背景
十年后数据库还是不敢拥抱NUMA, 这篇经典的纠正大家对NUMA 认知的文章一晃发布快3年了,这篇文章的核心结论是:
- 之所以有不同的NUMA Node 是不同的CPU Core 到不同的内存距离远近不一样所决定的,这是个物理距离
- 程序跑在不同的核上要去读写内存可以让性能差异巨大,所以我们要尽量让一个程序稳定跑在一个Node 内
- 默认打开NUMA Node 其实挺好的
写这个续篇是我收到很多解释,因为跨Node 导致性能抖动,所以集团在物理机OS 的启动参数里设置了 numa=off ,也就是不管BIOS 中如何设置,我们只要在OS 层面设置一下 numa=off 就能让程序稳定下来不再抖了! 我这几年也认为这是对的,只是让我有点不理解,既然不区分远近了,那物理上存在的远近距离(既抖动)如何能被消除掉的呢? 所以这个续篇打算通过测试来验证下这个问题
设置
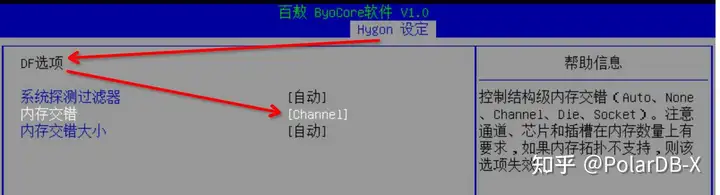
BIOS 中有 numa node 设置的开关(注意这里是内存交错/交织),不同的主板这个BIOS设置可能不一样,但是大同小异,基本都有这个参数
![]()
Linux 启动引导参数里也可以设置numa=on(默认值)/off ,linux 引导参数设置案例:
#cat /proc/cmdline
BOOT_IMAGE=/vmlinuz-3.10.0-327.x86_64 ro crashkernel=auto vconsole.font=latarcyrheb-sun16 vconsole.keymap=us BIOSdevname=0 console=tty0 console=ttyS0,115200 scsi_mod.scan=sync intel_idle.max_cstate=0 pci=pcie_bus_perf ipv6.disable=1 rd.driver.pre=ahci numa=on nosmt=force
注意如上的 numa=on 也可以改为 numa=off 看完全置篇要记住一条铁律:CPU到内存的距离是物理远近决定的,你软件层面做些设置是没法优化这个距离,也就是没法优化这个时延 (这是个核心知识点,你要死死记住和理解,后面的一切实验数据都回过头来看这个核心知识点并揣摩)
实验
测试机器CPU,如下是BIOS numa=on、cmdline numa=off所看到的,一个node
#lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz
Stepping: 4
CPU MHz: 2500.000
CPU max MHz: 3100.0000
CPU min MHz: 1000.0000
BogoMIPS: 4998.89
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 33792K
NUMA node0 CPU(s): 0-95
测试工具是lmbench,测试命令:
for i in $(seq 0 6 95); do echo core:$i; numactl -C $i -m 0 ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1
上述测试命令始终将内存绑定在 node0 上,然后用不同的物理core来读写这块内存,按照前一篇 这个时延肯定有快慢之分 BIOS和引导参数各有两种设置方式,组合起来就是四种,我们分别设置并跑一下内存时延,测试结果:
![]()
测试原始数据如下(测试结果文件名 lat.log.BIOSON.cmdlineOff 表示BIOS ON,cmdline OFF ):
//从下面两组测试来看,BIOS层面 on后,不管OS 层面是否on,都不会跨node 做交织,抖动存在
//BIOS on 即使在OS层面关闭numa也不跨node做内存交织,抖动存在
//默认从内存高地址开始分配空间,所以0核要慢
#grep -E "core|64.00000" lat.log.BIOSON.cmdlineOff
core:0 //第0号核
64.00000 100.717 //64.0000为64MB, 100.717 是平均时延100.717ns 即0号核访问node0 下的内存64MB的平均延时是100纳秒
core:24
64.00000 68.484
core:48
64.00000 101.070
core:72
64.00000 68.483
#grep -E "core|64.00000" lat.log.BIOSON.cmdlineON
core:0
64.00000 67.094
core:24
64.00000 100.237
core:48
64.00000 67.614
core:72
64.00000 101.096
//从下面两组测试来看只要BIOS off了内存就会跨 node 交织,大规模测试下内存 latency 是个平均值
#grep -E "core|64.00000" lat.log.BIOSOff.cmdlineOff //BIOS off 做内存交织,latency就是平均值
core:0
64.00000 85.657 //85 恰好是最大100,最小68的平均值
core:24
64.00000 85.741
core:48
64.00000 85.977
core:72
64.00000 86.671
