![]()
Apache Flink PMC(项目管理委员)很高兴地宣布发布 Apache Flink 1.19.0。与往常一样,这是一个充实的版本,包含了广泛的改进和新功能。总共有 162 人为此版本做出了贡献,完成了 33 个 FLIPs、解决了 600 多个问题。感谢各位贡献者的支持!
一、Flink SQL 提升
源表自定义并行度
现在,在 Flink 1.19 中,您可以通过选 scan.parallelism 设置自定义并行度,以调整性能。第一个可用的连接器是 DataGen( Kafka 连接器即将推出)。下面是一个使用 SQL Client 的示例:
-- set parallelism within the ddl
CREATE TABLE Orders (
order_number BIGINT,
price DECIMAL(32,2),
buyer ROW<first_name STRING, last_name STRING>,
order_time TIMESTAMP(3)
) WITH (
'connector' = 'datagen',
'scan.parallelism' = '4'
);
-- or set parallelism via dynamic table option
SELECT * FROM Orders /*+ OPTIONS('scan.parallelism'='4') */;
更多信息
可配置的 SQL Gateway Java 选项
一个用于指定 Java 选项的新选项 env.java.opts.sql-gateway ,这样你就可以微调内存设置、垃圾回收行为和其他相关 Java 参数。
更多信息
使用 SQL 提示配置不同的状态 TTL
从 Flink 1.18 开始,Table API 和 SQL 用户可以通过 SQL 编译计划为有状态操作符单独设置状态存续时间 ( TTL )。在 Flink 1.19 中,用户可以使用 STATE_TTL 提示,以更灵活的方式直接在查询中为常规连接和分组聚合指定自定义 TTL 值。
这一改进意味着您不再需要修改编译后的计划,就能为这些常用操作符设置特定的 TTL。引入 STATE_TTL 提示后,您可以简化工作流程,并根据操作要求动态调整 TTL。
下面是一个例子:
-- set state ttl for join
SELECT /*+ STATE_TTL('Orders'= '1d', 'Customers' = '20d') */ *
FROM Orders LEFT OUTER JOIN Customers
ON Orders.o_custkey = Customers.c_custkey;
-- set state ttl for aggregation
SELECT /*+ STATE_TTL('o' = '1d') */ o_orderkey, SUM(o_totalprice) AS revenue
FROM Orders AS o
GROUP BY o_orderkey;
更多信息
函数和存储过程支持命名参数
现在,在调用函数或存储过程时可以使用命名参数。使用命名参数时,用户无需严格指定参数位置,只需指定参数名称及其相应值即可。同时,如果没有指定非必要参数,这些参数将默认为空值。
