1. 引言
AutoMQ 是一个建立在 S3 Stream 流存储库基础上的 Apache Kafka 云原生重塑解决方案。S3 Stream 利用云盘和对象存储,将对象存储作为主存储,将云盘作为缓冲区,实现了低延迟、高吞吐、“无限”容量和低成本的流式存储。
Delta WAL 作为 S3 Stream 的一部分,是 AutoMQ 的核心组件之一。它基于云盘,具有持久化、低延迟、高性能的特性,是 Main Storage(对象存储)上层的写入缓冲区。本文将重点介绍 Delta WAL 的实现原理。
2. 什么是 Delta WAL
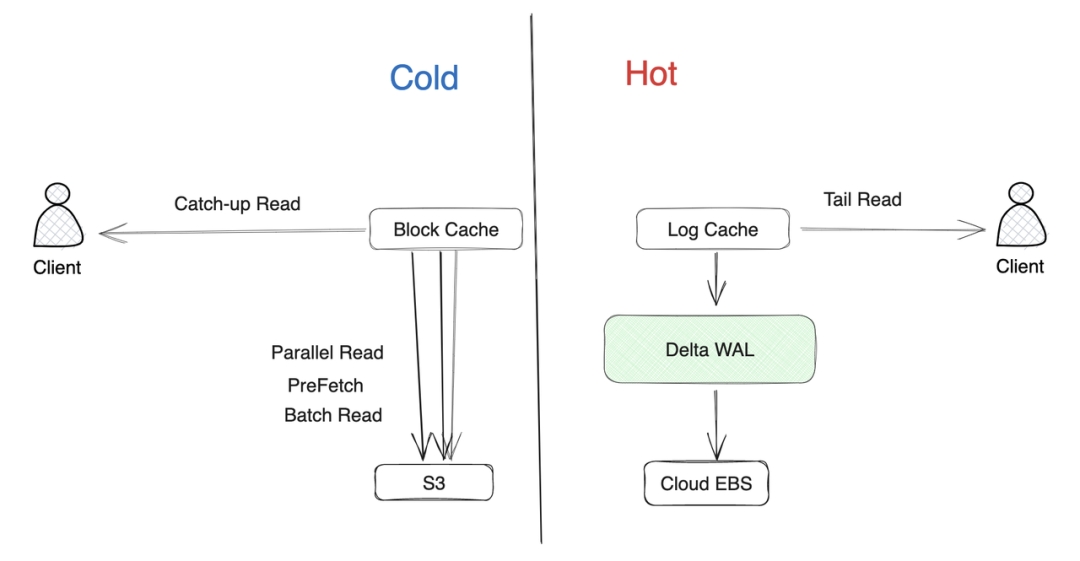
Delta WAL 在 AutoMQ 中的主要职责是作为持久化写入缓冲区,配合 Log Cache 将写入的数据以 WAL 的形式在云盘上做高效的持久化。在云盘上持久化成功后才会返回客户端成功。而数据的读取则均会从内存中读取并返回客户端。
AutoMQ S3Stream 设计了冷热隔离的缓存 Log Cache(缓存新写入数据)和 Block Cache(缓存从对象存储中拉取的数据)。Log Cache 中的数据在 WAL 的数据没有上传到对象存储之前在内存中不会失效。如果从 Log Cache 无法读取到数据,则改为从 Block Cache 中读取数据。Block Cache 会通过预读、批量读等手段保证冷读时读取数据也尽量在内存命中,从而确保冷读时读取的性能。
Delta WAL 作为 S3Stream 中支持高性能持久化 WAL 的组件,主要用于将 Log Cache 中的数据高效地持久化到裸设备上。
![]()
3. 为什么基于裸设备
Delta WAL 构建在云盘之上,绕过了文件系统,直接使用 Direct IO 对裸设备进行读写。这种设计选择有以下三个优势:
-
避免 Page Cache 污染
-
提高写入性能
-
宕机后恢复更快
3.1 避免 Page Cache 污染
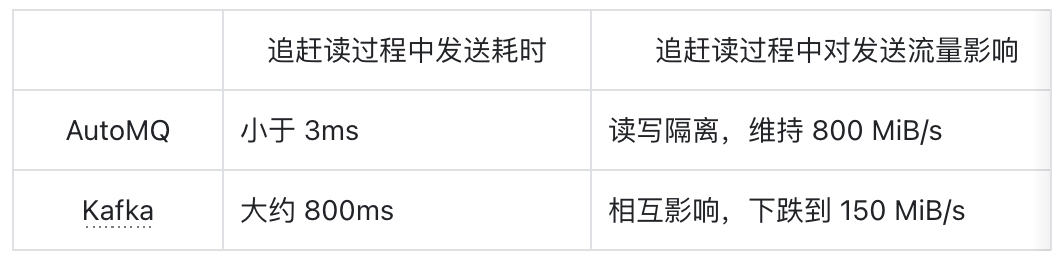
Kafka broker 在处理生产消息的请求时,会将数据写入 Page Cache,并异步地将数据写入磁盘;同样的,在处理消费请求时,如果数据不存在于 Page Cache 中,会从磁盘将数据读入 Page Cache。这种机制就会导致,当消费者追赶读(catch-up read)时,会把将从磁盘读取的数据放入 Page Cache,产生污染,影响实时的读写。而使用 Direct IO 进行读写时,绕过了 Page Cache,避免了这个问题,保证了实时读写与追赶读互不干扰。
在 AutoMQ 性能白皮书中,我们详细对比了 Kafka 与 AutoMQ 在追赶读时的性能表现。结果见下表:
![]()
从中可以看到,AutoMQ 很好地做到了读写隔离,在追赶读时,实时读写性能几乎不受影响;而 Kafka 在追赶读时,会导致发送消息延迟大幅增加,流量下跌严重。
3.2 提高写入性能
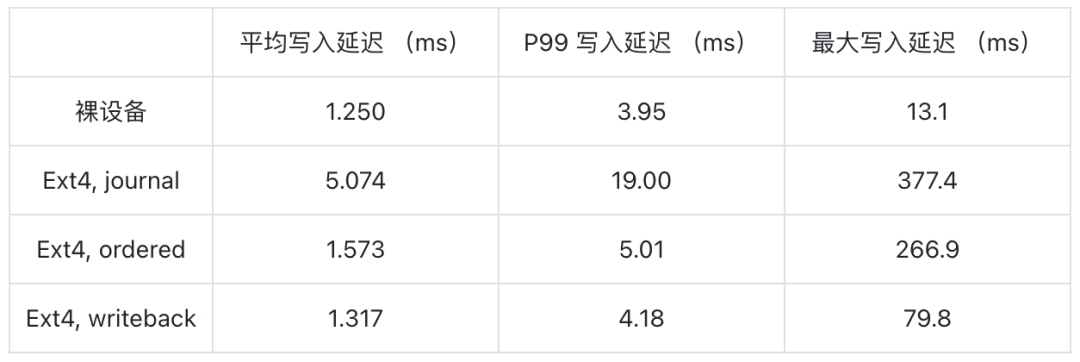
