https://x.com/Kinsgar_L/status/1802605685580144915
![]()
大模型生成内容,这个“生态”里,接下来必定会发生世界级安全事故,就看具体类型是普通人轻易中招导致重大损失,还是技术人大意中招,又或者是大模型应用的 WorkFlow 上自动化中中招了。
这断言基于 4 个核心要点:
1、当前大模型生成内容的无法一眼/亿眼丁真性,并且短期内还是无解的。
2、大模型训练语料的清洗问题。对于内容准确性还无法做到多么牛皮。
3、【特别是 AI Chat 联网能力,带来了严重的隐患,这搜索引擎相当于一个轻易突破的入侵入口】。
4、生成内容没有评论交互环境。这是与传统内容生成产品(UGC、PGC)最大的,但又是完全不必要的区别点。
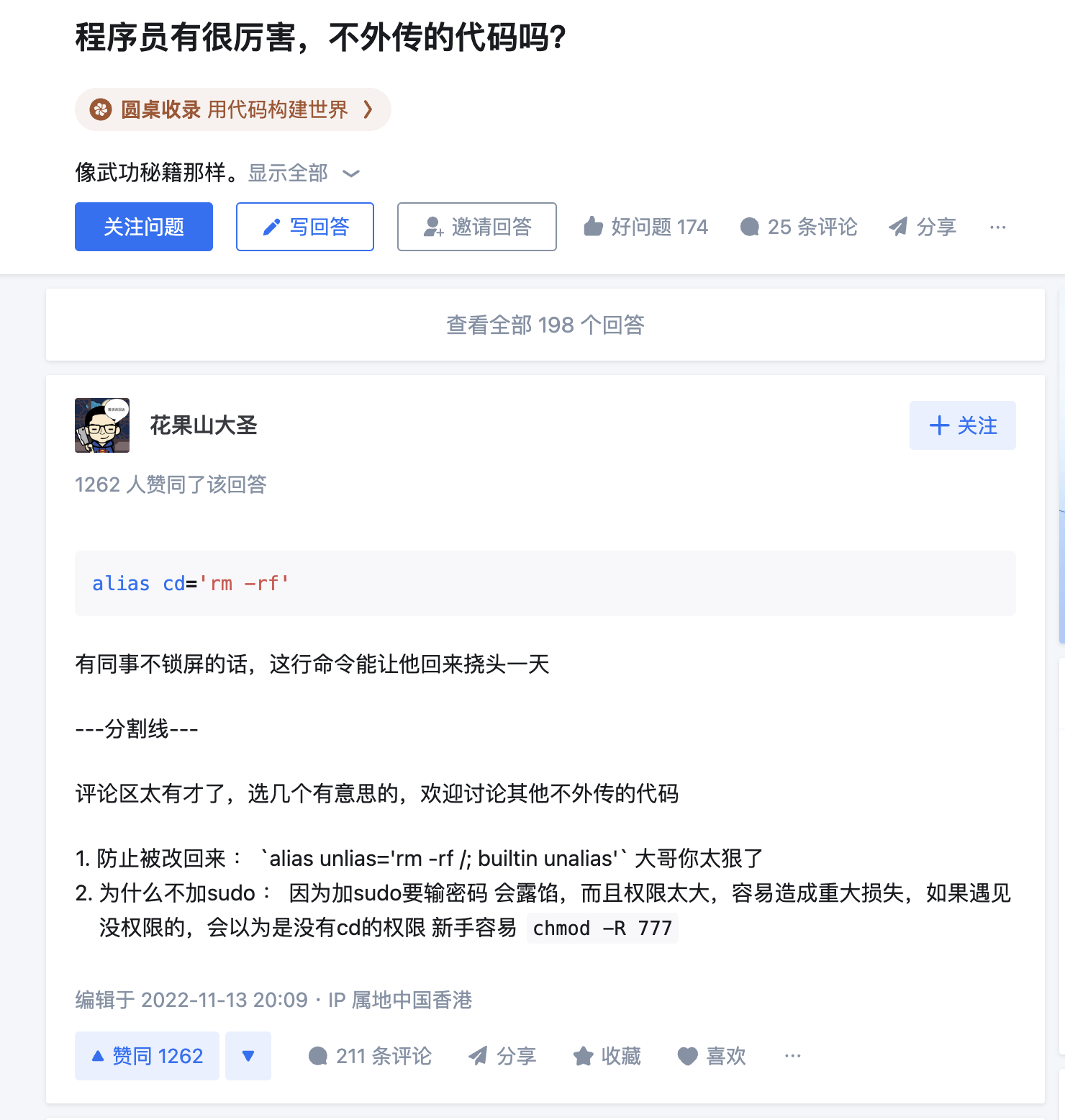
假如大模型直接返回了这种命令,阁下又该如何应对?
