![]()
导读:自如作为一家专注于提供租房产品和服务的 O2O 互联网公司,构建了一个涵盖城市居住生活领域全链条的在线化、数据化、智能化平台,实时计算在自如一直扮演着重要的角色。到目前为止,自如每日需要处理 TB 级别的数据,本文由自如的实时计算小伙伴带来,介绍了自如基于 StreamPark 的实时计算平台深度实践。
-
实时计算遇到的挑战
-
需求解决方案之路
-
基于 StreamPark 的深度实践
-
实践经验总结和示例
-
带来的收益
-
未来规划
自如作为提供租房产品及服务的 O2O 互联网品牌,成立于 2011 年 10 月,自如已为近 50 万业主、500 万自如客提供服务,管理房源超过 100 万间。 自如通过打造涵盖 To C 和 To B 的品质居住产品、逐步实现城市居住生活领域全链条的线上化、数据化、智能化的平台能力。自如 APP 装机量累计达 1.4 亿次,日均线上服务调用达 4 亿次,拥有智能化房源万余间。自如现已在 PC、APP、微信全渠道实现租房、服务、社区的 O2O 闭环,省去传统租房模式所有中间冗余环节,通过 O2O 模式重构居住市场格局,并建立了中国最大的 O2O 青年居住社区。
在拥有庞大用户群体情况下,自如为了给用户提供更加优质的产品体验,实现企业的数字化转型,从 2021 年开始大力发展实时计算,Flink 在自如的实时计算中一直扮演着重要的角色。到目前为止,自如每日需要处理 TB 级别的数据,总共拥有 500+ 个实时作业,并支撑每日超过 1000 万次的数据调用请求。
1. 实时计算遇到的挑战
在自如,实时计算大概分为 2 个应用场景:
在实时计算实践过程中遇到了一些挑战,大致如下:
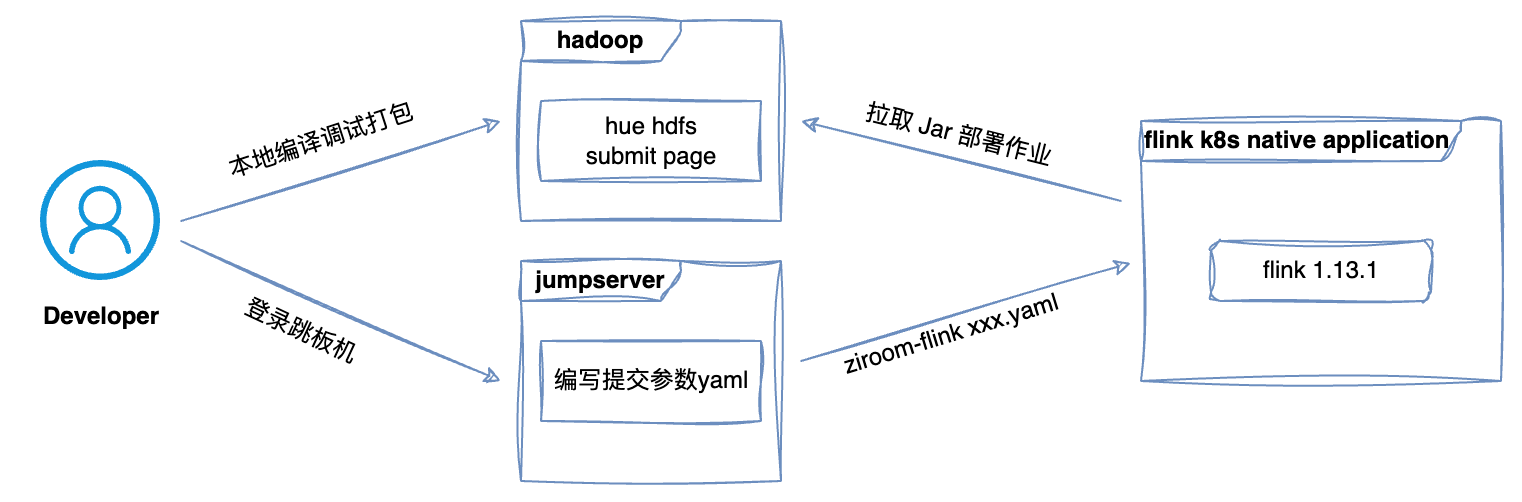
1.1 作业上线效率低
在自如实时作业的开发上线流程是:数据仓库开发人员将 Flink SQL 代码嵌入到程序中,在本地进行代码调试,然后编译成 FatJar,最后再将作业以工单和 JAR 包形式提交给运维,运维负责作业上线的小伙伴再通过命令行的方式将作业部署到线上 Kubernetes session 环境。可以看到这一过程涉及到诸多环节,每一步都是需要人为介入,效率极其低下,而且非常容易出错,影响工作效率和稳定性。因此,我们亟需构建一套高效、自动化的实时计算平台,以满足日益增涨的实时计算需求。
![]()
1.2 作业归属信息不明确
由于实时计算平台没有对作业进行统一管理,业务代码都是由 GitLab 管理,虽然解决了部分问题,但是我们发现仓库代码与线上部署的 Flink 作业管理之间仍然存在缺陷:缺乏明确归属、缺少分组和有效权限控制,导致作业管理混乱且责任链路难以追溯。为确保代码和上线作业的一致和可控性,亟需建立严格且清晰的作业管理体系,其中包括实行严格的代码版本控制、明确作业归属和负责人、以及建立有效的权限控制。
1.3 作业维护困难
在自如有多个不同版本的 Flink 作业在运行,由于 Apache Flink 的 API 在大版本升级中经常会发生变动,且不保证向下兼容性,这直接导致流作业项目代码的升级成本变得很高。因此如何管理这些不同版本的作业成了头痛的问题。
由于没有统一的作业平台,这些作业在提交时,只能通过执行脚本的形式进行提交。不同的作业有不同重要程度和数据量级,作业所需资源和运行参数也都各不相同,都需要相应的修改。我们可以通过修改提交脚本或直接在代码中设置参数来进行修改,但这使得配置信息的获取变得困难,尤其是当作业出现重启或失败时,FlinkUI 无法打开,配置信息变成一个黑盒。因此,亟需建立一个更加高效、支持配置实时计算平台。
1.4 作业开发调试困难
在以往的开发流程中,我们通常在本地的 IDEA 环境中,通过将 SQL 代码嵌入程序代码的方式进行作业的开发和调试,以验证程序的正确性。然而,这种方式存在如下弊端:
1. 多数据源调试困难。通常,一个需求可能涉及多个不同的数据源。为了在本地环境调试,开发人员需要申请开通数据访问需要的白名单,这一过程既耗时又繁琐。
2. SQL 代码难以阅读和修改。由于 SQL 代码是嵌入在程序代码中的,这使得代码难以阅读,修改起来也相当不便。更为困难的是,当需要通过 SQL 片段的方式进行调试时,由于缺少 SQL 版本管理和语法校验的支持,开发人员很难通过客户端日志定位到具体的 SQL 行号,从而找出执行失败的原因。
因此,急需提高开发、调试的效率。
2. 需求解决方案
在平台构建的初期阶段,2022 年初开始我们就全面调查了行业内的几乎所有相关项目,涵盖了商业付费版和开源版。经过调查和对比发现,这些项目都或多或少地存在一定的局限性,可用性和稳定性也无法有效地保障。