下面是一个使用命名参数定义带有一个必选参数和两个可选参数的函数的示例:
public static class NamedArgumentsTableFunction extends TableFunction<Object> {
@FunctionHint(
output = @DataTypeHint("STRING"),
arguments = {
@ArgumentHint(name = "in1", isOptional = false, type = @DataTypeHint("STRING")),
@ArgumentHint(name = "in2", isOptional = true, type = @DataTypeHint("STRING")),
@ArgumentHint(name = "in3", isOptional = true, type = @DataTypeHint("STRING"))})
public void eval(String arg1, String arg2, String arg3) {
collect(arg1 + ", " + arg2 + "," + arg3);
}
}
在 SQL 中调用函数时,可以通过名称指定参数,例如:
SELECT * FROM TABLE(myFunction(in1 => 'v1', in3 => 'v3', in2 => 'v2'))
可选参数也可以省略:
SELECT * FROM TABLE(myFunction(in1 => 'v1'))
更多信息
Window TVF 聚合功能
现在,用户可以在流模式下使用 SESSION Window TVF。下面是一个简单的示例:
-- session window with partition keys
SELECT * FROM TABLE(
SESSION(TABLE Bid PARTITION BY item, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES));
-- apply aggregation on the session windowed table with partition keys
SELECT window_start, window_end, item, SUM(price) AS total_price
FROM TABLE(
SESSION(TABLE Bid PARTITION BY item, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES))
GROUP BY item, window_start, window_end;
更多信息
新的 UDF 类型:AsyncScalarFunction
常见的 UDF 类型 ScalarFunction 可以很好地处理 CPU 密集型操作,但对于 IO 密集型或其他长时间运行的计算则效果不佳。在 Flink 1.19 中,我们新增了 AsyncScalarFunction ,它是一种用户定义的异步 ScalarFunction ,允许异步发出并发函数调用。
更多信息
