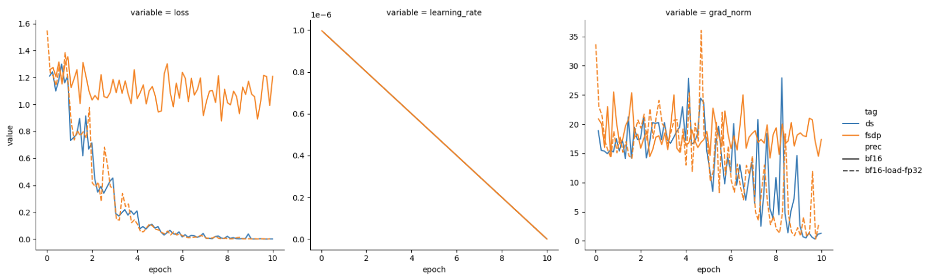
表 3 表明 FSDP 和 DeepSpeed 的表现类似,这与我们的预期相符。
随着大规模对齐技术 (如
InstructLab 及GLAN ) 的流行,我们计划对结合各种提高吞吐量的方法 (如,序列组装 + 4D 掩码、torch.compile、选择性 checkpointing) 进行全面的吞吐量对比基准测试。
| 框架 | 每 GPU 每秒词元数 | **每步耗时 (s) ** | **浮点算力利用率 (MFU) ** |
|---|---|---|---|
| FSDP (混合精度模式) | 3158.7 | 10.4 | 0.41 |
| DeepSpeed | 3094.5 | 10.6 | 0.40 |
表 3:四张 A100 GPU 上 FSDP 和 DeepSpeed 之间的大致吞吐量比较。
我们提供了新的
我们在 🤗 Accelerate 中考虑了配置这些框架的各种方式:
accelerate launch 从命令行配置
Plugin 类中配置
🤗 Accelerate 使得在 FSDP 和 DeepSpeed 之间切换非常丝滑,大部分工作都只涉及更改 Accelerate 配置文件 (有关这方面的说明,请参阅新的概念指南) 。
除了配置变更之外,还有一些如检查点处理方式的差异等,我们一并在指南中进行了说明。
本文中的所有实验都可以使用
我们计划后续在更大规模 GPU 上进行吞吐量比较,并对各种不同技术进行比较,以在保持模型质量的前提下更好地利用更多的 GPU 进行微调和对齐。
本工作凝聚了来自多个组织的多个团队的共同努力。始于 IBM 研究中心,特别是发现该问题的 Aldo Pareja 和发现精度差距并解决该问题的 Fabian Lim。Zach Mueller 和
英文原文: https://hf.co/blog/deepspeed-to-fsdp-and-back
原文作者: Yu Chin Fabian, aldo pareja, Zachary Mueller, Stas Bekman
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
本文分享自微信公众号 - Hugging Face(gh_504339124f0f)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
马里奥是站在游戏界顶峰的超人气多面角色。马里奥靠吃蘑菇成长,特征是大鼻子、头戴帽子、身穿背带裤,还留着胡子。与他的双胞胎兄弟路易基一起,长年担任任天堂的招牌角色。
为解决软件依赖安装时官方源访问速度慢的问题,腾讯云为一些软件搭建了缓存服务。您可以通过使用腾讯云软件源站来提升依赖包的安装速度。为了方便用户自由搭建服务架构,目前腾讯云软件源站支持公网访问和内网访问。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273