//BIOS 关闭后numa后,OS层面完全不知道下层的结构,默认一定是做交织
#grep -E "core|64.00000" lat.log.BIOSOff.cmdlineON
core:0
64.00000 89.123
core:24
64.00000 87.137
core:48
64.00000 87.239
core:72
64.00000 87.323
从数据可以看到在BIOS 设置ON后,无论 OS cmdline 启动参数里是否设置了 ON 还是 OFF,内存延时都是抖动且一致的(这个有点诧异,说好的消除抖动的呢?)。如果BIOS 设置OFF后内存延时是个稳定的平均值(这个比较好理解)
疑问
- 内存交错时为什么 lmbench 测试得到的时延是平均值,而不是短板效应的最慢值? 测试软件只能通过大规模数据的读写来测试获取一个平均值,所以当一大块内存读取时,虽然通过交织大块内存被切分到了快慢物理内存上,但是因为规模大慢的被平均掉了。(欢迎内核大佬指正)
- 什么是内存交织? 我的理解:假如你有8块物理内存条,如果你有一个int 那么只能在其中一块上,如果你有1MB的数据那么会按cacheline 拆成多个块然后分别放到8块物理内存条上(有快有慢)这样带宽更大,最后测试得到一个平均值 如果你开启numa那么只会就近交织,比如0-3号内存条在0号core所在的node,OS 做内存交织的时候只会拆分到这0-3号内存条上,那么时延总是最小的那个,如上测试中的60多纳秒。
这个问题一直困扰了我几年,所以我最近再次测试验证了一下,主要是对 BIOS=on 且 cmdline=off 时有点困扰
Intel 的 mlc 验证
测试参数: BIOS=on 同时 cmdline off 用Intel 的 mlc 验证下,这个结果有点意思,latency稳定在 145 而不是81 和 145两个值随机出现,应该是mlc默认选到了0核,对应lmbench的这组测试数据(为什么不是100.717, 因为测试方法不一样):
//如下是前面 lmbench 测试结果,抄下来和 mlc 做个对比
//从下面两种测试来看,BIOS层面 on后,不管OS 层面是否on,都不会跨node 做交织,抖动存在
//BIOS on 即使在OS层面关闭numa也不跨node做内存交织,抖动存在
#grep -E "core|64.00000" lat.log.BIOSON.cmdlineOff
core:0
64.00000 100.717
core:24
64.00000 68.484
core:48
64.00000 101.070
core:72
64.00000 68.483
对应的mlc
#./mlc
Intel(R) Memory Latency Checker - v3.9
Measuring idle latencies (in ns)...
Numa node
Numa node 0
0 145.8 //多次测试稳定都是145纳秒
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 110598.7
3:1 Reads-Writes : 93408.5
2:1 Reads-Writes : 89249.5
1:1 Reads-Writes : 64137.3
Stream-triad like: 77310.4
Measuring Memory Bandwidths between nodes within system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Numa node
Numa node 0
0 110598.4
Measuring Loaded Latencies for the system
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Inject Latency Bandwidth
Delay (ns) MB/sec
==========================
00000 506.00 111483.5
00002 505.74 112576.9
00008 505.87 112644.3
00015 508.96 112643.6
00050 574.36 112701.5
当两个参数都为 on 时的mlc 测试结果:
#./mlc
Intel(R) Memory Latency Checker - v3.9
Measuring idle latencies (in ns)...
Numa node
Numa node 0 1
0 81.6 145.9
1 144.9 81.2
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 227204.2
3:1 Reads-Writes : 212432.5
2:1 Reads-Writes : 210423.3
1:1 Reads-Writes : 196677.2
Stream-triad like: 189691.4
说明:mlc和 lmbench 测试结果不一样,mlc 时81和145,lmbench测试是68和100,这是两种测试方法的差异而已,但是快慢差距基本是一致的
结论
在OS 启动引导参数里设置 numa=off 完全没有必要、也不能解决抖动的问题,反而设置了 numa=off 只能是掩耳盗铃,让用户看不到 NUMA 结构
原文链接
本文为阿里云原创内容,未经允许不得转载。