背景
在之前我们提到采用自定义的内存分配器来解决防止频繁 make 导致的 gc 问题。gc 问题本质上是 CPU 消耗,而内存分配器本身如果产生了大量的 CPU 消耗那就得不偿失。经过测试初代内存分配器实现过于简单,产生了很多 CPU 消耗,因此必须优化内存分配器的性能。
性能消耗原因
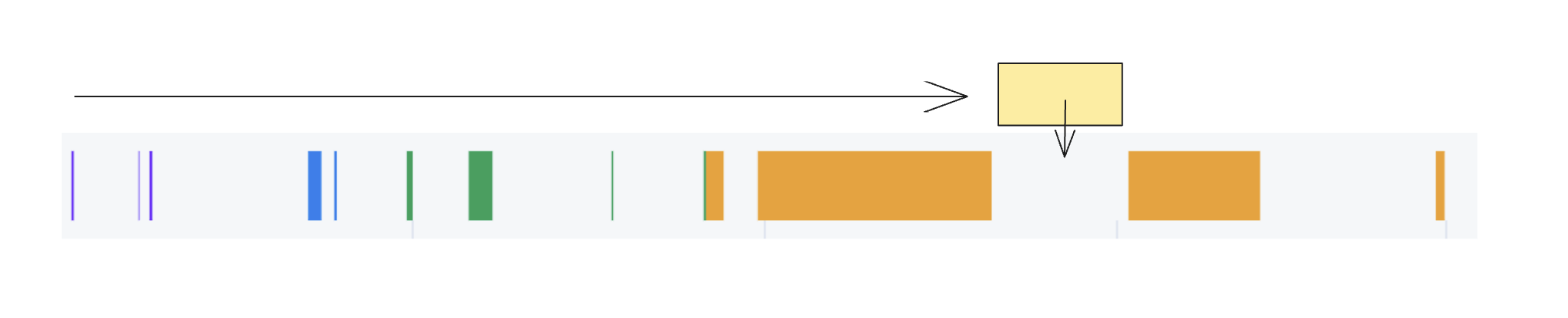
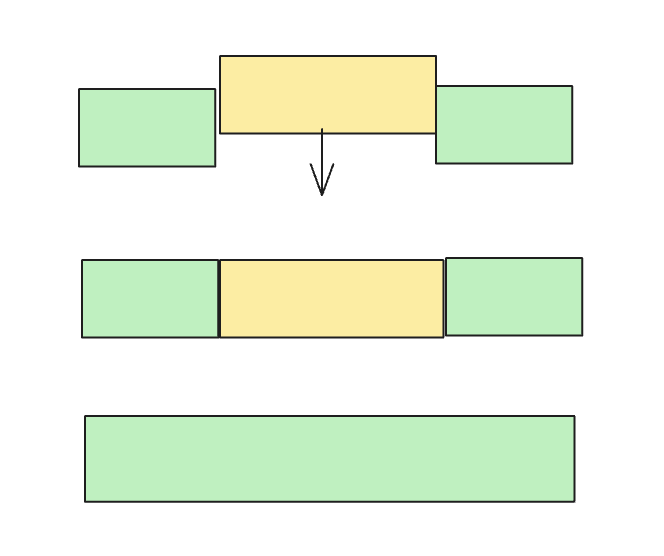
在内存的分配和回收上,使用了简单的循环检测,当内存碎片较多的时候,循环查找消耗非常可观
查找可分配的内存
![]()
找到回收的内存偏移
![]()
性能优化
很快在社区中大家给出了一个称为 Buddy 的内存分片算法,那么这个算法是否能解决问题呢?
