Disruptor 是英国外汇交易公司 LMAX 开发的一个高性能队列。很多知名开源项目里,比如 canal 、log4j2、 storm 都是用了 Disruptor 以提升系统性能 。
这篇文章,我们通过两个例子一步一个脚印帮助同学们入门 Disruptor 。
1 环形缓冲区
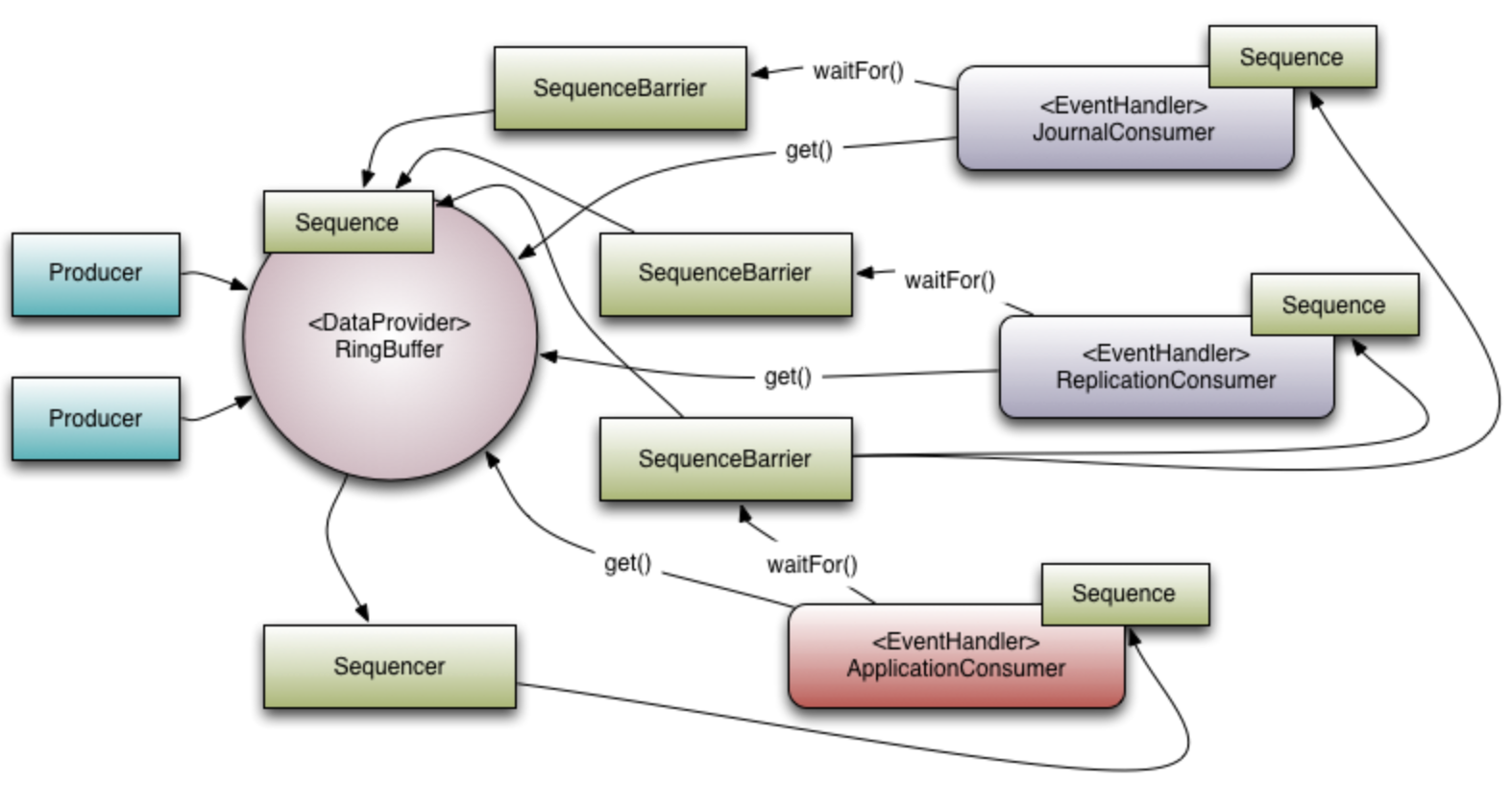
下图展示了 Disruptor 的流程图 。
![]()
和线程池机制非常类似, Disruptor 也是非常典型的生产者/消费者模式。线程池存储提交任务的容器是阻塞队列,而 Disruptor 使用的是环形缓冲区 RingBuffer。
环形缓冲区的设计相比阻塞队列有如下优点:
为了避免垃圾回收,采用数组而非链表。同时,数组对处理器的缓存机制更加友好。
数组长度2^n,通过位运算,加快定位的速度。下标采取递增的形式,不用担心 index 溢出的问题。index 是 long 类型,即使100万QPS的处理速度,也需要30万年才能用完。
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
2 写一个Hello world
我们写一个非常简单的例子:生产者传递一个单一的长整型值给消费者,而消费者将简单地打印出这个值。
2.1 添加依赖
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.6</version>
</dependency>
2.2 定义事件
首先,我们将定义一个事件(Event),它将携带数据,并且在接下来的所有示例中都是通用的。
public class LongEvent {
private long value;
public void set(long value) {
this.value = value;
}
@Override
public String toString() {
return "LongEvent{" + "value=" + value + '}';
}
}
