最新越发觉得AI的发展,对未来是一场革命,LangChain已经在工程设计上有了最佳实践,类似于AI时代的编程模型或编程框架,有点Spring框架的意思。之前在LangChain上也有些最佳实践,所以在这里分享记录下。
LangChain是基于LLM之上的,在应用层和底层LLM之前的一个很好的编程框架,如果把LLM比喻为各种类型的数据库、中间件等这些基础设施,应用层是各种业务逻辑的组合之外,那么LangChain就负责桥接与业务层和底层LLM模型,让开发者可以快速地实现对接各种底层模型和快速实现业务逻辑的软件开发框架。
那么LangChain是如何做到的呢?试想一下,现在底层有一个大模型的推理能力,除了在对话框手动输入跟他聊天之外。如何用计算机方式跟它互动呢?如果把一次LLM调用当作一个原子能力,如何编排这些原子能力来解决一些业务需求呢?Langchain就是来解决这个事情的。
▐ Model I/O
这里重点把背后的LLM模型做了一层封装,开发者可以通过更改配置的方式快速切换底层LLM模型,比如chatgpt,chatGLM、通义千问等模型。
同时还有些高阶功能:比如提供了缓存等功能,这样对于语义上类似的query,如果缓存有,那么langchain可以快速返回结果,而不需要调用大模型。
▐ Retriver
检索是为了解决大模型打通用户的本身数据,做一些面向业务属性的东西。这里的检索并非传统的关系型数据库,更多的是与大模型的本身逻辑相似的,比如向量数据库。
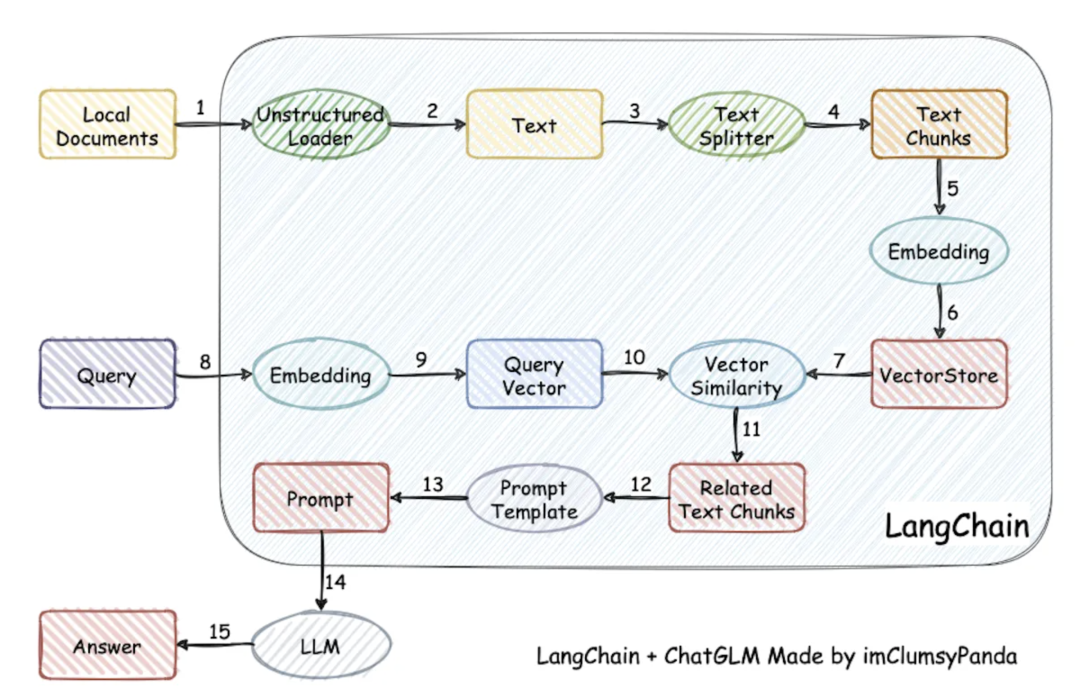
一个经典的结合LLM和外部用户的文档进行智能答疑的场景
query->向量数据库查询->TOP N->上下文+ 用户提问 + prompt -> LLM -> 返回结果
关键技术:文档如何拆分、embedding过程、 TOPN 向量距离的选择
embedding技术选型
embedding是将现实中的物体通过向量化的方法转化为高维向量,可被机器学习模型所识别。他是一种映射,同时也保证了能清晰地表达现实物体的特征。基于此,可以进行一些归类分析、回归分析等。
现在市面上常见的embedding方法有通义千问的embedding等方法。
向量数据库:
向量数据库底层存储的是一堆向量,它提供了根据向量相似度进行查询的能力,一般情况下,向量相似度代表了现实世界中物体的相似度。比如”我的名字是小明“ 和“我叫小明”这两句话所代表的含义几乎是相同的,那么在embedding之后,基于向量数据库进行查询的时候,它们俩的相似度就会很近。
▐ Chain
各种类型的chain,chain代表了各种业务类型的组合,类似于工作流的编排。
▐ Memory
LLM本身提供了记忆的能力,同时提供了接口,开发者可以将历史的对话记录传入给LLM。LangChain需要使用外部存储保存这些历史的会话和记忆。可以使用数据库、缓存等进行保存。
▐ Agent
重点是代理工具
代理工具可以让应用程序基于大模型的推理能力,然后进行代理工具或代理服务的调用。因为LLM是没有“联网”的能力的,如果想解决特定的应用场景,代理工具是个完美的选择。
代理工具通常包含三个方面:用户输入、prompt编排LLM思考与路由代理的过程、背后的代理服务。其中难点可能就在于prompt设计了。通常的“套路”是这样的:
ReAct 模型
输入:用户的问题
思考过程:如果是情况1(这个是需要LLM进行意图识别进行思考的),那么推理和提取出一些关键参数,调用agent1,如果是情况2,那么推理和提取出一些关键参数,调用agent2
Act:调用agent1对应一个JSON格式化的输入,调用function1,返回结果。
观察:观察调用后的结果,再结合推理的能力,再进行循环思考。
LangChain的在实际场景中的实践