Buddy 算法
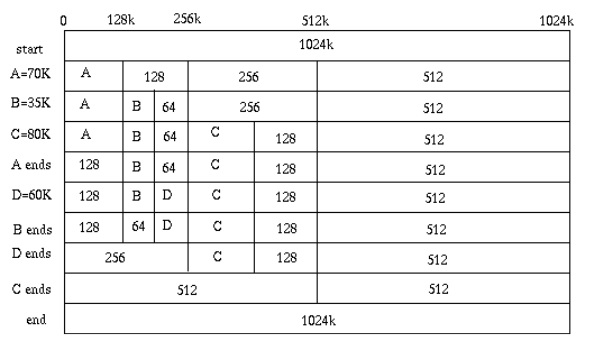
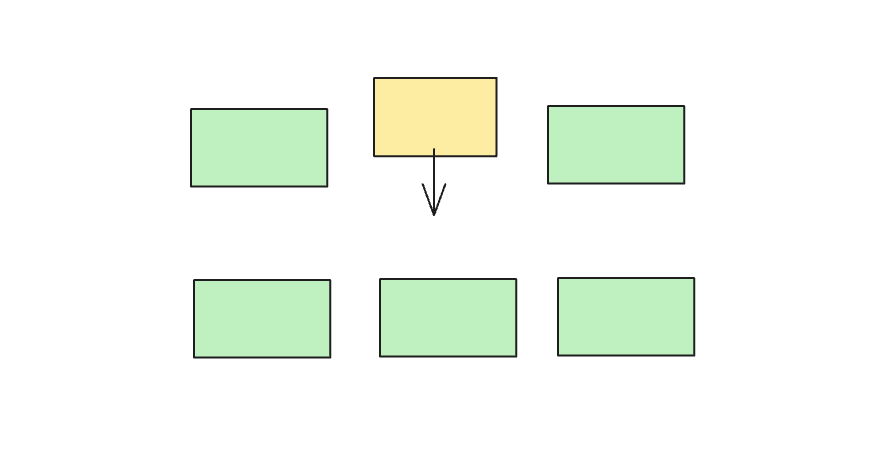
这是一个非常高效的算法,采用的是满二叉树数据结构,用一个数组来表示,然而当实际使用时却遇到了问题,因为我需要在自研的 BufReader 中使用,因此不能出现内存缝隙。Buffdy 算法在回收内存时只能按照申请什么回收什么的原则。举例,我申请了一个var a []byte = alloc(100),那么回收必须也是回收 free(a)。而自研的 BufReader,需要“部分回收”能力。比如先回收a[50:],然后再回收a[:50]。那么 Buddy 算法将无能为力。
![]()
当然,这个算法最终还会用到,这里先留个悬念。
双圣树模型
这是我自己起的名字,实际上是利用两颗平衡二叉树来实现快速找到可分配的内存以及快速回收内存。
type Allocator struct {
pool []*Block
sizeTree *Block
offsetTree *Block
Size int
// history []History
}
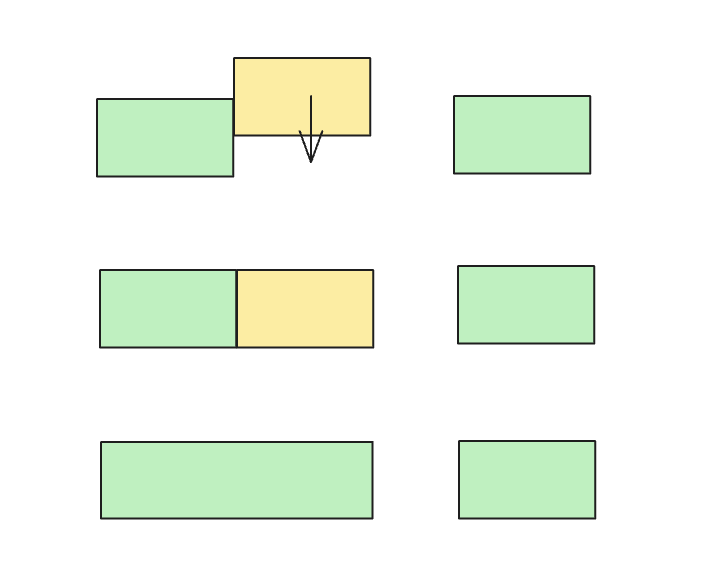
分配树
这颗树,用来快速查找可分配的内存,我们将可分配的内存用一个节点表示
type Block struct {
Start, End int
trees [2]Tree
}
sizeTree 通过对每个节点的大小(End-Start)进行排序,在分配时,通过查找树中刚好大于等于待分配大小的节点,再修改这个节点,对树进行平衡即可。
