一、背景介绍
CDP系统提供了强大的标签和群体的构建能力,面对海量数据的标签和群体,我们采用了Bitmap+ClickHouse的存储与计算方案。详细内容可以参考之前文章。
有了群体之后,它们被广泛的应用到支付,消金,财富,营销等各种核心业务的用户拉新,交易转化,促活等核心链路中。
而人群应用方式中,基于人群的命中服务,是非常重要的P0级接口(日常TPS峰值40W+,响应耗时50ms以内,大促备战120W+)
它主要用来查询指定用户ID是否包含在指定群体中,这篇文章就来分享人群命中接口的演进迭代过程。
二、问题描述
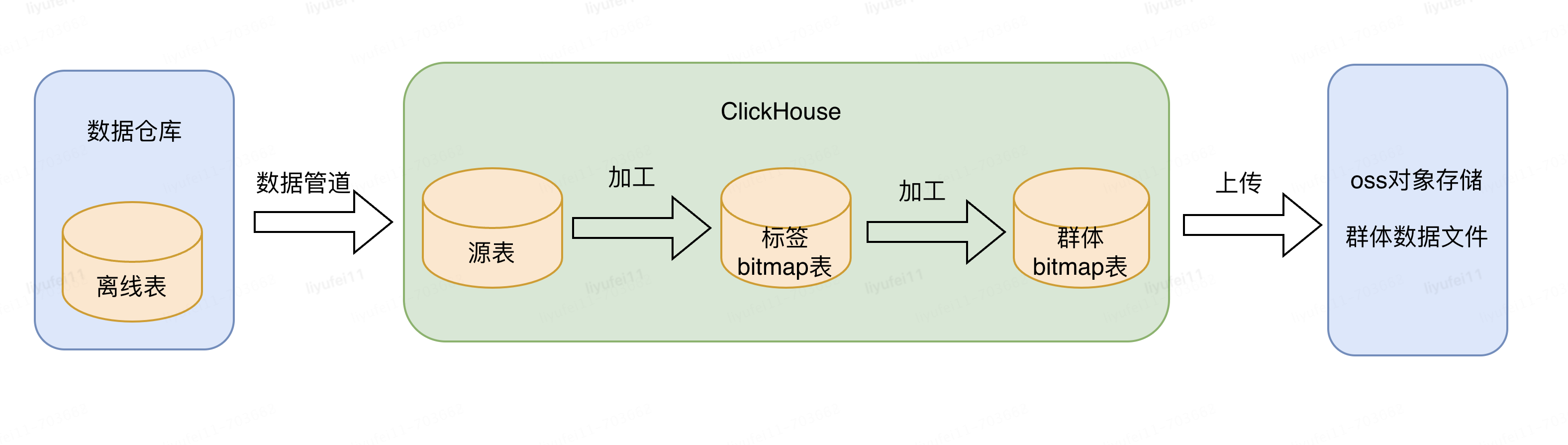
前文已经介绍了CDP中群体的加工和存储方式,采用了ClickHouse(以下简称CK)+Bitmap的方案,为了减轻ClickHouse的计算和存储压力,我们的22000+群体目前只在CK中存储了最新的版本。
这是因为CDP中标签和群体的计算都在CK中,而且依赖的都是最新数据,所以只存储最新数据即可满足需求。如下图:
上图可以看到除了CK中的数据外,我们在OSS对象存储中也放了一份群体数据。
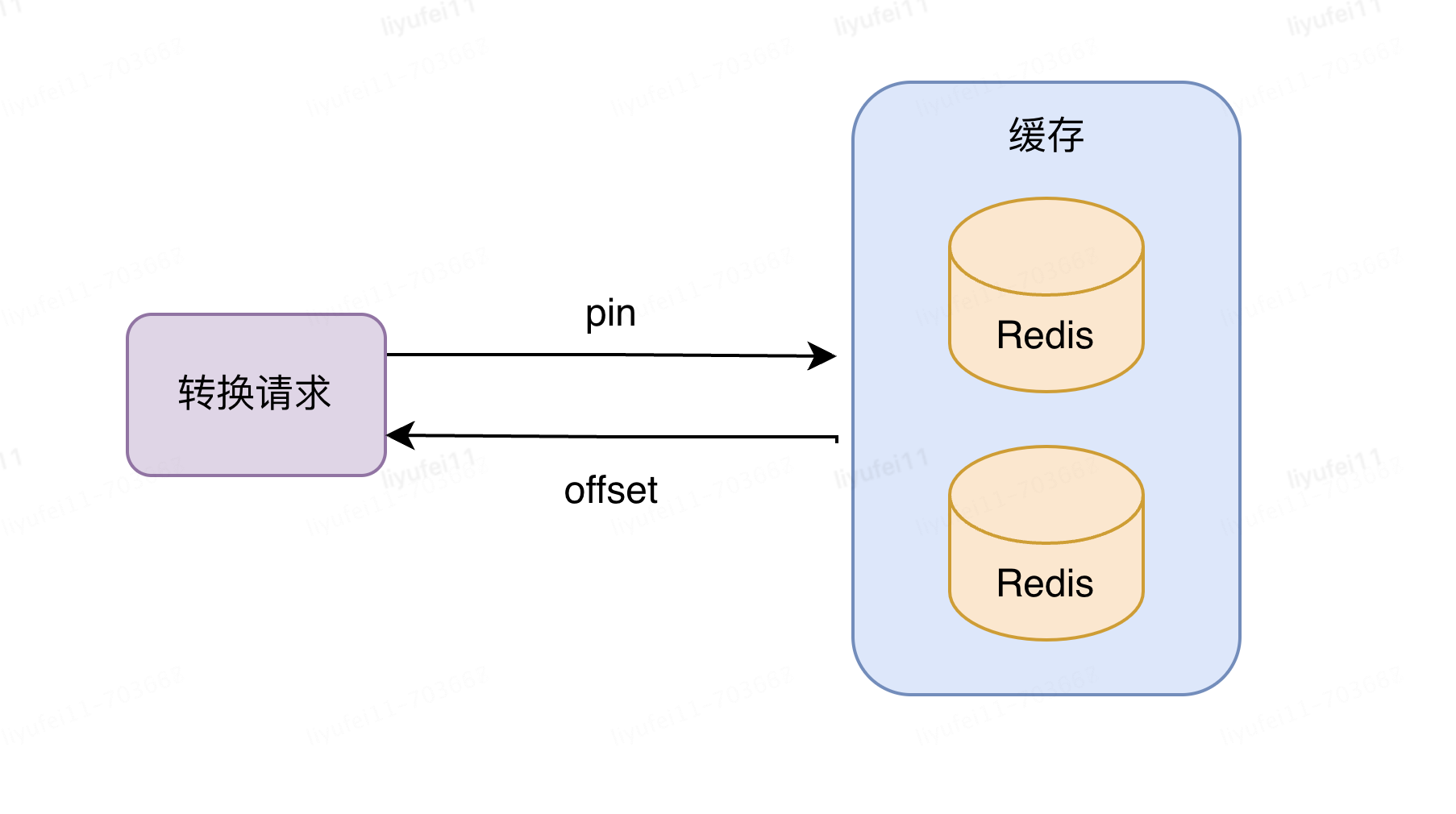
由前文可知,群体的bitmap文件中可以理解为存储的都是offset,这时候如果想查询某一个ID是否在指定群体中,即人群命中服务,需要两个步骤。