综合下来 StreamPark 在我们的评估中表现最优,是唯一一个没有硬伤且扩展性很强的项目:同时支持 SQL 和 JAR 作业,在 Flink 作业的部署模式上也是最为完善和稳定的,特有的架构设计使得不仅不会锁定 Flink 版本,还支持便捷的版本切换和并行处理,有效解决了作业依赖隔离和冲突的问题。我们重点关注的作业管理 & 运维能力也非常完善,包括监控、告警、SQL 校验、SQL 版本对比、CI 等功能,StreamPark 对 Flink on K8s 的支持也是我们调研的所有开源项目中最为完善的。但 StreamPark 的 K8s 模式提交需在本地构建镜像导致存储资源消耗目前在最新的 2.2 版本中社区已经重构了这部分实现。
在深入分析了众多开源项目的优缺点后,我们认为可以先去参与了解那些拥有优秀的架构、充满发展潜力,并且核心团队积极努力的项目,投身其中。基于这样的认识,我们做出了如下决策:
- 在作业部署模式上,我们决定采用 On Kubernetes 的模式。实时作业的资源消耗具有动态性,对 Kubernetes 提供的弹性扩缩容有强烈的需求,这有助于我们更好地应对数据产出的波动,确保作业的稳定运行。
- 在开源组件的选择上,我们经过各项指标综合对比评估,最终选择了当时的 StreamX。后续和社区保持密切的沟通,在此过程中深刻感受到创始人认真负责的态度和社区的团结友善的氛围,也见证了项目 2022 年 09 月加入 Apache 孵化器的过程,这让我们对该项目的未来充满希望。
- 在 StreamPark 基础上,我们要推动与公司已有生态的整合,以便更好地满足我们的业务需求。
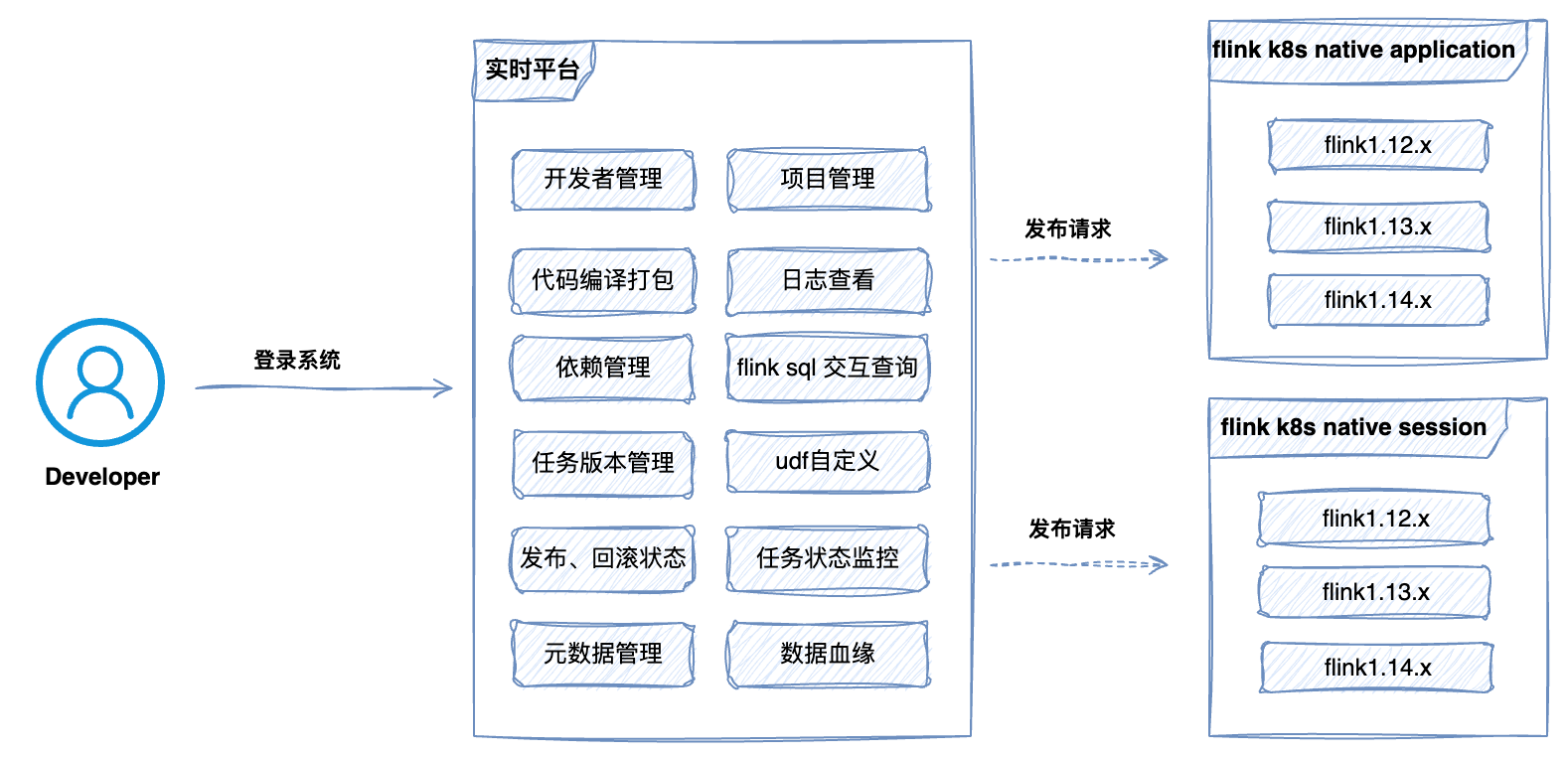
3. 基于 StreamPark 的深度实践
基于上述决策,我们启动了以 “痛点需求” 为导向的实时计算平台演进工作,基于StremaPark 打造一个稳定、高效、易维护的实时计算平台。从 2022 年初开始我们便参与社区的建设,同时我们内部平台建设也正式提上日程。
首先我们在 StreamPark 的基础上进一步完善相关的功能:
![]()
3.1 LDAP 登录支持
在 StreamPark 的基础上,我们进一步完善了相关的功能,其中包括对 LDAP 的支持,以便我们未来可以完全开放实时能力,让公司的四个业务线所属的分析师能够使用该平台,预计届时人数将达到 170 人左右。随着人数的增加,账号的管理变得越发重要,特别是在人员变动时,账号的注销和申请将成为一项频繁且耗时的操作。所以,接入 LDAP 变得尤为重要。因此我们及时和社区沟通,并且发起讨论,最终我们贡献了该 Feature。现在在 StreamPark 开启 LDAP 已经变得非常简单,只需要简单两步即可:
- step1: 填写对应的 LDAP 配置:
编辑 application.yml 文件,设置 LDAP 基础信息,如下:
ldap:
# Is ldap enabled?
enable: false
## AD server IP, default port 389
urls: ldap://99.99.99.99:389
## Login Account
base-dn: dc=streampark,dc=com
username: cn=Manager,dc=streampark,dc=com
password: streampark
user:
identity-attribute: uid
email-attribute: mail
- step2: LDAP 登陆
登录界面点击 LDAP 方式登录,然后输入对应的账号密码,点击登录即可
![]()
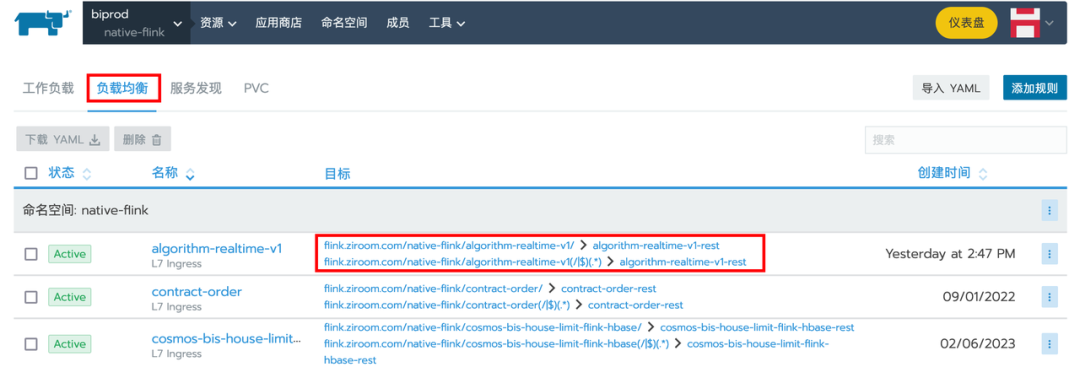
3.2 提交作业自动生成 Ingress
由于公司的网络安全政策,运维人员在 Kubernetes 的宿主机上仅开放了 80 端口,这导致我们无法直接通过 “域名+随机端口” 的方式访问在 Kubernetes 上的作业 WebUI。为了解决这个问题,我们需要使用Ingress在访问路径上增加一层代理,从而启到访问路由的效果。在 StreamPark 2.0 版本我们贡献了 Ingress 相关的功能。采用了策略模式的实现方式,在初始构建阶段,获取 Kubernetes 的元数据信息来识别其版本,针对不同版本来进行相应的对象构建,确保了在各种 Kubernetes 环境中都能够顺利地使用 Ingress 功能。
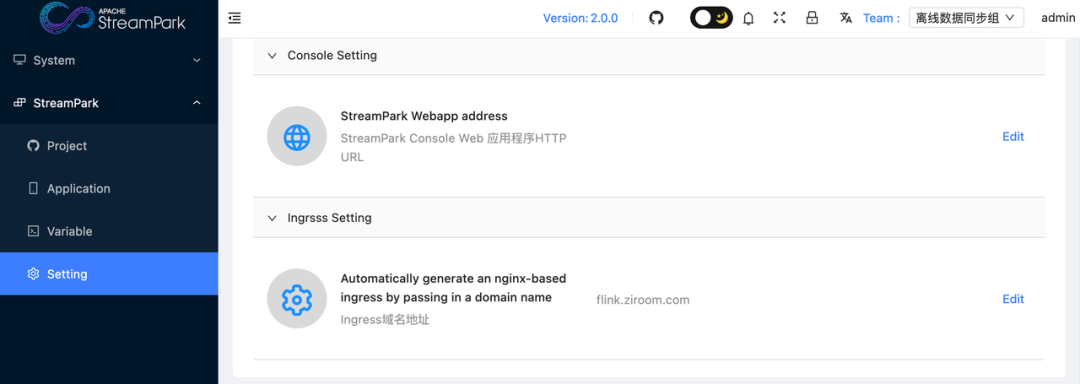
具体的配置步骤如下:
- step1: 点击进入 Setting-> 选择 Ingress Setting,填写域名
![]()
- step2: 提交作业
点击进入 K8s 管理平台,可以观察到在提交 Flink 作业的同时会对应提交一个名称相同的 Ingress
![]()
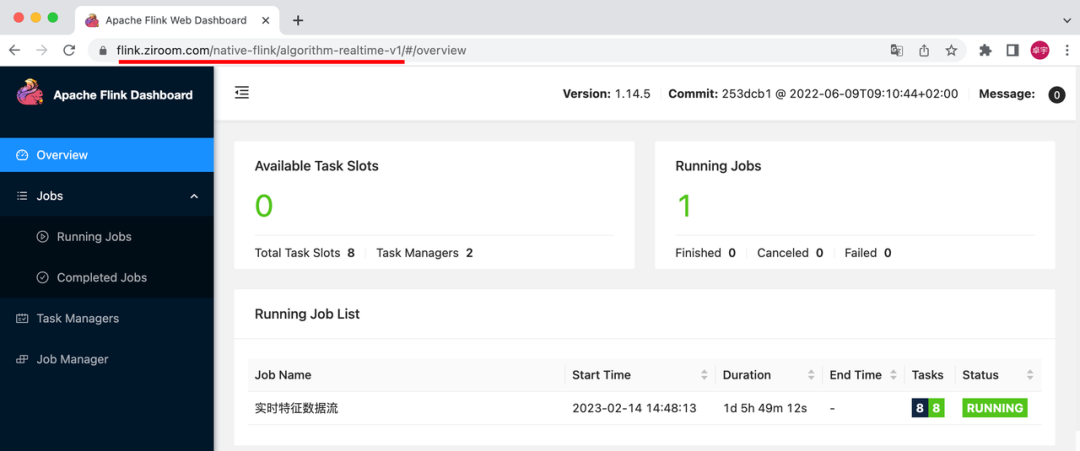
- step3: 点击进入 Flink 的 WebUI
可以观察到生成的地址将由三部分组成:域名 + 作业提交的命名空间 + 作业名称
![]()
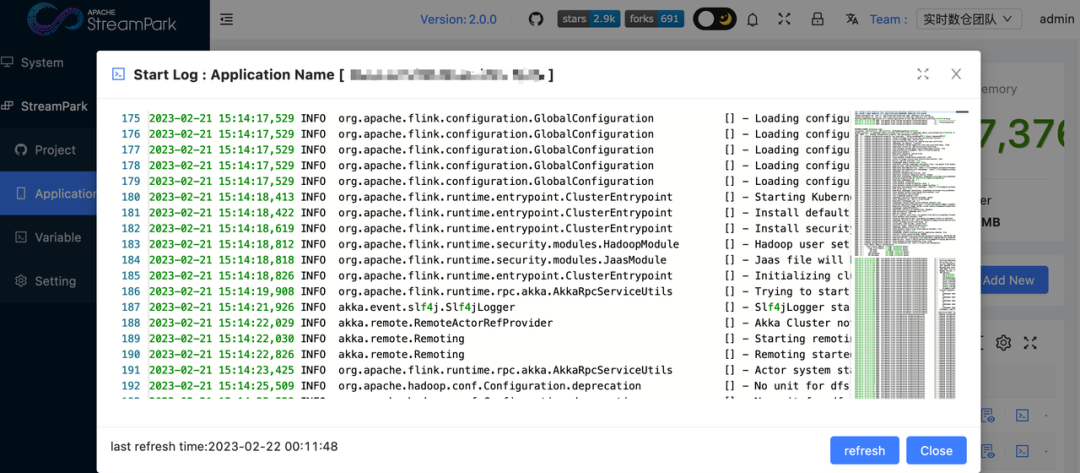
3.3 支持查看作业部署日志
在持续部署作业的过程中,我们逐渐意识到,没有日志就无法进行有效的运维操作,日志的留存归档和查看成为了我们在后期排查问题时非常重要的一环。因此在 StreamPark 2.0 版本我们贡献了 On Kubernetes 模式下启动日志存档、页面查看的能力,现在点击作业列表里的日志查看按钮,可以很方便的查看作业的实时日志。
![]()
3.4 集成 Grafana 监控图表链接
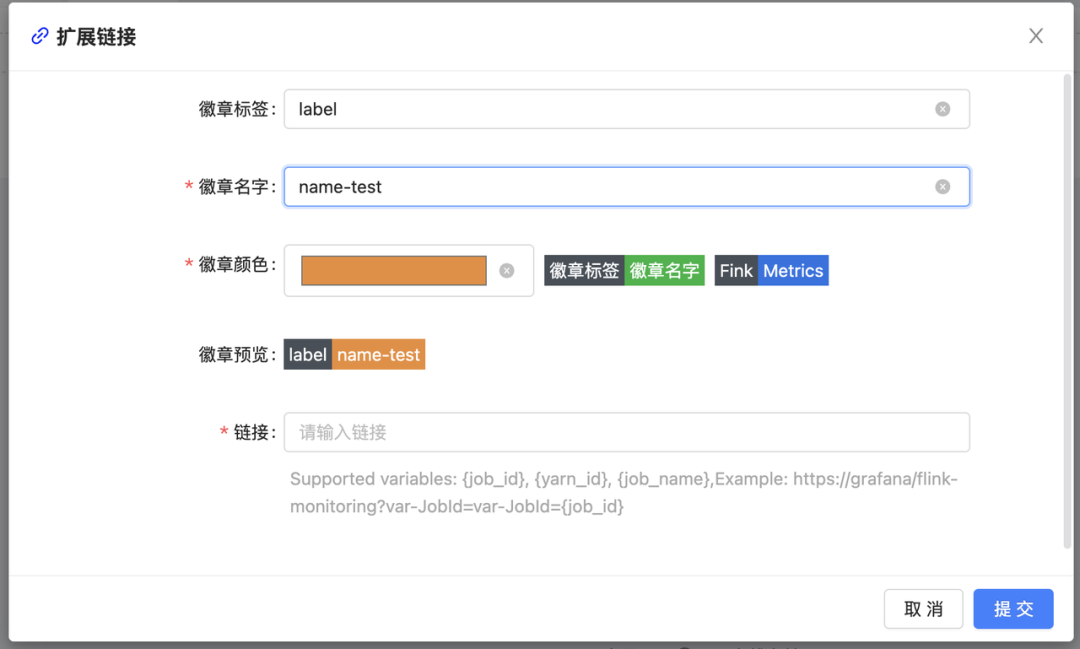
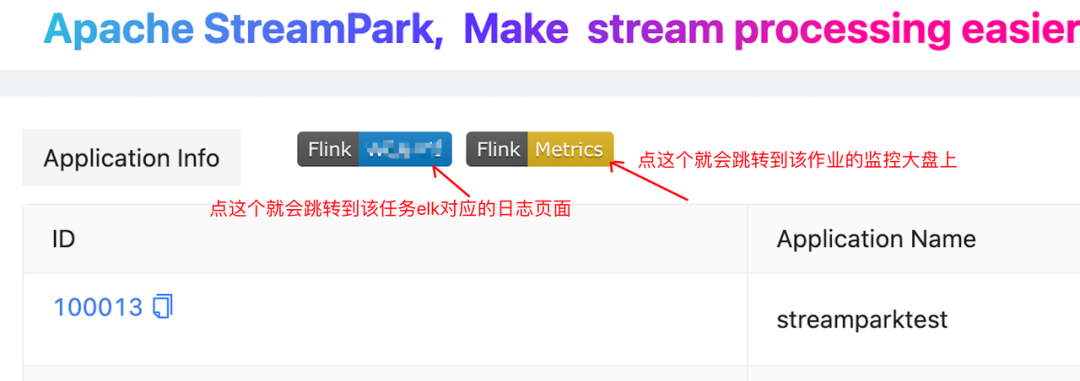
在实际的使用过程中,我们发现随着作业数量的增加,使用人数的上升,以及涉及的部门的增多,面临故障自排查困难的问题。我们团队的运维能力实际上是非常有限的。由于专业领域的不同,当我们告诉用户去 Grafana、ELK 上查看图表和日志时,用户通常会感到无从下手,不知道如何去找到与自己作业相关的信息。
为了解决这个问题,我们在社区提出一个需求:希望每个作业都能够通过超链接直接跳转到对应的监控图表和日志归档页面,这样使用者就可以直接查看与自己作业相关的监控信息和日志。无需在复杂的系统界面中进行繁琐的搜索,从而提高故障排查的效率。
我们在社区展开了讨论、并很快得到响应、大家都认为这是一个普遍存在的需求、因此很快有开发小伙伴提交了设计和相关PR,该问题也很快被解决,现在在 StreamPark 中要开启该功能已经变得非常简单:
![]()
![]()
![]()
3.5 集成 Flink sql security 权限控制
在我们的系统中,血缘关系管理采用 Apache Atlas,权限管理基于开源项目 Flink-sql-security,这是一个FlinkSQL数据脱敏和行级权限解决方案的开源项目,支持面向用户级别的数据脱敏和行级数据访问控制,即特定用户只能访问到脱敏后的数据或授权过的行。
这种设计是为了处理一些复杂的继承逻辑。例如,当将加密字段 age 的A 表与 B 表进行 join 操作,得到 C 表时,C 表中的 age 字段应继承 A 表的加密逻辑,以确保数据的加密状态不会因数据处理过程中的转换而失效。这样,我们可以更好地保护数据的安全性,确保数据在整个处理过程中都符合安全标准。
在权限控制方面,我们基于 Flink-sql-security 做了二次开发,实现了 flink-sql-security-streampark 插件。基本的实现思路如下:
- 在检查提交时系统会解析传入的 SQL,获取 InputTable 和 OutputTable 两个数据集。
- 系统通过对远端权限服务的查询,获取到用户所绑定的 RBAC(基于角色的访问控制)权限。
- 根据获取到的 RBAC 权限,系统会得到对应的表的加密规则。
- 系统将通过重写 SQL,将原本 SQL 查询字段包上一层预设的加密算法,进而实现逻辑的重组。
- 最后,系统会根据重组后的逻辑,进行相应的提交。
通过这样的整合和插件的开发,我们实现了对用户查询请求的权限控制,从而确保了数据的安全性。
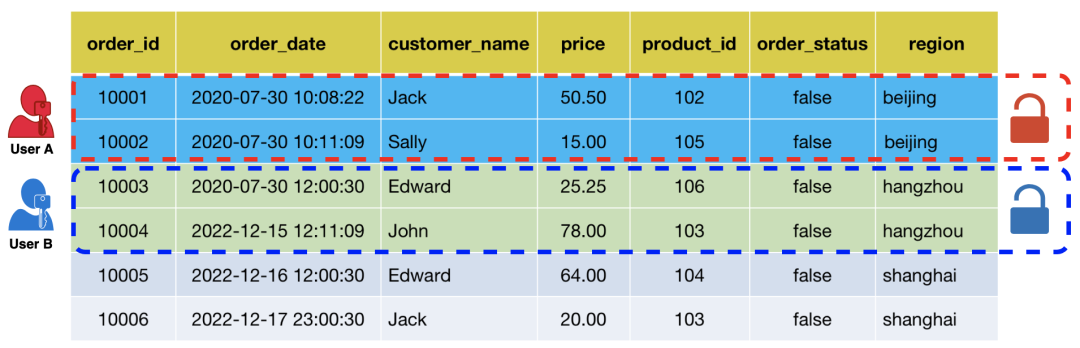
01. 行级权限条件:
![]()
![]()
输入 SQL
SELECT * FROM orders;执行SQL
用户 A 的真实执行 SQL:
SELECT * FROM orders WHERE region = 'beijing';
用户 B 的真实执行 SQL:
SELECT * FROM orders WHERE region = 'hangzhou';
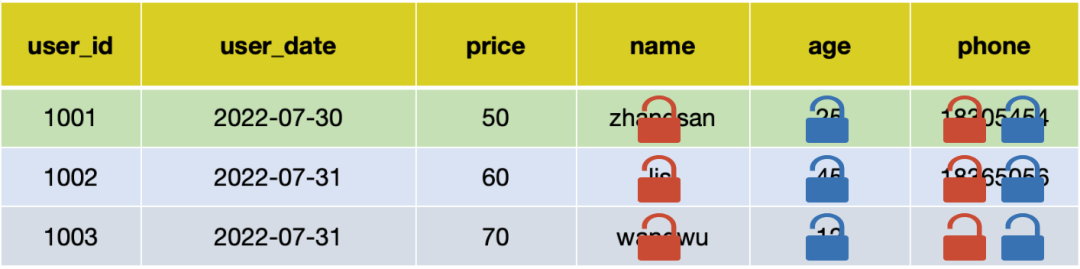
02. 字段脱敏条件:
![]()
![]()
SELECT name, age, price, phone FROM user;
执行 SQL:
用户 A 的真实执行 SQL:
SELECT Encryption_function(name), age, price, Sensitive_field_functions(phone) FROM user;
用户 B 的真实执行 SQL:
SELECT name, Encryption_function(age), price, Sensitive_field_functions(phone) FROM user;
3.6 基于 StreamPark 的数据同步平台
随着 StreamPark 的技术解决方案在公司的成功落地,我们实现了对 Flink 作业的深度支持,从而为数据处理带来质的飞跃。这促使我们对过往的数据同步逻辑进行彻底的革新,目标是通过技术的优化和整合,最大限度地降低运维成本。因此,我们逐步替换了历史上的 Sqoop 作业、Canal 作业和 Hive JDBC Handler 作业,转而采用 Flink CDC 作业、Flink 流和批作业。在这个过程中,我们也不断优化和强化 StreamPark 的接口能力,新增了状态回调机制,同时实现了与 DolphinScheduler 调度系统的完美集成,进一步提升了我们的数据处理能力。
外部系统集成 StreamPark 步骤如下,只需要简单几个步骤即可:
- 首先创建 API 访问的 Token:
![]()
- 查看 Application 外部调用链接:
![]()
curl -X POST '/flink/app/start' \
-H 'Authorization: $token' \
-H 'Content-Type: application/x-www-form-urlencoded; charset=UTF-8' \
--data-urlencode 'savePoint=' \
--data-urlencode 'allowNonRestored=false' \
--data-urlencode 'savePointed=false' \
--data-urlencode 'id=100501'
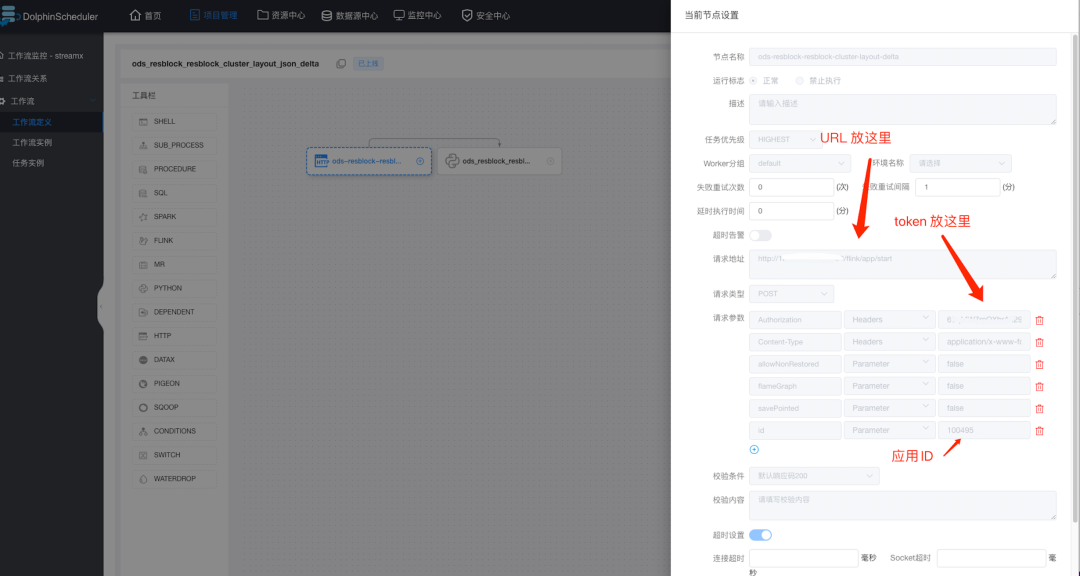
- DolphinScheduler 中配置 Http 调度:
![]()
4. 实践经验总结
在深度使用 StreamPark 实践过程中,我们总结了一些常见问题和实践过程中所探索出解决方案,我们把这些汇总成示例,仅供大家参考。
4.1 构建 Base 镜像
要使用 StreamPark 在 Kubernetes 上部署一个 Flink 作业,首先要准备一个基于 Flink 构建的 Base 镜像。然后,在 Kubernetes 平台上,会使用用户所提供的镜像来启动 Flink 作业。如果是沿用官方所提供的 “裸镜像”,在实际开发中是远远不够的,用户开发的业务逻辑往往会涉及到上下游多个数据源,这就需要相关数据源的 Connector,以及 Hadoop 等关联依赖。因此需要将这部分依赖项打入镜像中,下面我将介绍具体操作步骤。
- step1: 首先创建一个文件夹,内部包含两个文件夹和一个 Dockerfile 文件
![]()
conf 文件夹:存放 HDFS 配置文件,主要用于配置 Flink 的 Checkpoint 写入和FlinkSQL 中使用 Hive 的元数据
![]()
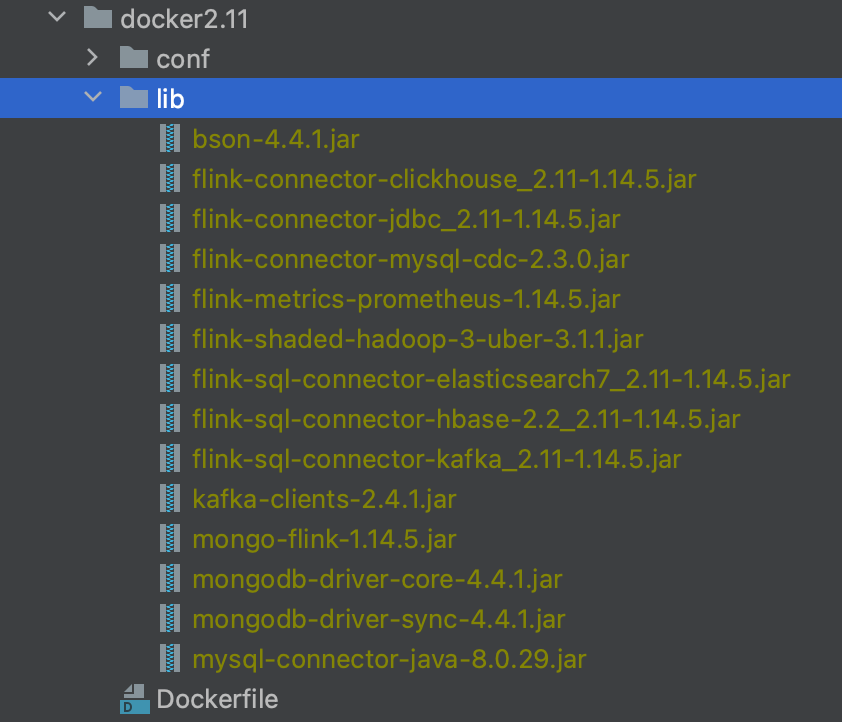
lib 文件夹:存放涉及到的 Jar 依赖包,如下:
![]()
Dockerfile 文件用于定义镜像的构建
FROM apache/flink:1.14.5-scala_2.11-java8
ENV TIME_ZONE=Asia/Shanghai
COPY ./conf /opt/hadoop/conf
COPY lib $FLINK_HOME/lib/
- step2: 镜像构建命令使用多架构构建模式,如下:
docker buildx build --push --platform linux/amd64 -t ${私有镜像仓库地址}
4.2 Base 镜像集成 Arthas 示例
随着公司内新发布上线的运行作业越来越多,团队内常常会遇到作业在长时间运行后性能下降的这种问题,如 Kafka 消费能力减弱、内存使用增加和 GC 时间延长等,我们是比较推荐使用Arthas,一款阿里巴巴开源的 Java 诊断工具。可以通过全局视角实时查看java应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,完成查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,可以大大提升我们线上问题排查效率。
