作者:吴昆
前言
在前面的文章《弹性调度助力企业灵活应对业务变化,高效管理云上资源》中,我们介绍了阿里云容器服务 ACK 弹性调度为了帮助客户解决在使用云上弹性资源时,面对的“难以差异化控制业务资源使用量,缩容时部分业务 Pod 未释放”等挑战,提供了按照多级资源的优先顺序进行调度,以及按照定义的优先顺序进行缩容的能力。
本文将介绍弹性调度如何使用虚拟节点来满足您的业务弹性需求。
企业在实施应用弹性过程中,弹性速度和弹性位置是重点关注的两个核心指标。
对于追求高可用以及稳定性的企业来说,敏捷的弹性能够在业务流量突增时,保证系统的连续性与稳定性。同时,通过跨多地域部署应用,可以在地域性故障发生时,有效地维持服务的持续可用性。
对于大数据处理任务的企业来说,快速的弹性能够缩短任务执行时间,加快应用的迭代速度。同时,集中部署在单个地域,则可以减少应用之间的网络通信时延,从而进一步提升数据处理效率。
显然,这两个指标对于确保企业业务的稳定高效运行至关重要。
然而,许多企业在面对快速到来的业务流量高峰和日益增长的大数据算力需求时,现行的分钟级自动伸缩节点池的弹性响应已经无法满足需求。并且,通过合理的部署策略,实现预期的弹性位置,也颇具挑战。
为此,阿里云推出弹性容器实例(Elastic Container Instance,ECI),以十秒级的弹性速度,有效应对突发流量的弹性需求。同时,阿里云容器服务 Kubernetes 版(ACK)利用虚拟节点技术实现与 ECI 弹性资源的无缝集成,使得业务能够在集群内灵活动态地调用 ECI 资源,迅速应对弹性挑战。此外,容器服务 ACK 的弹性调度功能在将业务调度到 ECI 上时,还能维持业务的亲和性配置不变,确保应用运行的稳定和高效。
使用虚拟节点实现秒级弹性
为了在 ACK 中使用 ECI,需要在 ACK 集群中安装虚拟节点组件。
在 ACK Pro 版集群中,可以通过组件管理页面部署 ack-virtual-node 组件,该组件默认被托管,不占用 Worker 节点资源。