首先要将ID转换为bitmap中对应的唯一offset,之后可以尝试直接利用CK SQL查询,bitmapContains(bitmap, offset)来进行判断是否在指定bitmap中。
也可以从CK或OSS中加载指定群体的bitmap,在JAVA程序中使用Roaring64NavigableMap的能力进行判断。
但是,直接使用CK SQL或者oss文件加载方式,肯定都无法直接满足50ms性能的问题。接下来就对我们的前后两套方案进行讲解。
三、历史方案
首先介绍我们的上一版方案,针对上文的问题,可以分解为两步,第一步解决ID到offset的高性能转换;第二步判断offset是否包含在指定群体的bitmap中。
1)解决数十亿ID和offset的快速转换
之前文章中提到,由于用户ID是唯一且不变的,所以对所有的ID进行了编码,每个ID对应一个唯一的offset,并生成了最终的一张ID池表,比如id_offset_table。
有了这些数据之后,就可以考虑如何进行快速查询来进行ID和offset的转换了。
最简单的思路就是每次去表中查询:
SELECT `offset` FROM id_offset_table where id='id1'
但是这种直接查询的方式,显然不能满足高性能的需求,所以,最自然的方式是将常用的ID的结果进行缓存;而常用缓存的方式可以选择缓存到请求的服务器内存,也可以加入到Redis缓存中。
