01 背景一览
在时序数据写入数据库的场景中,由于存在网络延迟等问题,可能会出现需要写入数据的时间戳小于已写入数据的最大时间戳的情况,这类数据统称为乱序数据。乱序数据的产生几乎是不可避免的,同时,乱序数据的写入会影响所有数据的排序和查询,因此,我们需要在支持乱序数据写入的基础上,也能良好地支撑乱序数据高效查询。
02 流程概述
在处理乱序数据时,指定时间窗口内(比如 10 分钟或 1 小时)的乱序数据会根据去重策略处理之后存储下来,时间窗口之外的乱序数据会被丢弃。下图是乱序数据写入的基本流程:
![]()
其中,需明确 3 个要点:
- 时间窗口是指表最新数据时间戳的时间点再前置的一段时间,在表没有新数据的写入时,它的时间窗口不会变。
- 配置文件中存在参数:ts_st_iot_disorder_interval,用以支持乱序数据写入的时间窗口,单位:秒。此配置项的值不能超过分区时间间隔数值。
- 数据是否乱序的判断依据为写入数据的时间戳小于等于写入的表对象中存储的所有数据最大时间戳。
03 场景示例
1、正常写入流程
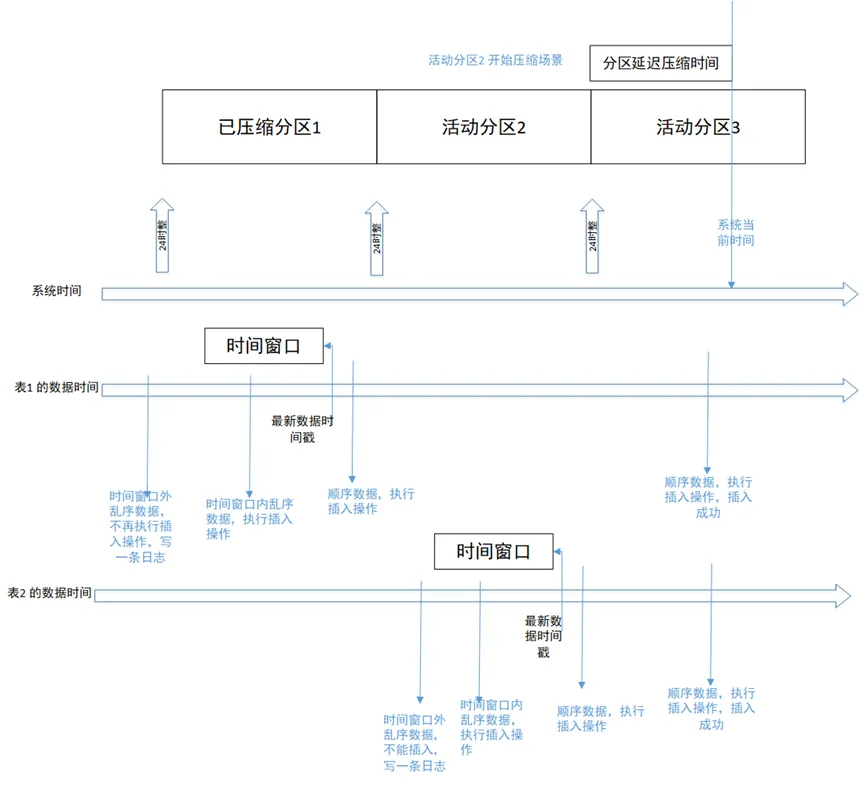
时间分为系统时间和数据时间两条线。数据时间每个表都不相同,因此分为表 1 的数据时间和表 2 数据时间两条线。
![]()
-
场景1:顺序写入两天前的数据场景如上图所示,表 1 的顺序写入历史分区 1 的场景,写入的顺序数据会被存储到对应的分区中,历史分区写入失败并抛错。
-
场景2:时间窗口内写入乱序数据如上图所示,表 2 写入时间窗口内的乱序数据,写入的数据会被存储到活动分区 2 中,活动分区 2 正在另一个线程中进行分区压缩,写入操作也会成功。
-
场景3:超出时间窗口的乱序数据写入当数据库开启压缩功能,并且配置乱序时间窗口为 1 小时,写入比表最新记录时间戳早 1 小时以前的乱序数据会失败。写入的数据会被过滤掉,写入到日志中。
2、导入数据流程
