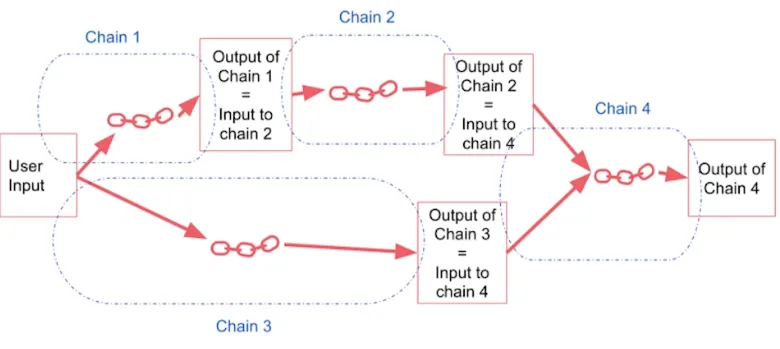
RAG、text2api、text2sql、澄清反问和生成图表,都是大模型应用中经常使用的不同类型的任务或功能。为了优化和提升大模型在处理复杂任务时的表现,通常把它们以链的方式串起来。在这些链中,又包含不同的子过程,它们之间可能存在嵌套、回退、跳转、并行、汇总等复杂的处理逻辑。
![]()
顺序链(图片来源:https://mpspatel555.medium.com/develop-apllication-with-llm-and-langchain-e1ba3df1cea5)
因此,在函数式大模型应用中常常会面临以下挑战:
-
链路过长与调用复杂性:在复杂的函数式架构中,由于函数相互调用形成的长链路和深层嵌套,可能导致系统难以理解和维护。这种结构增加了监控的难度,使得故障排查和性能分析变得更加复杂。当函数调用路径非线性增加时,问题定位和调试尤为困难。
-
性能瓶颈识别与优化难题:在函数式编程模型中,由于函数的纯度和不可变性原则,虽然有助于逻辑清晰和测试,但这也可能使得定位和优化性能瓶颈变得更加困难。没有明确的状态变化和副作用,跟踪函数执行的资源消耗和时间成本可能需要更细致的监控机制和分析工具。
-
模型用量与性能监控不足:在大型模型应用中,缺乏有效的监控工具来实时追踪每个子函数或组件的资源使用情况(如CPU、内存、IO等),这限制了对系统性能的精细管理和优化。特别是当模型规模庞大、调用层级深时,监控的缺失会直接影响到对系统效率和稳定性的把控。
-
参数传递与扩展性问题:函数式编程在处理参数传递时,尤其是在大模型应用中,若参数过多或参数结构复杂,可能会导致信息传递不畅,尤其是在算法端与前端之间。这不仅影响了系统的扩展性,还限制了新功能或参数的灵活添加。为了保持函数的纯净性,每次参数变更可能都需要重新设计函数接口,这在大型项目中可能会引发连锁反应,增加开发成本。
而对于包含超过200个子过程、10多条分支的复杂大模型应用来说,其难度还要再上一层。针对上述问题,枫清科技(Fabarta)大语模型算法专家王斐设计了一套针对复杂大模型应用的监控方案,基于监控结果可以实现用量统计、性能分析、log 收集、评估等功能。主要从以下几个方面来实现:
-
性能分析:分析火焰图和时序图,找出性能瓶颈,并发执行可拆分、可并行的模块,如:并发执行意图确认和生成链路。
-
对话评估:通过自动化评估找到薄弱环节,如:在链路中加入 text2api 参数、text2sql 数据项澄清和反问,提高大模型在智能问数场景下的正确率和用户体验。
-
用量监控:监控链路中不同过程的 prompt 长度,当 prompt 超长时,允许回退到其它子链路,如:重新召回、切换模型。
-
基于 json config 的前后端分离开发模式:使用统一的 json config 管理前后端参数。
关于这套方案的更多细节,可以关注 2024 亚太人工智能与机器人产业峰会暨 GOTC 全球开源技术峰会,在”LLMOps 最佳实践”论坛上,王斐将基于这套监控方案,分享其在 LLMOps 方面的实践经验。王斐在枫清科技负责大模型应用的底层架构和解决方案研发,曾任职 IBM 数据科学家,在计算机视觉、大模型项目落地有丰富经验。
“LLMOps 最佳实践” 论坛还将邀请广东智用人工智能应用研究院工业 & 社区 CTO 张善友,小码科技创始人、Agents-Flex 作者杨福海,微软高级云技术布道师(人工智能方向)卢建晖,阿里云技术专家蔡健,全栈工程师、LLM 技术科普作者莫尔索等,带领开发者探索和分享 LLMOps 的最新实践、技术和工具,深入讨论如何高效、可靠地管理和运维大规模语言模型,确保它们在生产环境中的最佳性能。
参会报名,请访问:https://www.oschina.net/news/297185
![]()
2024 亚太人工智能与机器人产业峰会暨 GOTC 全球开源技术峰会由中国人工智能学会与开源中国联合举办,将于 7 月 13-14 日在杭州隆重举行。本次峰会将汇聚全球顶尖的专家、学者、企业领袖及开源技术代表,深入探讨机器人技术、软件开发、开源技术和 AI 大模型等前沿领域。
会议将重点展示机器人在制造、医疗、物流和服务等行业的最新应用,探讨智能算法和自主学习能力如何提升机器人性能,并分享开源技术在推动技术创新与协作中的关键作用。此外,峰会还将关注 AI 大模型的最新研究进展及其在实际应用中的挑战与机遇。
![]()