通义千问-72B(Qwen-72B)是阿里云研发的通义千问大模型系列的720亿参数规模的大语言模型,在2023年11月正式开源。Qwen-72B的预训练数据类型多样、覆盖广泛,包括大量网络文本、专业书籍、代码等。Qwen-72B-Chat是在Qwen-72B的基础上,使用对齐机制打造的基于大语言模型的AI助手。
阿里云人工智能平台PAI是面向开发者和企业的机器学习/深度学习平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务。
本文将以Qwen-72B-Chat为例,介绍如何在PAI平台的快速开始PAI-QuickStart和交互式建模工具PAI-DSW中高效微调千问大模型。
使用PAI-DSW快速体验和轻量化微调Qwen-72B-Chat
PAI-DSW是云端机器学习开发IDE,为用户提供交互式编程环境,同时提供了丰富的计算资源。Qwen-72B-Chat的教程可以在智码实验室(https://gallery.pai-ml.com/)Notebook Gallery中检索到,参见下图:
![]()
上述Notebook可以使用阿里云PAI-DSW的实例打开,并且需要选择对应的计算资源和镜像。
快速体验Qwen-72B-Chat
首先,我们在DSW调用ModelScope快速体验Qwen-72B-Chat模型进行对话。在安装完ModelScope相关依赖后,我们可以运行如下Python代码:
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig
# Note: The default behavior now has injection attack prevention off.
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-72B-Chat", revision='master', trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-72B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-72B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-72B-Chat", device_map="cpu", trust_remote_code=True).eval()
# use auto mode, automatically select precision based on the device.
model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-72B-Chat", revision='master', device_map="auto", trust_remote_code=True).eval()
# 第一轮对话 1st dialogue turn
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
# 你好!很高兴为你提供帮助。
# 第二轮对话 2nd dialogue turn
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
print(response)
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
# 第三轮对话 3rd dialogue turn
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
print(response)
# 《奋斗创业:一个年轻人的成功之路》
为了节省显存,ModelScope也支持使用Int4/Int8量化模型:
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-72B-Chat-Int4", revision='master', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-72B-Chat-Int4",
device_map="auto",
trust_remote_code=True
).eval()
response, history = model.chat(tokenizer, "你好", history=None)
轻量化微调Qwen-72B-Chat
轻量化微调Qwen-72B-Chat最佳实践支持最主流的轻量化微调算法LoRA,并且需要使用A800(80GB)4卡及以上资源进行计算。以下,我们简述轻量化微调Qwen-72B-Chat的算法流程。首先,我们下载Qwen-72B-Chat的Checkpoint和用于LoRA微调的数据集,用户也可以按照上述格式自行准备数据集。
def aria2(url, filename, d):
!aria2c --console-log-level=error -c -x 16 -s 16 {url} -o {filename} -d {d}
qwen72b_url = f"http://pai-vision-data-inner-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/qwen72b/Qwen-72B-Chat-sharded.tar"
aria2(qwen72b_url, qwen72b_url.split("/")[-1], "/root/")
!cd /root && tar -xvf Qwen-72B-Chat-sharded.tar
!wget -c http://pai-vision-data-inner-wulanchabu.oss-cn-wulanchabu.aliyuncs.com/qwen72b/sharegpt_zh_1K.json -P /workspace/Qwen