集团内部开发了一个JAVA版本的LangChain框架,以下实践基于此框架与开源大模型chatGLM-6B进行。
▐ 淘宝开放平台智能问答
淘宝开放平台对内托管了上万个API,每天在内部群里都会有开发者咨询API发布问题,之前我们是通过NLP来实现智能问答的,现将它升级为基于大模型的智能问答,以下是具体的技术实现过程。
由于之前已经沉淀好了很多知识库,都是Question-Answer的这种形式,这里我们对Question,也就是问题进行Embedding,此处采用通义千问提供的Embedding方法。
知识库embedding:
TongYiEmbeddings embeddings = new TongYiEmbeddings();embeddings.setServerAccessId(ALINLP_EMBEDDINGS_ACCESSID);embeddings.setServerUrl(ALINLP_EMBEDDINGS_SERVER_URL);embeddings.setServerUuid(ALINLP_EMBEDDINGS_UUID);Document document = new Document();document.setPageContent(rawText);List<Document> documents = embeddings.embedDocument(Arrays.asList(document));Document vecDocument= documents.get(0);String embeddingString = JSON.toJSONString(vecDocument.getEmbedding()).replaceAll("\\[", "{").replaceAll("\\]", "}");
return embeddingString;
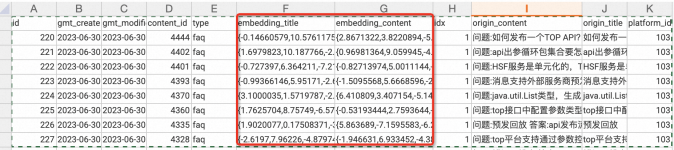
此处采用hologres向量数据库,图中红框表示知识库问题与回答在数据库中具体的向量化存储数据。
向量距离数据库查询:
select origin_content as originContent, origin_title as originTitle, pm_approx_squared_euclidean_distance(embedding_title, from vs_knowledgeorder by distance asclimit
ChatGLMV2Internal chatGLMV2Internal = new ChatGLMV2Internal();chatGLMV2Internal.setTemperature(0.01d);chatGLMV2Internal.setMaxLength(2048);
PromptTemplate prompt = new PromptTemplate();String template = "已知信息:\n" +"{context} \n" +"\n" +"根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。问题是:{question}";prompt.setTemplate(template);
RetrievalQA qa = new RetrievalQA();qa.setRecommend(5);qa.setMaxDistanceValue(10000.0d);qa.setLlm(chatGLMV2Internal);qa.setPrompt(prompt);qa.setRetriever(holoRetriver.asRetriever());qa.init();