绝大多数文件系统在读写时都会有一定的额外开销:比如文件系统的元数据操作、记录 Journal 等。这些操作会占用一部分磁盘的带宽与 IOPS,同时写入路径也会变得更长。而使用裸设备进行读写,避免了这些开销,写入延迟更低。下表对比了在文件系统与裸设备上进行写入的性能表现。可以看到,相较于文件系统,裸设备的写入延迟明显更低,性能更好。
![]()
注:基于 fio 测试,运行指令为 sudo fio -direct=1 -iodepth=4 -thread -rw=randwrite -ioengine=libaio -bs=4k -group_reporting -name=test -size=1G -numjobs=1 -filename={path}
3.3 宕机后恢复更快
当使用文件系统时,如果 OS Crash,在重启后,需要进行文件系统的检查与恢复,这个过程可能会非常耗时,与文件系统上的数据与元数据的大小成正比。
而使用裸设备时,不需要进行文件系统的检查与恢复,宕机后恢复更快。
4. 设计目标
Delta WAL 作为 S3 Stream 中的组件有如下设计目标:
-
轮转写入,存储空间需求不大。 Delta WAL 作为数据写入对象存储前的缓冲区,不会存储很多数据(默认每攒够 512 MiB 即上传到对象存储)。因此,可以采用轮转写入的模式(类似于 Ring Buffer),不需要太大的存储空间(默认 2 GiB)。
-
充分发挥云盘性能。 目前大多数云厂商的云盘都会提供一部分免费的 IOPS 与带宽,例如,AWS EBS GP3 会提供免费的 3000 IOPS 与 125 MiB/s 的带宽。这就需要 Delta WAL 充分利用云盘的能力,尽可能地使用免费的 IOPS 与带宽来提高性能。
-
支持从非优雅关闭中恢复,且速度尽可能快。 当发生宕机等非预期问题,导致 AutoMQ 非优雅关闭时,Delta WAL 需要在重启后尽可能快地恢复到正常状态,且不会丢失数据。
5. 具体实现
Delta WAL 的源码可以在 s3stream 仓库中找到。接下来我们将从上至下介绍 Delta WAL 的具体实现。
5.1 接口
Delta WAL 的接口定义在 WriteAheadLog.java。其中有如下几个主要的方法:
public interface WriteAheadLog {
AppendResult append(ByteBuf data) throws OverCapacityException;
interface AppendResult {
long recordOffset();
CompletableFuture<CallbackResult> future();
interface CallbackResult {
long flushedOffset();
}
}
CompletableFuture<Void> trim(long offset);
Iterator<RecoverResult> recover();
interface RecoverResult {
ByteBuf record();
long recordOffset();
}
}
-
