Apache RocketMQ 发展历程回顾
![]()
RocketMQ 最早诞生于淘宝的在线电商交易场景,经过了历年双十一大促流量洪峰的打磨,2016年捐献给 Apache 社区,成为 Apache 社区的顶级项目,并在国内外电商,金融,互联网等各行各业的广大客户落地验证,得到广泛认可。
Apache RocketMQ 社区在2022年10月正式对外发布了全新的5.0版本,腾讯云消息队列团队也和社区紧密合作,支持了5.0的商业化版本,现在将整个落地过程的经验教训做个总结,回馈社区。
什么是 RocketMQ 5.0?
一个新版本号?
一套新设计的API?
一系列新的特性实现?
一个存算分离的新架构?
一种新的商业化产品形态?
RocketMQ 面向云原生的新思考?
Apache RocketMQ 社区过去一年对5.0新架构从不同的角度进行了分享介绍,导致很多用户对5.0新架构认识不一致,其实从以上不同角度理解都对,本文尝试从多个维度做一个较全面的解释和回顾,帮助用户全面理解 RocketMQ 5.0 架构演进背后的思考逻辑。
RocketMQ 5.0 的演进目标
RocketMQ 运行依赖的环境过去十年发生了巨大的变化,从最早的物理机部署开始,到现在云计算已经深入人心,资源越来越“弹性伸缩, 按量付费, 高SLA”,计算资源容器化,存储资源都演进为标准的分布式存储,比如块存储、文件存储和对象存储越来越成熟和标准化,尤其是以S3 为代表的对象存储,对比其他存储有很大的成本优势,所以新架构的演进就是要充分利用新计算和存储资源的优势。