![]()
![]()
因此做了 base 镜像集成 arthas,来方便运行时问题的排查。
FROM apache/flink:1.14.5-scala_2.11-java8
ENV TIME_ZONE=Asia/Shanghai
COPY ./conf /opt/hadoop/conf
COPY lib $FLINK_HOME/lib/
RUN apt-get update --fix-missing && apt-get install -y fontconfig --fix-missing && \
apt-get install -y openjdk-8-jdk && \
apt-get install -y ant && \
apt-get clean;
RUN apt-get install sudo -y
# Fix certificate issues
RUN apt-get update && \
apt-get install ca-certificates-java && \
apt-get clean && \
update-ca-certificates -f;
# Setup JAVA_HOME -- useful for docker commandline
ENV JAVA_HOME /usr/lib/jvm/java-8-openjdk-amd64/
RUN export JAVA_HOME
RUN apt-get install -y unzip
RUN curl -Lo arthas-packaging-latest-bin.zip 'https://arthas.aliyun.com/download/latest_version?mirror=aliyun'
RUN unzip -d arthas-latest-bin arthas-packaging-latest-bin.zip
4.3 镜像中依赖冲突的解决方式
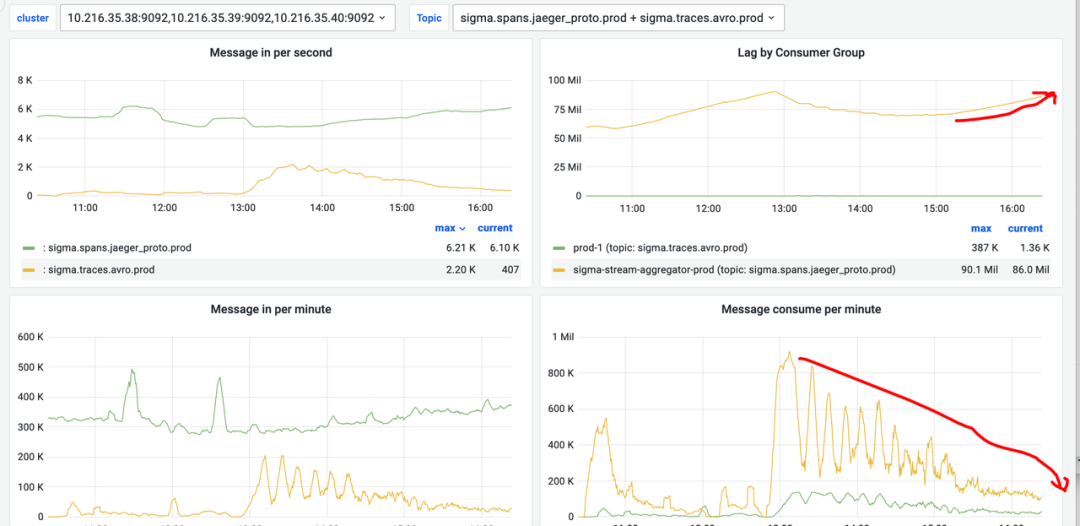
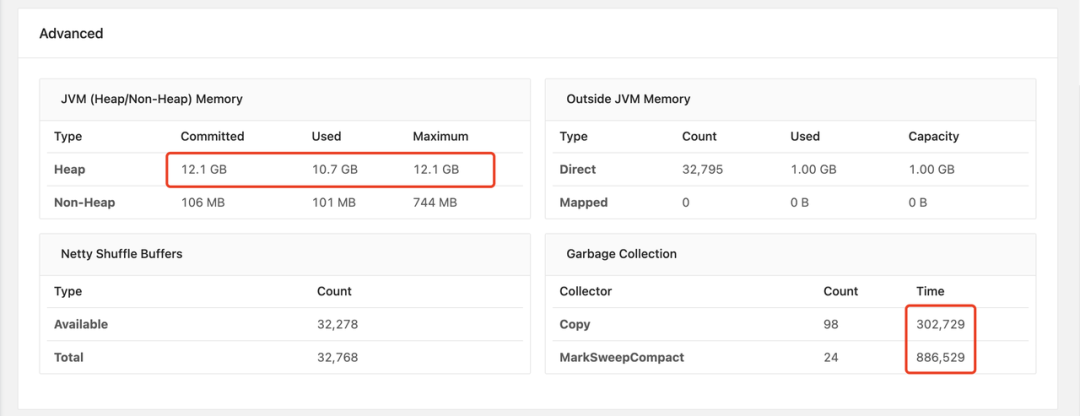
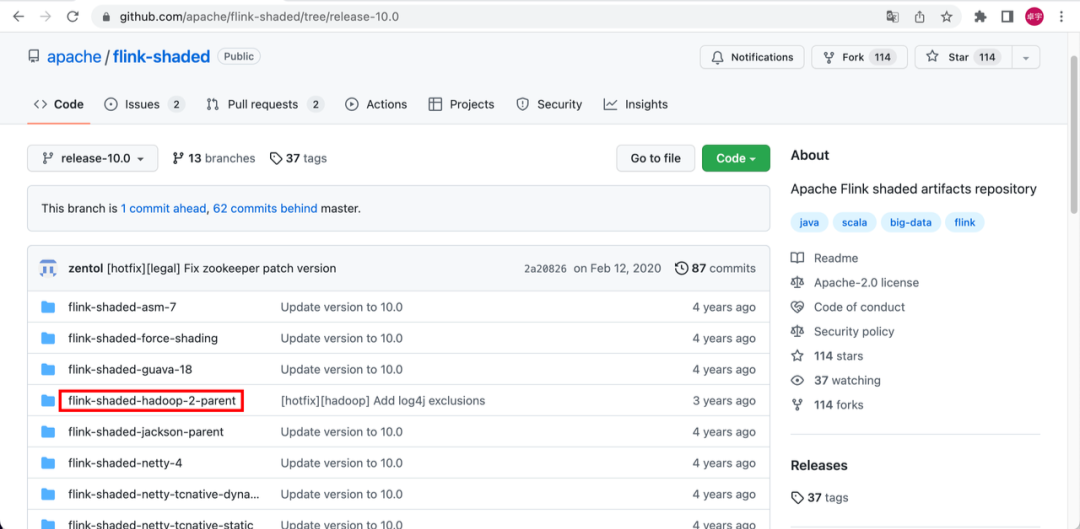
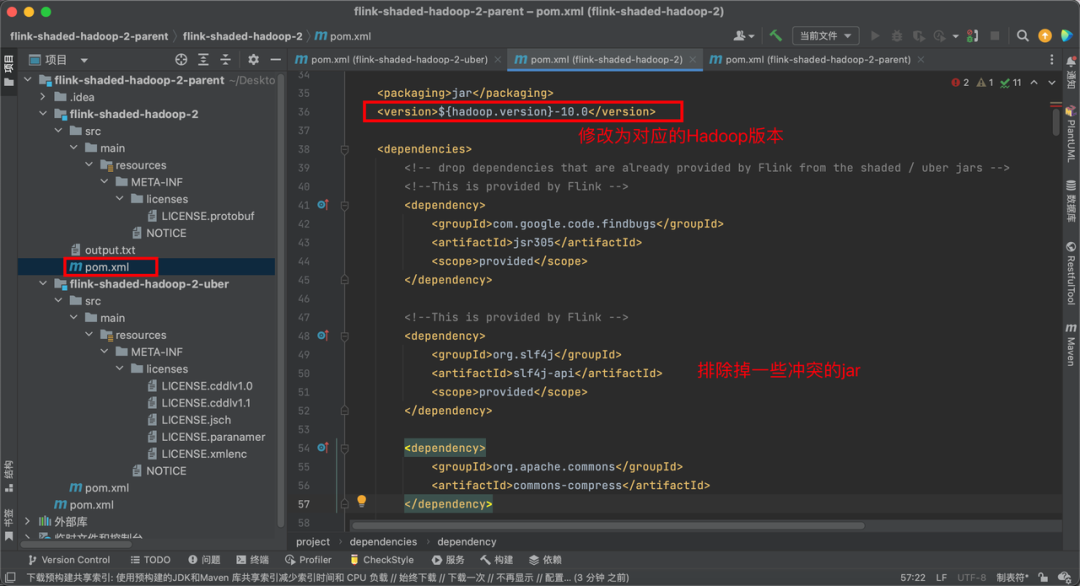
在使用 StreamPark 的过程中,我们常遇到基于 Base 镜像运行的 Flink 作业中出现 NoClassDefFoundError、ClassNotFoundException 和 NoSuchMethodError 这三种依赖冲突异常。排查思路就是,找到报错中所示的冲突类,所在的包路径。例如这个报错的类在 org.apache.orc:orc-core, 就到相应模块的目录下跑 mvn dependency::tree 然后搜 orc-core,看一下是谁带进来的依赖,用 <exclusion> 去掉就可以了。下面我通过一个 base 镜像中的 flink-shaded-hadoop-3-uber JAR 包引起的依赖冲突示例,来详细介绍通过自定义打包的方法来解决依赖冲突。
- step1: Clone flink-shaded 项目到本地👇
git clone https://github.com/apache/flink-shaded.git
![]()
step2: 项目加载到 IDEA 中
![]()
step3: 针对冲突的部分进行排除后再进行打包。
4.4 集中作业配置示例
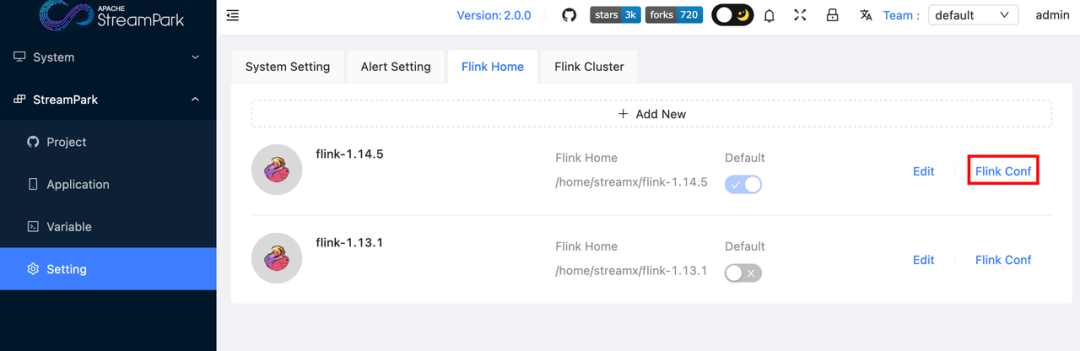
使用 StreamPark 有个非常大的便利就是可以进行配置的集中管理,可以将所有的配置项,配置到平台所绑定的 Flink 目录下的 conf 文件中。
cd /flink-1.14.5/conf
vim flink-conf.yaml
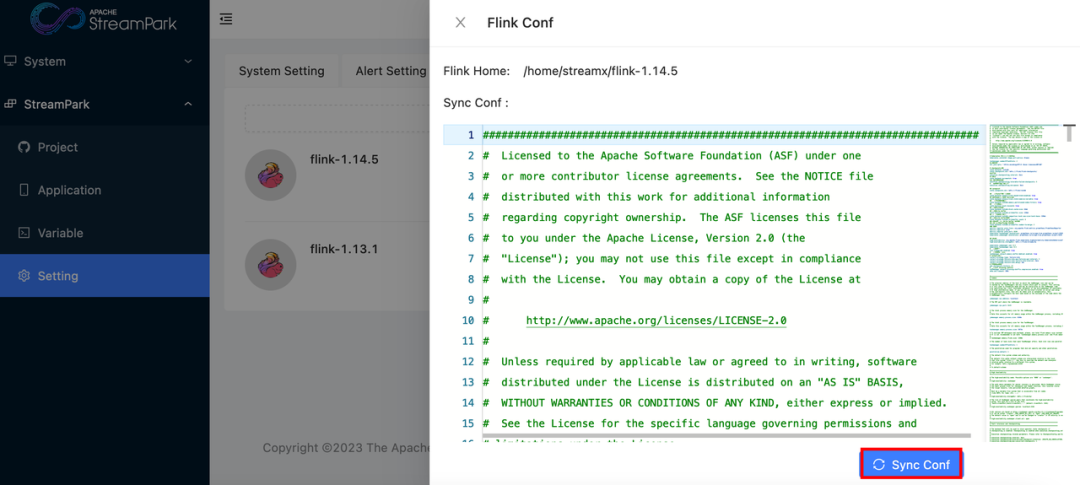
配置完成后保存。然后进入到平台的 Setting 下,点击 Flink Conf 这个图标。
![]()
点击 Sync Conf 全局配置文件就会进行相应的同步,新提交的作业就会按照新的配置进行提交。
![]()
4.5 StreamPark 配置 DNS 解析
在使用 StreamPark 平台提交 FlinkSQL 的过程中,一个正确合理的 DNS 解析配置非常重要。主要涉及到以下几点:
- Flink 作业的 Checkpoint 写入 HDFS 需要通过 ResourceManager 获取的一个 HDFS 节点进行快照写入,如果企业中同时有发生Hadoop集群的扩容,并且这些这些新扩容出来的节点,没有被DNS解析服务所覆盖,就直接会导致Checkpoint失败,从而影响线上稳定。
- Flink 作业的通常需要配置公司内部不同数据源的连接串。如果配置数据库的真实 IP 地址,往往这个地址会随着迁库时常发生变化,而导致线上作业异常退出。因此在实际生产中连接串往往是由域名加属性参数构成,请求时由DNS服务将其解析为真实 IP 地址,在进行访问。
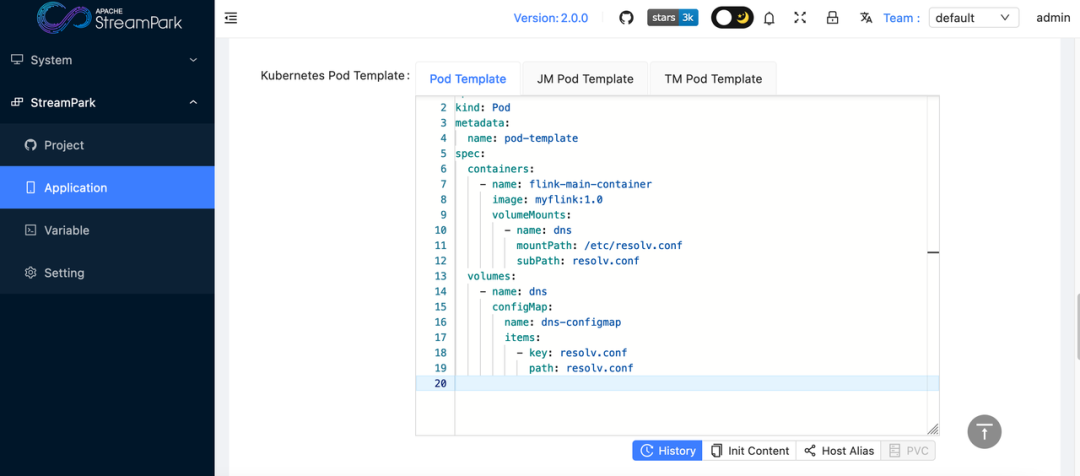
起初,我们是通过 Pod Template 来维护 DNS 配置的。
apiVersion: v1
kind: Pod
metadata:
name: pod-template
spec:
hostAliases:
- ip: 10.216.xxx.79
hostnames:
- handoop1
- hostnames:
- handoop2
ip: 10.16.xx.48
- hostnames:
- handoop3
ip: 10.16.xx.49
- hostnames:
- handoop4
ip: 10.16.xx.50
.......
虽然该方法理论上可行,但在实际操作过程中,我们遭遇到了一系列问题。当进行 HDFS 扩容时,我们发现 Flink 的 Checkpoint 功能出现了写入失败的情况,而数据库迁移也出现了链接失败的问题,这导致我们的线上服务突然宕机。经过深入的排查,我们发现这些问题的根源在于 DNS 解析。
过去,我们曾使用 hostAliases 来维护域名和 IP 地址之间的映射关系。但这种方法在实际操作中代价较大,因为每当更新 hostAliases 时,我们都需要停掉所有的 Flink 作业,这无疑增加了我们的运维成本。为了寻求一种更为灵活和可靠的方法来管理 DNS 解析配置,保障 Flink 作业的正常运行,我们决定搭建 dnsmasq 来进行双向的 DNS 解析。
在完成 dnsmasq 的配置和安装后,我们首先需要对 Flink 镜像中 /etc 目录下的resolv.conf 配置文件进行覆盖。然而,由于 resolv.conf 是一个只读文件,如果我们想要覆盖它,就需要使用挂载的方式。因此,我们首先将 resolv.conf 配置成 ConfigMap,以便在覆盖过程中使用。这样,我们就能够更为灵活和可靠地管理DNS 解析配置,从而确保 Flink 作业的稳定运行。
apiVersion: v1
data:
resolv.conf: "nameserver 10.216.138.226" //DNS服务
kind: ConfigMap
metadata:
creationTimestamp: "2022-07-13T10:16:18Z"
managedFields:
name: dns-configmap
namespace: native-flink
在通过 Pod Template 进行挂载。
![]()
这样大数据平台相关的 DNS 就可以维护在 dnsmasq 上,而 Flink 作业所运行的宿主机就可以按照 DNS 解析流程。
- 先检查自己本地的 hosts 文件,是否存在对应关系,读取到记录进行解析,没有则进行下一步
- 操作系统会去查看本地的 DNS 缓存,没有则进行下一步
- 操作系统会去我们在网络配置中定义的 DNS 服务器地址上进行查找
以此来实现动态的实现 DNS 的变更识别。
4.6 多实例部署实践
在实际生产环境中,我们常常需要操作多个集群,包括一套用于测试的集群和一套线上正式集群。任务首先在测试集群中进行结果验证和性能压测,确保无误后再发布到线上正式集群。
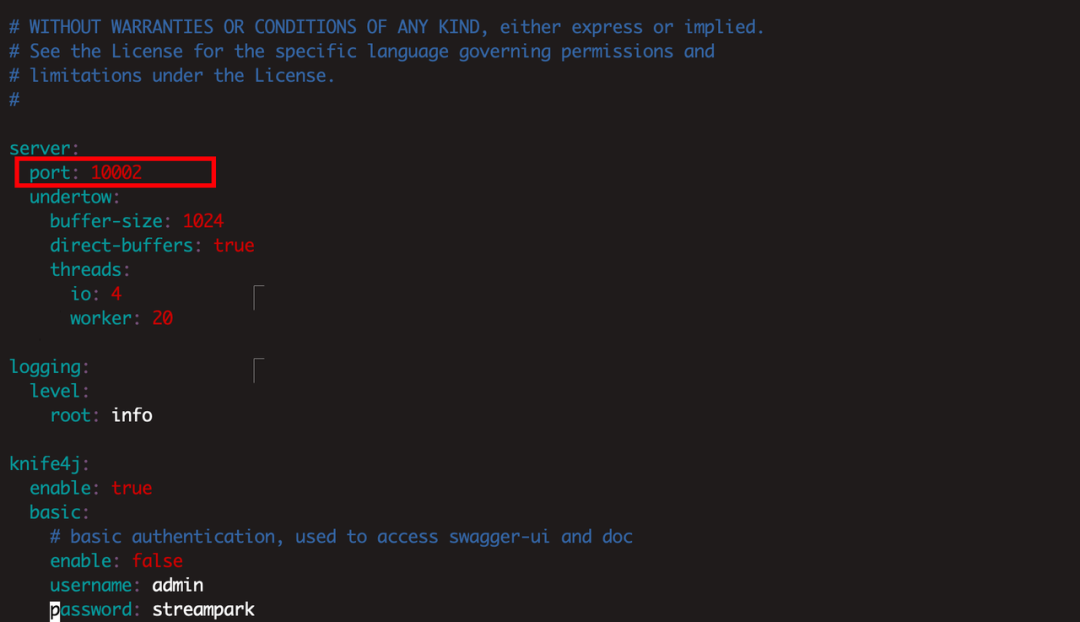
有效地切断了 Flink on K8s 加载 HDFS 配置的默认逻辑。这样的操作确保了 A StreamPark 仅连接至 A Hadoop 环境,而 B StreamPark 则对应连接至 B Hadoop 环境,从而达到了将测试和生产环境进行完整隔离的目的。
具体来说,在这一操作指令生效后,我们就可以确保在 10002 端口提交的 Flink 作业所连接的 Hadoop 环境为 B Hadoop 环境。这样一来,B Hadoop 环境与过去在 10000 端口提交的 Flink 作业所使用的Hadoop环境就成功实现了隔离,有效防止了不同环境之间的相互干扰,确保了系统的稳定性和可靠性。
下述内容为 Flink 加载 Hadoop 环境逻辑代码分析:
// 寻找hadoop配置文件的流程