append:向 Delta WAL 中异步写入一条 record。返回该 record 的位点(offset)与写入结果的 future,该 future 会在 record 被刷入磁盘后完成。
-
trim:删除位点小于等于指定位点的 record 。值得说明的是,这里只是逻辑删除,实际上并不会删除磁盘上的数据。当一段数据被上传到对象存储后,会使用该方法更新位点。
-
recover:从最新的 trim 位点开始,恢复所有 record 。返回一个迭代器,迭代器中的每个元素都是一条 record 与其位点。该方法会在重启后被调用,用于恢复 Delta WAL 中尚未上传到对象存储的数据。
值得说明的是,Delta WAL 中返回 offset 只是逻辑位点,而非实际在磁盘上的位置(物理位点)。这是由于前文提到的,Delta WAL 采用了轮转写入的模式,物理位点会在磁盘上循环,而逻辑位点则是单调递增的。
5.2 数据结构
Delta WAL 中的主要数据结构有 WALHeader,RecordHeader 和 SlidingWindow,接下来将分别介绍它们。
5.2.1 WALHeader
WALHeader 是 Delta WAL 的头部信息,定义在 WALHeader.java。它包含了 Delta WAL 的一些元信息,包括:
-
magicCode:用于标识 Delta WAL 的头部,防止误读。
-
capacity:裸设备的容量。在初始化时配置,不会改变。用于换算逻辑位点与物理位点。
-
trimOffset:Delta WAL 的 trim 位点。trim 位点之前的 record 已被上传到对象存储,可以覆盖;在 recover 时,会从 trim 位点开始恢复。
-
lastWriteTimestamp:最后一次刷新 WALHeader 的时间戳。
-
slidingWindowMaxLength:滑动窗口的最大长度。具体作用将在下文介绍。
-
shutdownType:关闭类型。用于标识上一次关闭 Delta WAL 时是否为优雅关闭。
-
crc:WALHeader 的 CRC 校验码。用于校验 WALHeader 是否损坏。
5.2.2 RecordHeader
RecordHeader 是 Delta WAL 中每条 record 的头部信息,定义在 SlidingWindowService.java。它包含了 Delta WAL 中每条 record 的一些元信息,包括:
5.2.3 SlidingWindow
SlidingWindow 是 Delta WAL 中用于写入的滑动窗口,定义在 SlidingWindowService.java。它用于分配每条 record 的写入位点,并控制 record 的写入。它由几个位点组成,如下图:
![]()
-
Start Offset: 滑动窗口的起点,在此之前的 record 已经落盘完成。
-
Next Offset: 尚未分配的下一个逻辑位点,新的 record 将从这里开始写入。Next Offset 与 Start Offset 之间的数据尚未完全落盘。
-