RocketMQ 4.x 以前的协议,基于十多年前设计的私有Remoting协议,导致开发非 Java 语言的 SDK 成本非常高,所以 5.0 基于 gRPC 设计的全新 API 和 Proxy 模式,可以极大的方便多语言 SDK 开发,丰富多语言生态。
社区还开源了 EventBridge, Connector, Stream, MQTT 等周边项目,有助于完善和增强周边生态,拓展更多业务场景。
RocketMQ 5.0 的关键新特性
为了支持以上三个主要的演进目标,RocketMQ 5.0 版本引入了大量新的技术和特性,下面将一些关键特性逐个简要介绍,其中不少特性已经在腾讯云投入实际使用,并发挥了业务价值。
POP 消费模式
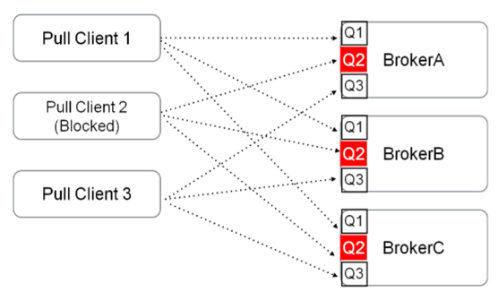
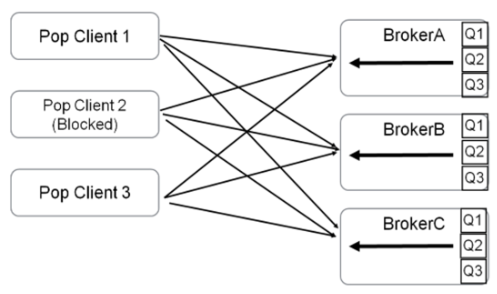
RocketMQ 5.0 之前版本只提供了Pull的消费模式(即使 PushConsumer 也是通过 Pull 和长轮训模拟的 Push 效果),Pull 消费模式和 Kafka 消费模式类似,也是需要在客户端做负载均衡,计算客户端实例和队列的映射关系,然后再消费消息和维护队列的位点信息,通过新的 POP 消费模式,带来了以下明显的好处:
-
不需要在客户端计算分配逻辑,简化客户端逻辑
-
降低了客户端SDK开发的复杂度,便于快速支持多语言客户端
-
消费位点完全维护在Broker端,避免单个消费节点慢导致消费延迟
-
适配其他协议的Proxy模式更顺畅,方便支持多消费模型时做推拉转换
![]()
![]()