在 ACK 专有版集群中,可以通过应用市场页面部署 ack-virtual-node 组件,安装成功后会在 kube-system 命名空间下创建一个名为 ack-virtual-node-controller 的 deployment,该 deployment 会运行在您的 Worker 节点上。
安装成功后用户可以通过 kubectl get no 命令在集群中查看到若干虚拟节点,代表虚拟节点安装成功。
虚拟节点安装成功之后,可以使用弹性调度功能配置 ECI 的使用策略,以下是“优先调度 ECS,当 ECS 资源使用完后使用 ECI 资源”的示例。
apiVersion: scheduling.alibabacloud.com/v1alpha1
kind: ResourcePolicy
metadata:
name: test
spec:
strategy: prefer
units:
- resource: ecs
- resource: eci
配置了以上 ResourcePolicy 之后,在 default 命名空间下的所有 Pod 都将遵循以下的调度规则:优先使用 ECS,ECS 资源用完后使用 ECI。
🔔 需要注意的是: 以上配置会使得 ECS 节点上的抢占功能失效,如果需要同时保持在 ECS 上的抢占能力,请配置 preemptPolicy=BeforeNextUnit,如果需要限定生效的业务范围,请按需配置 selector。
以下是实际使用效果:
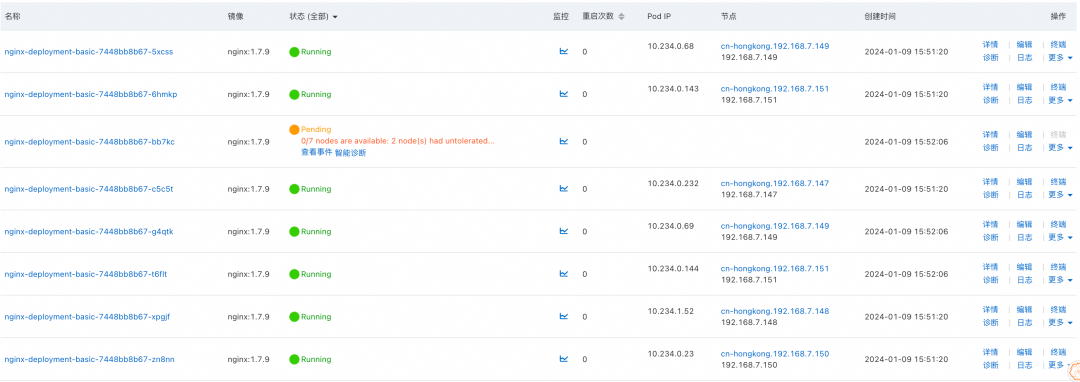
首先,提交一个 Deployment,8 个业务 Pod 中仅有 7 个业务 Pod 能够被成功调度。
![]()
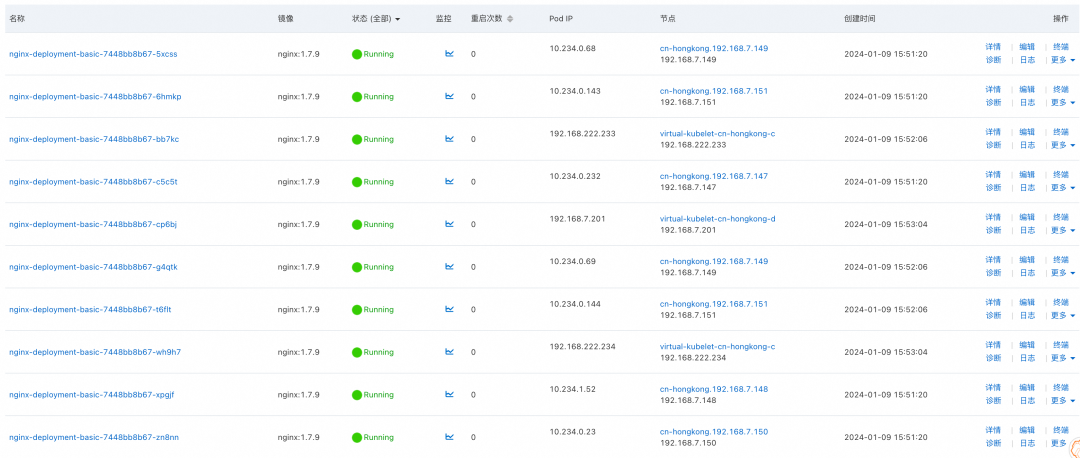
此时,提交 ResourcePolicy,并将 Deployment 的副本数增加到 10,新的副本将全部运行在 ECI 上。