Max Offset: 滑动窗口的最大逻辑位点。当 Next Offset 到达 Max Offset 时,会尝试扩大滑动窗口。当窗口达到最大长度时(之前在 WALHeader 中提到的 slidingWindowMaxLength),会暂停写入,直到有 record 落盘,窗口向前滑动。
5.3 写入与恢复
下面重点介绍一下 Delta WAL 的写入与恢复流程。
5.3.1 写入
AutoMQ 在设计写入实现时充分考虑了云盘的计费项和底层实现的特性,以最大化性能和成本效益。以 AWS EBS GP3 为例,免费提供 3000 IOPS,因此 Delta WAL 的时间阈值默认为 1/3000 秒,以匹配免费 IOPS 额度,避免额外成本。此外,AutoMQ 引入了批大小阈值(默认为 256 KiB),避免发送过大的 Record 到云盘。云盘底层实现会将大于 256 KiB 的 Record 拆分成多个 256 KiB 的小数据块顺序写入持久化介质。
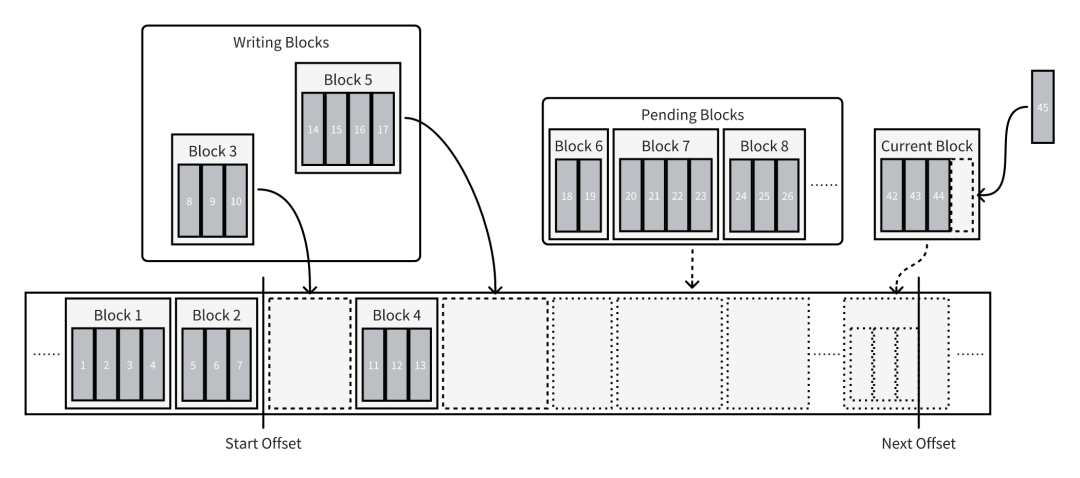
AutoMQ 的拆分操作确保云盘底层并行写入,提升写入性能。下图展示了 Delta WAL 具体的写入流程:
![]()
图中的 Start Offset 与 Next Offset 在上文已经介绍过,这里不再赘述。新引入的几个数据结构含义如下:
-
Block:一次 IO 操作的最小单位,其中包含一条或多条 record。在写入磁盘时,每个 Block 都会对齐到 4 KiB。
-
writingBlocks:正在写入的 block 集合。当 block 写入磁盘后,会从集合中移除。
-
pendingBlocks:待写入的 block 集合。当 IO 线程池满时,新的 block 会被放入该集合,等待前面的 IO 完成后再移入 writingBlocks 进行写入。
-
currentBlock:最新的 Block。需要写入的 record 会被放入该 block 中,该 block 同时会负责分配新 record 的逻辑位点。当 currentBlock 写满时,会被放入 pendingBlocks,同时新的 Block 会被创建并成为 currentBlock。
一次写入的流程如下:
-
调用方发起 append 请求,传入一条 record 。
-
从将其添加到 currentBlock 的末尾,并分配位点,将位点同步返回给调用方。
-
如果 currentBlock 已经积攒一定大小或一定时间,将其放入 pendingBlocks,同时创建新的 currentBlock。
-
如果 writingBlocks 的数量小于 IO 线程池的大小,从 pendingBlocks 中取出一个 block,放入 writingBlocks 进行写入。
-
当 block 写入磁盘后,从 writingBlocks 中移除。同时计算并更新滑动窗口的 Start Offset,并完成 append 请求的 future。
5.3.2 恢复
在 Delta WAL 重启时,外部会调用 recover 方法,从最新的 trim 位点开始,恢复所有 record。恢复的流程如下:
-