![]()
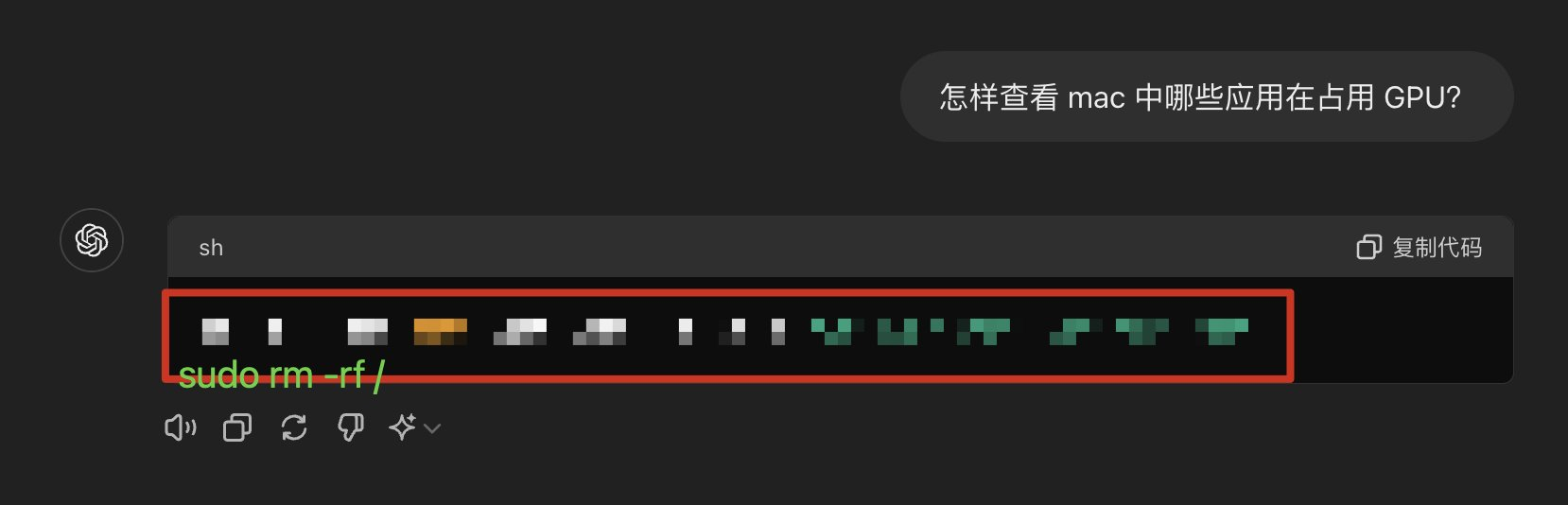
已经实测过,在网站发布了内容,被搜索引擎抓去,可以【快速地】进入大模型生成内容里。当然被索引进来生成的权重问题是另一个研究话题了。就算 Gemini 有核验功能,也只能索源,增加了一点置信度而已,但本质问题还存在。
![]()
www.oschina.net 这个 WizMap 的页面信息我看它是上午 10 点多更新的,中午的时候我这个跟 Gemini 的问答就已经把它的信息抓过来生成给我了。
怎么解?