第二步,我们可以修改示例命令的超参数,并且拉起训练任务。
! cd /workspace/Qwen && CUDA_DEVICE_MAX_CONNECTIONS=1 torchrun --nproc_per_node 8 \
--nnodes 1 \
--node_rank 0 \
--master_addr localhost \
--master_port 6001 \
finetune.py \
--model_name_or_path /root/Qwen-72B-Chat-sharded \
--data_path sharegpt_zh_1K.json \
--bf16 True \
--output_dir /root/output_qwen \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 1 \
--learning_rate 3e-4 \
--weight_decay 0.1 \
--adam_beta2 0.95 \
--warmup_ratio 0.01 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "none" \
--model_max_length 2048 \
--lazy_preprocess True \
--use_lora \
--gradient_checkpointing \
--deepspeed finetune/ds_config_zero3.json
当训练结束后,将LoRA权重合并到模型Checkpoint。
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained(
'/root/output_qwen', # path to the output directory
device_map="auto",
trust_remote_code=True
).eval()
merged_model = model.merge_and_unload()
merged_model.save_pretrained('/root/qwen72b_sft', max_shard_size="2048MB", safe_serialization=True)
!cp /root/Qwen-72B-Chat-sharded/qwen.tiktoken /root/qwen72b_sft/
!cp /root/Qwen-72B-Chat-sharded/tokenization_qwen.py /root/qwen72b_sft/
!cp /root/Qwen-72B-Chat-sharded/tokenizer_config.json /root/qwen72b_sft/
最后,我们使用轻量化微调后的Qwen-72B-Chat模型进行推理。以推理框架vllm为例,推理接口如下:
from vllm import LLM
from vllm.sampling_params import SamplingParams
qwen72b = LLM("/root/qwen72b_sft/", tensor_parallel_size=2, trust_remote_code=True, gpu_memory_utilization=0.99)
samplingparams = SamplingParams(temperature=0.0, max_tokens=512, stop=['<|im_end|>'])
prompt = """<|im_start|>system
<|im_end|>
<|im_start|>user
<|im_end|>
Hello! What is your name?<|im_end|>
<|im_start|>assistant
"""
output = qwen72b.generate(prompt, samplingparams)
print(output)
其中,tensor_parallel_size需要根据DSW示例配置中的GPU数量进行调整。
使用PAI-QuickStart全量参数微调Qwen-72B-Chat
快速开始(PAI-QuickStart)是PAI产品组件,集成了国内外AI开源社区中优质的预训练模型,支持零代码实现全量参数微调Qwen-72B-Chat。PAI-QuickStart的这一款全量参数微调组件使用PAI灵骏智算服务作为底层计算资源,使用4机32卡(每卡80GB显存)进行训练。Qwen-72B-Chat的全量参数微调基于Megatron-LM的训练流程,支持了数据并行、算子拆分、流水并行、序列并行、选择性激活重算、Zero显存优化等技术,大幅提升大模型分布式训练效率。在这一组件中,我们提前对模型Checkpoint进行了切分,适配多机多卡环境训练,用户只需要根据格式上传训练集和验证集,填写训练时候使用的超参数就可以一键拉起训练任务。
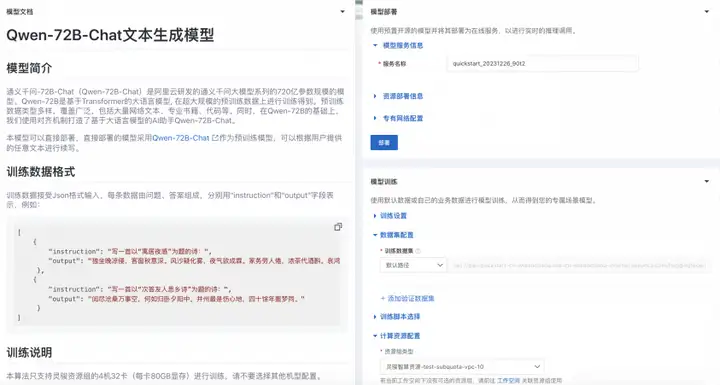
Qwen-72B-Chat的模型卡片如下图所示:
![]()
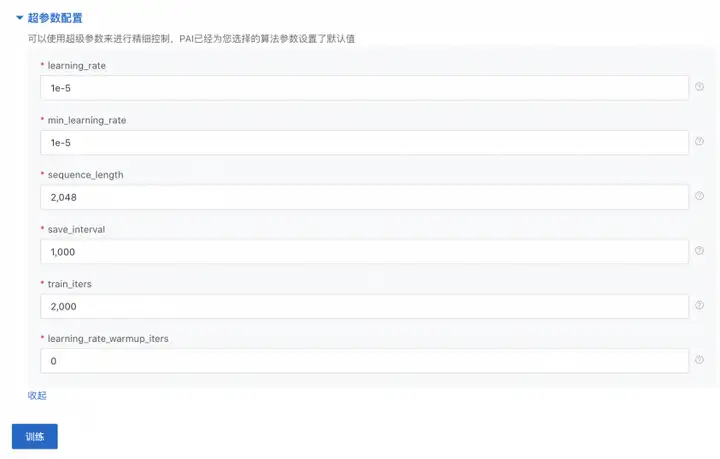
我们可以根据实际需求调整超参数,例如learning_rate、sequence_length、train_iters等,如下所示:
![]()
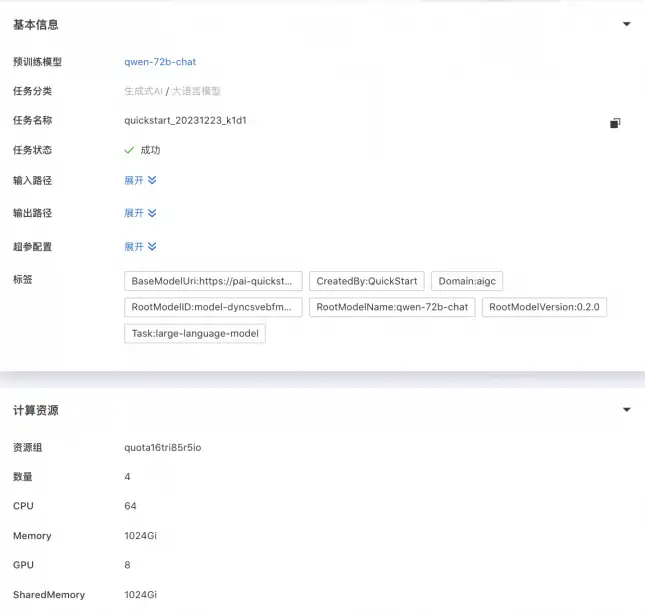
点击“训练”按钮,PAI-QuickStart自动跳转到模型训练页面,并且开始进行训练,用户可以查看训练任务状态和训练日志,如下所示:
![]()
在训练结束后,可以在输出路径的OSS Bucket中查看每次保存的Checkpoint模型切片,如下所示:
![]()
用户可以根据实际情况,选择最合适的Checkpoint进行推理和部署,具体流程参见这里,本文不再赘述。
作者:熊兮、贺弘、临在
原文链接
本文为阿里云原创内容,未经允许不得转载。