为了让 Disruptor 为我们预分配这些事件,我们需要一个 EventFactory 来执行构造。这可以是一个方法引用,比如 LongEvent::new ,或者是 EventFactory 接口的显式实现:
public class LongEventFactory implements EventFactory<LongEvent> {
@Override
public LongEvent newInstance() {
return new LongEvent();
}
}
2.3 定义消费者
定义了事件,我们需要创建一个消费者来处理这些事件。我们会创建一个事件处理器(EventHandler),它会将把值打印到控制台上。
public class LongEventHandler implements EventHandler<LongEvent> {
@Override
public void onEvent(LongEvent longEvent, long sequence, boolean endOfBatch) throws Exception {
System.out.println("currentThread:" + Thread.currentThread().getName() + " Event: " + longEvent);
}
}
2.4 发布
public class LongEventMain {
public static void main(String[] args) throws Exception {
int bufferSize = 2;
Disruptor<LongEvent> disruptor =
new Disruptor<>(
new LongEventFactory(),
bufferSize,
DaemonThreadFactory.INSTANCE,
ProducerType.SINGLE,
new BlockingWaitStrategy());
disruptor.handleEventsWith(new LongEventHandler());
disruptor.start();
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++) {
bb.putLong(0, l);
ringBuffer.publishEvent((event, sequence, buffer) -> event.set(buffer.getLong(0)), bb);
Thread.sleep(1000);
}
}
}
整个发布流程分为四个部分:
-
指定环形缓冲区的大小,必须是2的幂次方,例子中设置的值是 1024 ;
-
构建 Disruptor ,参数分别是事件工厂EventFactory 、环形缓冲区的大小ringBufferSize 、处理器线程池 、生产者类型(单生产者/多生产者)、消费者阻塞策略 ;
-
定义事件处理器eventHandler,我们这里的逻辑是打印数据打印在控制台;
-
启动 Disruptor,从 Disruptor 中获取环形缓冲区ringBuffer,在 for 循环里 ,调用环形队列的publishEvent方法。
这里使用了 ByteBuffer 做为数据的存储容器 , 方便作为参数传递。
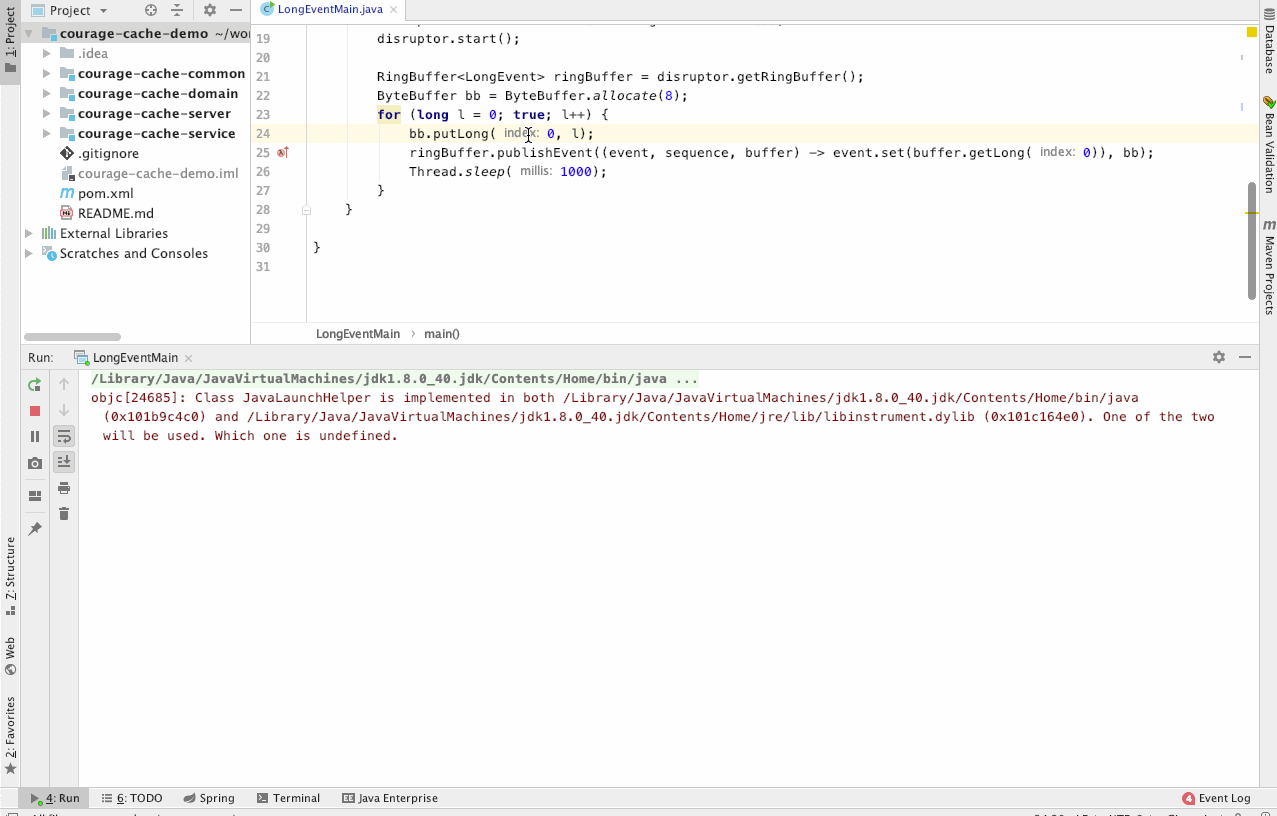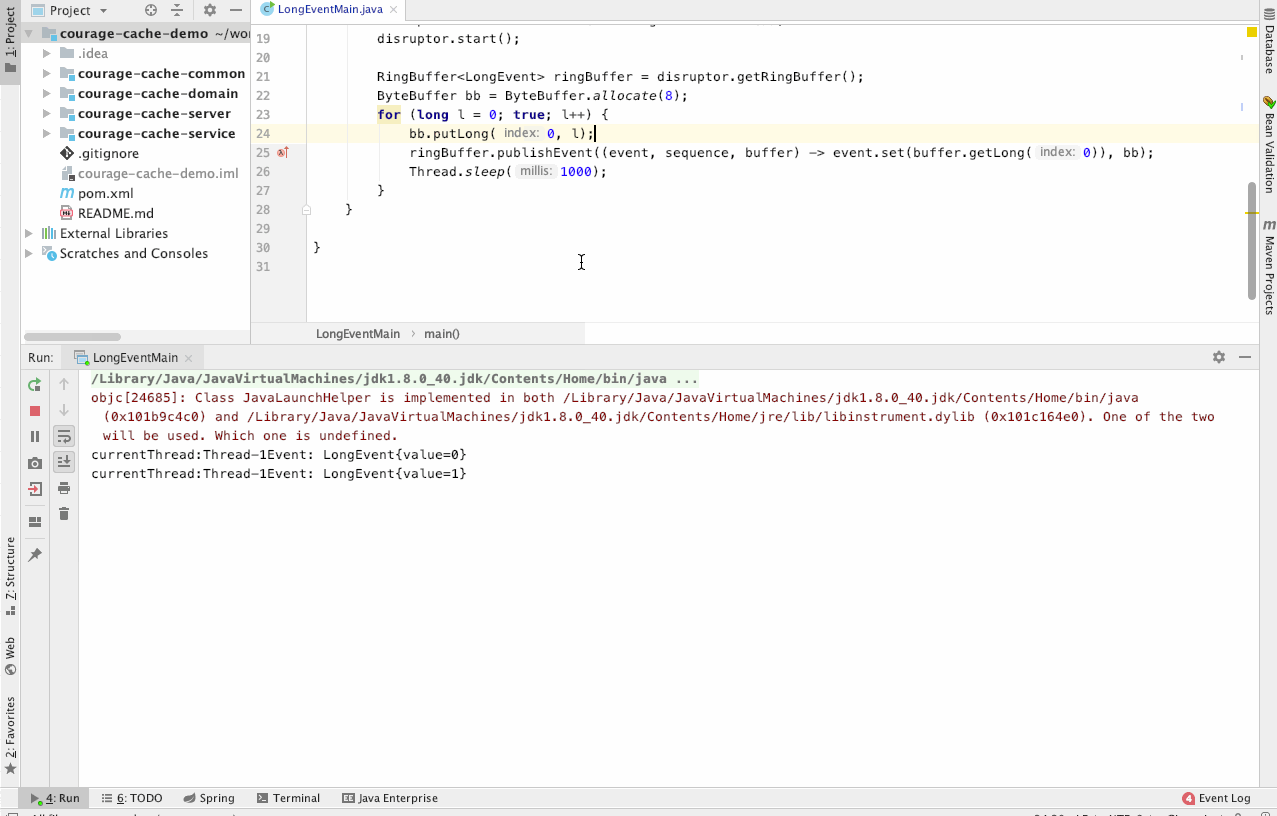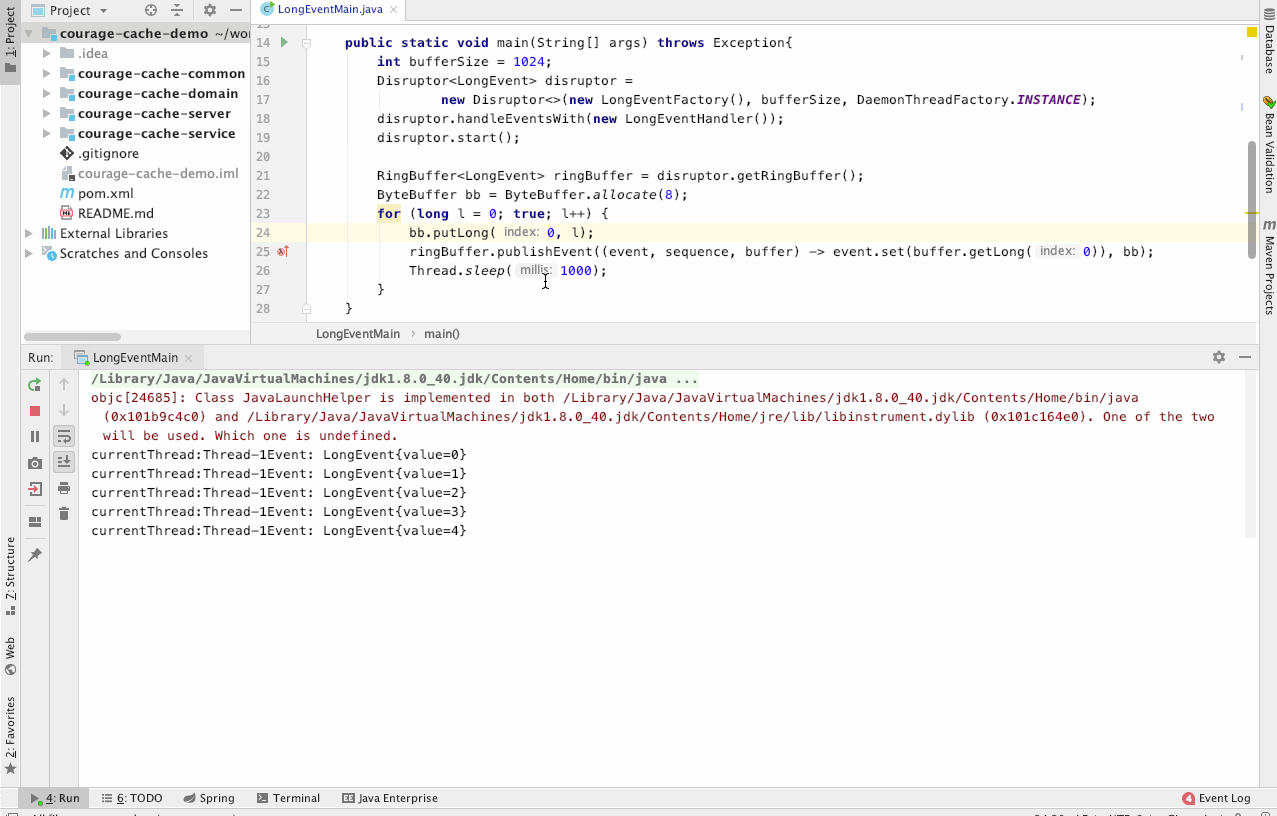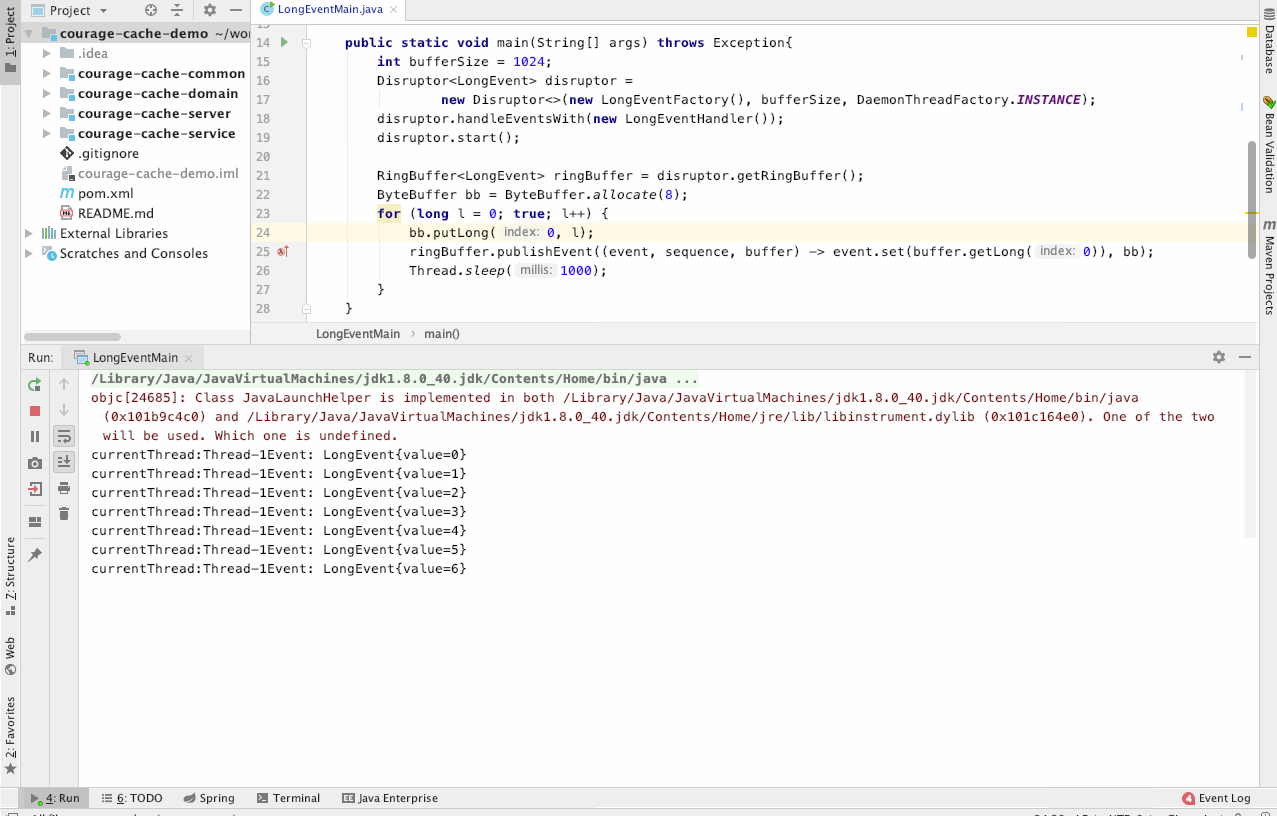
我们来看下执行结果 :
![]()
3 日志处理
3.1 应用场景
上面的例子比较简单,但假如要应用到生产环境,就显得非常粗糙。
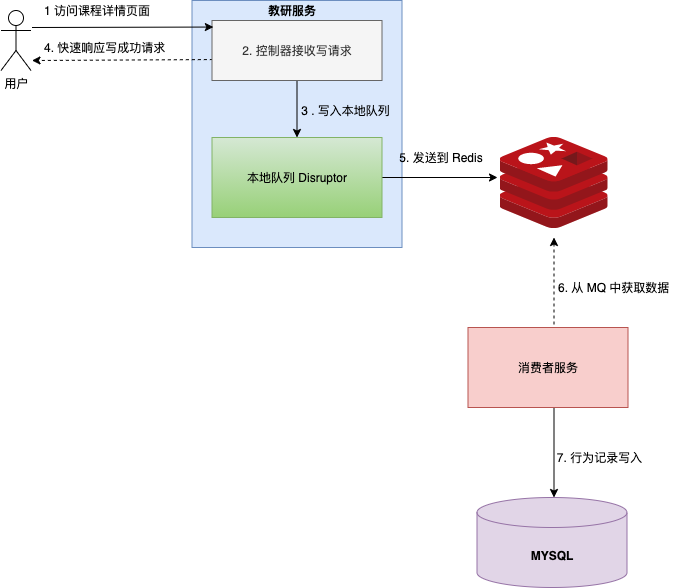
我们模拟一个日志处理的场景,用户进入视频播放页面,浏览器定时的发送浏览日志到服务端,服务端将日志存储起来。
![]()
3.2 核心类设计
我们定义一个 DisruptorManager 管理器 , 管理器包含三个核心参数:消费者监听器 DataEventListener、消费者数量、环形队列长度。
public class DisruptorManager<T> {
private static final Integer DEFAULT_CONSUMER_SIZE = 4;