Map<String, Object> inputs = new HashMap<>();inputs.put("question", question);inputs.put("input", question);Map<String, Object> outputs = qa.run(inputs);
llmKonwledgeDO.setContent(String.valueOf(outputs.get("text")));return llmKonwledgeDO;
▐ AI Agent实践
以下实现了一个网关API调用日志解析的agent。
this.setName("ApiLogTool");this.setDescription("这是一个调用日志查询接口,如果[{question}]中包含requestId关键字,你可以请求这个工具与日志系统进行交互,调用这个工具。\n" + "请先提取出requestId的值,将它赋值为value。调用参数:[{\"requestId\": \"value\", \"type\": \"String\", \"description\": \"调用请求id\"}]。");
Map<String,Object> parse = (Map<String,Object>)JSON.parse(toolInput);if(parse.get("requestId")==null){ return new ToolExecuteResult("");}String requestId = parse.get("requestId").toString();ApiLogSearchQuery apiLogSearchQuery = new ApiLogSearchQuery();
public static final String FORMAT_INSTRUCTIONS_CH ="用户提出了一个问题: {question} \n" +"你可以选择使用下面这些工具:\n"+"{tool_list_description}"+"\n"+"同时你的思考过程如下:"+"Thought: 每一次你需要首先思考你应该做什么\n" +"Action: 你需要决定是否使用工具,应该是[{tool_names}] 中的一个Action,格式为JSON。如果匹配不到工具,就不要思考了,直接返回结果,请不要把思考过程返回给用户。\n" +"Input: 如果匹配到工具,使用的工具的输入参数,赋值给params\n" +"Observation: 如果匹配到工具,工具的输出结果 格式为[]。\n" +"Answer: 每一步回答问题的答案,格式为JSON。你可以多次使用Thought/Action/Input/Observation/Answer来一步一步的思考如何回答问题。\n";
-
未来微服务HSF这种形式会向上往 agent工厂或者agent服务框架这种形式演进,因为这个框架搭好了后,后面各个业务方快速集成到agent服务上,可被上层AI应用层调用
-
-
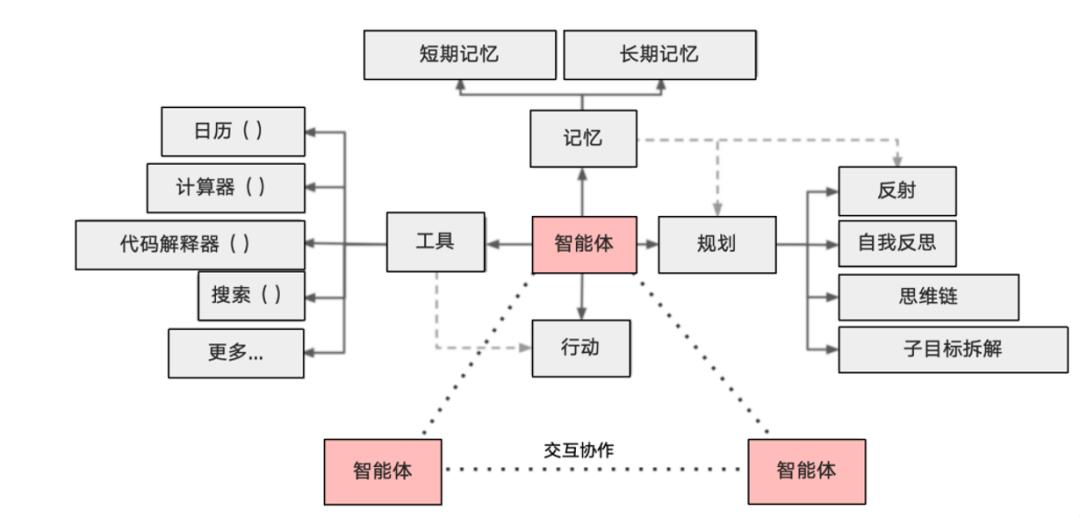
Agent体系架构可以分为慎思型、反应型和混合型。
慎思型构建负责规划和推理行为,反应型构建处理需要快速响应的重要事件。
信念-期望-意图(Belief-Desire-ltension, BDI) 体系架构是混合型体系架构的一个重要类型。 Agent的表示形式,Agent的行为可以被描述成好像拥有信念、期望和意图等思维状态。信念表示Agent拥有的知识,期望描述Agent追求的目标,意图说明Agent选择计划以实现哪些目标。
![]()
团队介绍
我们是淘天集团商家与开放平台团队,目前主要围绕商家的日常经营场景,为中小商家提供高效易用的电商工具。