由于目前的ID池已经达到了惊人的数十亿,放到请求服务器内存中,极限情况预计需要500G的内存,单机存放显然是不太现实的。
所以这里最终选择的是放入到Redis缓存中,这也是目前我们采用的方式。
2)判断offset是否包含在指定群体的bitmap中
有了ID对应的offset,接下来就是如何判读是否存在于指定bitmap中;bitmap目前由两个地方存储,一个是CK中,另一个是OSS对象存储中。
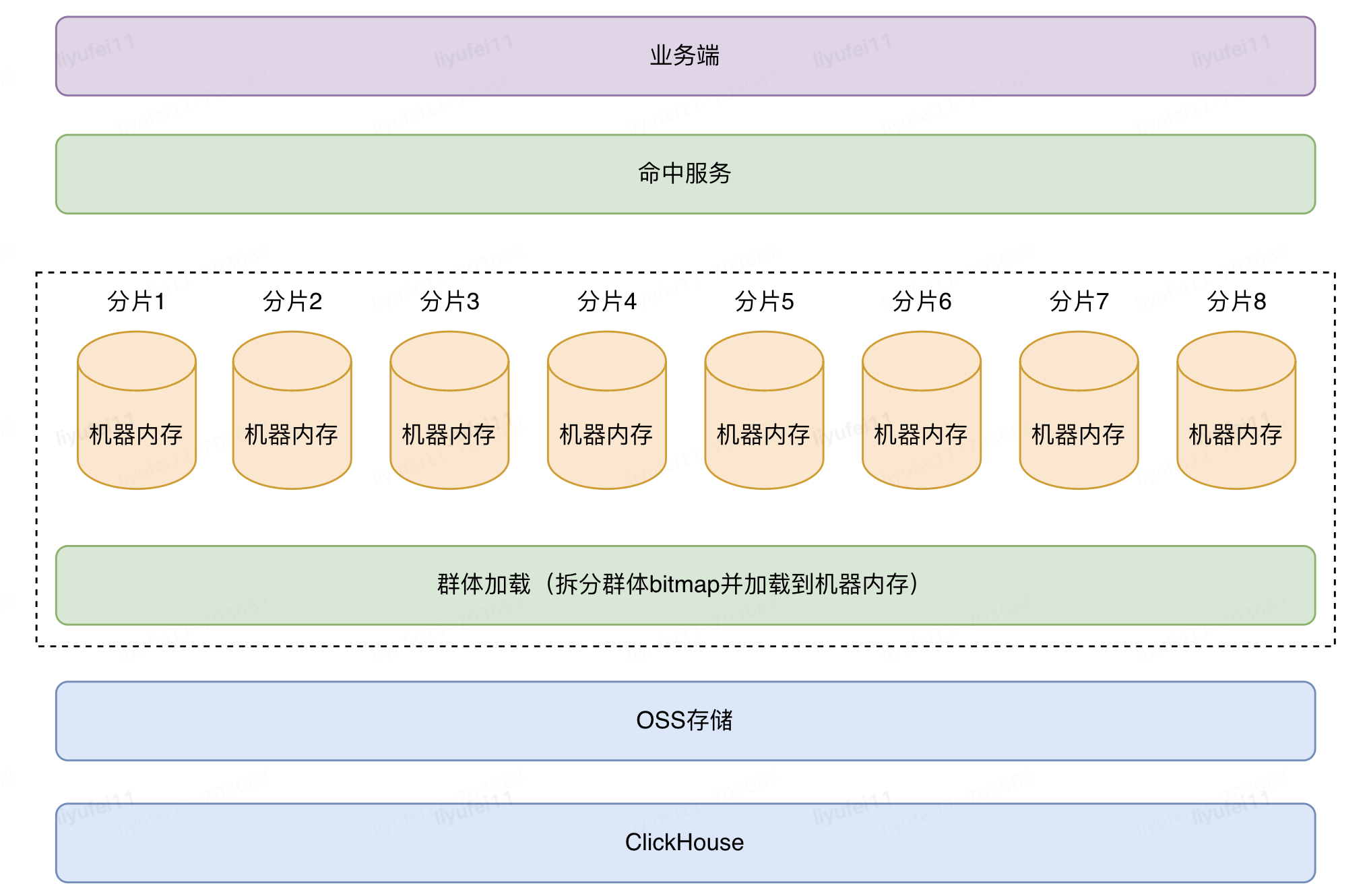
之前方案,没有从CK中获取bitmap,采用的是从OSS中将群体文件,直接拉取到大内存物理中,然后再通过接口读取内存数据实现。
这样做的好处是,减少了CK的访问次数,减轻它的压力,毕竟CDP平台的几千个标签和上万个群体的更新都依赖于CK,减轻它的压力,同样的集群配置可以让更多资源留给计算。
但由于群体太多,将OSS文件放入单机内存中,是无法装载所有群体的(采用了32核192G的机器),所以针对群体还进行了分片处理(分为8片,每片中又包含若干台机器),将一个群体的大bitmap拆成若干个小的bitmap,再按照分片通过hash算法加载到不同分组机器的内存中,如下图:
这套方案是将物理机内存作为存储空间,并且使用自研的分片方案,再通过接口层直接读取bitmap数据来获取命中结果。