public static final Integer DEFAULT_SIZE = 4096 << 1 << 1;
private DataEventListener<T> dataEventListener;
private DisruptorProducer<T> producer;
private int ringBufferSize;
private int consumerSize;
public DisruptorManager(DataEventListener<T> dataEventListener) {
this(dataEventListener, DEFAULT_CONSUMER_SIZE, DEFAULT_SIZE);
}
public DisruptorManager(DataEventListener<T> dataEventListener, final int consumerSize, final int ringBufferSize) {
this.dataEventListener = dataEventListener;
this.ringBufferSize = ringBufferSize;
this.consumerSize = consumerSize;
}
public void start() {
EventFactory<DataEvent<T>> eventFactory = new DisruptorEventFactory<>();
Disruptor<DataEvent<T>> disruptor = new Disruptor<>(
eventFactory,
ringBufferSize,
DisruptorThreadFactory.create("consumer-thread", false),
ProducerType.MULTI,
new BlockingWaitStrategy()
);
DisruptorConsumer<T>[] consumers = new DisruptorConsumer[consumerSize];
for (int i = 0; i < consumerSize; i++) {
consumers[i] = new DisruptorConsumer<>(dataEventListener);
}
disruptor.handleEventsWithWorkerPool(consumers);
disruptor.start();
RingBuffer<DataEvent<T>> ringBuffer = disruptor.getRingBuffer();
this.producer = new DisruptorProducer<>(ringBuffer, disruptor);
}
public DisruptorProducer getProducer() {
return this.producer;
}
}
首先和 Hello world 代码中的不同的点,Disruptor 的构造函数中我们自定义了消费者的处理器线程。
DisruptorThreadFactory.create("consumer-thread", false),
然后我们定义消费者的业务逻辑 :
DisruptorConsumer<T>[] consumers = new DisruptorConsumer[consumerSize];
for (int i = 0; i < consumerSize; i++) {
consumers[i] = new DisruptorConsumer<>(dataEventListener);
}
disruptor.handleEventsWithWorkerPool(consumers);
消费者本质上是workHandler的实现类,只不过初始化时将 DataEventListener 作为构造函数的参数。
public class DisruptorConsumer<T> implements WorkHandler<DataEvent<T>> {
private DataEventListener<T> dataEventListener;
public DisruptorConsumer(DataEventListener dataEventListener) {