腾讯云在 RocketMQ 5.0 的产品形态中,支持5.0新协议和兼容其他消息协议的过程中,都采用了 POP 消费模式,方便支持了Proxy的完全无状态和负载均衡。
更详细的POP方案设计扩展阅读参考:
基于gRPC的新API设计
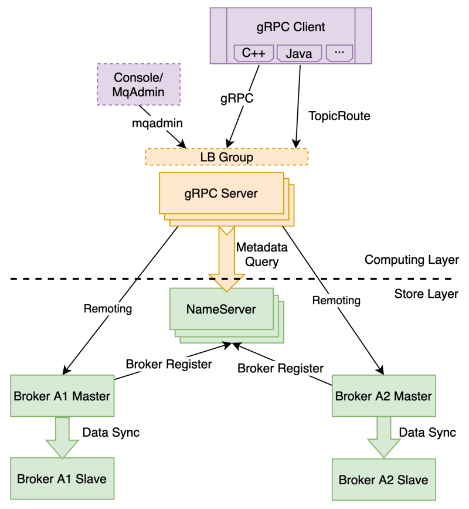
RocketMQ 社区过去几年在支持 RocketMQ 4.x 客户端的过程中,越来越意识到 Remoting 协议的不足,开发非Java SDK的门槛和成本过高,导致各个公司推出了基于 HTTP 等其他协议多种兼容 Proxy 方案,这次新 API 相当于官方出了一个统一的可扩展 Proxy 方案,方便各公司在这个 Proxy 的基础上,合并兼容一些其他协议,统一和简化架构,最终形成一个以RocketMQ Broker 为存储内核,兼容各种消息协议的无状态 Proxy 的存算分离统一架构。
![]()
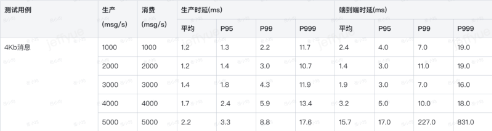
腾讯云在落地新架构的过程中,因为 Proxy 要处理协议序列化和转换等 CPU 密集型计算,要注意对 CPU 占用的优化,我们也向社区提了多个优化代码,以下是我们对4C8G规格的参考压测数据:
![]()
Proxy 压测过程中典型火焰图占用分析如下:
![]()
更详细的关于新方案设计和扩展阅读详见:
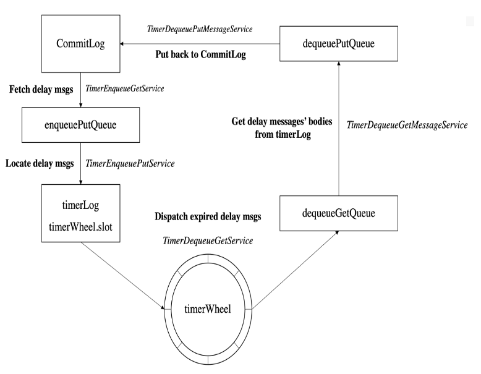
秒级定时消息