从 WAL header 中读取 trim offset, 并设置为 recover offset。
-
读取 recover offset 下的 record header,校验是否合法。
a. 若是,则更新 recover offset 为该 record 末尾。
b. 若否,则将 recover offset 设置为下一个 4K 对齐的位置。
-
重复第 2 步,直至在第一次遇到非法 record 后,继续尝试读取了 window max length 的长度。
值得说明的是,第 3 步中,之所以在遇到非法 record 后仍要继续尝试读取,是因为在滑动窗口中 Start Offset 与 Next Offset 之间的数据可能存在空洞,即,一部分 record 已经落盘,一部分 record 尚未落盘。在恢复时,需要尽可能地恢复已经落盘的 record,而不是直接跳过。
5.4 读写裸设备
前面提到过,Delta WAL 底层没有依赖文件系统,而是直接使用 Direct IO 读写裸设备。在实现时,我们依赖了一个三方库 kdio,并对其进行了一点修改以适配 Java 9 中引入的 Modules 特性。它对 pread 与 pwrite 等系统调用进行了封装,提供了一些便利的方法,帮助我们直接读写裸设备。
下面介绍一下我们在使用 Direct IO 读写裸设备时积累的一些经验。
5.4.1 对齐
在使用 Direct IO 读写时,要求内存地址、IO 的偏移量及大小与以下几个值对齐,否则会写入失败:
为了保证 IO 的偏移量与大小对齐,我们对前文提到的 Block 进行了对齐处理,使其大小为 4 KiB 的整数倍,并将其写入磁盘时的偏移量也对齐到 4 KiB。这样做的好处是,在每次写入时,IO 偏移量都是对齐的,无需处理在某个扇区的中间写入的情况。同时由于 Block 有攒批的逻辑,Delta WAL 也仅作为缓冲区无需长期存储数据,因此对齐后产生的空洞带来的空间浪费是较小且可以接受的。
在实现的过程中,使用了以下几个方法来处理内存地址的对齐:
public static native int posix_memalign(PointerByReference memptr, NativeLong alignment, NativeLong size);
// following methods are from io.netty.util.internal.PlatformDependent
public static ByteBuffer directBuffer(long memoryAddress, int size);
public static long directBufferAddress(ByteBuffer buffer);
public static void freeDirectBuffer(ByteBuffer buffer);
-
posix_memalign 是 POSIX 标准中的方法,用于分配一块内存,并保证其地址对齐到指定的大小
-
其余三个方法是 Netty 中的工具方法:
a. directBuffer 用于将一个内存地址及大小封装为 ByteBuffer