// 获取命中结果示例
Roaring64NavigableMap bitmap = getBitmap();
boolean isHit = bitmap.contains(offset);
需要注意的是由于对群体数据进行了分片存储,所以存和取的逻辑需要保持统一才能取到正确结果。
3)方案优缺点
通过Redis存储ID和offset的关系,人群数据拆分到8分组机器内存中,实现了群体命中接口的性能需求,总结此历史方案的优缺点,如下:
优点:
1、通过从OSS拉取文件方式,减少CK的查询次数,降低CK压力。
2、拆分逻辑自研,实际上是替换小文件,直接覆盖小文件更新速度快。
3、可分组内水平扩容机器,增加接口整体承载量,经过压测单机可到30000QPS。
4、直接机器内存取值,快速返回结果,满足接口TP999:50ms内需求,但严重依赖机器性能。
缺点:
1、由于加载到机器内存,导致每次重启机器总要全量加载所有群体,启动非常慢(虽然经过优化启动效率已经提升了很多,但随着群体数量的增加重启也会越来越慢)
2、虽然分组内可以水平扩容,但是固定分组后,单机器的内存有限,一旦达到上限需要扩容分组时,必须成倍的扩容,导致扩容分组困难;
3、由于是自研的依赖于机器内存的存储方案,整体结构复杂,在运维的能力方面偏弱,运维的相关工具少;无法有效监控内存数据,这就间接造成了系统的稳定性较差。
