引言
Prometheus 已经成为监控和报警生态系统的基石,在高效、直接地处理实时指标(Metric)方面有着强大的表现。Prometheus 的核心是一个包含单个值和一系列标签的数据模型。这种设计在提升简单性和适应性的同时,也带来了一些挑战,包括影响数据收集效率、分析深度和查询能力。
本文探讨了 Prometheus 单值数据模型的固有限制,GreptimeDB 如何成为一个解决这些问题的创新方案,并结合若干实例说明其中的差别。
单值数据模型的挑战
1. 数据收集中的冗余标签传输
Prometheus 的数据模型要求测度(Measurement)上报时总要携带同一来源的所有标签,当测量需求涉及多个值时,意味着重复传输这些标签,从而导致数据收集和存储效率低下。虽然 Prometheus 的存储引擎优化了数据存储,但标签信息冗余问题仍是一个重大的开销。
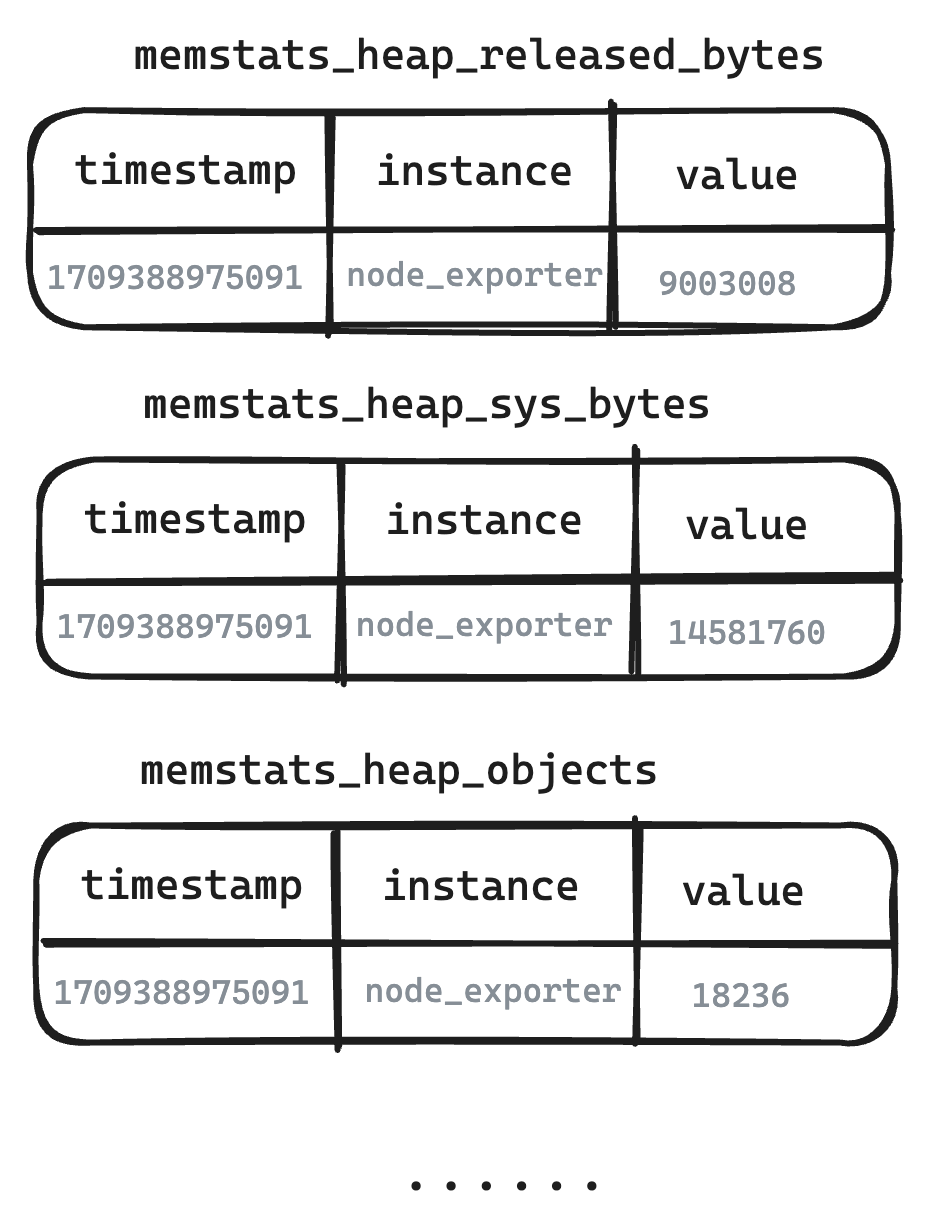
示例:在从服务器集群收集 CPU 使用率、内存使用量和磁盘 I/O 等多个指标的场景下,每个指标都携带相同的标签,如 cluster_name、region、instance 和 server_type,这就导致了不必要的重复。
![示例图:instance 标签在三个指标中重复出现]()
示例图:instance 标签在三个指标中重复出现
- 丢失测度(Measurement)之间的关联
在没有结构化分组或继承的机制的情况下,把相关的多个测度分隔成独立的指标,将会丢失测度之间的关联。这种分隔将使关联分析和查询变得困难,也限制了对指标之间相互影响的洞察。
示例:以监控 Redis 为例,使用多个指标来分别跟踪内存使用量、命令处理率和活动连接等行为,会使得分析它们之间的相互影响非常困难。例如,内存使用量如何影响命令处理效率。
- 查询复合监控视图的复杂性
创建全面的监控仪表板,需要从多个独立的 PromQL 查询中聚合数据,但这样的构建逻辑会使仪表板构建复杂化并增加不必要的查询开销。
示例:有效监控一个 Kubernetes 节点的仪表板需要聚合 CPU 负载、内存消耗、网络 I/O 和 pod 计数等多个指标,每个指标都需要单独地进行 PromQL 查询,但这样的行为会复杂化仪表板的设置,甚至可能影响性能。
GreptimeDB 的解决方案
为了应对上述挑战,GreptimeDB 在支持 PromQL 查询时,实现了一个创新解决方案来规避单值模型的局限。
1. 相关指标成组地聚合存储
GreptimeDB 为这类监控场景开发了 Metric Engine 存储引擎。它支持在底层聚合存储多个测度,而在应用层呈现出单值模型的视图。这大幅降低了存储成本,并提高了查询若干相关的测度时的性能。
2. 多值采样和不同的值类型
GreptimeDB 允许来自单一数据源的样本存储多个值,支持浮点数等多种值类型。
示例:监控 Redis 在一个或多个时间序列中存储的数据,其中标签作为独立的标签列存储,分组测量作为不同的字段列。这种方法减少了标签传输的冗余,保留了数据关联性,并能够优化相关的分析和查询性能。
![监控 Redis 提取多个数据值]()
示例图:监控 Redis 提取多个数据值
3. 扩展 PromQL 以查询多个字段
GreptimeDB 增强了 PromQL 以允许查询并返回多个字段值的能力。要指定特定字段,可以使用扩展的 __field__ 标签。
示例:查询 memstats{ __field__ = "used_bytes", __field__ = "free_bytes"},可以获取两个时间序列并一起渲染。这种扩展简化了复合监控视图下的查询,降低了组建具体仪表板负载的复杂性。
4. 支持表模型和 SQL 进行高级关联分析