定时消息是在线消息场景经常用的一种消息类型,发送方发送消息以后,并不想让订阅方立即消费到消息,而是等一段时间以后,消息对订阅方可见,典型的业务场景是订单下单五分钟后检查订单状态,或交易成功后第二天固定时间生成积分或优惠券。
RocketMQ 5.0 之前的版本,只能利用重试消息固定间隔的机制,实现Level固定级别的定时消息,5.0 新版本中重新实现了定时消息,可以支持超大规模超⻓时间任意秒级粒度的定时消息。
![]()
更详细的关于秒级定时消息方案设计和扩展阅读参考:
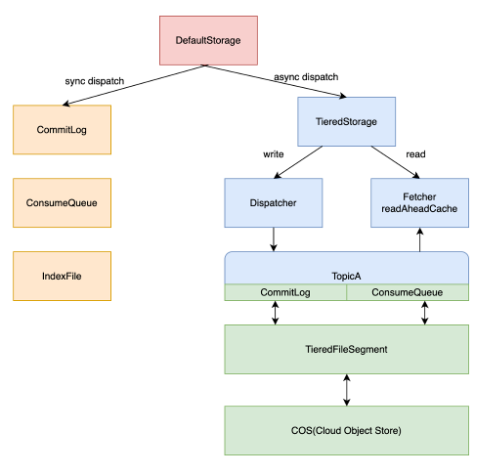
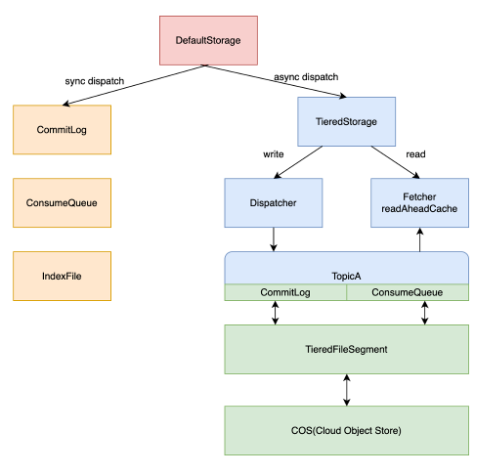
分层存储
RocketMQ 4.x 只支持本地磁盘或云盘等块设备作为持久化存储介质,块设备存储虽然能带来低延迟和可靠性,但是其存储成本却是对象存储的5~10倍,而消息队列数据是典型的冷热分布的数据,根据作者在实际系统的统计,约85%热数据在10分钟内通过内存缓存读取,其次10%温数据可能会在1小时内读走,约有5%的冷数据只有长时间堆积或回溯消费的场景才会被读到。
RocketMQ 5.0 引入了分层存储技术,可以将冷数据搬迁到更廉价的存储中,比如对象存储,可以在不降低用户体验的前提下,极大的降低综合存储成本。实现思路如下图所示,通过写入时将消息异步复制到分层存储,读取时优先读取本地存储,不命中的话再读取远程存储,实现分层存储的目的。
![]()
腾讯云在落地分层存储的过程中,一级存储选择了腾讯云云盘CBS,二级存储选择了腾讯云对象存储COS,以下表格是我们在腾讯云上的一个性能测试报告,开启分层存储对在线业务几乎不会有影响,这也与代码预期行为一致(dispatch异步写对象存储、热数据读本地缓存),二级存储单分区消费可以支持7500msg/s,扩分区可以等比例扩容消费速度,可以满足线上需求标准。