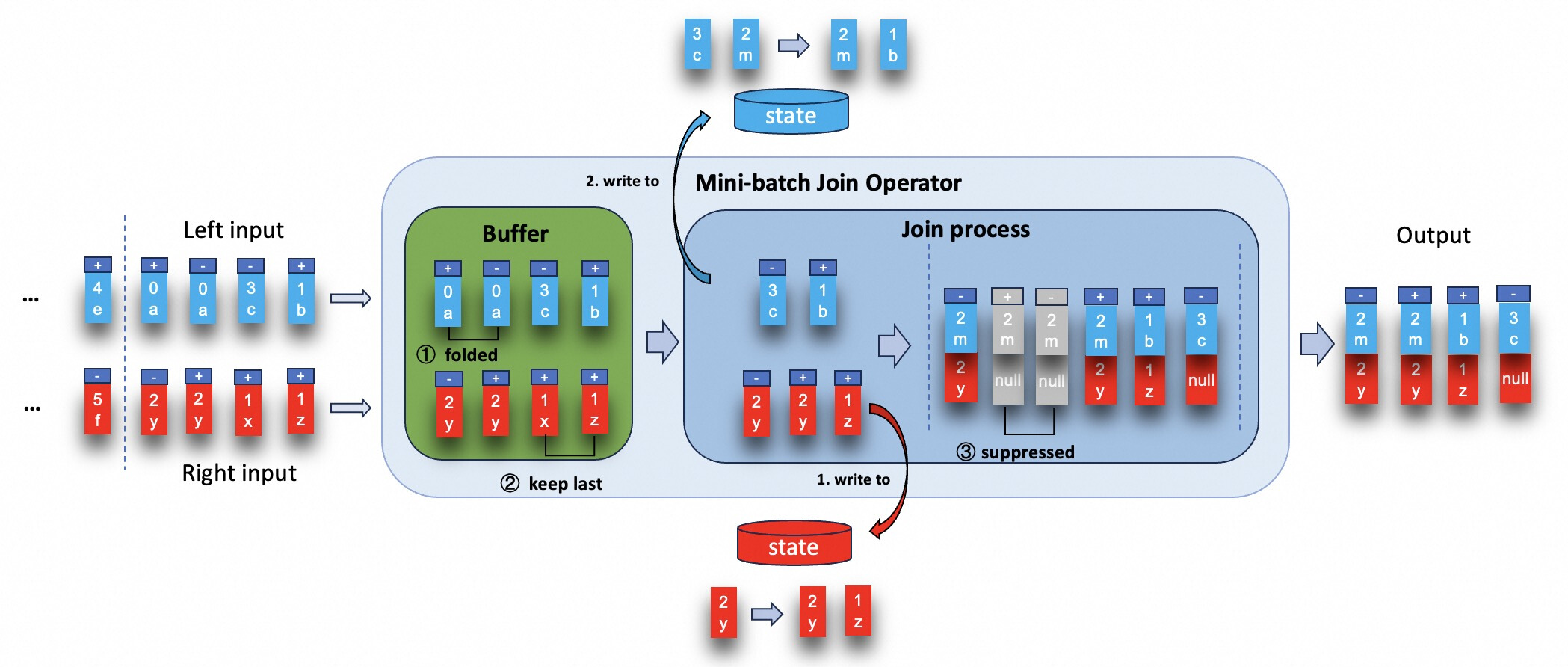
Regular Join 支持 MiniBatch 优化
消息放大是 Flink 中执行级联连接时的一个痛点,现在在 Flink 1.19 中得到了解决,新的 MiniBatch 优化可用于 Regular Join,以减少此类级联连接场景中的中间结果。
![]()
更多信息
二、Runtime & Coordination 提升
批作业支持源表动态并行度推导
在 Flink 1.19 中,我们支持批作业的源表动态并行度推导,允许源连接器根据实际消耗的数据量动态推断并行度。
与以前的版本相比,这一功能有了重大改进,以前的版本只能为源节点分配固定的默认并行度。
源连接器需要实现推理接口,以启用动态并行度推理。目前,FileSource 连接器已经开发出了这一功能。
此外,配置 execution.batch.adaptive.auto-parallelism.default-source-parallelism 将被用作源并行度推理的上限。现在,它不会默认为 1。取而代之的是,如果没有设置,将使用通过配置 execution.batch.adaptive.auto-parallelism.max-parallelism 设置的允许并行度上限。如果该配置也未设置,则将使用默认的并行度设置 parallelism.default 或 StreamExecutionEnvironment#setParallelism() 。
更多信息
Flink Configuration 支持标准 YAML 格式
从 Flink 1.19 开始,Flink 正式全面支持标准 YAML 1.2 语法。默认配置文件已改为 config.yaml ,放置在 conf/directory 中。如果用户想使用传统的配置文件 flink-conf.yaml ,只需将该文件复制到 conf/directory 中即可。一旦检测到传统配置文件 flink-conf.yml ,Flink 就会优先使用它作为配置文件。而在即将推出的 Flink 2.0 中, flink-conf.yaml 配置文件将不再起作用。
更多信息
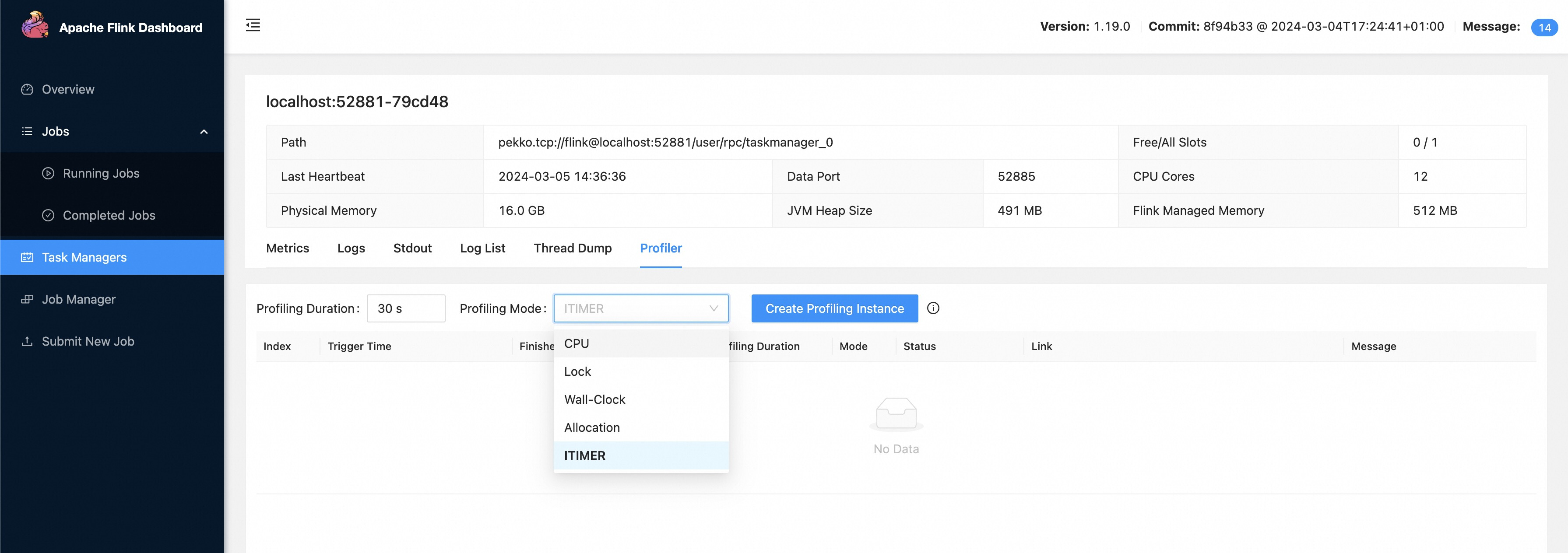
在 Flink Web 上 Profiling JobManager/TaskManager
在 Flink 1.19 中,我们支持在 JobManager/TaskManager 级别触发 Profile,允许用户创建具有任意时间间隔和事件模式(由 async-profiler 支持)的 Profile 实例。用户可以在 Flink Web UI 中轻松提交剖析并导出结果。
例如,用户只需在确定存在性能瓶颈的候选任 JobManager/TaskManager 后,通过 "Create Profiling Instance" 提交一个具有指定周期和模式的 Profile 实例:
![]()
Profile 结果:
![]()
更多信息
新增管理员 JVM 选项配置选项
有一组管理员 JVM 选项可供使用,它们是用户设置的额外 JVM 选项的前缀,用于全平台范围的 JVM 调整。
更多信息
三、Checkpoints 提升