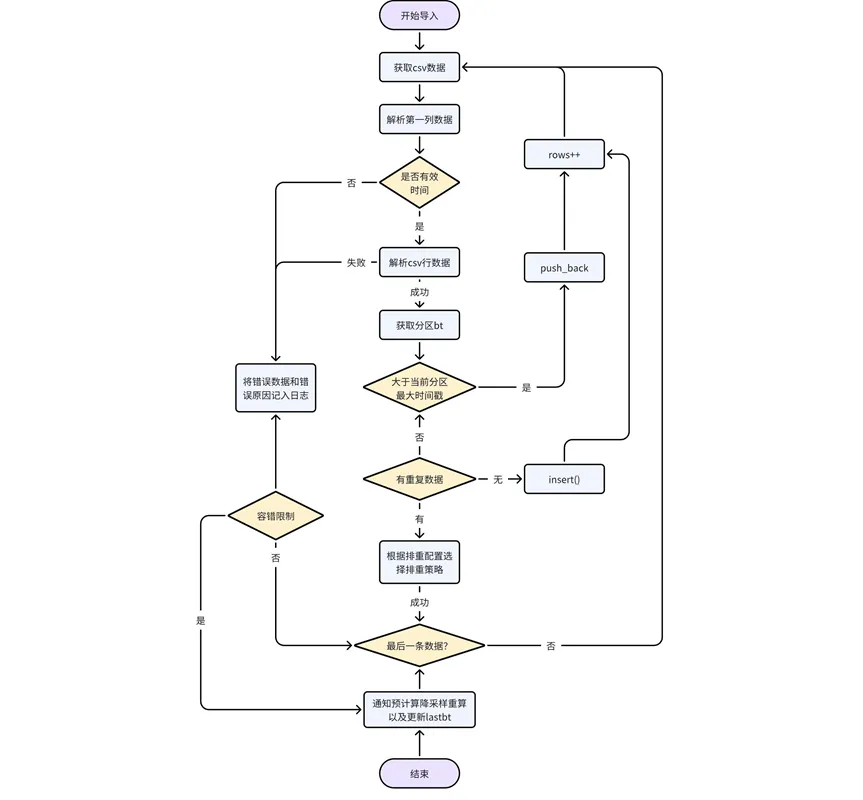
导入数据中也会存在有乱序数据的情况,这种场景下对于乱序数据的处理同正常写入流程保持一致。
![]()
-
数据本身处理:逐行解析 CSV 文件中的数据,判断第一列数据是不是有效的时间/时间戳类型,如果不是报错返回;如果是有效时间数据,判断数据所属分区,获取分区 bt。如果该数据时间戳大于当前分区中已有数据最大时间戳,直接 pushback;否则需要根据去重配置逻辑处理乱序数据。
-
适配降采样和预计算逻辑:导入的数据过程中需要更新 kaiwudb_jobs 系统任务表中 url 的记录状态为 expired;导入完成后通知预计算/降采样,对涉及的数据重新计算/处理,或者等待下一次预计算任务被系统调度时再重算。
导入结束后,通知预计算和降采样进行重计算或者结果更新,以及更新 lastbt。
3、降采样流程
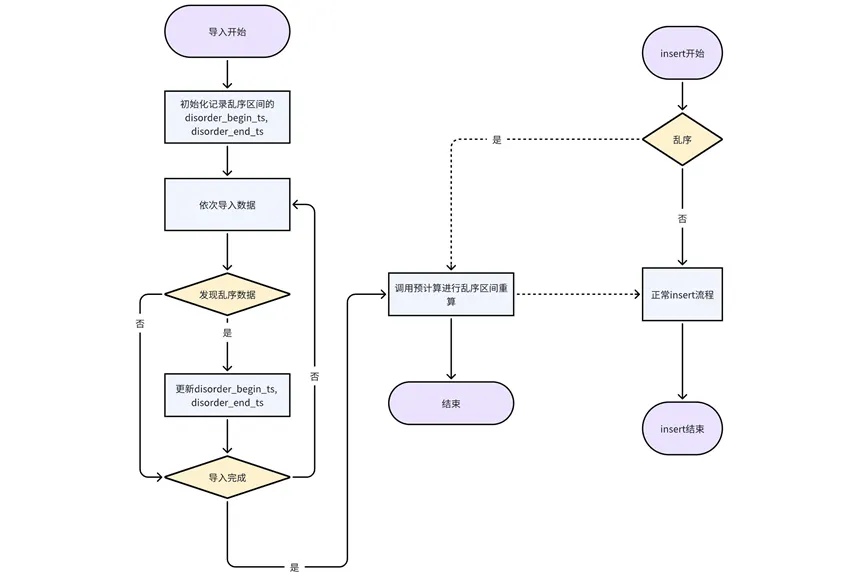
乱序数据写入之后,降采样结果需要根据最新的数据进行更新。
![]()
-
处理导入历史分区的乱序数据:导入归属历史分区的乱序数据时,更新 kaiwudb_jobs 系统任务表中 url=[database/partition/table_name] 的记录状态为 expired,后续会对该分区表重新进行对应降采样规则处理。
-
处理 insert 写入历史分区数据:在对 insert 数据表的历史分区解压时,更新 kaiwudb_jobs 系统任务表中 url=[database/partition/table_name] 的记录状态为 expired,后续样会对该分区表重新进行对应降采样规则的处理。
4、预计算流程 乱序数据写入之后,预计算结果需要根据最新的数据进行更新。
![]()
04 总结
乱序数据处理的场景中,涉及到的功能及联动模块较多,需要进行同步处理及更新。当数据库具备完善的乱序数据处理后,可更好地适配用户业务场景,大幅提高数据库的多场景适用性。