4、使用物理机,曾经在大促期间占用了100+台物理机,耗费资源很大。
四、最新方案
上述历史方案中,可以看到ID转offset的方案没有问题;主要问题出在判断offset是否包含在指定群体bitmap这一步中。所以在最新方案中,只对群体加载与offset的判断进行重新梳理及优化。
1)Redis多集群多分片写入
思路和上文中的内存方案类似,都是部署多个集群(或分组),将群体bitmap进行拆分,并根据一定的路由策略存储到不同的集群上,通过不同的集群提供查询能力,如下图:
在新方案中,增加了一整套的群体推送服务,包括数据的新增,更新,删除,检测,重试以及预警等策略,大大增强了群体加载的可监测性及有效性,而在之前的方案中,非常缺少这些有效的运维手段。
2)数据加载策略
和内存加载不同的是,Redis存储中不能再使用文件替换方案,只能采用其他的写入方案。
在这之中,还需要考虑如何保证写入的过程中不影响命中接口的性能。
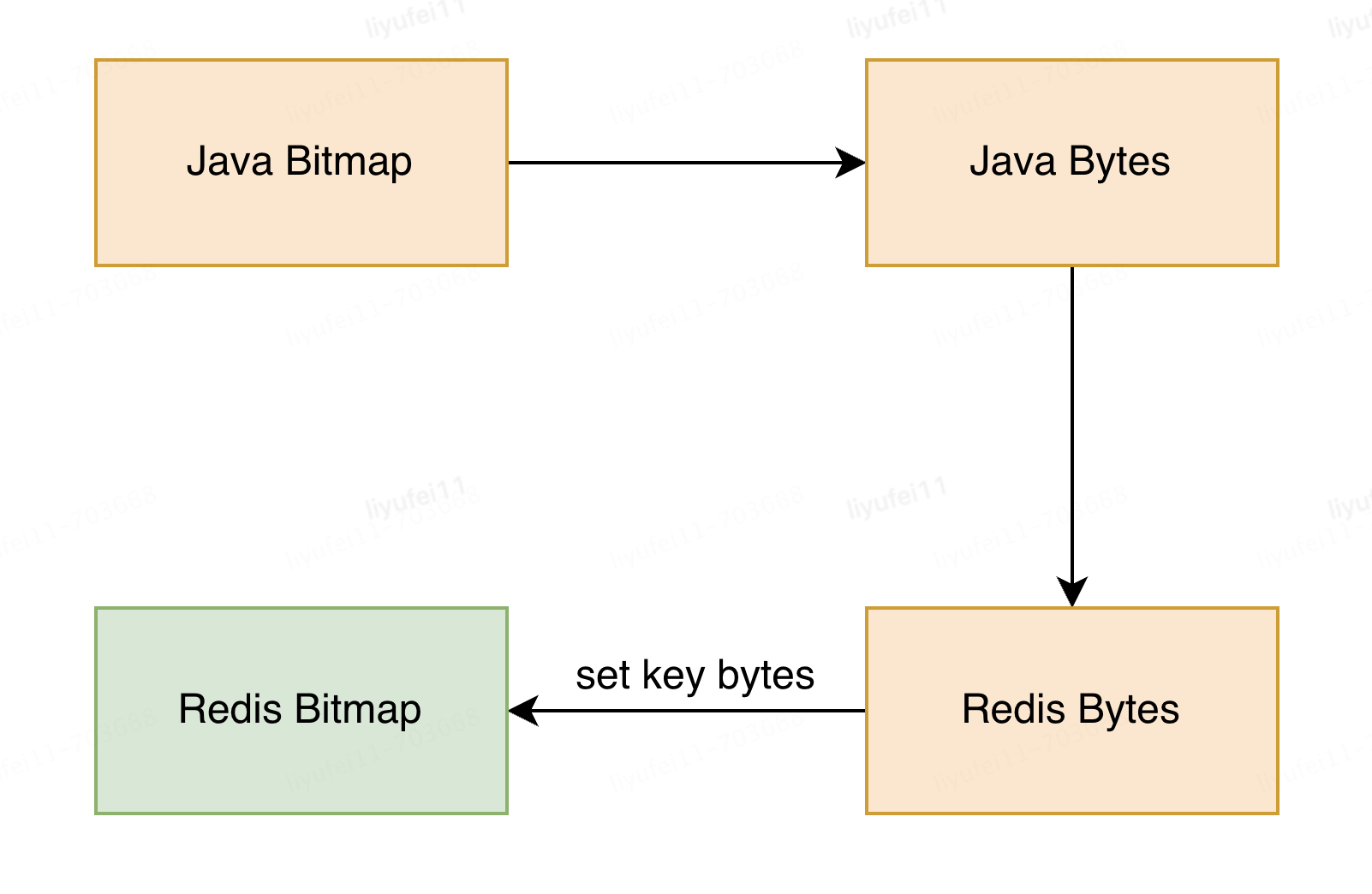
针对群体数据,同样采用了拆分的思路,把每一个群体按照固定区间切成若干个小的bitmap,并为每个小bitmap编号(即桶号,此桶号同样采用bitmap存储在索引里),缓存key为群体code加上桶号,以便快速取到offset值。