![]()
更详细的实现方案详见RIP文档:
基于KV的百万队列索引
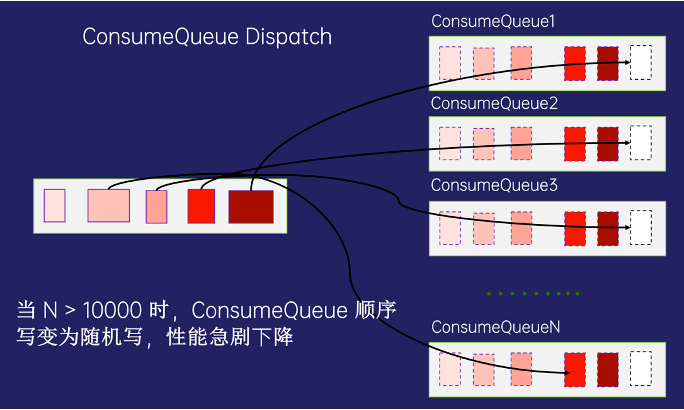
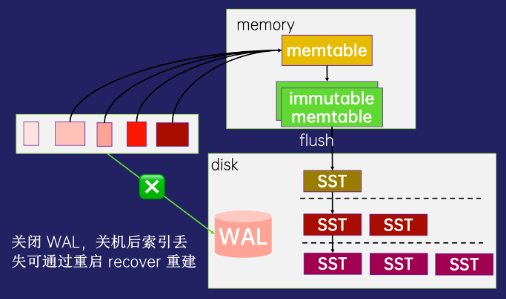
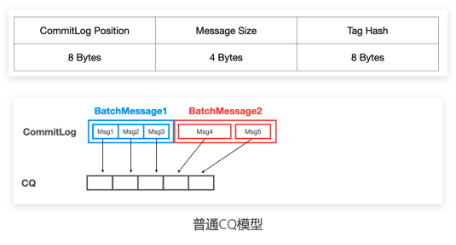
RocketMQ 4.x 版本中,每个Topic实际都是由多个队列来存储消息的,队列的数据存在统一的Commitlog中,消息队列索引是通过文件队列来存储消息索引的,当队列少于1万时,可以稳定高效的提供读写服务,当队列数超过10万以后,队列索引会退化成严重的随机写,导致性能严重下降
RocketMQ 5.0 引入 RocksDB 存储队列索引,利用 RocksDB 的 LSM 索引结构特性,将大量文件队列索引的随机写转化为 SST 文件的顺序写,即使有上百万个消息队列,从整个架构看,底层云盘依然只有少量的顺序写文件,依然可以稳定的提供消息读写服务。
![]()
![]()
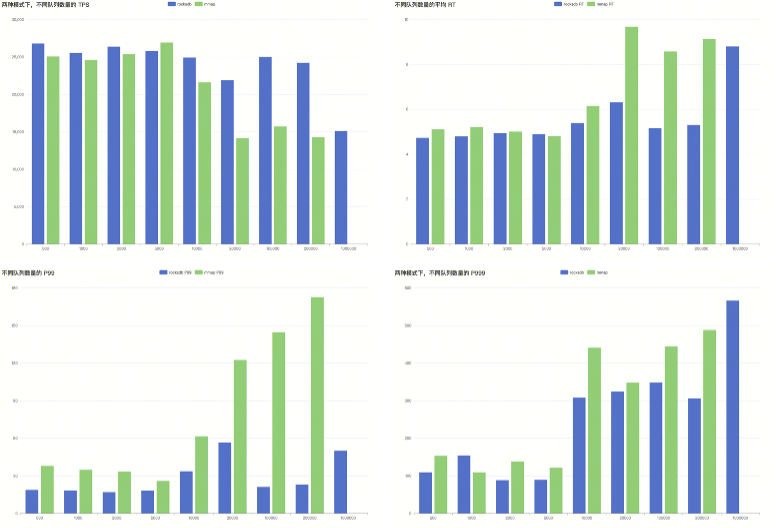
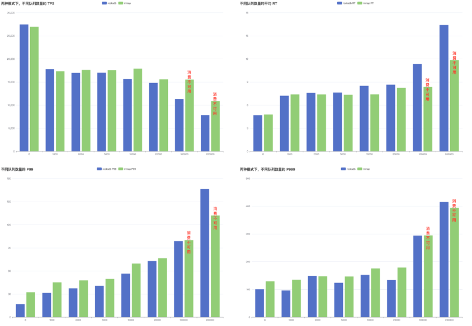
以下是在我们测试环境测得的数据,队列数量少的时候,两个方案的从TPS和耗时指标差别不大,但是队列数超过20万以后,基于RocksDB的索引方案性能和稳定性的优势明显。
![]()
![]()