//1、先去寻找是否添加了参数:kubernetes.hadoop.conf.config-map.name
@Override
public Optional<String> getExistingHadoopConfigurationConfigMap() {
final String existingHadoopConfigMap =
flinkConfig.getString(KubernetesConfigOptions.HADOOP_CONF_CONFIG_MAP);
if (StringUtils.isBlank(existingHadoopConfigMap)) {
return Optional.empty();
} else {
return Optional.of(existingHadoopConfigMap.trim());
}
}
@Override
public Optional<String> getLocalHadoopConfigurationDirectory() {
// 2、如果没有 1 中指定的参数,查找提交 native 命令的本地环境是否有环境变量:HADOOP_CONF_DIR
final String hadoopConfDirEnv = System.getenv(Constants.ENV_HADOOP_CONF_DIR);
if (StringUtils.isNotBlank(hadoopConfDirEnv)) {
return Optional.of(hadoopConfDirEnv);
}
// 3、如果没有 2 中环境变量,再继续看否有环境变量:HADOOP_HOME
final String hadoopHomeEnv = System.getenv(Constants.ENV_HADOOP_HOME);
if (StringUtils.isNotBlank(hadoopHomeEnv)) {
// Hadoop 2.2+
final File hadoop2ConfDir = new File(hadoopHomeEnv, "/etc/hadoop");
if (hadoop2ConfDir.exists()) {
return Optional.of(hadoop2ConfDir.getAbsolutePath());
}
// Hadoop 1.x
final File hadoop1ConfDir = new File(hadoopHomeEnv, "/conf");
if (hadoop1ConfDir.exists()) {
return Optional.of(hadoop1ConfDir.getAbsolutePath());
}
}
return Optional.empty();
}
final List<File> hadoopConfigurationFileItems = getHadoopConfigurationFileItems(localHadoopConfigurationDirectory.get());
// 如果没有找到 1、2、3 说明没有 hadoop 环境
if (hadoopConfigurationFileItems.isEmpty()) {
LOG.warn(
"Found 0 files in directory {}, skip to mount the Hadoop Configuration ConfigMap.",
localHadoopConfigurationDirectory.get());
return flinkPod;
}
// 如果 2 或者 3 存在,会在路径下查找 core-site.xml 和 hdfs-site.xml 文件
private List<File> getHadoopConfigurationFileItems(String localHadoopConfigurationDirectory) {
final List<String> expectedFileNames = new ArrayList<>();
expectedFileNames.add("core-site.xml");
expectedFileNames.add("hdfs-site.xml");
final File directory = new File(localHadoopConfigurationDirectory);
if (directory.exists() && directory.isDirectory()) {
return Arrays.stream(directory.listFiles())