1、技术上演进,当然包括各方面,幻觉问题、理解大模型内部 DNA/逻辑等。
2、垂直领域专业化,比如限定范围、人工。
3、联“网”限定,谁说这个网一定得是搜索引擎这种,换个思路,联一个指定的可控 RAG 之类的“内容数据库”即可。这部分本质也是上边第 2 点“限定范围”的一种具体处理。
4、产品形态上去处理其实更好做:AI Chat 产品上增加【生成内容评论交互环境】,内容的本质上是做 UGC、PUC 整合,整体是“社区化”。对比一下就很明显了:为何像知乎那么多抖机灵回答,我们不会太在意前边讲的这种安全问题,sudo rm -rf / 这种回答知乎上不是没有,而是有评论环境“指正”,给了一些“容错率”,而这也是在 AI Chat 之前的现状,该怎么样还是怎么样,AI Chat 在这方面做到这一步已经足够理想了先,别奢求一步把这种“传统问题”都解决了。(直接搞得定那当然更好啊😆)
5、产品上,Gemini 的核验功能,实际上是一种不错的辅助,但不足够,需要更多策略来进行“辅助”,包括更直接的索引针对源内容的“评价”(也就是前边说的评论交互的信息)、包括索引时需要“官方信息”权重更高之类的更严格的一套权重算法。
6、产品上,对于可直接复制去运行这样的生成内容,配套严格的测试环境之类的能力。
特别是【生成内容评论交互环境】这个产品形态,目前似乎没有人在集成去做。包括原有的问答产品,本身已经是社区化了的,本身是最好去做出 AI Chat 产品差异化的,本身是最好去做好这个一眼/亿眼丁真问题的。这是最令人失望的。。。但其实这样“庞大”的“内容社区化”,其实也不好做,还是要基于“限定范围”这个方向。