更详细的实现方案介绍参考:
原生批量消息支持
RocketMQ 4.x 的版本中的批量消息是一个“伪批量”消息实现,需要在发送方发送一个业务层面组织好的消息数组,RocketMQ Broker 收到消息数组后,会再拆成多个消息,逐个处理消息的写入,旧方案虽然兼容性好,实现简单,但是只优化了网络开销,压缩和存储性能优化不明显。
RocketMQ 5.0 引入了新的 AutoBatch 特性,对批量消息做了全链路的优化,从发送端的自动攒批编程界面,到新的存储格式和索引结构,都做了全面的优化。
![]()
![]()
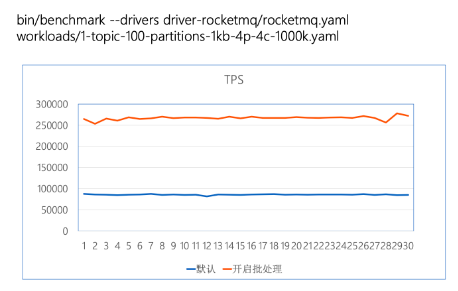
以下是 RocketMQ 社区咸鱼(guyinyou · GitHub)同学提供的几种场景的压测数据,对比普通消息吞吐量翻倍提升,对比 Kafka 同等节点规格和业务场景下可以达到几乎相同的吞吐,在分区增加的场景下,提供更优的发送延时抖动:
![]()
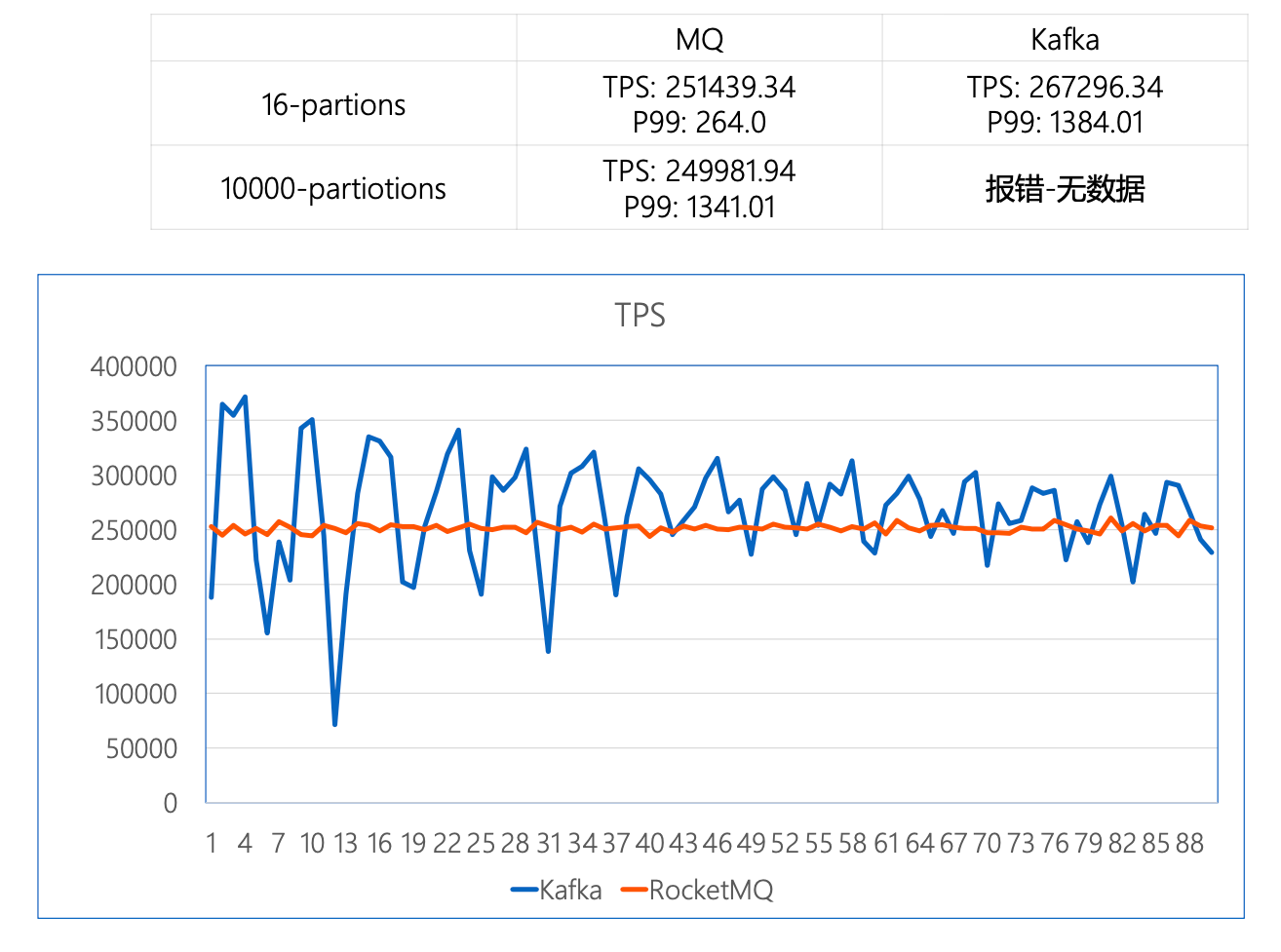
使用同样测试节点和 Kafka 作性能对比,部署架构都采用3节点2副本的测试场景下,同样 16 分区下可以达到几乎同样的吞吐量但更低的发送延时,并且随着分区数增加,RocketMQ的稳定性和发送延时有明显的优势。
![]()
![]()
更详细的设计文档和测试结果详见:
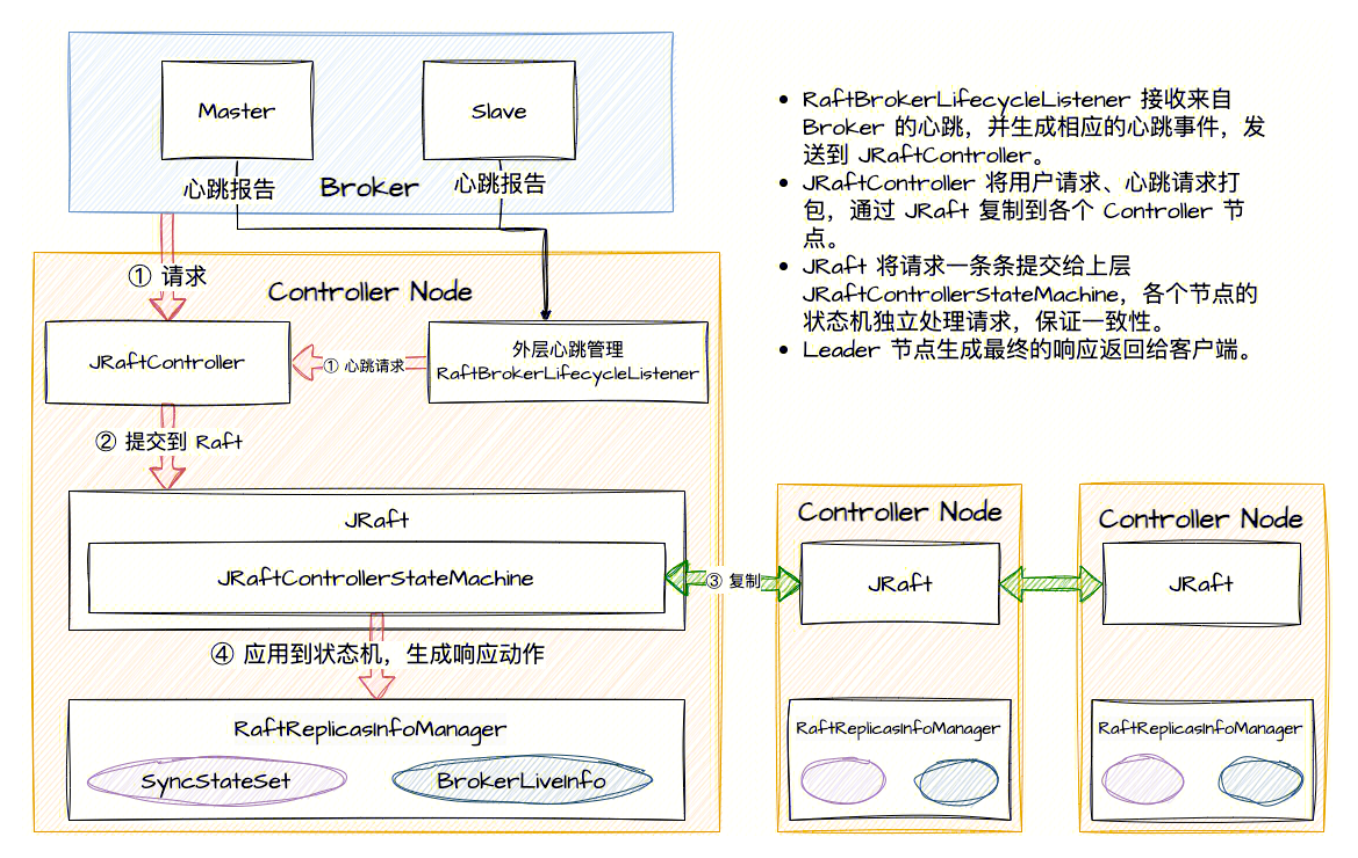
jRaft Controller 实现
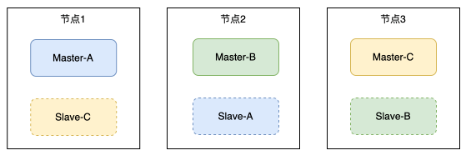