b. directBufferAddress 用于获取 ByteBuffer 的内存地址,其被作为 pread 和 pwrite 的参数c. freeDirectBuffer 用于释放 ByteBuffer
将以上方法结合起来,我们就可以在 Java 中分配、使用、释放对齐的内存了。
5.4.2 维护裸设备大小
与文件系统不同,裸设备的大小无法通过文件的元数据来获取,这就需要我们自己维护裸设备的大小。在初始化时,上层会指定 WAL 的大小,Delta WAL 会在初始化时获取裸设备的大小,并与指定的大小进行比较:如果裸设备的大小小于指定的大小,会抛出异常;如果裸设备的大小大于指定的大小,会将 WALHeader 中的 capacity 设置为指定的大小,且之后不可更改。这样做的好处是,可以保证 Delta WAL 的大小不绑定于裸设备的大小,避免裸设备大小的变化导致的问题。
在未来,我们还会支持动态变更 Delta WAL 的大小,以满足更多的场景。
6. 基准测试
为了验证 Delta WAL 的性能,我们进行了一些基准测试。测试环境如下:
-
AWS EC2 m6i.xlarge, 4 vCPU, 16 GiB RAM
-
AWS EBS GP3 (2 GiB, 3000 IOPS, 125 MiB/s)
-
Ubuntu 22.04 LTS linux 5.15.0-91-generic
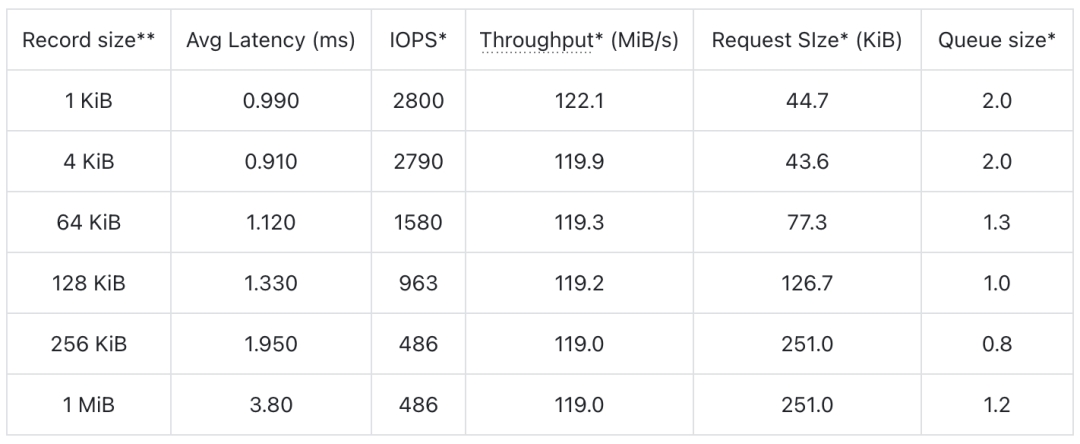
测试代码详见仓库。测试时配置 IO 线程池大小为 4,目标写入吞吐为 120 MiB/s。测试结果如下:
![]()
*: 为 iostat 中的读数**: Stream WAL 中每个 record 还有 24 Bytes 的 header,这在测试时被减去了
可以看到
-
Delta WAL 可以充分发挥云盘的性能
a. 写入吞吐接近 125 MiB/s(还有一小部分带宽用于写入写 header、4K 对齐等开销)。
b. 当 record 不过大时,可以基本跑满 3000 IOPS。
-
Delta WAL 的写入延迟较低,小包平均延迟在 1 ms 以内,大包平均延迟在 2 ms 以内。在 AutoMQ 性能白皮书中可以看到 AutoMQ 发送消息的长尾延迟明显优于 Kafka。
7. 结语
Delta WAL 作为 S3 Stream 的一部分,是 AutoMQ 的核心组件之一。它基于裸设备,避免了 Page Cache 污染,提高了写入性能,且宕机后恢复更快。在实现时,我们充分利用了云盘的 IOPS 与带宽,保证了 Delta WAL 的性能,进而保证了 AutoMQ 的低延迟、高吞吐。在未来,我们还会支持更多的特性,例如动态变更 Delta WAL 的大小,以满足更多的场景。
END
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
👀 B站:AutoMQ官方账号
🔍 视频号:AutoMQ
👉 扫二维码加入我们的社区群
![]()
关注我们,一起学习更多云原生技术干货!
👇点击下方阅读原文,前往 GitHub 了解体验!