Source 反压时支持使用更大的 Checkpointing 间隔
引入 ProcessingBacklog 的目的是为了说明处理记录时应采用低延迟还是高吞吐量。ProcessingBacklog 可由 Source 算子设置,并可用于在运行时更改作业的检查点间隔。
更多信息
CheckpointsCleaner 并行清理单个检查点状态
现在,在处置不再需要的检查点时,ioExecutor 会并行处置每个状态句柄/状态文件,从而大大提高了处置单个检查点的速度(对于大型检查点,处置时间可从 10 分钟缩短至 < 1 分钟)。可以通过设置为 false 恢复旧版本的行为。
更多信息
通过命令行客户端触发 Checkpoints
命令行界面支持手动触发检查点。
使用方法:
./bin/flink checkpoint $JOB_ID [-full]
如果指定"-full "选项,就会触发完全检查点。否则,如果作业配置为定期进行增量检查点,则会触发增量检查点。
更多信息
四、Connector API提升
与 Source API 一致的 SinkV2 新接口
在 Flink 1.19 中,SinkV2 API 做了一些修改,以便与 Source API 保持一致。以下接口已被弃用: TwoPhaseCommittingSink、StatefulSink 、WithPreWriteTopology、WithPreCommitTopology、WithPostCommitTopology 。引入了以下新接口 CommitterInitContext 、CommittingSinkWriter 、 WriterInitContext 、StatefulSinkWrite。更改了以下接口方法的参数: Sink#createWriter 。 在 1.19 版本发布期间,原有接口仍将可用,但会在后续版本中移除。
更多信息
用于跟踪 Committables 状态的新 Committer 指标
修改了 TwoPhaseCommittingSink#createCommitter 方法的参数化,新增了 CommitterInitContext 参数。原来的方法在 1.19 版本发布期间仍然可用,但会在后续版本中移除。
更多信息
五、重要API弃用
为了给 Flink 2.0 版本做准备,社区决定正式废弃多个已接近生命周期终点的 API。
六、升级说明
Apache Flink 社区努力确保升级过程尽可能平稳, 但是升级到 1.19 版本可能需要用户对现有应用程序做出一些调整。请参考 Release Notes 获取更多的升级时需要的改动与可能的问题列表细节。
贡献者列表
![]()
Flink Forward Asia 2023
本届 Flink Forward Asia 更多精彩内容,可微信扫描图片二维码观看全部议题的视频回放及 FFA 2023 峰会资料!
![]()
![]()
更多内容
![]()
活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
59 元试用 实时计算 Flink 版(3000CU*小时,3 个月内)
了解活动详情:https://free.aliyun.com/?pipCode=sc
![]()
![]()