一、平台介绍
财务自营计费主要承接京东自营数据在整个供应链中由C端转B端的功能实现,在整个供应链中属于靠后的阶段了,系统主要功能是计费和向B端的汇总。
二、问题描述
近年来自营计费数据量大增,有百亿+的数据量,一天中汇总占据了一半的数据库资源。
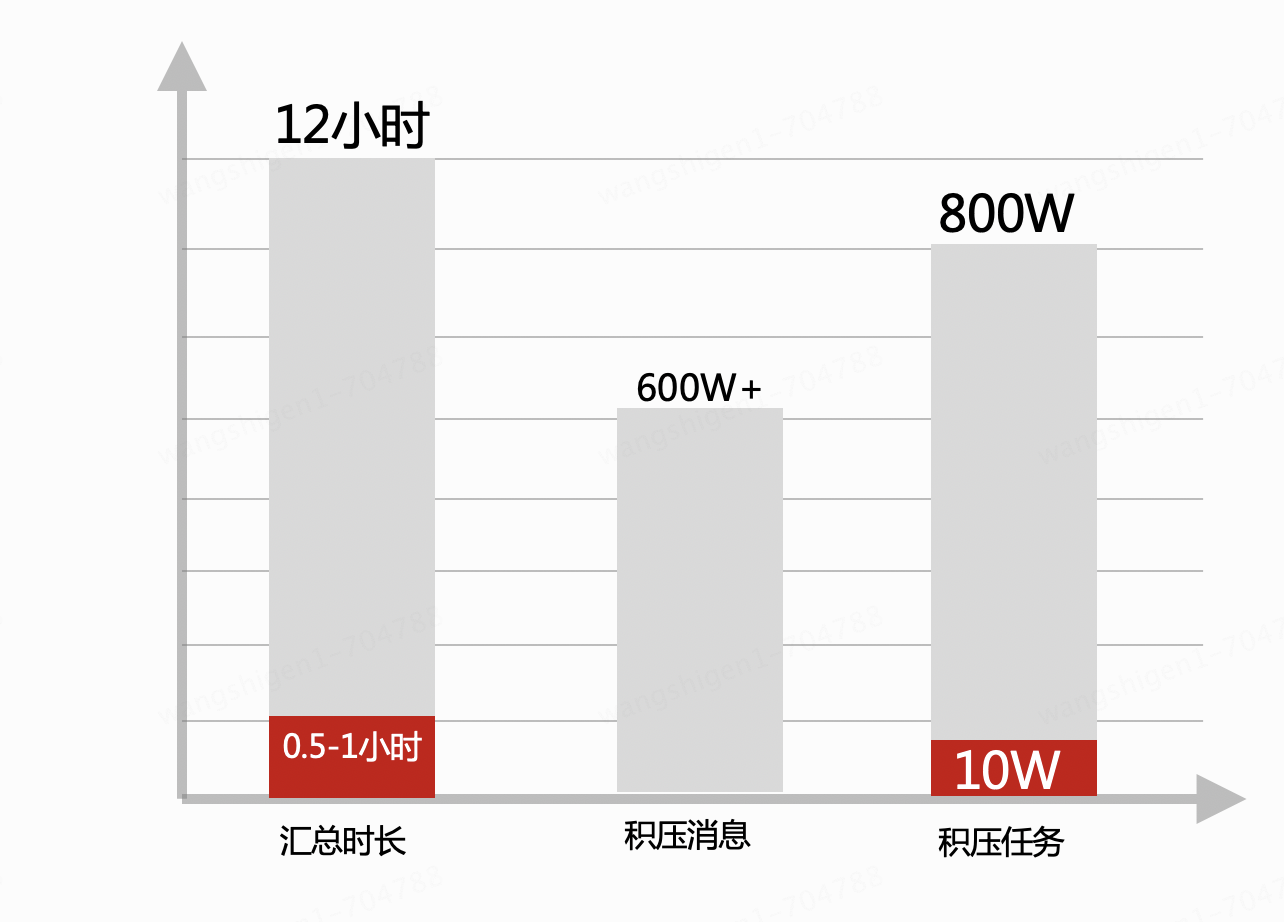
1、每天从单表千万W+中定位几万数据执行汇总,即全库全表执行group by操作,32库*32表,每天要花12小时处理。
2、汇总期间,系统基本停滞,导致了消息、任务处理慢,积压多,数据无法及时计费。
3、数据库压力大,有随时崩溃的风险。
4、影响供应商体验,大促期间供应商要实时查看销售数据,出战报,系统无法及时响应。
三、原技术介绍
系统汇总核心是依靠MySQL物理机在每库每表通过group by进行,汇总是按费用类型分而治之,每种类型汇总维度不一样,每次如有新的汇总维度引入,需从前到后,写一遍新的汇总逻辑,主要是锁定新维度的数据范围,确定新的group by 字段,之前逻辑还得回归测试,很蠢是吧,我也觉得。
四、解决问题的思路和办法
根据以上的背景和问题,确定大致的解决问题思路
1、首先要脱离MySQL汇总,数据库是很脆弱的,要保护数据库,不然量级一直递增,总有天塌的一天。
2、顺带解决新需求重复开发的弊端。
五、实践过程描述
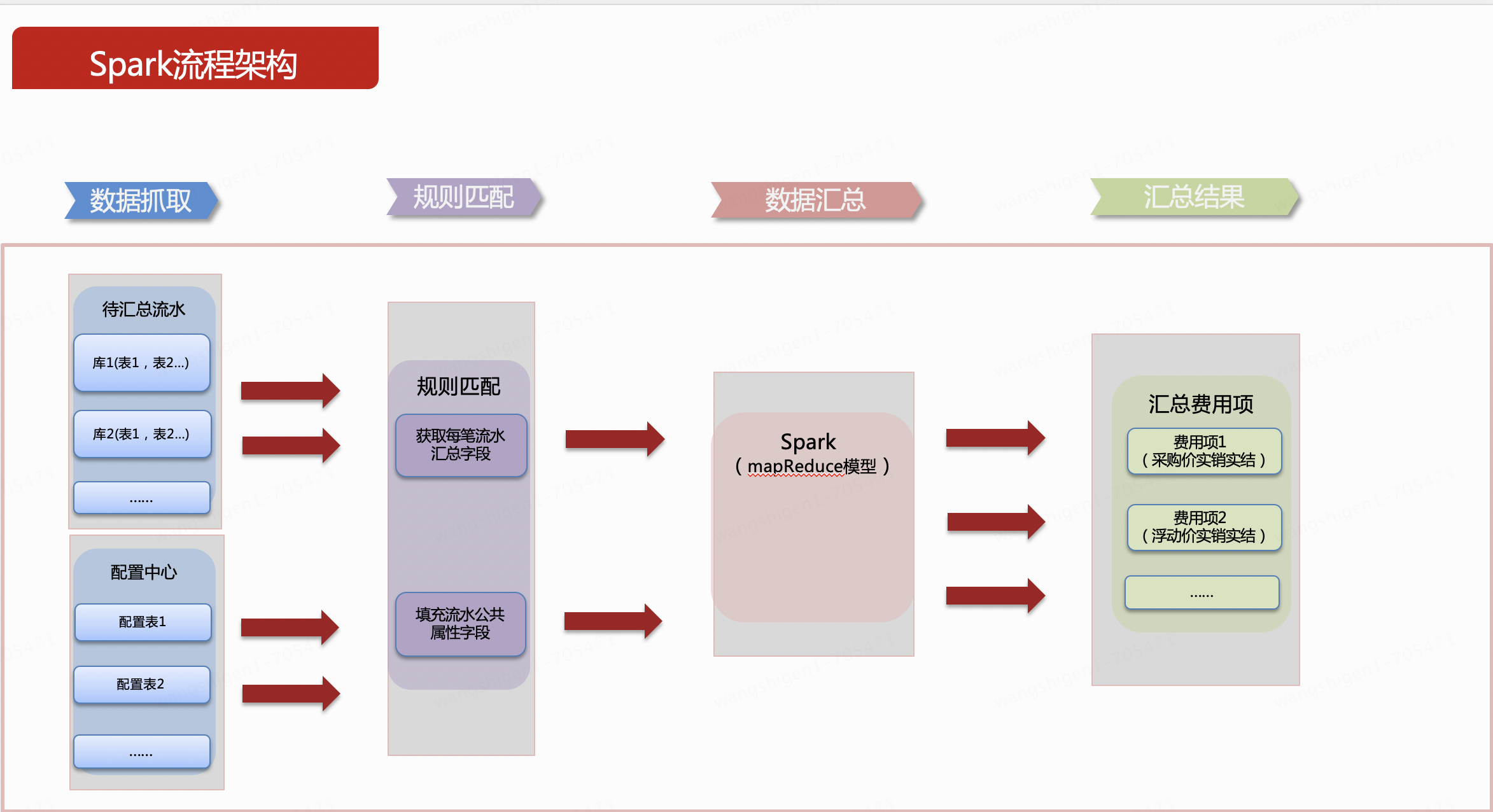
由于量大,业务上允许T+1处理,既然是离线数据处理,一般都能想到spark,spring batch,finlk等,在技术调研阶段,主要考虑成熟性,社区活跃度,主要采用spark技术。按照汇总的流程划分4个步骤。以下内容为了通俗易懂,简化了逻辑进行简单描述下。