RocketMQ 4.x 主从复制提供了简单高效的消息高可靠方案,但是一直存在一个无法自动切换主从的功能缺失,DLedger模式虽然通过基于Raft的三副本解决了自动选主的问题,但是性能比较差,并且机器成本高。
RocketMQ 5.0 新增了一个 Controller 组件(此组件可以和Namesrv合并部署),解决主从复制部署模式下自动切换的问题,但是社区默认的 Controller 组件是基于 DLedger 实现的,Raft 实现并不完善,腾讯云消息团队同学为社区提供了一个新的基于 SOFAJRaft 更成熟的 Raft 实现方案,可以实现更稳定可靠的主从切换。
![]()
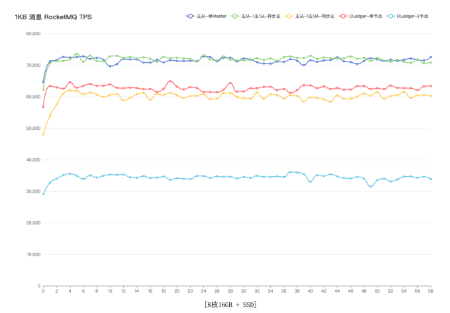
不同副本和同步机制的性能对比如下图所示:
![]()
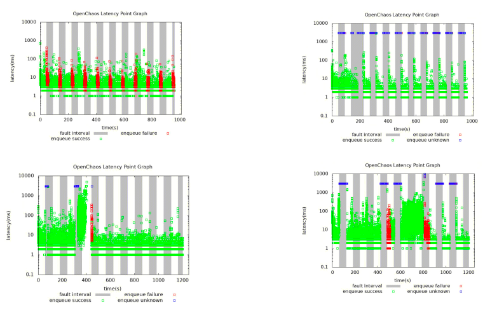
在腾讯云测试环境的混沌测试结果全部通过:
![]()
更多JRaft Controller的详细设计文档参考:
其他新特性索引
RocketMQ 社区针对大的特性变更,都会有详细RIP文档和评审流程,限于篇幅,本文只挑了几个关键新特性做了简要介绍,更多新特新可以参考社区全部 RIP 列表链接。
腾讯云 RocketMQ 的商业化历程
腾讯云消息队列团队过去几年基于 Apache RocketMQ 社区走过了完整的商业化历程,在2023年9月正式推出了5.x 商业化版本,提供极致弹性和更低成本的RocketMQ 服务,满足不同场景对 RocketMQ 的差异化需求,并已经在金融、出行、教育、游戏等多个行业落地实践。
