![]()
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。
What's On In Databend
探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。
利用 Cluster Key 优化查询性能
通过定义 Cluster Key ,可以引导 Databend 对表进行聚类来提高查询性能,此时数据将会根据 Cluster Key 来组织和分组,而不仅仅依赖数据摄入的顺序。从而在处于大型表中获得优化的数据读取逻辑,加速查询。
一旦表设定了 Cluster Key ,在使用 COPY INTO 和REPLACE INTO 这两种方式写入数据时,会自动执行 compact 和 recluster 操作。
由于执行聚类和重聚类操作需要消耗一定的时间,所以我们建议主要为查询性能较慢的大型表定义集群键。
如果您想了解更多信息,请查看下面列出的资源。
Code Corner
一起来探索 Databend 和周边生态中的代码片段或项目。
Databend Local 模式
Databend 的 local 模式旨在为 Databend 提供一个简易版本,用户无需部署 Databend 服务就可以用 SQL 进行交互交互,从而方便开发者们用 SQL 使用 Databend 支持的功能进行简单的数据处理。
Local 模式 将启动一个临时的 databend-query 进程,并且提供客户端和服务端的融合支持。其存储位于临时目录中,生命周期跟随进程,进程离开后资源也将销毁,你可以在一个服务器中启动多个 local 进程,他们的资源是相互隔离的。
❯ alias databend-local="databend-query local"
❯ echo " select sum(a) from range(1, 100000) as t(a)" | databend-local
4999950000
❯ databend-local
databend-local:) select number %3 n, number %4 m, sum(number) from numbers(1000000000) group by n,m limit 3 ;
┌───────────────────────────────────┐
│ n │ m │ sum(number) │
│ UInt8 │ UInt8 │ UInt64 NULL │
├───────┼───────┼───────────────────┤
│ 0 │ 0 │ 41666666833333332 │
│ 1 │ 0 │ 41666666166666668 │
│ 2 │ 0 │ 41666666500000000 │
└───────────────────────────────────┘
0 row result in 1.669 sec. Processed 1 billion rows, 953.67 MiB (599.02 million rows/s, 4.46 GiB/s)
如果你需要在生产环境使用 Databend,我们建议按官方文档部署 Databend 服务或使用 Databend Cloud,但如果你是开发人员或测试工程师,则可以使用 local 模式来体验 Databend 。
如果您想了解更多信息,请查看下面列出的资源。
Highlights
以下是一些值得注意的事件,也许您可以找到感兴趣的内容。
What's Up Next
我们始终对前沿技术和创新理念持开放态度,欢迎您加入社区,为 Databend 注入活力。
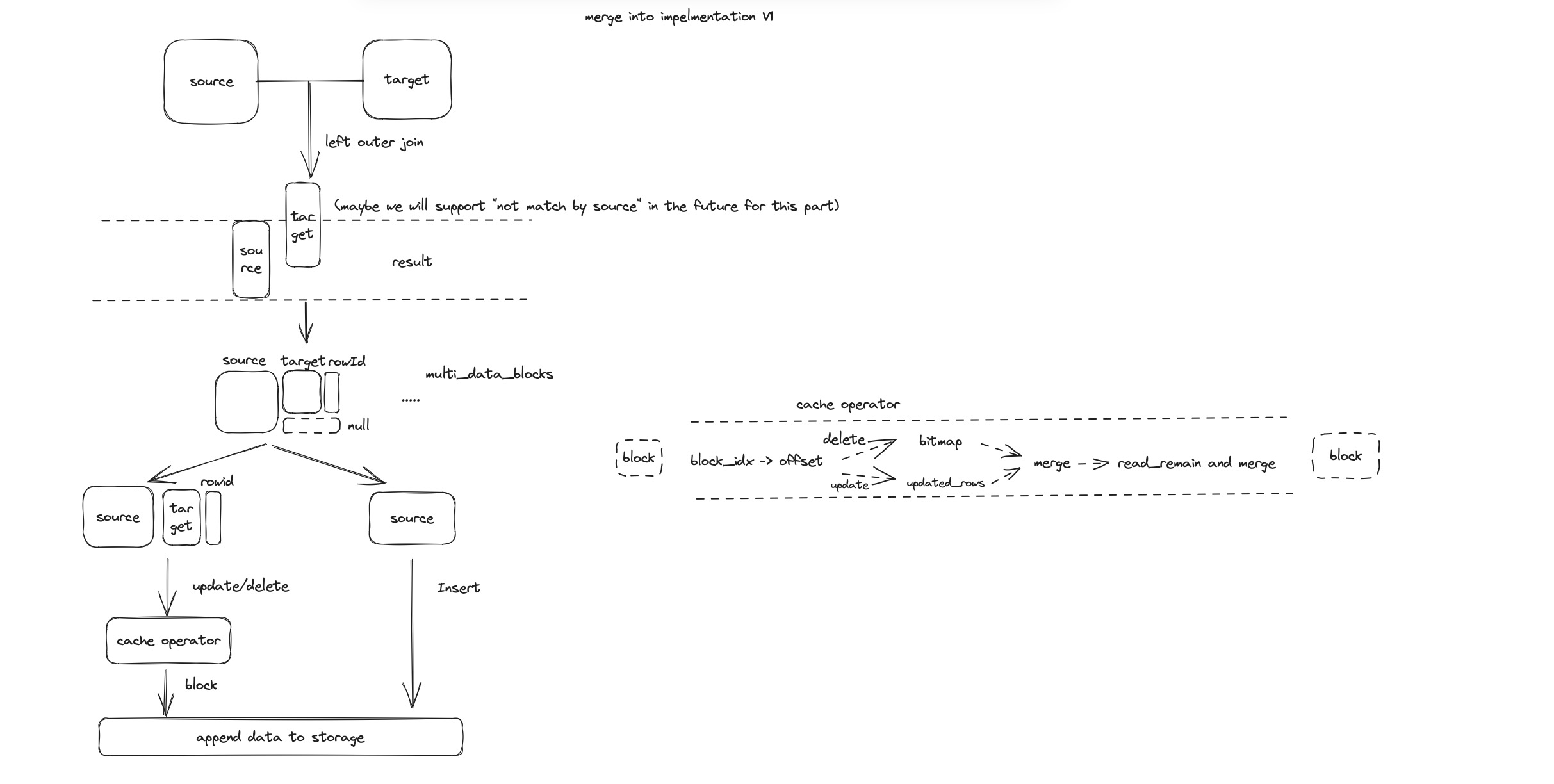
优化 MERGE INTO 实现
在 PR #12350 | feat: support Merge-Into V1 中,Databend 初步支持了 MERGE INTO 语法。
![]()
在这个基础上,还有很多值得关注的优化可以实施,比如:提供并行和分布式的实现,减少 IO 并简化数据块拆分等。
Issue #12595 | Feature: Merge Into Optimizations
如果你对这个主题感兴趣,可以尝试解决其中的部分问题或者参与讨论和 PR review 。或者,你可以点击 https://link.databend.rs/i-m-feeling-lucky 来挑选一个随机问题,祝好运!
Changelog
前往查看 Databend 每日构建的变更日志,以了解开发的最新动态。
地址:https://github.com/datafuselabs/databend/releases
Contributors
非常感谢贡献者们在本周的卓越工作。 ![]()
Connect With Us
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。