1、数据抓取
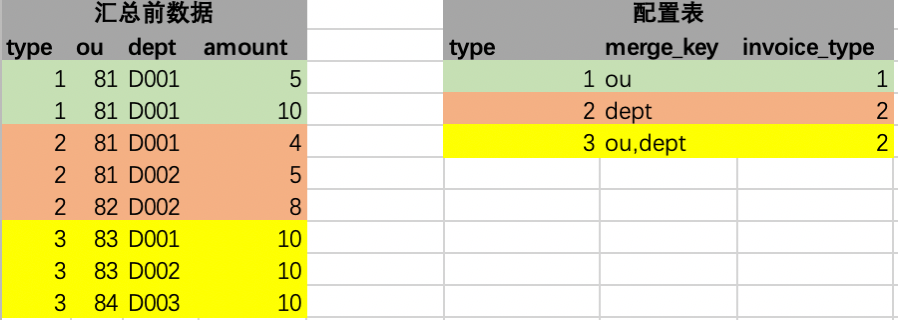
汇总前数据,就是业务数据,type泛指业务数据中划分数据费用类型的字段,ou、dept泛指源数据的维度,可以是别的一个或者多个字段,amount就是要汇总求和的字段,此处用金额表示。
配置表,就是针对源数据衍生出来的,配置数据可以由很多个,是泛指,本系统只用到了一张。type表示费用类型用来和源数据关联使用,关联可以用一个或者多个字段关联,此处用一个字段举例,merge_key是汇总的字段,字段取值是从源数据的表结构的一个或者多个字段组成。invoice_type,代表汇总后的结果集需要填充的公共字段,此处用发票类型来泛指。可以根据填充的字段扩充,扩充的话在配置表中往后增加列即可。如下示例图以单个字段表达这个意思。
2、规则匹配
进行第一次加工,即把源数据中的每一行和配置表中的唯一一行关联,如下图,特殊说明下,源数据的每一行,在配置表中有且仅有一行配置可以关联上,即left join,无法关联上的,即无配置,过滤掉,不进行汇总。第一步骤加工操作是在内存中操作完成。
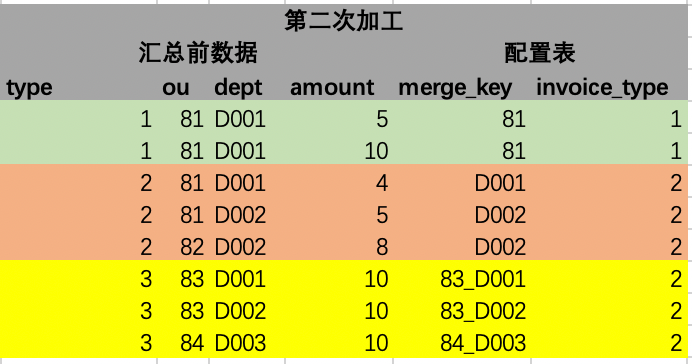
然后进行第二步骤加工,此步骤我们需要把从配置表中取出的merger_key字段进一步解析成当前left join后的行所对应字段的具体值。解析后的结果如下图,此步骤说明下,根据merger_key的字段,比如第一行ou,获取本行对应列的字段值,就是81,原理是通过Java反射实现,现在已有各种开源的工具包可以直接用,如spring的表达式等工具。以此类推,也能获取多个字段的值,多个字段可以按照一定的连接符号拼接,此图以_拼接。填充字段也同步进行添加。