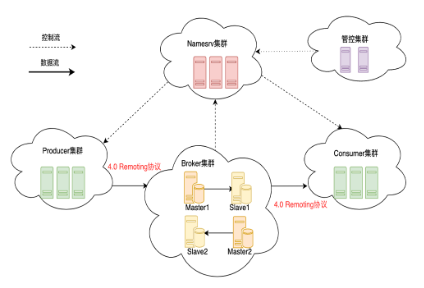
新存算分离架构升级
在腾讯云内部,我们也将部署架构做了调整,按照 RocketMQ 5.0 推荐的存算分离架构,简化RocketMQ 的运维,也可以为用户提供更好的升降配弹性体验。
![]()
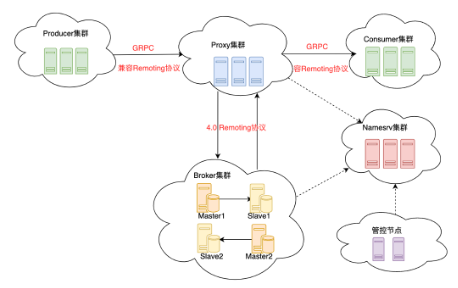
下图是 RocketMQ 5.0 新的存算分离架构:
![]()
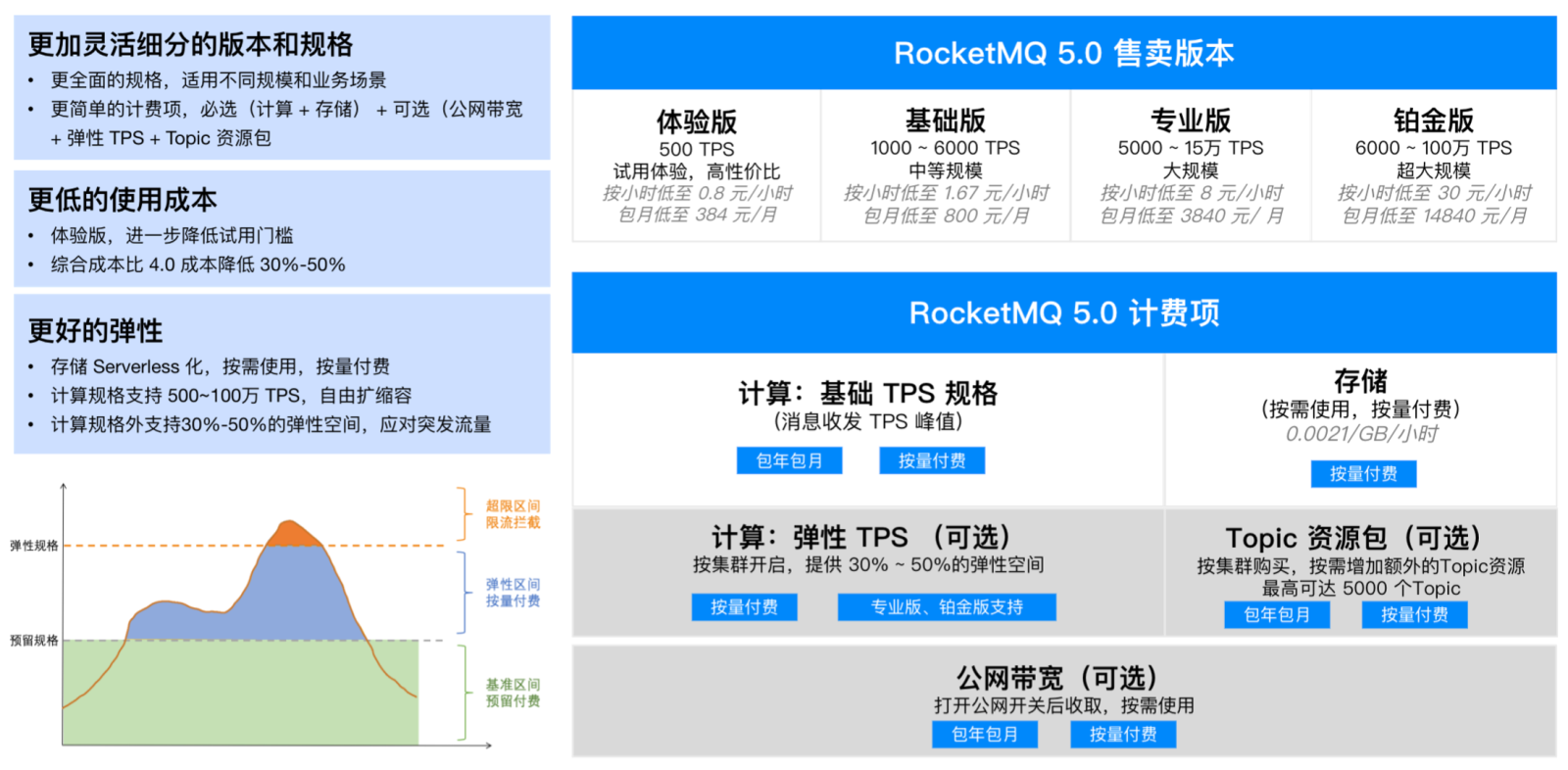
全新的 5.0 Serverless 产品形态
基于以上新的存算分离新架构,我们推出了新的 TDMQ RocketMQ 5.0 Serverless 产品形态,通过全新的按量计费模式,并且专业版以上免费提供了弹性TPS的能力,可以更低成本来应对突发流量。
![]()
落地实践总结与展望
回顾 RocketMQ 过去十年的发展历程,可以看到 RocketMQ 社区的蓬勃发展和功能的快速迭代演进,并且在国内各大云厂商也有快速的落地支持,腾讯云也会持续的大力研发投入,给 RocketMQ 用户提供了更多更优的选择。
腾讯云在 RocketMQ 商业化过程中,也积极回馈 RocketMQ 社区,近一年腾讯云为 RocketMQ 社区贡献了 30+ 缺陷修复和性能优化代码合并,并且贡献了一个 RIP 67,也希望未来和 RocketMQ 社区更紧密配合,为 Apache RocketMQ 的繁荣发展做出贡献,为用户提供更优质的 RocketMQ 服务。