![]()
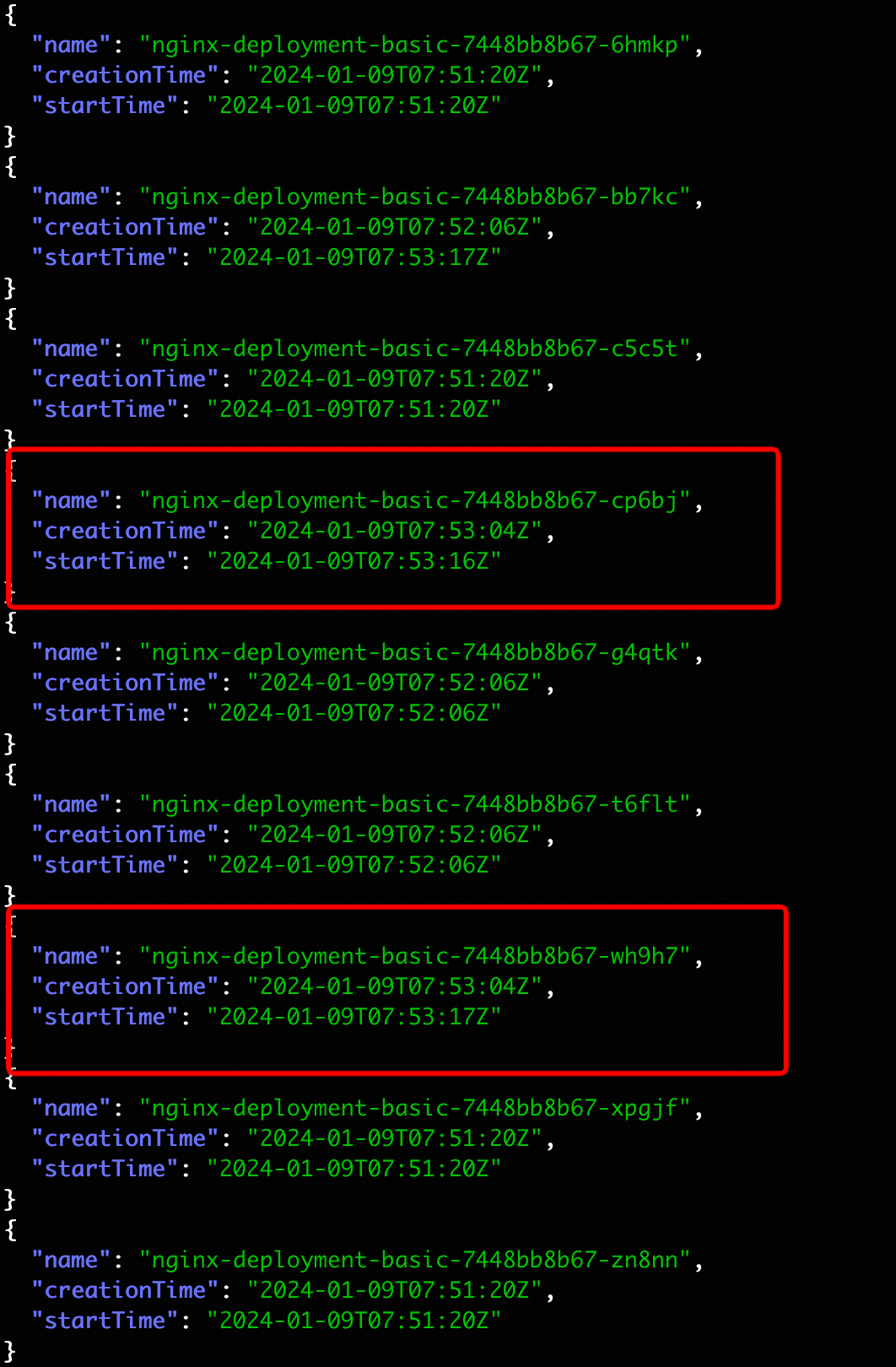
通过统计业务 Pod 的创建时间以及 startTime,可以看到这里新 Pod 的创建时间在 13 秒,远远低于自动伸缩节点所需的弹性时间。
![]()
降低大数据任务通信时延
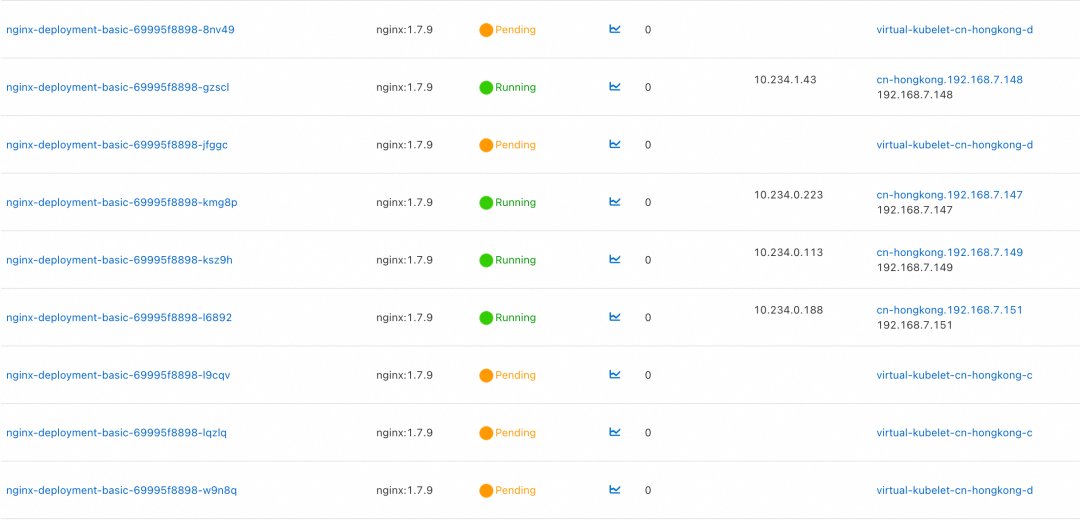
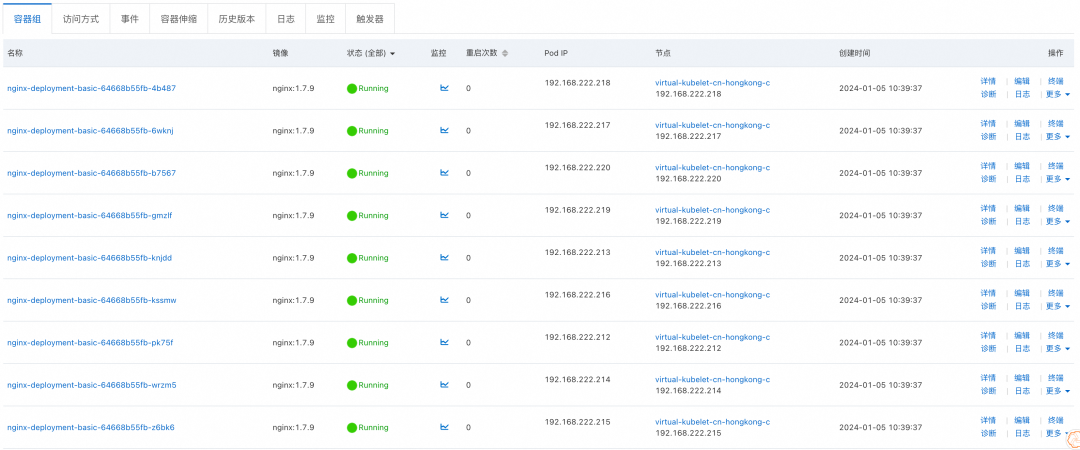
若您的集群配置了多个可用区的虚拟节点,在默认情况下,ECI Pod 可能会被调度在多个可用区上。如下图,在默认情况下,nginx 被调度到了 C 和 D 两个可用区的 virtual node 上。
![]()
![]()
对于大数据型应用,配置可用区亲和往往意味着计算 Pod 之间的网络通信代价更小,进而带来更高的吞吐量。通过阿里云弹性调度,您可以通过 Pod 上的节点亲和以及 Pod 亲和限制业务调度的可用区,从而实现 ECS 上的 Pod 与 ECI 上的 Pod 调度在相同的可用区上。
以下是两种在 ECI 上配置相同可用区调度的示例,分别使用了指定可用区调度以及不指定可用区调度两种方式,在以下的两个例子中,已提前提交了 ResourcePolicy:
手动指定可用区
原生 Kubernetes 提供了节点亲和调度语义来控制 Pod 的调度位置,以下的例子中我们指定 nginx 服务仅在可用区 C 上进行调度。您唯一需要进行的修改是在工作负载的 PodTemplate 或 PodSpec 中添加节点亲和约束。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx-deployment-basic
spec:
replicas: 9
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- cn-hongkong-c
containers:
- image: 'nginx:1.7.9'
imagePullPolicy: IfNotPresent
name: nginx
resources:
limits:
cpu: 1500m
requests:
cpu: 1500m
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
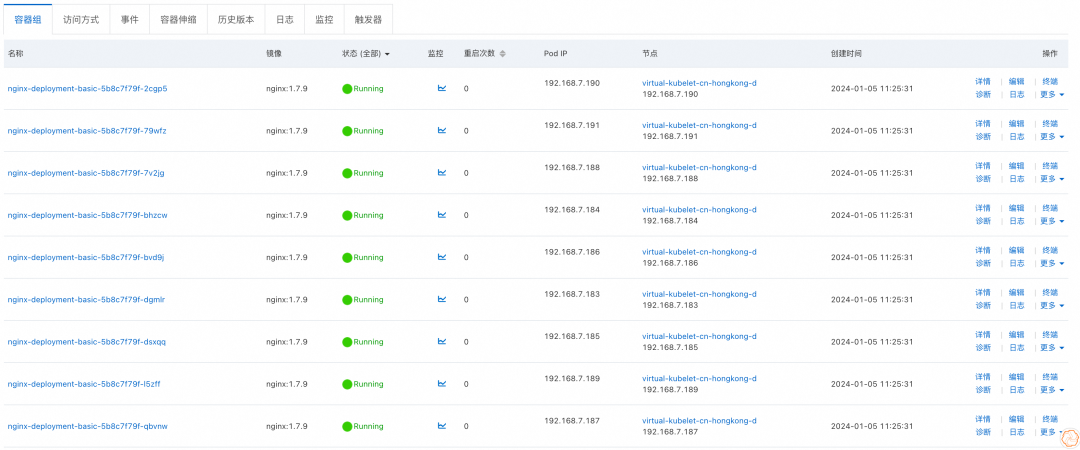
同样将业务 Pod 扩容到 9,此时能够观察到业务 Pod 全部运行在可用区 C 上,由于集群中 ECS 节点均为可用区 D 上的机器,因此所有业务 Pod 全部运行在 ECI 上。
![]()
最优可用区感知调度
为应对大数据计算需求,通常需要部署大量的 Pod,这时候确保 ECI 提供充足的算力资源成为关键。为确保选择到具有充足剩余算力的可用区,可以在指定可用区亲和时使用 Pod 亲和。在 ECI 调度过程中,调度器会参考 ECI 提供的可用区建议,选择一个可用算力更多的可用区,从而实现自动选择更优位置的效果。以下例子中我们将限制 Pod 仅在 ECI 上调度,并通过 Pod 亲和限制 Pod 必须被调度到同一个可用区。
🔔 注: Pod 亲和会使得后续 Pod 与第一个被调度的 Pod 亲和在相同可用区,当采用 ECS+ECI 弹性调度时,由于第一个被调度的 Pod 通常为 ECS Pod,会使得后续 ECI Pod 亲和在 ECS 相同的可用区,此时建议您使用 preferredDuringSchedulingIgnoredDuringExecution。
提交的 ResourcePolicy 为:
apiVersion: scheduling.alibabacloud.com/v1alpha1
kind: ResourcePolicy
metadata:
name: test
spec:
strategy: prefer
units:
- resource: eci