3、数据汇总
规则匹配数据加工完毕后,我们只需要对加工完毕后的merger_key字段进行汇总,汇总引擎中只需要按照固定的汇总字段(此处举例是第二步骤加工完毕后的merger_key字段),汇总的逻辑就能够固化下来,只需要1个通用sql即可实现所有费用类型的汇总,最终产生的汇总结果。
4、汇总结果
汇总后的数据和通过原技术实现汇总出来的数据能保持一样的结果,同时还能填充一些公共的字段。如下图,其中绿色的2行源数据,按ou汇总在结果表中变成1行;橙色的3行源数据按dept汇总在结果表中变成2行;黄色的源数据按ou、dept字段汇总变成3行。
最后把这个汇总结果回写到MySQL即可。
六、实践过程思考和效果评价
1、在测试环境验证的过程中,测试表和线上表表数量级别不一样,初上线时,读取数据超慢。由于spark读取单表速度很快,读取分库分表数据效率直线下降,此处采用多线程方式去读符合条件的未汇总数据,最后汇总一个大集合。
2、上线稳定运行一段时间后,性能对比图,主要是通过剥离了MySQL中执行group by的操作,汇总时长下降了,数据库性能提高了,进而处理消息和异步任务能力也提高了,牵一发而影响全局。
3、后续有新的汇总需求上线时,通过配置即可实现新维度汇总功能,简化了研发工作,提高了需求交付时效。弊端也是有的,目前汇总维度的字段必须要从主表里取,因为spark读取业务数据只读取了主表,未读取扩展表。后续对hive表数据质量有信心,可以改成spark直接读取hive表,或者读es,ck等库。
4、通过spark框架引入、把大库汇总从在线改成离线,缓解了数据库压力,数据库性能提升后,从而也提升了计费的实效性,同时还增加了系统的稳定性,提升了供应商体验。
作者:王石根
来源:京东云开发者社区 转载请注明来源