引言
近年来,"Ops"一词在 IT 运维领域的使用迅速增加。IT 运维正在向自动化过程转变,以改善客户交付。传统的应用程序开发采用 DevOps 实施持续集成(CI)和持续部署(CD)。但对于数据密集型的机器学习和人工智能(AI)应用,精确的交付和部署过程可能并不适用。
本文将定义不同的"Ops"并解释以下几种:DevOps、DataOps、MLOps 和 AIOps 的工作原理。
DevOps
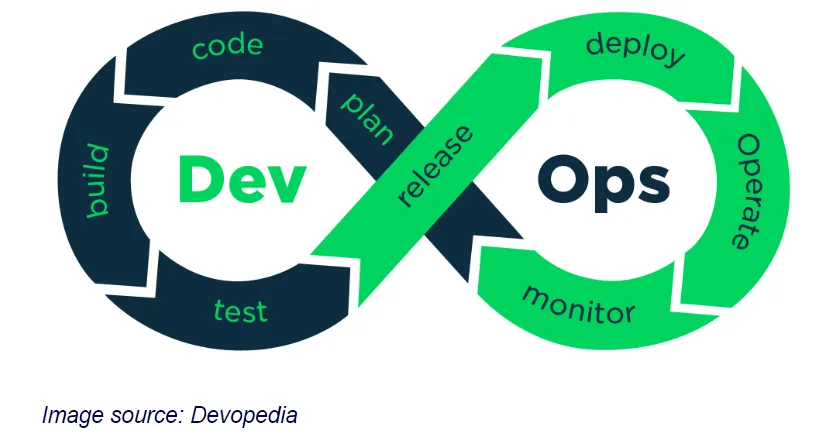
这一实践自动化了开发(Dev)和运营(Ops)之间的合作。主要目标是更快、更可靠地交付软件产品,并持续提供软件质量。DevOps 补充了敏捷软件开发过程/敏捷工作方式。
![file]()
DataOps
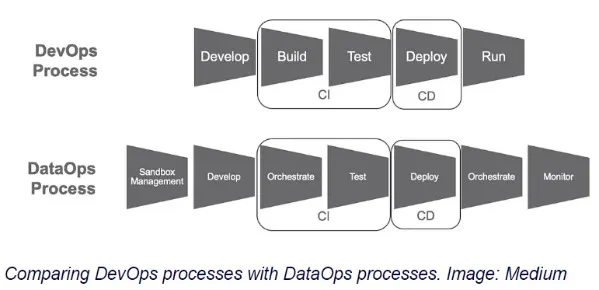
DataOps 是一种实践或技术,结合了集成的、面向流程的数据与自动化,以提高数据质量、协作和分析。
![file]()
它主要涉及数据科学家、数据工程师和其他数据专业人员之间的合作。DataOps 与 DevOps 的比较。
MLOps
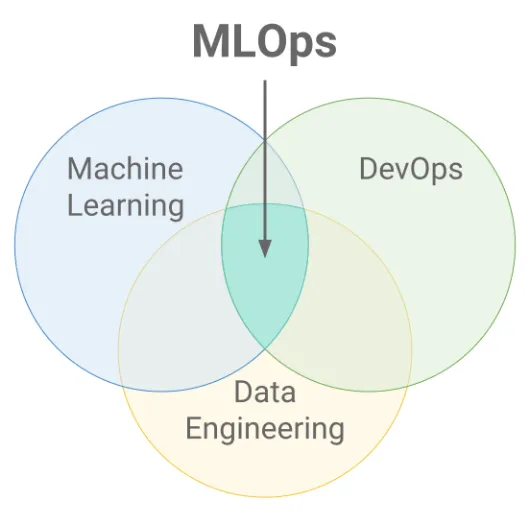
MLOps 是一种实践或技术,可靠且高效地开发和部署机器学习模型。
MLOps 是 DevOps、ML 和数据工程交集处的一套实践。
![file]()
AIOps
AIOps 是自动化和简化自然语言处理和机器学习模型的运营工作流的过程。机器学习和大数据是 AIOps 的主要方面,因为 AI 需要来自不同系统和过程的数据,并使用 ML 模型。AI 通过机器学习模型创建、部署、训练并分析数据以获得准确结果。
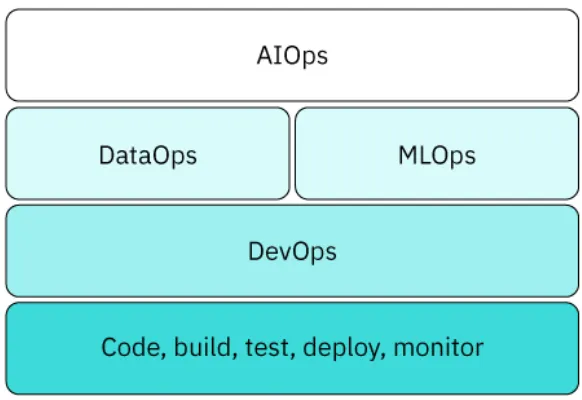
根据 IBM Developer 的说法,以下是典型的"Ops"如何协同工作:Ops 协同工作。
![file]()
图片来源:IBM
综合比较
下表描述了 DevOps、DataOps、MLOps 和 AIOps 之间的比较:
* 方面 * DEVOPS * DATAOPS * MLOPS * AIOPS * *-----------*------------------------------------------*-----------------------------------------*-----------------------------------------*----------------------* * 焦点 * IT 运维和敏捷方式的软件开发 * 数据质量、协作和分析 * 机器学习模型 * IT 运维 * * 关键技术/工具 * Jenkins, JIRA, Slack, Ansible, Docker, Git, Kubernetes, Chef * Apache DolphinScheduler , Databricks, Data Kitchen, Apache SeaTunnel * Python, TensorFlow, PyTorch, Jupyter, Notebooks * 机器学习, AI 算法, 大数据, 监控工具 * * 关键原则 * IT 流程自动化、团队协作与沟通、持续集成和持续交付 (CI/CD) * 数据协作、数据管道自动化与优化、数据构件的版本控制 * 机器学习模型、版本控制、持续监控与反馈 * IT 事件的自动化分析与响应、主动问题解决、IT 管理工具集成、通过反馈持续改进 * * 主要用户 * 软件和 DevOps 工程师 * 数据和 DataOps 工程师 * 数据科学家和 MLOps 工程师 * 数据科学家、大数据科学家和 AIOps 工程师 * * 用例 * 微服务、容器化、CI/CD、协作开发 * 数据摄取、处理转换数据、数据提取到其他平台 * 用于预测分析和 AI 的机器学习 (ML) 和数据科学项目 * IT AI 运维以增强网络、系统和基础设施 *
总结
总之,由于业务流程变得越来越复杂,IT 系统随着新技术的动态变化,单一项目团队管理系统的时代已经结束。详细的实施涉及协作实践、自动化、监控的结合,以及作为 DevOps、DataOps、MLOps 和 AIOps 过程的一部分的持续改进的重点。
DevOps 主要关注 IT 流程和软件开发,而 DataOps 和 MLOps 方法则关注改进 IT 和业务的协作以及组织中的整体数据使用。DataOps 工作流程利用 DevOps 原则来管理数据工作流。
原文链接来自于:https://dzone.com/articles/comparison-of-all-ops
本文由 白鲸开源科技 提供发布支持!