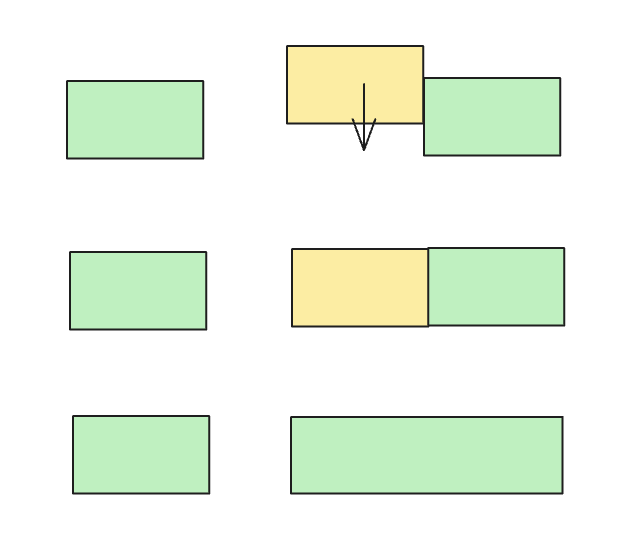
回收树
这颗树,用来找到回收内存块前后的 Block,通过合并或者插入 Block 达到回收内存的效果。
共享节点
由于两棵树只是表达了不同的排序,里面所有节点的数量和属性都是相同的,因此不需要两套节点,只需要公用一套节点集合即可。
type Tree struct {
left, right *Block
height int
}
每个节点有两套指针,分别指向两棵树的不同的子节点,从而在逻辑上形成了两棵树。
进阶优化
虽然我们最终通过双圣树模型,实现了内存分配器的性能优化,但是优化并没有因此而停止。因为上述的内存分配器是无锁的,只适合给单个 goroutine 使用,如果加锁则性能大打折扣。那么从宏观角度来说,分配器持有的大内存块也会存在需要回收的情况。比如在流销毁的时候。
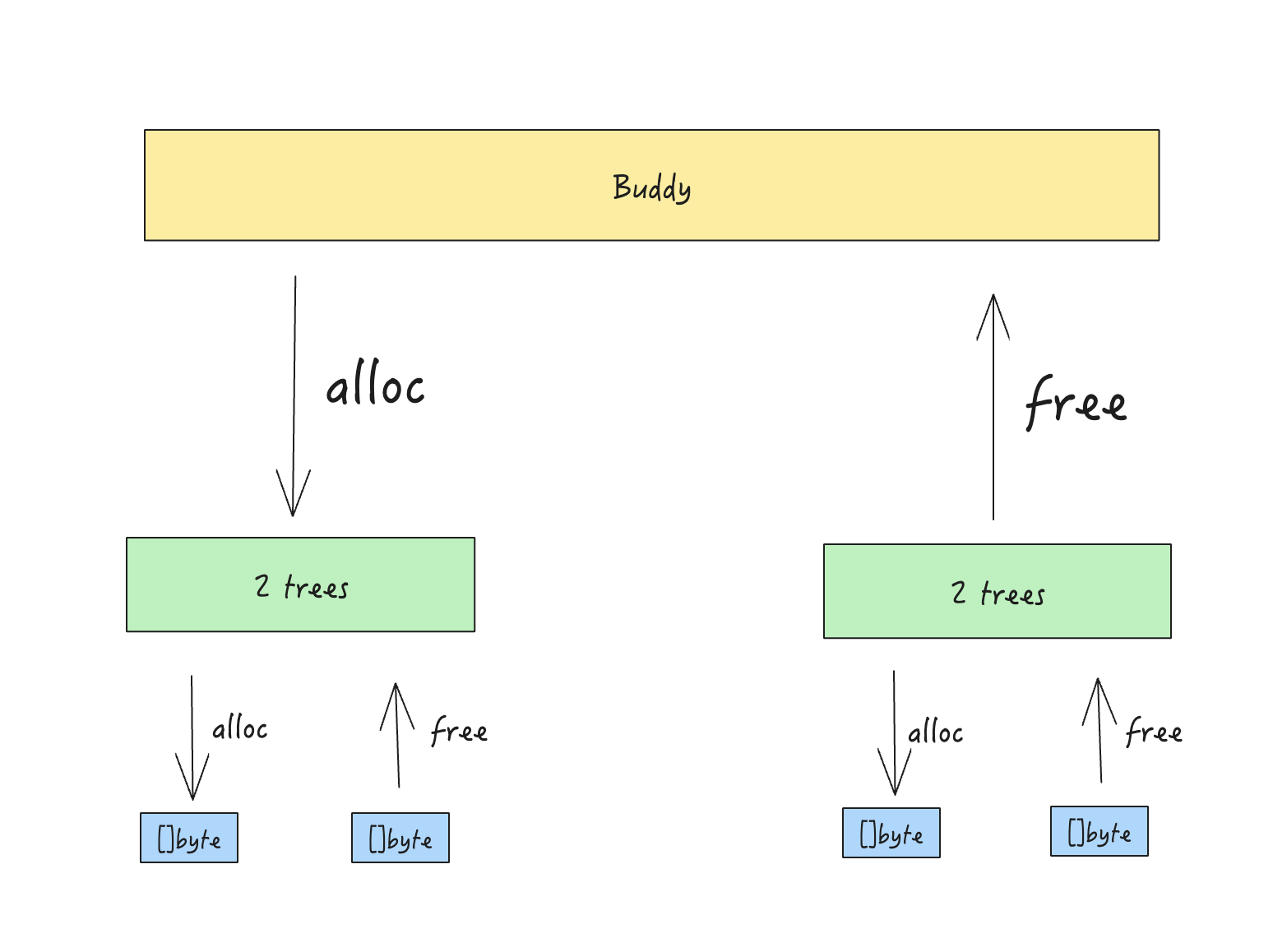
再次使用 Buddy 算法
这时候大内存块就不需要部分回收了,此时就又可以采用 Buddy 算法了。我们只需要在申请大内存块时,按照 2 倍数来申请,可以最大化利用。最终我们形成了两级内存分配。当然在这里就需要用锁了。
![]()
最终优化后性能得到大幅度提升
v5 版本通过 github.com/langhuihui/monibuca 切换到 v5 分支测试,或者gitee.com/m7s/monibuca。
进入仓库的 exsamle/default目录下运行 go run main.go即可体验。目前 v5 功能比较有限,目前仅能测试 rtmp 、hdl、webrtc 部分功能。