然后将小bitmap的数据转化成字符串的形式,并且拆分之后可以将数据按照Hash规则,均匀的分布到不同的缓存分片(我们最终的分片数达到了16个集群*64分片=1024片)。如下图:
对于读取来说,假如人群命中有1000万QPS,则每个集群分到62.5万,均摊到64个分片也才不到1万,可以说对缓存的单分片来说毫无压力。
对于写入来说,如果按照一个个bit写入的方式,耗时是不可接受的,在这方面我们采用的是将Java字节码转换为Redis字节码,最终以set(key, string)的方式进行数据写入。
这种方式具有以下优点:
1、单值小:每个bitmap最多有65536个Offset(bit位),相当于最大8kb,不会在缓存中产生较大key而导致性能差
2、写入快:每个key一次性写入到缓存,但是最多可以含有65536个offset(ID),42.94亿群体只需要65536次写入
3、查询效率高:getbit支持查询key下面每个offset,时间复杂度是O(1)
4、拆分压缩数据:拆分多个小的bitmap,相当于是对bitmap进行了压缩
在验证过程中,一个42亿的群体按bit写入需要11.6个小时,而采用字节码转换的方式写入,只需要65~120秒之间,写入效率提升99.9%。
写入完成之后,使用Redis的getbit方法即可获取对应位的值,正如前文提到的即使是1000w的QPS,也能达到高性能命中的目标。
// 获取指定偏移量的值,例如某ID对应的offset为3