.filter(
file ->
file.isFile()
&& expectedFileNames.stream()
.anyMatch(name -> file.getName().equals(name)))
.collect(Collectors.toList());
} else {
return Collections.emptyList();
}
}
//如果有 hadoop 的环境,将会把上述两个文件解析为 kv 对,然后构建成一个 ConfigMap,名字命名规则如下
public static String getHadoopConfConfigMapName(String clusterId) {
return Constants.HADOOP_CONF_CONFIG_MAP_PREFIX + clusterId;
}
然后进行进程端口占用查询:
netstat -tlnp | grep 10000
netstat -tlnp | grep 10002
5. 带来的收益
我们的团队从 StreamX(即 StreamPark 的前身)开始使用,经过一年多的实践和磨合,StreamPark 显著改善了我们在 Apache Flink 作业的开发管理和运维上的诸多挑战。StreamPark 作为一站式服务平台,极大地简化了整个开发流程。现在,我们可以直接在 StreamPark 平台上完成作业的开发、编译和发布,这不仅降低了 Flink 的管理和部署门槛,还显著提高了开发效率。
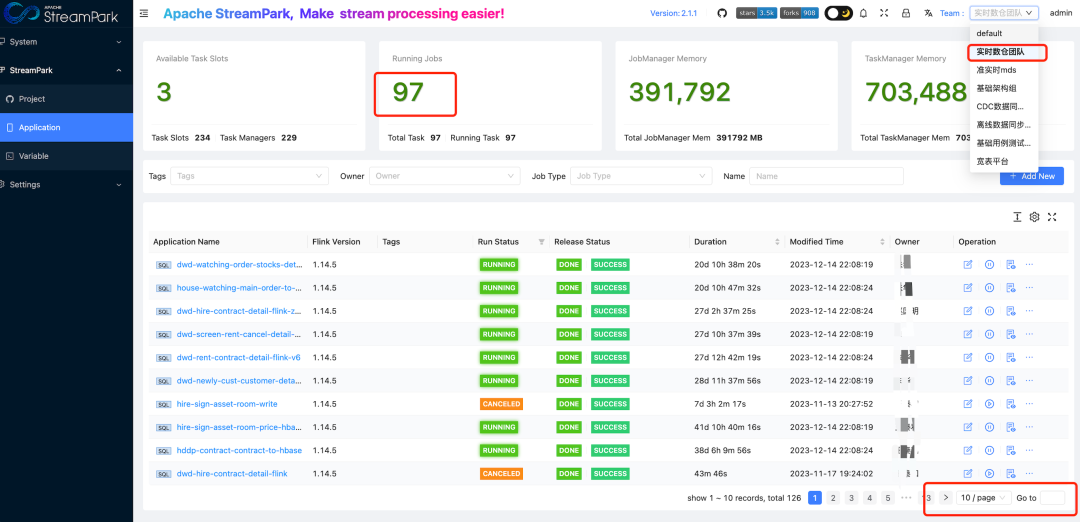
自从部署 StreamPark 以来,我们已经在生产环境中大规模使用该平台。从最初管理的 50 多个 FlinkSQL 作业,增长到目前近 500 个作业,如图在 StreamPark 上划分为 7 个 team,每个 team 中有几十个作业。这一转变不仅展示了 StreamPark 的可扩展性和高效性,也充分证明了它在实际业务中的强大应用价值。
![]()
6. 未来期待
自如作为 StreamPark 早期的用户之一,我们一直和社区同学保持密切交流,参与 StreamPark 的稳定性打磨,我们将生产运维中遇到的 Bug 和新的 Feature 提交给了社区。在未来,我们希望可以在 StreamPark 上管理 Apache Paimon 湖表的元数据信息和 Paimon 的 Action 辅助作业的能力,基于 Flink 引擎通过对接湖表的 Catalog 和 Action 作业,来实现湖表作业的管理、优化于一体的能力。目前 StreamPark 正在对接 Paimon 数据集成的能力,这一块在未来对于实时一键入湖会提供很大的帮助。
在此也非常感谢 StreamPark 团队一直以来对我们的技术支持,祝 Apache StreamPark 越来越好,越来越多用户去使用,早日毕业成为 Apache 顶级项目。
7. 加入我们
StreamPark 是一个流处理应用程序开发管理框架。旨在轻松构建和管理流处理应用程序,提供使用 Apache Flink 和 Apache Spark 编写流处理应用程序的开发框架。同时 StreamPark 提供了一个流处理应用管理平台,核心能力包括但不限于应用开发、调试、交互查询、部署、运维、实时数仓等,最初开源时项目名称叫 StreamX ,于 2022 年 8 月更名为 StreamPark,随后通过投票正式成为 Apache 开源软件基金会的孵化项目。目前已有腾讯、百度、联通、天翼云、自如、马蜂窝、同程数科、长安汽车等众多公司在生产环境使用
StreamPark 社区一直以来都以用心做好一个项目为原则,高度关注项目质量,努力建设发展社区。加入 Apache 孵化器以来,认真学习和遵循「The Apache Way」,我们将秉承更加兼容并包的心态,迎接更多的机遇与挑战。诚挚欢迎更多的贡献者参与到社区建设中来,和我们一道携手共建。
💻 项目地址:https://github.com/apache/streampark
🧐 提交问题和建议:Issues · apache/incubator-streampark · GitHub
🥁 贡献代码:Pull requests · apache/incubator-streampark · GitHub
📮 Proposal:StreamPark Proposal - INCUBATOR - Apache Software Foundation
📧 订阅社区开发邮件列表:dev@streampark.apache.org
💁♀️社区沟通:
![]()