this.dataEventListener = dataEventListener;
}
@Override
public void onEvent(DataEvent<T> dataEvent) throws Exception {
if (dataEvent != null) {
dataEventListener.processDataEvent(dataEvent);
}
}
}
因为我们是希望线程池并行的处理这些消息数据,使用的是disruptor.handleEventsWithWorkerPool 可以保证每个事件只会由一个工作处理器处理。
在 springboot 项目中,我们需要初始化相关 bean。
@Configuration
@AutoConfigureBefore(RedisConfig.class)
public class DisruptorConfig {
private final static Logger logger = LoggerFactory.getLogger(DisruptorConfig.class);
private final static String LIST_KEY = "disruptor:list";
@Autowired
private RedissonClient redissonClient;
@Bean
public DataEventListener<String> createConsumerListener() {
DataEventListener<String> dataEventListener = new DataEventListener<String>() {
@Override
public void processDataEvent(DataEvent<String> dataEvent) throws InterruptedException {
logger.info("processDateEvent data:" + dataEvent.getData());
redissonClient.getList(LIST_KEY).add(dataEvent.getData());
}
};
return dataEventListener;
}
@Bean
public DisruptorProducer<String> createProducer(DataEventListener dataEventListener) {
DisruptorManager disruptorManage = new DisruptorManager(dataEventListener,
8,
1024 * 1024);
disruptorManage.start();
return disruptorManage.getProducer();
}
首先,我们定义好消费者的事件监听器,然后定义 DisruptorProducer, 该类用来将数据提交到环形队列。
public class DisruptorProducer<T> {
private final Logger logger = LoggerFactory.getLogger(DisruptorProducer.class);
private final RingBuffer<DataEvent<T>> ringBuffer;
private final Disruptor<DataEvent<T>> disruptor;
private final EventTranslatorOneArg<DataEvent<T>, T> translatorOneArg = (event, sequence, t) -> event.setData(t);
public DisruptorProducer(final RingBuffer<DataEvent<T>> ringBuffer, final Disruptor<DataEvent<T>> disruptor) {
this.ringBuffer = ringBuffer;
this.disruptor = disruptor;
}
/**
* Send a data.
*
* @param data the data
*/
public void onData(final T data) {
try {