jedis.getbit("crowdBitmap", 3);
3)方案优缺点
优点:
1、采用公司内部存储中间件,有专业的运维团队支持。
2、Redis缓存支持主从备份,甚至是一主多从,支持高可用。
3、支持多分片,支持高并发场景,分摊到单个分片的流量较少。
4、写入与读取也很快,满足群体的快速更新需求。
5、只需要很少的机器写入与维护缓存,应用启动效率大大提升。
6、存储扩容方便,即使面对猛增的业务也可以从容应对。
缺点:
1、依赖于公司内部缓存中间件,倘若中间件出现问题,会造成很大影响;虽然理论上概率非常小。当然,也可以再做一个备份存储,这时需要考虑存储成本与收益之间的平衡。
五、现状及展望
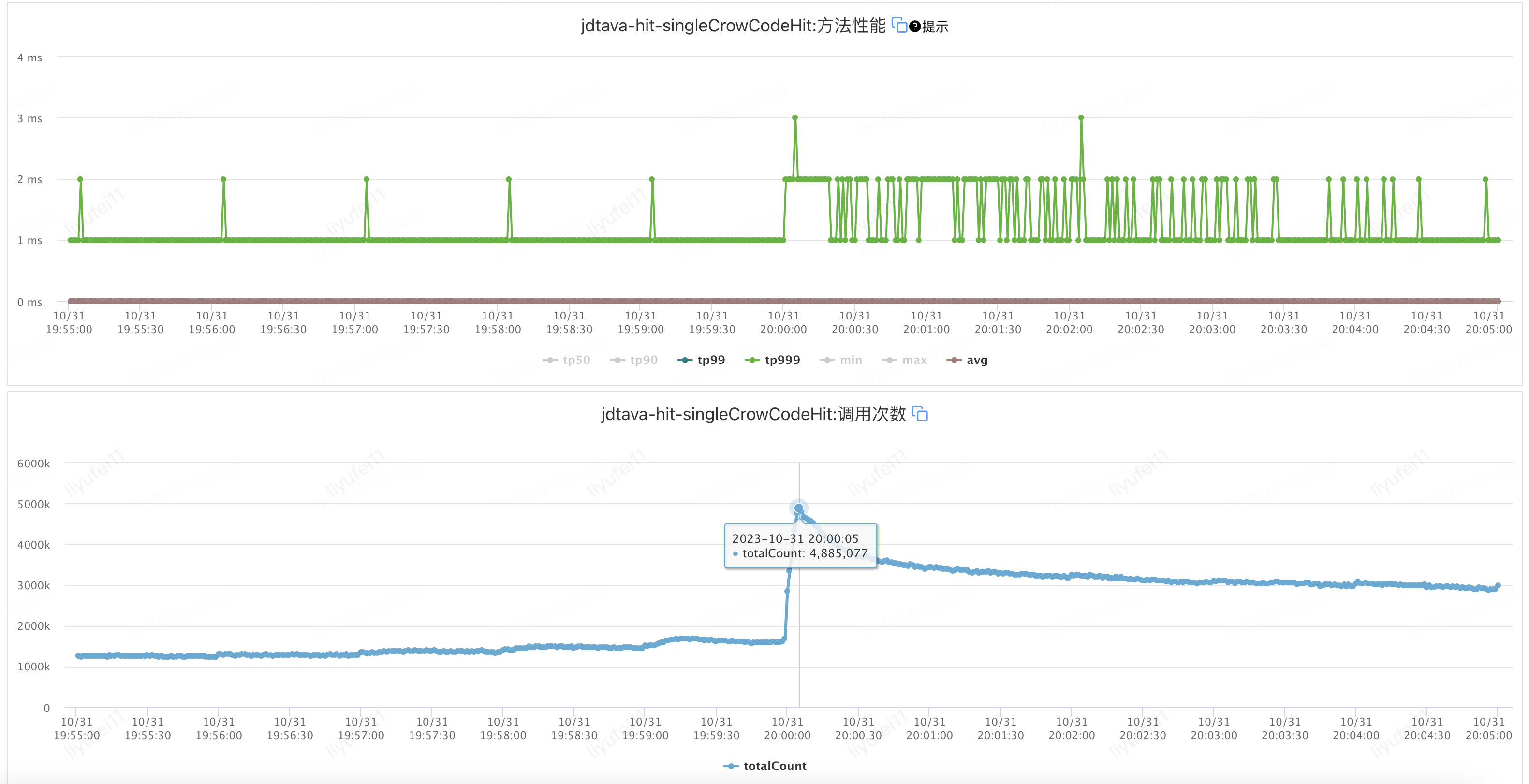
上述方案上线后,可以看到非常明显的提升,接口整体TP999耗时从40ms下降到25ms左右 ,如下图:
目前最新的方案经过23年双十一大促的检验,TPS峰值:49.7w/s,TP999峰值:24ms,单次访问查询达到了500w/s,(甚至在某一天军演压测时达到了1000w/s)平稳顺利地完成新老方案的过渡。
随着业务的不断发展,CDP中的群体数量还在持续增加中,按当前的增速评估,此方案已经能够完全支撑业务的持续发展,理论上可以支持到千万级TPS而无压力。
作者:京东科技 黎宇飞
来源:京东云开发者社区 转载请注明来源