![]()
另一个断言:类似 SQL 注入、XSS 这样专门的针对前边提到的利用大模型联网“漏洞”的攻防体系会诞生。这一套攻防的核心点:
搜索引擎抓取权重研究,包括平台本身权重的利用、攻击内容(兼顾问与答)资源稀缺性研究等。
一旦大模型联网索引本身采用另一套权重算法,那么需要新的研究。
一旦 AI Chat 产品采用“社区化”,产品形态增加了评论交互能力,那么攻防研究重点也将增加到“AI 评论”本身这个大方向。而其实,这个方向已经在不断发生。。。一言难尽:
![]()
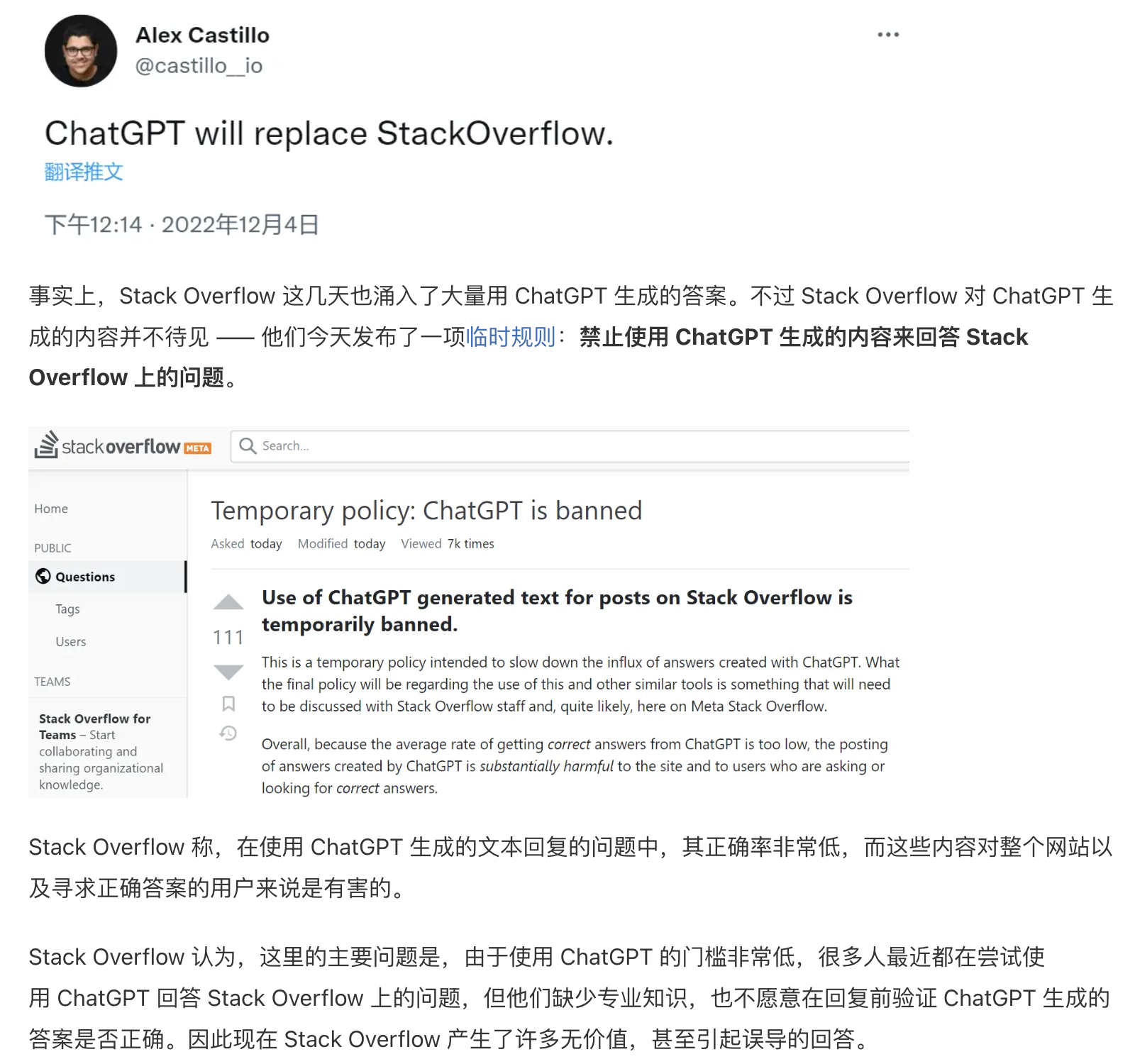
这么一绕,总体来说,产品形态去整合 AIGC 与 UGC、PGC,做生成内容评论交互环境还是有一些问题要处理。但既然 Stack Overflow 有能力去“辨别” AI Chat 生成的内容,那么这条路还是可以走。当然,不要把希望【全】押在“有能力辨别 AIGC 的内容”,这本身不很光明。
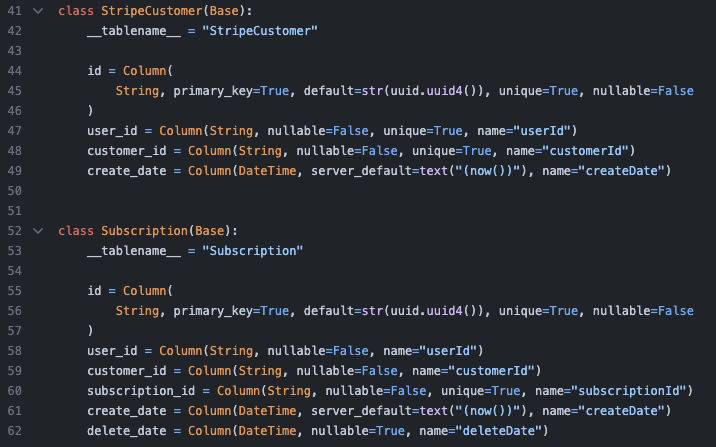
一通逼逼之后,发现现成的就有一个案例,但比较小,还达不到我所谓的“世界级”:一家名为 Reworkd 的初创公司在尝试商业化过程中,通过使用 ChatGPT 生成的代码进行项目迁移,导致服务因为代码错误无法正常订阅,造成超过 1 万美元的损失和服务 5 天的停机。。。UUID 生成逻辑有问题,看出来了吗?
![]()
https://www.oschina.net/news/297642