提交的工作负载为:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx-deployment-basic
spec:
replicas: 9
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: topology.kubernetes.io/zone
containers:
- image: 'nginx:1.7.9'
imagePullPolicy: IfNotPresent
name: nginx
resources:
limits:
cpu: 1500m
requests:
cpu: 1500m
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
提交后可用发现,此时 Pod 依然均调度在相同的可用区,此时调度到的可用区将会是 ECI 推荐的更优可用区。
![]()
保证在线业务高可用
对于在线业务而言,配置业务多可用区部署是保证业务高可用的一种有效手段。通过阿里云弹性调度,您可以通过 Pod 上的拓扑分布约束来实现 ECS 上的 Pod 与 ECI 上的 Pod 遵循相同的拓扑分布约束,从而实现业务的高可用。
以下是一个在 ECI 上配置业务高可用的示例,指定了业务 Pod 在多个可用区上均匀分布,并且在 ECS 资源不足时使用 ECI。
apiVersion: scheduling.alibabacloud.com/v1alpha1
kind: ResourcePolicy
metadata:
name: test
spec:
strategy: prefer
units:
- resource: ecs
- resource: eci
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx-deployment-basic
spec:
replicas: 9
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
topologySpreadConstraints:
- labelSelector:
matchLabels:
app: nginx
maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
containers:
- image: 'nginx:1.7.9'
imagePullPolicy: IfNotPresent
name: nginx
resources:
limits:
cpu: 1500m
requests:
cpu: 1500m
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
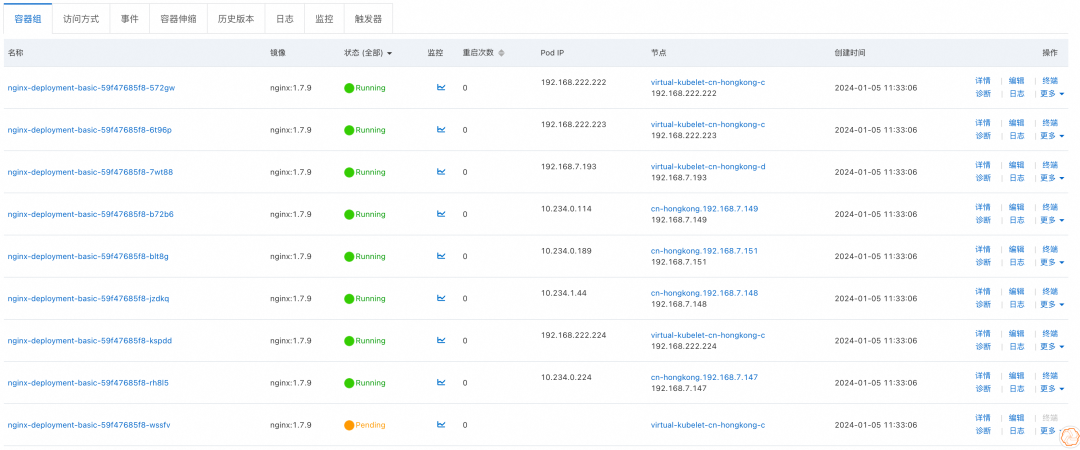
提交上述资源清单后,Pod 最终的可用区和节点分布如下,由于可用区 D 上存在三个 ECS 节点,因此最终 Pod 在可用区 D 上存在 5 个 Pod,在可用区 C 上存在 4 个 Pod。能够满足约束中最大倾斜度为 1 的要求。
![]()
What's Next
阿里云容器服务 Kubernetes 版(ACK)在标准 K8s 调度框架的基础上扩展了弹性调度功能,致力于提高应用性能和集群整体资源的利用率,保障企业业务的稳定高效运行。
在前期文章《弹性调度助力企业灵活应对业务变化,高效管理云上资源》中,我们已经探讨了如何通过阿里云容器服务 ACK 的弹性调度有效管理各类弹性资源,以帮助企业优化资源配置,实现降本增效。
在本文中,我们又深入解析了 ACK 弹性调度如何与弹性容器实例(ECI)这一关键弹性资源结合,凭借 ECI 快速弹性、秒级计费和即时释放的优势,显著提升企业业务的稳定性和效率。
在即将推出的调度系列文章中,我们将详细介绍如何在 ACK 上管理和调度 AI 任务,助力企业 AI 业务在云端快速落地。