ringBuffer.publishEvent(translatorOneArg, data);
} catch (Exception ex) {
logger.error("publish event error:", ex);
}
}
public void shutdown() {
if (null != disruptor) {
disruptor.shutdown();
}
}
}
最后,在控制器中,接收前端请求:
@Autowired
private DisruptorProducer<String> producer;
@GetMapping("/pushlog")
public ResponseEntity pushlog(String log) {
producer.onData(log);
return ResponseEntity.successResult(null);
}
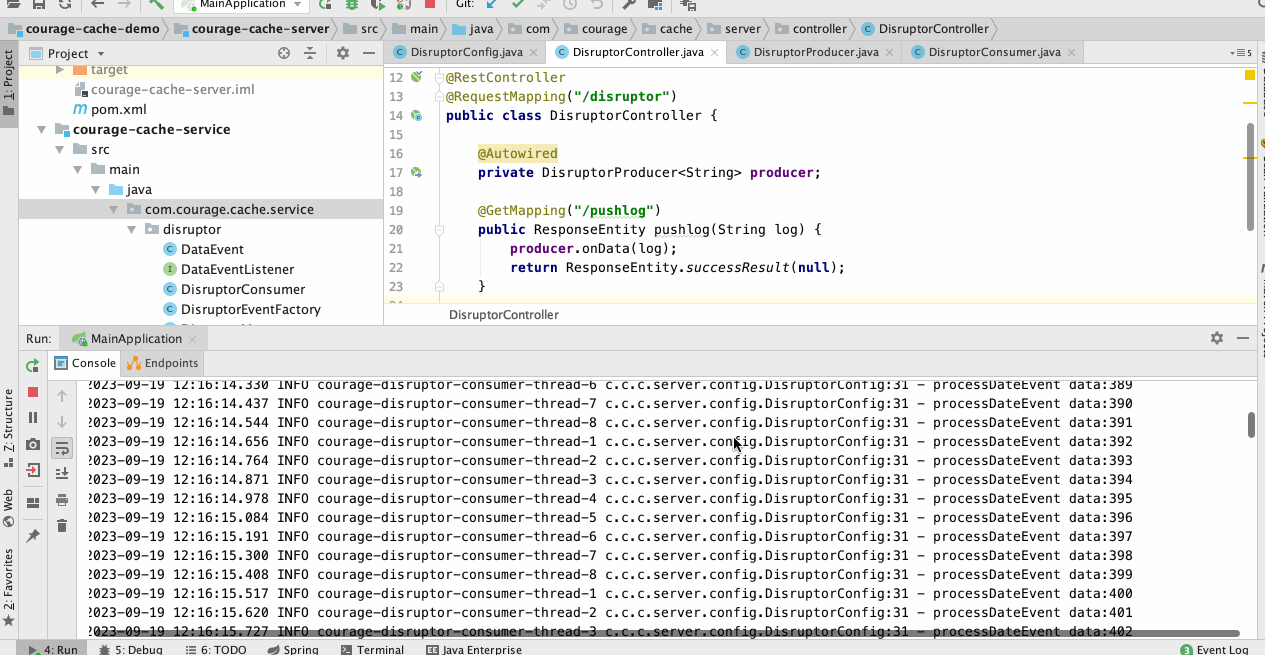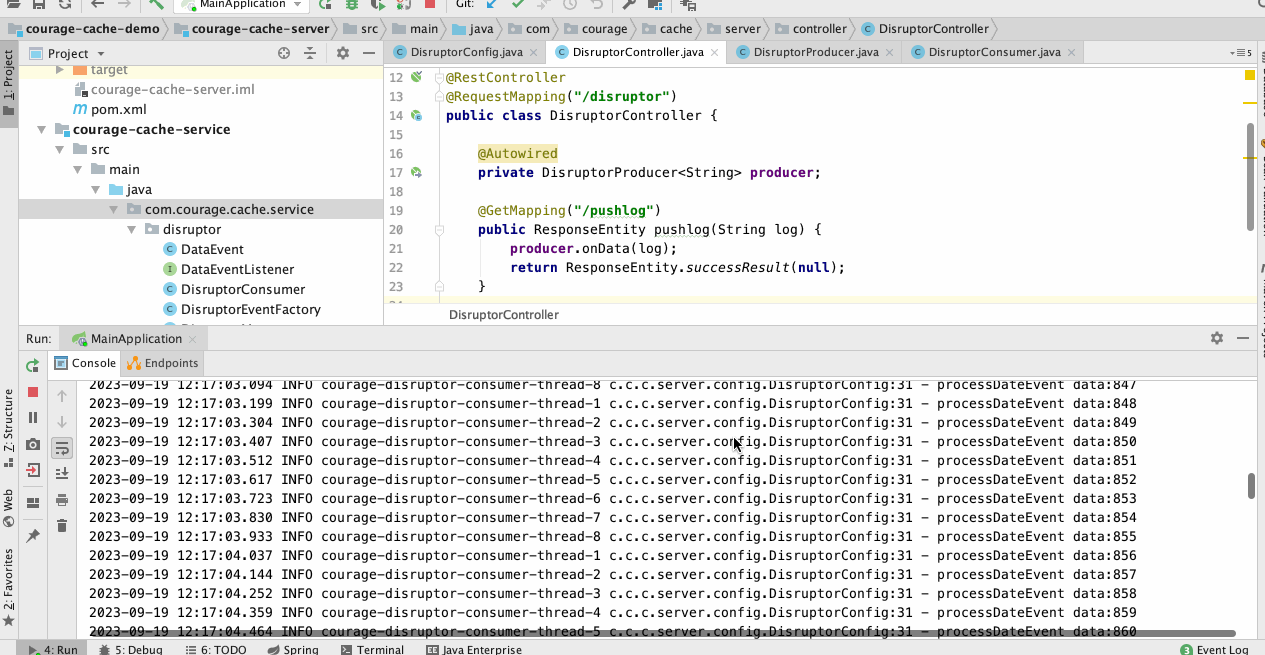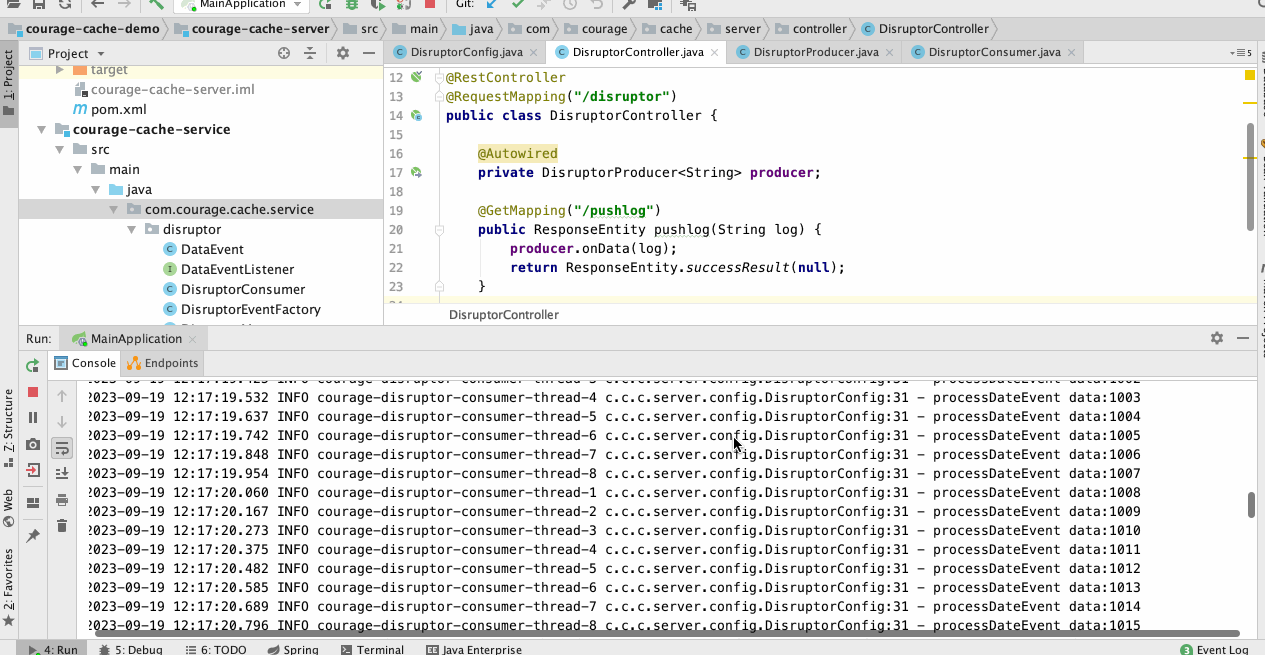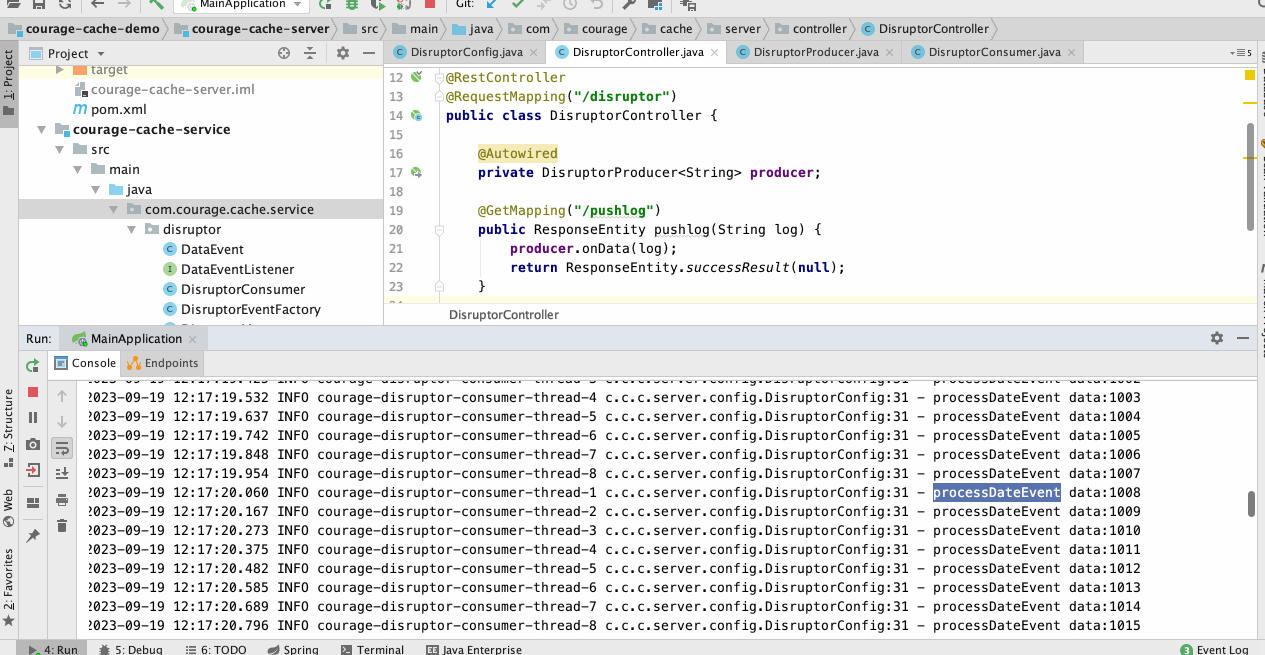
从下图中,我们可以看到从控制器接收到请求后,消费处理器线程不断地将数据打印出来,并且发送到队列中。
![]()
4 写到最后
日志处理的例子里,我们试图封装 Disruptor 相关 API ,以便在 springboot 项目中更方便的使用。
笔者在测试过程时,发现若消费逻辑慢的时候,生产者发送数据事件时,可能会阻塞。
为什么生产者会阻塞,Disruptor 的核心原理是什么 ,如何使用 Disruptor 的高级特性顺序依赖执行 ?
正因为有这些疑问,笔者觉得深入理解 Disruptor 原理特别有必要,笔者也会在接下来的文章里一一为大家答疑解惑。
参考资料:
https://lmax-exchange.github.io/disruptor/disruptor.html
https://zhuanlan.zhihu.com/p/45575008