GreptimeDB 的核心优势之一就是强大的分析能力,表现为支持表模型和使用 SQL 查询数据,这一能力在进行关联分析和执行复杂查询时,可以实现远超 PromQL 的灵活性。基于关系模型,用户可以连接多个数据集进行关联分析,更深入且细致地挖掘监控系统数据的价值。
示例:在复杂的监控场景中,需要将服务器性能指标与应用错误日志相关联,GreptimeDB 允许用户使用 SQL 一起查询这些数据。比如,执行一个 SQL 查询时,可以根据时间戳将 CPU 使用率的指标与应用错误日志关联起来,就能够提供 CPU 使用率上升与错误率增加的关联的监控视角。如果仅用 PromQL 来实现这种分析,即便可行,实现过程也会非常繁琐复杂。
👀 (P.S. GreptimeDB 正在实现专业的日志存储支持,敬请期待)
支持表模型和 SQL 查询,让 GreptimeDB 能够帮助用户从传统 SQL-based 系统平滑地切换到专业的时序数据栈上。同时这也使得用户无需应对 PromQL 陡峭的学习曲线,直接开始深入挖掘时序数据价值,包括基于监控数据的进行基本展示,完成复杂的性能分析,排查系统存在的故障等一系列广泛的分析任务。这是 GreptimeDB 的技术创新为监控数据获取、存储和实用化带来的一大进步。
结论
尽管 Prometheus 的单值数据模型有助于用户简单上手,并且目前已经被广泛采用,但是它在数据收集效率、测度关联性和查询复杂性方面都面临明显的挑战。GreptimeDB 的解决方案克服了这些限制,提供了更有效的数据收集方法,增强了关联分析,并简化了查询,能够帮助用户高效获取全面的监控视图。
GreptimeDB 作为开源项目,欢迎对时序数据库、Rust 语言等内容感兴趣的同学们参与贡献和讨论。第一次参与项目的同学推荐先从带有 good first issue 标签的 issue 入手,期待在开源社群里遇见你! Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb 微信搜索 GreptimeDB,关注公众号不错过更多技术干货和福利~
关于 Greptime
Greptime 格睿科技专注于为物联网(如智慧能源、智能汽车等)及可观测等产生大量时序数据的领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前主要有以下三款产品:
GreptimeDB 是一款用 Rust 语言编写的开源时序数据库,具有云原生、无限水平扩展、高性能、融合分析等特点,帮助企业实时读写、处理和分析时序数据的同时,降低长期存储的成本。我们提供 GreptimDB 企业版,支持更多功能和定制化服务,如有需要欢迎联系小助手。
GreptimeCloud 是一款全托管的云上数据库即服务(DBaaS)解决方案,基于开源时序数据库 GreptimeDB 打造,能够高效支持可观测、物联网、金融等领域的应用。用户可以通过内置的可观测解决方案 GreptimeAI 全面地掌握 LLM 应用的成本、性能、流量和安全等情况。
车云一体解决方案 是一款深入车企实际业务场景的车云协同数据解决方案,解决了企业车辆数据呈几何倍数增长后的实际业务痛点。多模态车端数据库结合云端 GreptimeDB 企业版帮助车企极大降低流量、计算和存储成本,并帮助提升数据实时性和业务洞察能力。
GreptimeDB 作为开源项目,欢迎对时序数据库、Rust 语言等内容感兴趣的同学们参与贡献和讨论。第一次参与项目的同学推荐先从带有 good first issue 标签的 issue 入手,期待在开源社群里遇见你!
官网:https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime